要求:编写实现网页数据集PageRank算法的程序,对网页数据集进行处理得到网页权重排序。 ####相关知识 ######PageRank算法原理 1.基本思想: 如果网页T存在一个指向网页A的连接,则表明T的所有者认为A比较重要,从而把T的一部分重要性得分赋予A。这个重要性得分值为:PR(T)/L(T) 其中PR(T)为T的PageRank值,L(T)为T的出链数。则A的PageRank值为一系列类似于T的页面重要性得分值的累加。
即一个页面的得票数由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(链入页面)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。
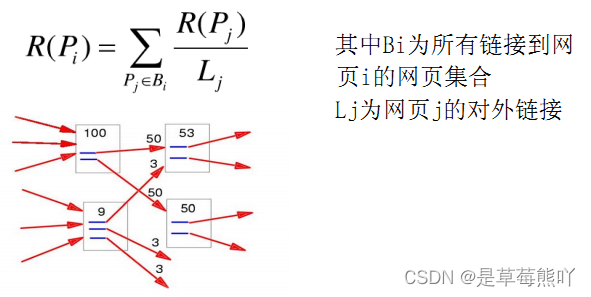
2.PageRank简单计算: 假设一个由只有4个页面组成的集合:A,B,C和D。如图所示,如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。

继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。
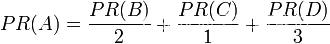
换句话说,根据链出总数平分一个页面的PR值。
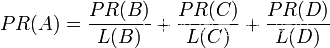
完整PageRank计算公式
由于存在一些出链为0不链接任何其他网页的网页,因此需要对 PageRank公式进行修正,即在简单公式的基础上增加了阻尼系数(damping factor)q, q一般取值q=0.85
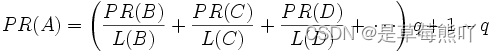
更加准确的表达为:
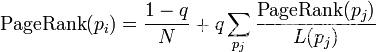
P1,P2,...,Pn是被研究的页面,M(Pi)是Pi链入页面的数量,L(Pj)是Pj链出页面的数量,而N是所有页面的数量。PageRank值是一个特殊矩阵中的特征向量。这个特征向量为:
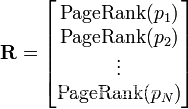
R是如下等式的一个解:
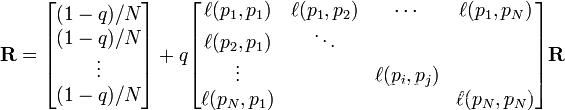
如果网页i有指向网页j的一个链接,则
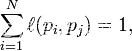
否则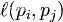 =0.
=0.
PageRank计算过程
PageRank 公式可以转换为求解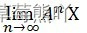
的值, 其中矩阵为 A = q × P + ( 1 一 q) * 。 P 为概率转移矩阵,为 n 维的全 1 行. 则=
幂法计算过程如下: X 设任意一个初始向量, 即设置初始每个网页的 PageRank值均。一般为1。R = AX。
while (1){ if ( |X - R| < e) return R; //如果最后两次的结果近似或者相同,返回R else { X =R; R = AX; } }
MapReduce计算PageRank
上面的演算过程,采用矩阵相乘,不断迭代,直到迭代前后概率分布向量的值变化不大,一般迭代到30次以上就收敛了。真的的web结构的转移矩阵非常大,目前的网页数量已经超过100亿,转移矩阵是100亿*100亿的矩阵,直接按矩阵乘法的计算方法不可行,需要借助Map-Reduce的计算方式来解决
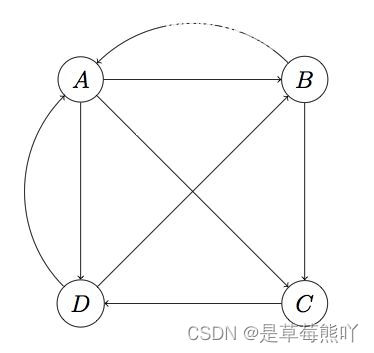
对于如下图所示的相互链接网页关系
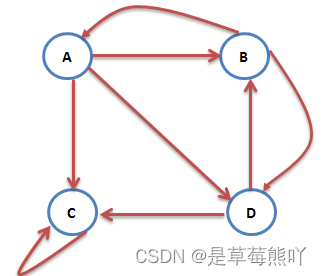
可以利用转移矩阵进行表示。转移矩阵是一个多维的稀疏矩阵,把web图中的每一个网页及其链出的网页作为一行,这样第四节中的web图结构用如下方式表示:
1. A B C D 2. B A D 3. C C 4. D B C
可以看A有三条出链,分布指向A、B、C,实际上爬取的网页结构数据就是这样的。 1.Map阶段 Map操作的每一行,对所有出链发射当前网页概率值的1/k,k是当前网页的出链数,比如对第一行输出<B,1/3*1/4>,<C,1/3*1/4>,<D,1/3*1/4>; 2、Reduce阶段 Reduce操作收集网页id相同的值,累加并按权重计算,pj=a*(p1+p2+…Pm)+(1-a)*1/n,其中m是指向网页j的网页j数,n所有网页数。 思路就是这么简单,但是实践的时候,怎样在Map阶段知道当前行网页的概率值,需要一个单独的文件专门保存上一轮的概率分布值,先进行一次排序,让出链行与概率值按网页id出现在同一Mapper里面,整个流程如下:
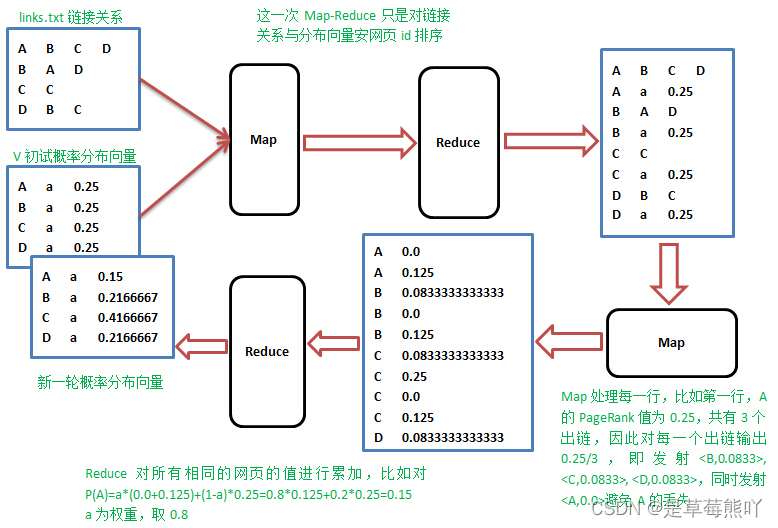
这样进行一次迭代相当于需要两次MapReduce,但第一次的MapReduce只是简单的排序,不需要任何操作,用java调用Hadoop的Streaming. ####编程要求 本关的编程任务是补全右侧代码片段中map和reduce函数中的代码,具体要求及说明如下:
import java.io.IOException;
import java.text.DecimalFormat;
import java.text.NumberFormat;
import java.util.StringTokenizer;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class PageRank {
public static class MyMapper extends Mapper<Object, Text, Text, Text>
{
private Text id = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException
{
String line = value.toString();
//判断是否为输入文件
if(line.substring(0,1).matches("[0-9]{1}"))
{
boolean flag = false;
if(line.contains("_"))
{
line = line.replace("_","");
flag = true;
}
//对输入文件进行处理
String[] values = line.split("\t");
Text t = new Text(values[0]);
String[] vals = values[1].split(" ");
String url="_";//保存url,用作下次计算
double pr = 0;
int i = 0;
int num = 0;
if(flag)
{
i=2;
pr=Double.valueOf(vals[1]);
num=vals.length-2;
}
else
{
i=1;
pr=Double.valueOf(vals[0]);
num=vals.length-1;
}
for(;i<vals.length;i++)
{
url=url+vals[i]+" ";
id.set(vals[i]);
Text prt = new Text(String.valueOf(pr/num));
context.write(id,prt);
}
context.write(t,new Text(url));
}
}
}
public static class MyReducer extends Reducer<Text,Text,Text,Text>
{
private Text result = new Text();
private Double pr = new Double(0);
public void reduce(Text key, Iterable<Text> values, Context context ) throws IOException, InterruptedException
{
double sum=0;
String url="";
//****请通过url判断否则是外链pr,作计算前预处理****//
/*********begin*********/
for(Text val:values)
{
//发现_标记则表明是url,否则是外链pr,要参与计算
if(!val.toString().contains("_"))
{
sum=sum+Double.valueOf(val.toString());
}
else
{
url=val.toString();
}
}
pr=0.15+0.85*sum;
String str=String.format("%.3f",pr);
result.set(new Text(str+" "+url));
context.write(key,result);
/*********end**********/
//****请补全用完整PageRank计算公式计算输出过程,q取0.85****//
/*********begin*********/
/*********end**********/
}
}
public static void main(String[] args) throws Exception
{
String paths="file:///tmp/input/Wiki0";//输入文件路径,不要改动
String path1=paths;
String path2="";
for(int i=1;i<=5;i++)//迭代5次
{
System.out.println("This is the "+i+"th job!");
System.out.println("path1:"+path1);
System.out.println("path2:"+path2);
Configuration conf = new Configuration();
Job job = new Job(conf, "PageRank");
path2=paths+i;
job.setJarByClass(PageRank.class);
job.setMapperClass(MyMapper.class);
//****请为job设置Combiner类****//
/*********begin*********/
job.setCombinerClass(MyReducer.class);
/*********end**********/
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(path1));
FileOutputFormat.setOutputPath(job, new Path(path2));
path1=path2;
job.waitForCompletion(true);
System.out.println(i+"th end!");
}
}
}
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我需要用任何语言编写一个算法,根据3个因素对数组进行排序。我以度假村为例(如Hipmunk)。假设我想去度假。我想要最便宜的地方、最好的评论和最多的景点。但是,显然我找不到在所有3个中都排名第一的方法。Example(assumingthereare20importantattractions):ResortA:$150/night...98/100infavorablereviews...18of20attractionsResortB:$99/night...85/100infavorablereviews...12of20attractionsResortC:$120/night
我正在尝试用ruby编写一个简单的网络抓取代码。它一直工作到第29个url,然后我收到此错误消息:C:/Ruby193/lib/ruby/1.9.1/open-uri.rb:346:in`open_http':500InternalServerError(OpenURI::HTTPError)fromC:/Ruby193/lib/ruby/1.9.1/open-uri.rb:775:in`buffer_open'fromC:/Ruby193/lib/ruby/1.9.1/open-uri.rb:203:in`blockinopen_loop'fromC:/Ruby193/lib/r
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我有一个对象如下:[{:id=>2,:fname=>"Ron",:lname=>"XXXXX",:photo=>"XXX"},{:id=>3,:fname=>"Dain",:lname=>"XXXX",:photo=>"XXXXXXX"},{:id=>1,:fname=>"Bob",:lname=>"XXXXXX",:photo=>"XXXX"}]我想按fname排序,不区分大小写,所以它会导致编号:1,3,2我该如何排序?我正在尝试:@people.sort!{|x,y|y[:fname]x[:fname]}但这没有任何效果。 最佳答案
有人可以告诉我如何根据自定义字符串对嵌套数组进行排序吗?比如有没有办法排序:[['Red','Blue'],['Green','Orange'],['Purple','Yellow']]“橙色”、“黄色”,然后是“蓝色”?最终结果如下所示:[['Green','Orange'],['Purple','Yellow'],['Red','Blue']]它不是按字母顺序排序的。我很想知道我是否可以定义要排序的值以实现上述目标。 最佳答案 sort_by对于这种排序总是非常方便:a=[['Red','Blue'],['Green','Ora
我有以下现有的Dog对象数组,它们按age属性排序:classDogattr_accessor:agedefinitialize(age)@age=ageendenddogs=[Dog.new(1),Dog.new(4),Dog.new(10)]我现在想插入一条新的狗记录,并将它放在数组中的正确位置。假设我想插入这个对象:another_dog=Dog.new(8)我想把它插入到数组中,让它成为数组中的第三项。这是一个人为的示例,旨在演示我特别想如何将一个项目插入到现有的有序数组中。我意识到我可以创建一个全新的数组并重新对所有对象进行排序,但这不是我的目标。谢谢!
我有一个这样的哈希{55=>{:value=>61,:rating=>-147},89=>{:value=>72,:rating=>-175},78=>{:value=>64,:rating=>-155},84=>{:value=>90,:rating=>-220},95=>{:value=>39,:rating=>-92},46=>{:value=>97,:rating=>-237},52=>{:value=>73,:rating=>-177},64=>{:value=>69,:rating=>-167},86=>{:value=>68,:rating=>-165},53=>{:va