MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。
Map负责“分”,把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce负责“合”,即对map阶段的结果进行全局汇总。
MapReduce运行在yarn集群。ResourceManager+NodeManager这两个阶段合起来就是MapReduce思想的体现。
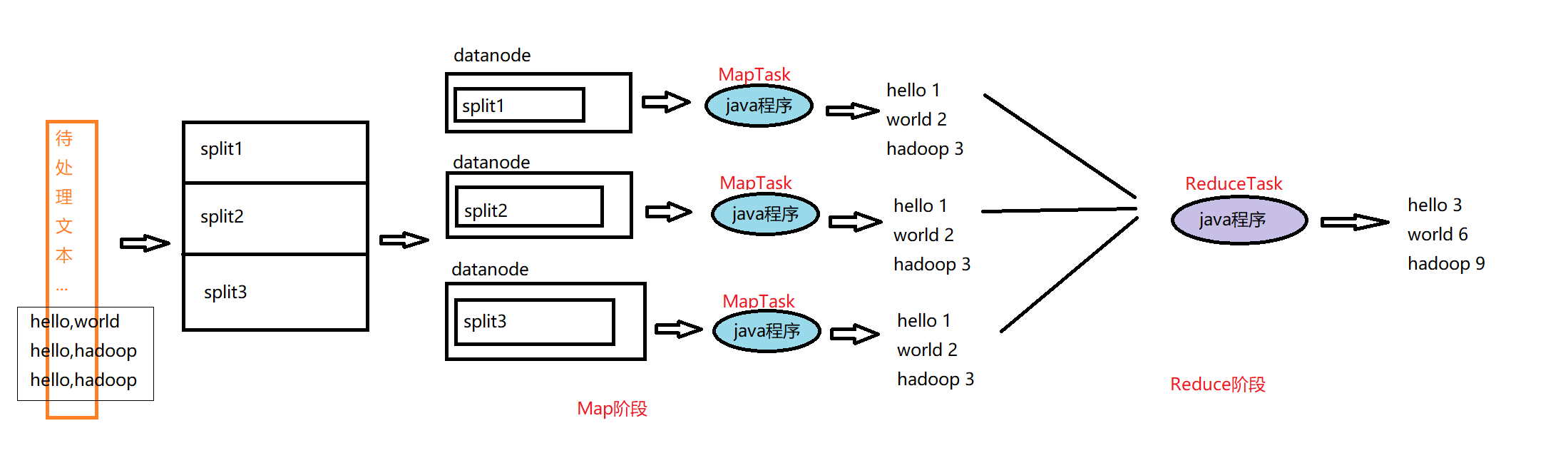
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在Hadoop集群上。
MapReduce设计并提供了一个同意的计算框架,为程序员隐藏了绝大多数系统层面的处理细节,为程序员提供了一个抽象和高层的编程接口和框架。程序员仅需要关心应用层的具体计算问题,仅需要编写少量的处理应用本身计算问题的程序代码。
Map和Reduce为程序员提供了一个清晰的操作接口抽象描述。MapReduce中定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现Map和Reduce,MapReduce处理的数据类型是<key,value>键值对。
一个完整的MapReduce程序在分布式运行时有三类实例进程:
MRAppMaster 负责整个程序的过程调度及状态协调
MapTask 负责map阶段的整个数据处理流程
ReduceTask 负责reduce阶段的整个数据处理流程
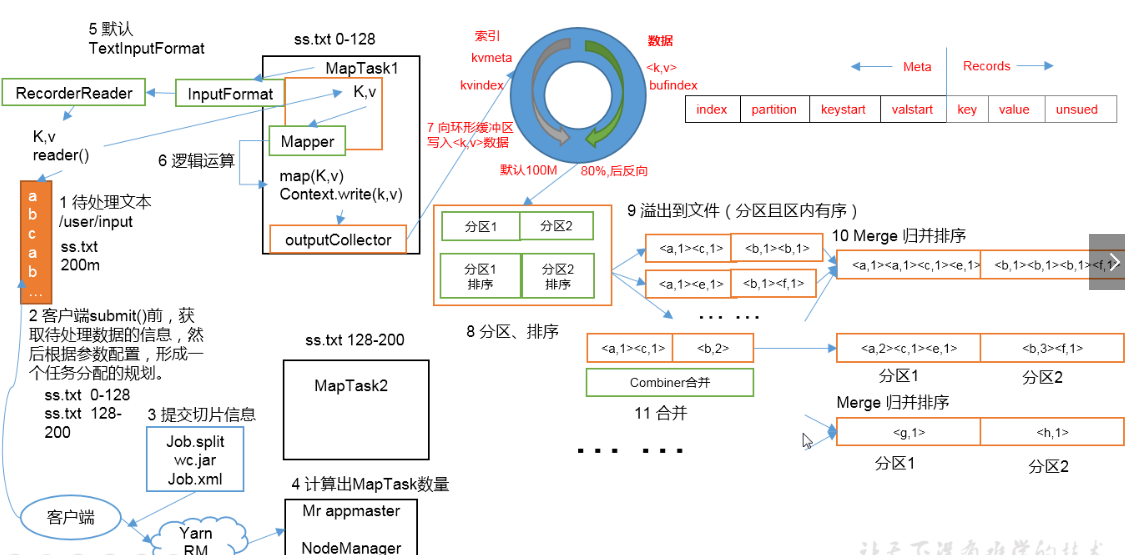
FileInputstream,首先要计算切片大小,FileInputstream是一个抽象类,继承InputFormat接口,真正完成工作的是它的实现类,默认为是TextInputFormat,TextInputFormat是读取文件的,默认为一行一行读取,将输入文件切分为逻辑上的多个input split,input split是MapReduce对文件进行处理和运算的输入单位,只是一个逻辑概念。
在进行Map计算之前,MapReduce会根据输入文件计算的切片数开启map任务,一个输入切片对应一个maptask,输入分片存储的并非数据本身,而是一个分片长度和一个记录数据位置的集合,每个input spilt中存储着该分片的数据信息如:文件块信息、起始位置、数据长度、所在节点列表等,并不是对文件实际分割成多个小文件,输入切片大小往往与hdfs的block关系密切,默认一个切片对应一个block,大小为128M;注意:尽管我们可以使用默认块大小或自定义的方式来定义分片的大小,但一个文件的大小,如果是在切片大小的1.1倍以内,仍作为一个片存储,而不会将那多出来的0.1单独分片。
TextInputFormat 会创建RecordReader去读取数据,通过getCurrentkey,getCurrentvalue,nextkey,value等方法来读取,读取结果会形成key,value形式返回给maptask,key为偏移量,value为每一行的内容,此操作的作用为在分片中每读取一条记录就调用一次map方法,反复这一过程直到将整个分片读取完毕。
此阶段就是程序员通过需求偏写了map函数,将数据格式化的<K,V>键值对通过Mapper的map()方法逻辑处理,形成新的<k,v>键值对,通过Context.write输出到OutPutCollector收集器
map端的shuffle(数据混洗)过程:溢写(分区,排序,合并,归并)
溢写:
由map处理的结果并不会直接写入磁盘,而是会在内存中开启一个环形内存缓冲区,先将map结果写入缓冲区,这个缓冲区默认大小为100M,并且在配置文件里为这个缓冲区设了一个阀值,默认为0.8,同时map还会为输出操作启动一个守护线程,如果缓冲区内存达到了阀值0.8,这个线程会将内容写入到磁盘上,这个过程叫作spill(溢写)。
分区Partition
当数据写入内存时,决定数据由哪个Reduce处理,从而需要分区,默认分区方式采用hash函数对key进行哈布后再用Reduce任务数量进行取模,表示为hash(key)modR,这样就可以把map输出结果均匀分配给Reduce任务处理,Partition与Reduce是一一对应关系,类似于一个分片对应一个map task,最终形成的形式为(分区号,key,value)
排序Sort:
在溢出的数据写入磁盘前,会对数据按照key进行排序,默认采用快速排序,第一关键字为分区号,第二关键字为key。
合并combiner:
程序员可选是否合并,数据合并,在Reduce计算前对相同的key数据、value值合并,减少输出量,如(“a”,1)(“a”,1)合并之后(“a”,2)
归并menge
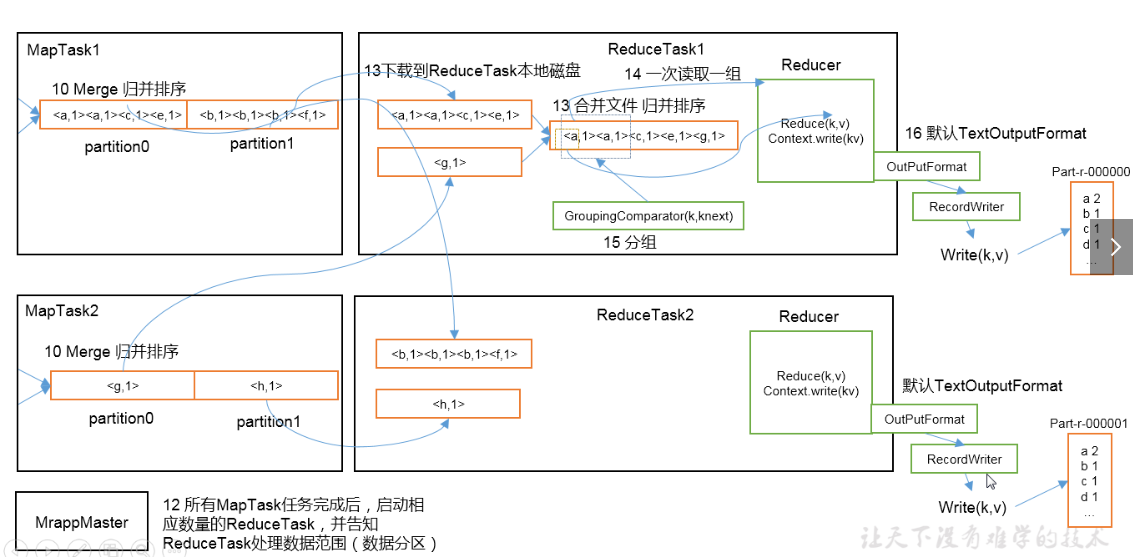
每块溢写会成一个溢写文件,这些溢写文件最终需要被归并为一个大文件,生成key对应的value-list,会进行归并排序<"a",1><"a",1>归并后<"a",<1,1>>。
Reduce 端的shffle:
数据copy:map端的shffle结束后,所有map的输出结果都会保存在map节点的本地磁盘上,文件都经过分区,不同的分区会被copy到不同的Recuce任务并进行并行处理,每个Reduce任务会不断通过RPC向JobTracker询问map任务是否完成,JobTracker检测到map位务完成后,就会通过相关Reduce任务去aopy拉取数据,Recluce收到通知就会从Map任务节点Copy自己分区的数据此过程一般是Reduce任务采用写个线程从不同map节点拉取
归并数据:
Map端接取的数据会被存放到 Reduce端的缓存中,如果缓存被占满,就会溢写到磁盘上,缓存数据来自不同的Map节点,会存在很多合并的键值对,当溢写启动时,相同的keg会被归并,最终各个溢写文件会被归并为一个大类件归并时会进行排序,磁盘中多个溢写文许归并为一个大文许可能需要多次归并,一次归并溢写文件默认为10个
Reduce任务会执行Reduce函数中定义的各种映射,输出结果存在分布式文件系统中。
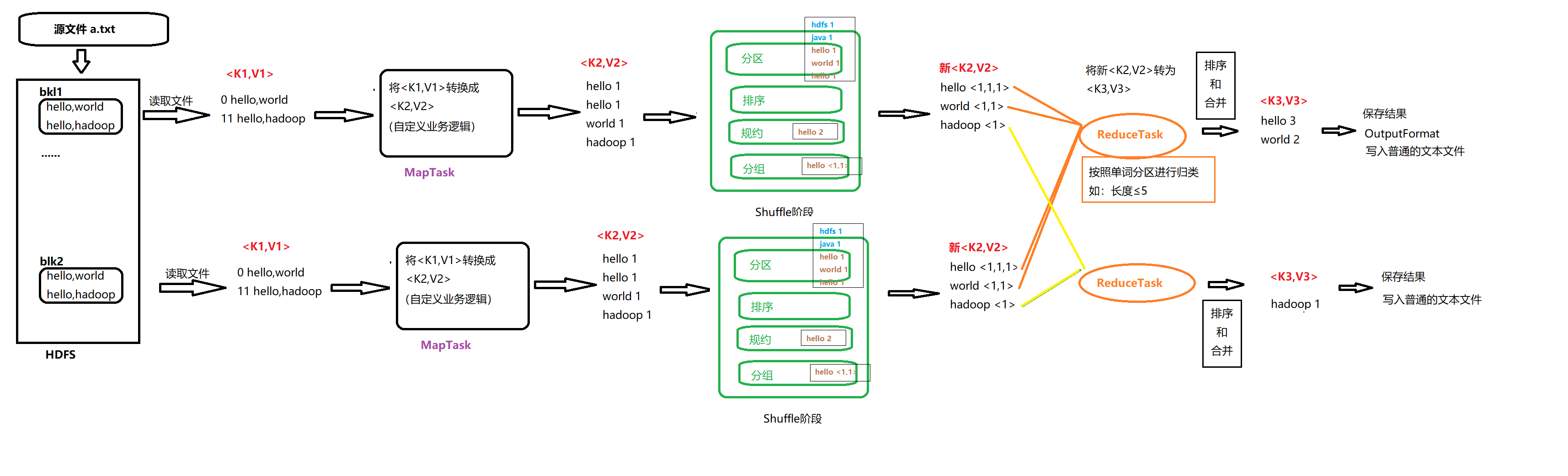
设置InputFormat类,将数据切分为Key-Value(K1和V1)对,输入到第二步
自定义Map逻辑,将第一步的结果转换为另外的Key-Value(K2和V2)对,输出结果
对输出的Key-Value进行分区
对不同分区的数据按照相同的key排序
(可选)对分组过的数据初步规约,降低数据的网络拷贝
对数据进行分组,相同的Key和Value放入一个集合中
对多个Map任务的结果进行排序以及合并,编写Reduce函数实现自己的逻辑,对输入的Key-Value进行处理,转为新的Key-Value(K3和V3)输出
设置OutputFromat处理并保存Reduce输出的Key-Value数据
(1)Input:一系列(K1,V1)。
(2)Map和Reduce:
Map:(K1,V1) -> list(K2,V2) (其中K2/V2是中间结果对)
Reduce:(K2,list(v2)) -> list(K3,V3)
(3)Output:一系列(K3,V3)。
# 将maven版本改为1.8
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
# 添加如下依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>${hadoop-version}</version>
</dependency>
《wordcount.txt》
hello java
hello hadoop
hello java
hello java hadoop
java hadoop
hadoop java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text = new Text();
IntWritable intWritable = new IntWritable();
System.out.println("WordCountMap stage Key:"+key+" Value:"+value);
String[] words = value.toString().split(" "); // "hello world"->[hello,world]
for (String word : words) {
text.set(word);
intWritable.set(1);
context.write(text,intWritable); // <hello,1> <word,1>
}
}
}
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text, IntWritable,Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
System.out.println("Reduce stage Key:"+key+" Values"+values.toString());
int count=0;
for (IntWritable intWritable : values) {
count += intWritable.get();
}
LongWritable longWritable = new LongWritable(count);
System.out.println("Key:"+key+" ResultValue:"+longWritable.get());
context.write(key,longWritable);
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCountDriver.class);
// 设置mapper类
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置Reduce类
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定map输入的文件路径
FileInputFormat.
setInputPaths(job,new Path("D:\\Servers\\hadoopstu\\in\\wordcount.txt"));
// 指定reduce结果的输出路径
Path path = new Path("D:\\Servers\\hadoopstu\\out1");
FileSystem fileSystem = FileSystem.get(path.toUri(), configuration);
if(fileSystem.exists(path)){
fileSystem.delete(path,true);
}
FileOutputFormat.setOutputPath(job,path);
job.waitForCompletion(true);
}
}

protected void map(LongWritable key, Text value, Context context)
继承Mapper类,实现map方法,重写的map方法中包含三个参数,key、value就是输入的key、value键值对(<K1,V1>),context记录的是整个上下文,可以通过context将数据写出去。

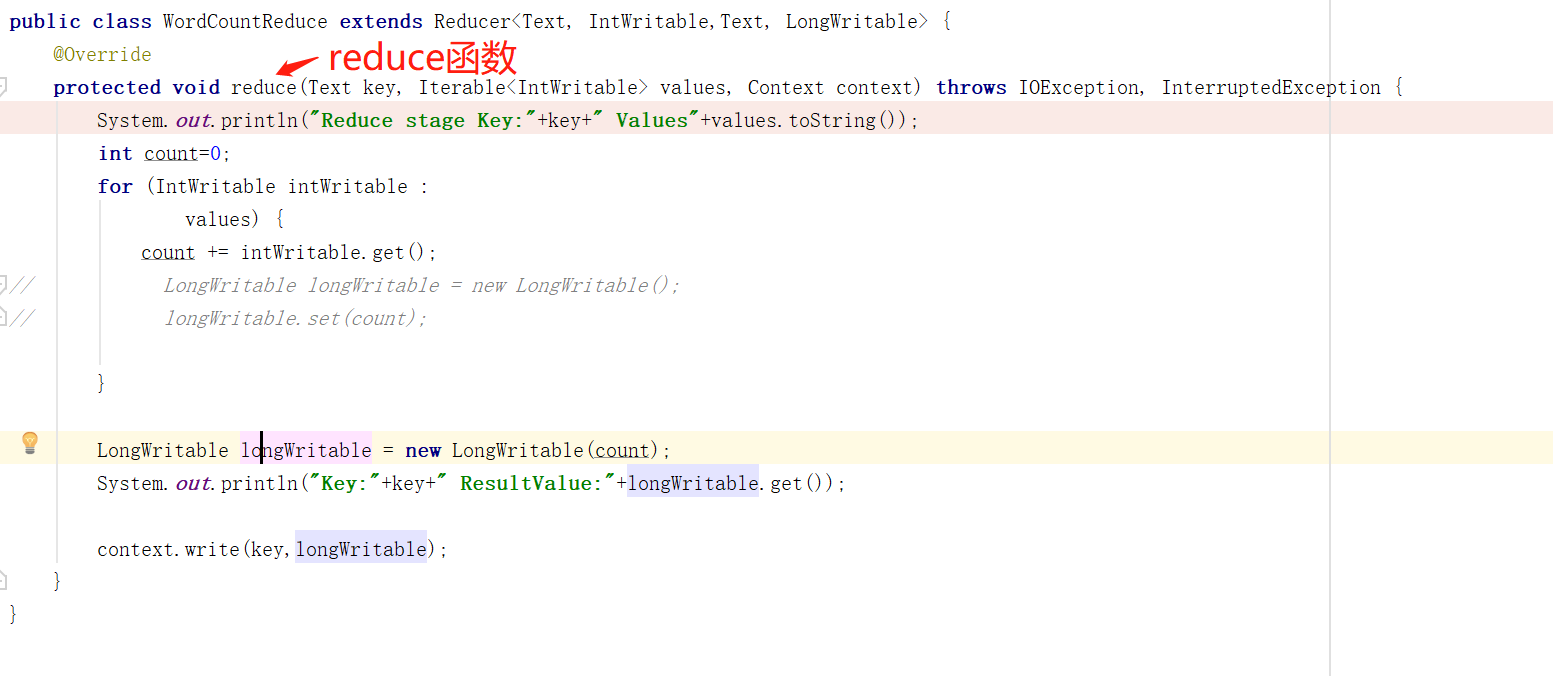
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
继承Reduce类,实现reduce方法,reduce函数输入的是一个<K,V>形式,但是这里的value是以迭代器的形式Iterable<IntWritable> value。即,reduce的输入是一个key对应一组value。
reduce中context参数与map中的reduce参数作用一致。

创建configuration()类,作用是读取MapReduce系统配置信息
创建job类
设置map函数、map函数输出的key、value类型
设置reduce函数、reduce函数输出的key、value类型,即最终存储再HDFS结果文件中的key、value类型
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
使用Ruby1.9.2运行IDE提示说需要gemruby-debug-base19x并提供安装它。但是,在尝试安装它时会显示消息Failedtoinstallgems.Followinggemswerenotinstalled:C:/ProgramFiles(x86)/JetBrains/RubyMine3.2.4/rb/gems/ruby-debug-base19x-0.11.30.pre2.gem:Errorinstallingruby-debug-base19x-0.11.30.pre2.gem:The'linecache19'nativegemrequiresinstall
我知道全局变量$!包含最新的异常对象,但我对下面的语法感到困惑。谁能帮助我理解以下语法?rescue$! 最佳答案 此构造可防止异常停止您的程序并使堆栈跟踪冒泡。它还会将该异常作为值返回,这很有用。a=get_me_datarescue$!在此行之后,a将保存请求的数据或异常。然后您可以分析该异常并采取相应措施。defget_me_dataraise'Nodataforyou'enda=get_me_datarescue$!puts"Executioncarrieson"pa#>>Executioncarrieson#>>#更现实的
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我在我正在处理的一些代码中发现了这一点。它旨在解决从磁盘读取key文件的要求。在生产环境中,key文件的内容位于环境变量中。旧代码:key=File.read('path/to/key.pem')新代码:key=File.read('|echo$KEY_VARIABLE')这是如何工作的? 最佳答案 来自IOdocs:Astringstartingwith“|”indicatesasubprocess.Theremainderofthestringfollowingthe“|”isinvokedasaprocesswithappro