段落排序是信息检索领域中十分重要且具有挑战性的话题,受到了学术界和工业界的广泛关注。段落排序模型的有效性能够提高搜索引擎用户的满意度并且对问答系统、阅读理解等信息检索相关应用有所助益。在这一背景下,例如 MS-MARCO,DuReader_retrieval 等一些基准数据集被构建用于支持段落排序的相关研究工作。然而常用的数据集大部分都关注英文场景,对于中文场景,已有的数据集在数据规模、细粒度的用户标注和假负例问题的解决上存在局限性。在这一背景下,我们基于真实搜索日志,构建了一个全新的中文段落排序基准数据集:T2Ranking。
T2Ranking由超过 30 万的真实查询和 200 万的互联网段落构成,并且包含了由专业标注人员提供的 4 级细粒度相关性标注。目前数据和一些 baseline 模型已经公布在 Github,相关研究工作已作为 Resource 论文被 SIGIR 2023 录用。

段落排序任务的目标是基于给定的查询词,从一个大规模段落集合中召回并排序候选段落,按照相关性从高到低的顺序得到段落列表。段落排序一般由段落召回和段落重排序两个阶段组成。
为了支持段落排序任务,多个数据集合被构建用于训练和测试段落排序算法。广泛使用的数据集大多聚焦英文场景,例如最常用的有 MS-MARCO 数据集,该数据集包含了 50 多万个查询词和 800 多万个段落,其中,每一个查询词都具有问题属性。对于每一个查询词,MS-MARCO 数据发布团队招募了标注人员提供了标准答案,根据给定段落是否包含人工提供的标准答案判断这个段落是否与查询词相关。
在中文场景中,也有一些数据集被构建用于支持段落排序任务。例如 mMarco-Chinese 是 MS-MARCO 数据集的中文翻译版本,DuReader_retrieval 数据集采用了和 MS-MARCO 相同的范式生成段落标签,即从人工提供的标准答案中来给定查询词 - 段落对的相关性评分。Multi-CPR 模型包含了来自三个不同领域(电子商务、娱乐视频和医药)的段落检索数据。基于搜狗搜索的日志数据,Sogou-SRR,Sogou-QCL 和 Tiangong-PDR 等数据集也相继被提出。
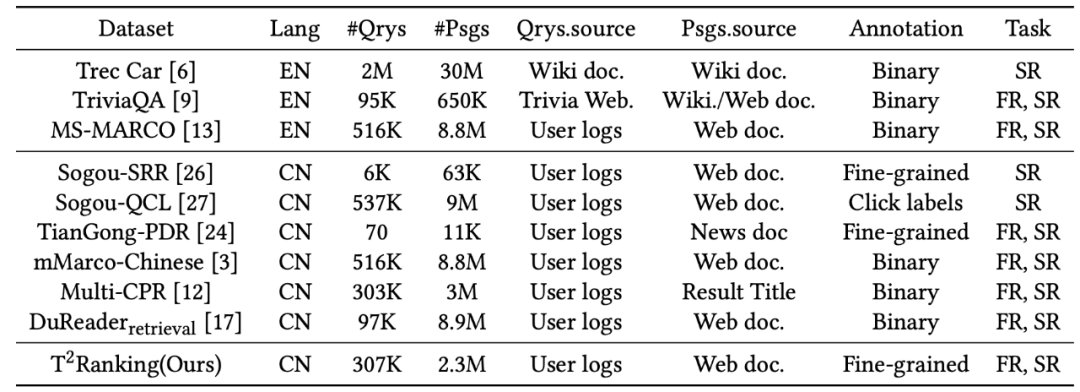
图 1:段落排序任务中常用数据集的统计信息
虽然已有数据集推进了段落排序应用的发展,我们也需要关注几个局限性:
1)这些数据集不是大规模的或者相关性标签不是人工标注的,特别是在中文场景下。Sogou-SRR 和 Tiangong-PDR 仅包含了少量的查询数据。虽然 mMarco-Chinese 和 Sogou-QCL 规模较大,但前者基于机器翻译,后者采用的相关性标签为用户的点击数据。最近,Multi-CPR 和 DuReader_retrieval 两个规模相对较大的数据集被相继构建和发布。
2)已有数据集缺乏细粒度的相关性标注信息。大部分数据集采用了二值相关性标注(粗粒度),即相关或者不相关。已有工作表明细粒度的相关性标注信息有助于挖掘不同实体之间的关系和构建更加精准的排序算法。然后已有数据集不提供或者仅提供少量的多级细粒度标注。例如 Sogou-SRR 或者 Tiangong-PDR 仅提供不超过 10 万个的细粒度标注。
3)假负例问题影响了评价的准确性。已有数据集受到了假负例问题的影响,即有大量相关文档被标记为不相关文档。这一问题是由于大规模数据中人工标注数量过少引起的,会显著影响评价的准确性。例如在 Multi-CPR 中,对于每一个查询词只有一个段落会被标记为相关,而其他都会被标记为不相关。DuReader_retrieval 尝试让标注者人工检查并且重新标注靠前的段落集合来缓解假负例问题。
为了能够更好地支持段落排序模型进行高质量的训练和评测,我们构建并且发布了一个新的中文段落检索基准数据集 - T2Ranking。
数据集的构建流程包括查询词采样,文档召回,段落提取和细粒度相关性标注。同时我们也设计了多个方法用于提升数据集质量,包括采用基于模型的段落切分方法和基于聚类的段落去重方法保证了段落的语义完整性和多样性,采用基于主动学习的标注方法提升标注的效率和质量等。
1)整体流程
图 2:维基百科页面示例。所展示的文档包含了清晰定义的段落。
2)基于模型的段落分割方法
在现有数据集中,段落通常是根据自然段落(换行符)或通过固定长度的滑动窗口从文档中进行分割得到的。然而,这两种方法可能都会导致段落的语义不完整或者因为段落过长而导致段落包含了多个不同的主题。在这个工作中,我们采用了基于模型的段落分割方法,具体而言,我们使用搜狗百科、百度百科和中文维基百科作为训练数据,因为这部分文档的结构是比较清晰的,并且自然段落也都得到了较好的定义。我们训练了一个分割模型来判断一个给定的单词是否需要作为分割点。我们利用了序列标注任务的思想,将每一个自然段的最后一个单词作为正例对模型进行训练。
3)基于聚类的段落去重方法
对高度相似的段落进行标注是冗余和无意义的,对于段落排序模型而言,高度相似的段落内容带来的信息增益有限,因此我们设计了一个基于聚类的段落去重方法来提高标注的效率。具体而言,我们采用了一个层次化聚类算法 Ward 对相似文档进行无监督聚类。在同一个类中的段落被认为是高度相似的,我们从每一个类中采样一个段落进行相关性标注。需要注意的是,我们只在训练集中进行这个操作,对于测试集,我们会对所有提取的段落进行完整标注,减少假负例的影响。
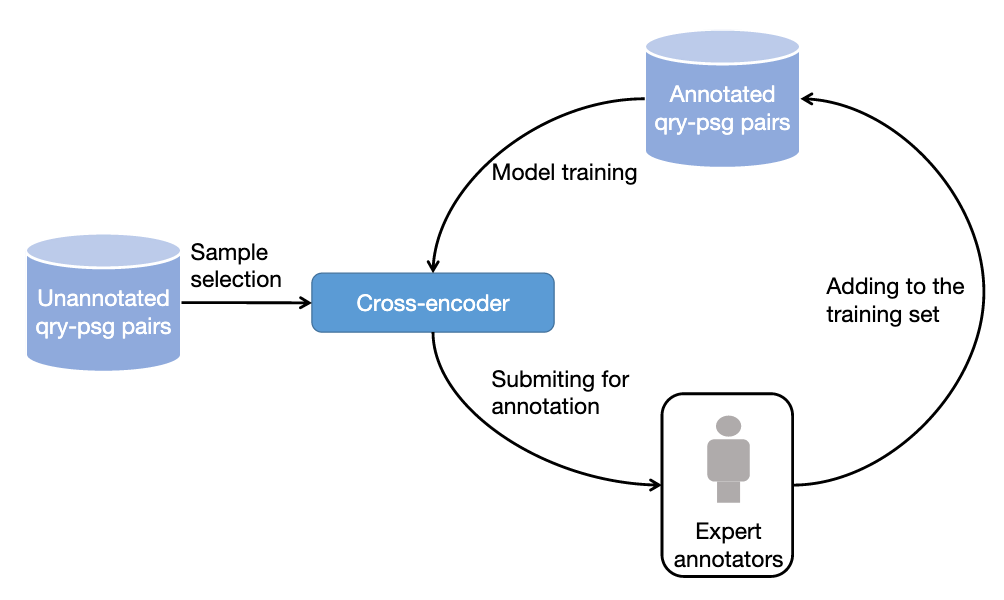
图 3:基于主动学习的采样标注流程
4)基于主动学习的数据采样标注方法
在实践中,我们观察到并不是所有的训练样本都能够进一步提升排序模型的性能。对于模型能够准确预测的训练样本,对于后续模型的训练助益有限。因此,我们借鉴了主动学习的想法,让模型能够选择更有信息量的训练样本进行进一步的标注。具体而言,我们先基于已有的训练数据,训练了一个以交叉编码器为框架的查询词 - 段落重排序模型,接着我们用这个模型对其他数据进行预测,去除过高置信分数(信息量低)和过低置信分数(噪音数据)的段落,对保留的段落进行进一步标注,并迭代这一流程。
T2Ranking 由超过 30 万的真实查询和 200 万的互联网段落构成。其中,训练集包含约 25 万个查询词,测试集包含约 5 万个查询词。查询词长度最长为 40 个字符,平均长度在 11 个字符左右。同时,数据集中的查询词覆盖了多个领域,包括医药、教育、电商等,我们也计算了查询词的多样性分数(ILS),与已有数据集相比,我们的查询多样性更高。采样的 230 多万个段落来源于 175 万个文档,平均每个文档被分割为了 1.3 个段落。在训练集中,平均每个查询词有 6.25 个段落被人工标注,而在测试集中,平均每个查询词有 15.75 个段落被人工标注。
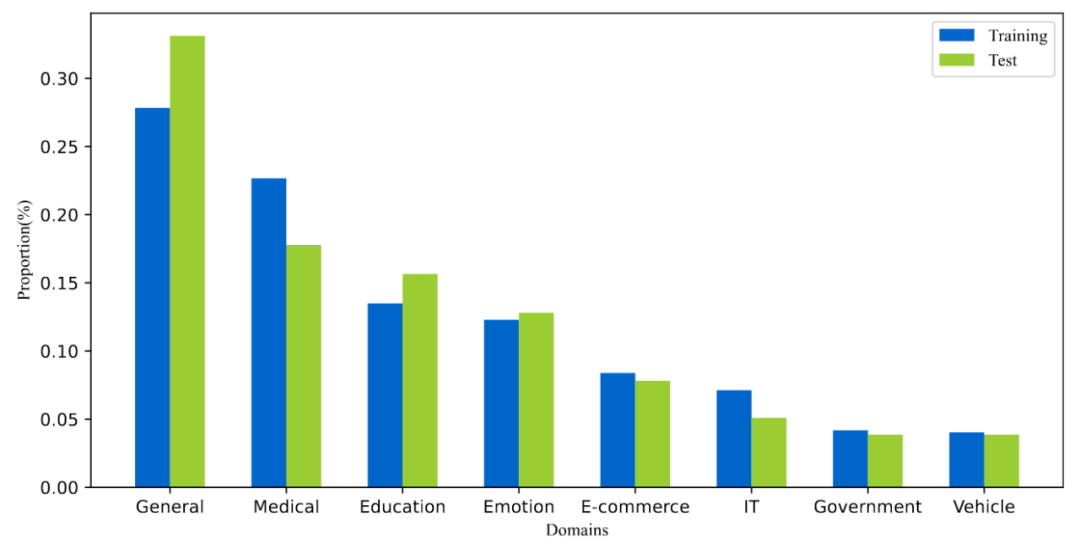
图 4:数据集中查询词的领域分布情况
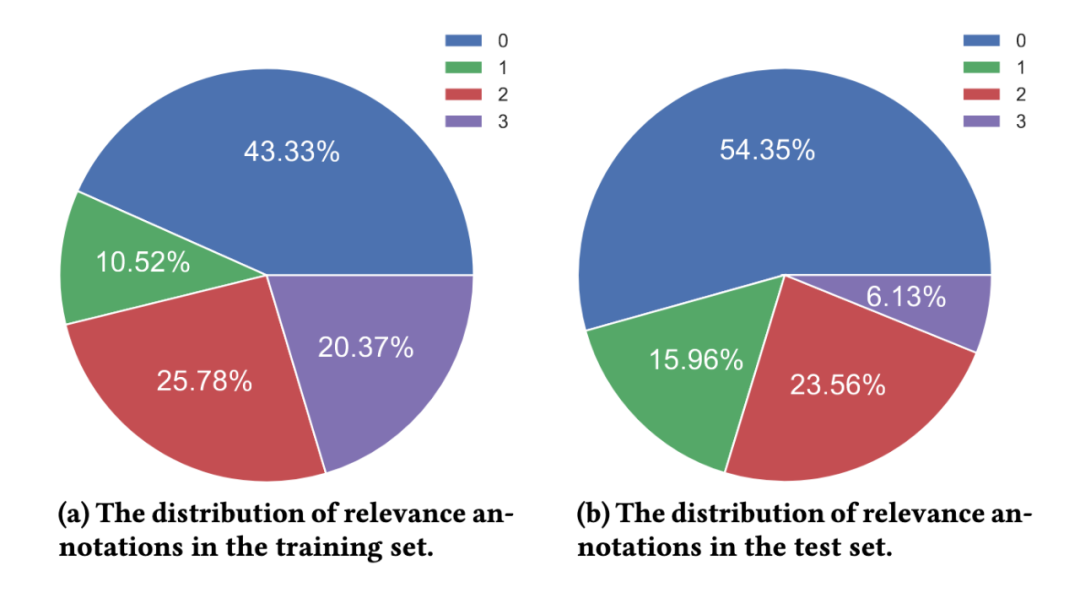
图 5:相关性标注分布情况
我们在所得到的数据集上,测试了一些常用的段落排序模型的性能,我们同时评测了已有方法在段落召回和段落重排序两个阶段上的性能。
1)段落召回实验
已有的段落召回模型可以被大致分为稀疏召回模型和稠密召回模型。
我们测试了以下召回模型的表现:
在这些模型中,QL 和 BM25 是稀疏召回模型,其他模型为稠密召回模型。我们采用 MRR,Recall 等常用指标来评价这些模型的性能,实验结果如下表所示:
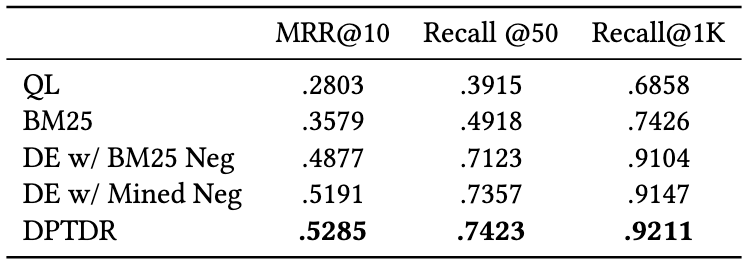
图 6:段落召回模型在测试集上的表现
从实验结果可以看出,相较于传统的稀疏排序模型,稠密检索模型取得了更好的表现。同时引入了难负例对于模型性能的提升也是有帮助的。值得一提的是,这些实验模型在我们数据集上的召回表现要比在其他数据集上的表现差,例如 BM25 在我们的数据集上的 Recall@50 是 0.492,而在 MS-Marco 和 Dureader_retrieval 上是 0.601 和 0.700。这可能是由于我们有更多的段落被进行了人工标注,在测试集中,平均每个查询词下我们有 4.74 个相关文档,这使得召回任务更加具有挑战性且一定程度上降低了假负例的问题。这也说明了 T2Ranking 是一个具有挑战的基准数据集,对未来的召回模型而言有较大的提升空间。
2)段落重排序实验
相比于段落召回阶段,重排序阶段需要考虑的段落规模较小,因此大多数方法倾向于使用交互编码器(Cross-Encoder)作为模型框架,在本工作中,我们测试了交互编码器模型在段落重排序任务上的性能,我们采用 MRR 和 nDCG 作为评价指标,实验效果如下:

图 7:交互编码器在段落重排序任务上的表现
实验结果表明,在双塔编码器(Dual-Encoder)召回的段落基础上进行重排效果比在 BM25 召回的段落基础上重排能够取得更好的效果,这与已有工作的实验结论一致。与召回实验类似,重排序模型在我们数据集上的表现比在其他数据集上的表现差,这可能是由于我们数据集采用了细粒度标注且具有更高的查询词多样性造成,也进一步说明了我们的数据集是具有挑战性的,并且能够更精确地反映模型性能。
该数据集由清华大学计算机系信息检索课题组(THUIR)和腾讯公司 QQ 浏览器搜索技术中心团队共同发布,得到了清华大学天工智能计算研究院的支持。THUIR 课题组聚焦搜索与推荐方法研究,在用户行为建模和可解释学习方法等方面取得了典型成果,课题组成果获得了包括 WSDM2022 最佳论文奖、SIGIR2020 最佳论文提名奖和 CIKM2018 最佳论文奖在内的多项学术奖励,并获得了 2020 年中文信息学会 “钱伟长中文信息处理科学技术奖” 一等奖。QQ 浏览器搜索技术中心团队是腾讯 PCG 信息平台与服务线负责搜索技术研发的团队,依托腾讯内容生态,通过用户研究驱动产品创新,为用户提供图文、资讯、小说、长短视频、服务等多方位的信息需求满足。
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实
我需要用任何语言编写一个算法,根据3个因素对数组进行排序。我以度假村为例(如Hipmunk)。假设我想去度假。我想要最便宜的地方、最好的评论和最多的景点。但是,显然我找不到在所有3个中都排名第一的方法。Example(assumingthereare20importantattractions):ResortA:$150/night...98/100infavorablereviews...18of20attractionsResortB:$99/night...85/100infavorablereviews...12of20attractionsResortC:$120/night
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排