摄像头能否实现激光雷达的检测效果,以更低成本实现自动驾驶感知?在最新的 CVPR2023 论文《Collaboration helps camera overtake LiDAR in 3D detection》中,来自上海交通大学、加州大学洛杉矶分校、以及上海人工智能实验室的研究者提出了纯视觉协作探测方法(CoCa3D),通过让多个基于纯视觉的智能车高效协作,在 3D 目标探测效果上,接近甚至超越基于激光雷达的智能车。

论文标题:Collaboration Helps Camera Overtake LiDAR in 3D Detection
论文链接:https://arxiv.org/abs/2303.13560
代码链接:https://github.com/MediaBrain-SJTU/CoCa3D
近年来,自动驾驶感知领域存在着巨大的技术分歧:以 Waymo 为代表的多传感器融合派以激光雷达为主传感器,而以 Tesla 为代表的视觉优先派坚持使用纯摄像头。其中激光雷达的主要问题在于价格昂贵,Velodyne 的 64 线激光雷达成本为 75,000 美金左右,成本高,难以扩大规模。纯视觉的方案极低地降低了成本,Autopilot 2.+ 的 BOM 成本控制在 2,500 美金左右。但同激光雷达相比,摄像头缺乏深度信息,在 3D 空间的目标检测上存在天然巨大劣势。虽然近年来基于鸟瞰图(BEV)的技术方法快速发展,大大提升了纯视觉探测的效果,但距离激光雷达的探测效果依旧相去甚远。
为了突破纯视觉 3D 空间感知能力瓶颈,CoCa3D 开辟了多车协作的全新维度,从物理属性上迅速提升纯视觉 3D 目标检测能力。多辆纯视觉智能车通过分布式地交换关键信息,使得来自多车多视角几何信息可以互相校验,能够有效提升 2D 相机对 3D 空间的感知能力,从而接近激光雷达的探测效果。除此之外,多车多视角观测信息的互相补充,能突破单体感知的视角局限性,实现更完备的探测,有效缓解遮挡和远距离问题,进而超越单个激光雷达的 3D 空间感知效果。

图 1. 多车协作可以避免 “鬼探头” 引发的事故,实现更安全的智能驾驶
与许多多视角几何问题不同,多个纯视觉车协作依赖先进的通信系统来进行信息交互,而现实情况下通信条件多变且受限。因此,多个纯视觉车协作的关键问题在如何在通信带宽限制的情况下,选择最关键的信息进行共享,弥补纯视觉输入中缺失的深度信息,同时弥补单视角下视野受限区域缺失的信息,提升纯视觉输入的 3D 空间感知能力。
CoCa3D 考虑以上关键问题,进行了两个针对性的设计。
首先,协作信息应包含深度信息,这将使得来自多个纯视觉车的不同角度的观测,缓解单点观测的深度歧义性,相互矫正定位正确的深度。同时,每个纯视觉车过滤掉不确定性较高的深度信息,选择最关键的深度信息分享,减少带宽占用。最高效地弥补纯视觉输入相比 LiDAR 输入缺失的深度信息,实现接近的 3D 检测效果。
其次,协作信息中应包含检测信息以缓解单点观测的视角局限性,例如遮挡和远程问题,相互补充检测信息正确定位物体。并潜在地实现了更全面的 3D 检测,即检测所有存在于三维场景中的目标,包括那些超出视觉范围的目标。同时,每个纯视觉车过滤掉置信度较低的检测信息,选择最关键的检测信息分享,减少带宽占用。由于 LiDAR 也受到视野有限的限制,这潜在地使得多个纯视觉车协作有可能取得胜过 LiDAR 的探测效果。
基于此动机,CoCa3D 整体系统包括两个部分,单体相机 3D 检测,实现基本的深度估计和检测能力,以及多体协作,共享估计的深度信息和检测特征以提高 3D 表示和检测性能。其中多体协作由协作特征估计和协作检测特征学习两个关键部分构成。
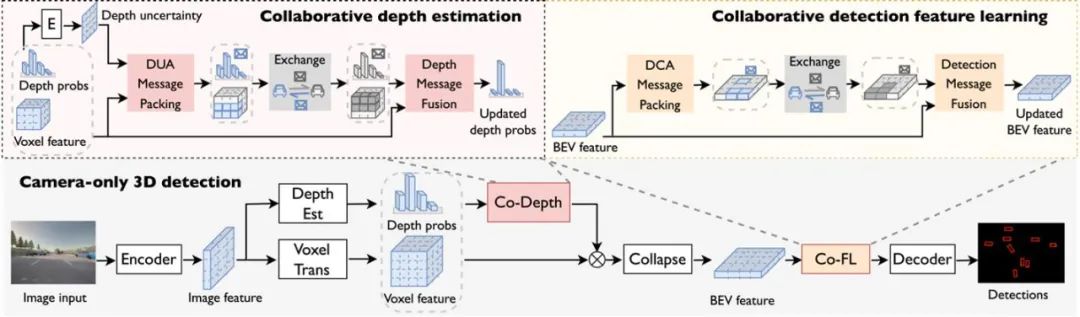
图 2. CoCa3D 整体系统框图。协作深度估计(Collaborative depth estimation)和协作检测特征学习(Collaborative detection feature learning)是两大关键模块
协作深度估计(Collaborative depth estimation, Co-Depth):旨在消除单体相机深度估计中深度的歧义性,并通过多视图的一致性定位正确的候选深度。直觉是,对于正确的候选深度,其对应的 3D 位置从多个代理的角度来看应该在空间上是一致的。为此,每个协作者可以通过通信交换深度信息。同时,通过选择最关键和明确的深度信息来提高通信效率。Co-Depth 由两部分构成:a) 基于不确定性的深度消息打包模块,将确定的深度信息打包为紧凑的消息包传递出去;和 b) 深度信息融合模块,通过与接收到的来自其他协作者视角的深度消息校验来缓解自身单视角下深度估计的歧义性。
协作检测特征学习(Collaborative detection feature learning, Co-FL):协作深度估计会仔细细化深度并为每个智能体提供更准确的 3D 表示。然而,单一智能体的物理局限性,如视野受限、遮挡和远程问题仍然存在。为了实现更全面的 3D 检测,每个智能体都应该能够交换 3D 检测特征并利用互补信息。同时,通过选择感知上最关键的信息来提高通信效率。核心思想是探索感知信息的空间异质性。直觉是包含目标的前景区域比背景区域更关键。在协作过程中,带有目标的区域可以帮助恢复由于有限视野而导致的漏检问题,而背景区域则可以忽略以节省宝贵的带宽。Co-FL 由两部分构成:a)基于检测置信度的感知信息打包模块,在检测置信度的指导下打包空间稀疏但感知上关键的三维特征;和 b)检测信息融合模块,通过补充接收到的来自其他协作者视角的检测信息来提升自身受限视角下的不完备的三维特征。
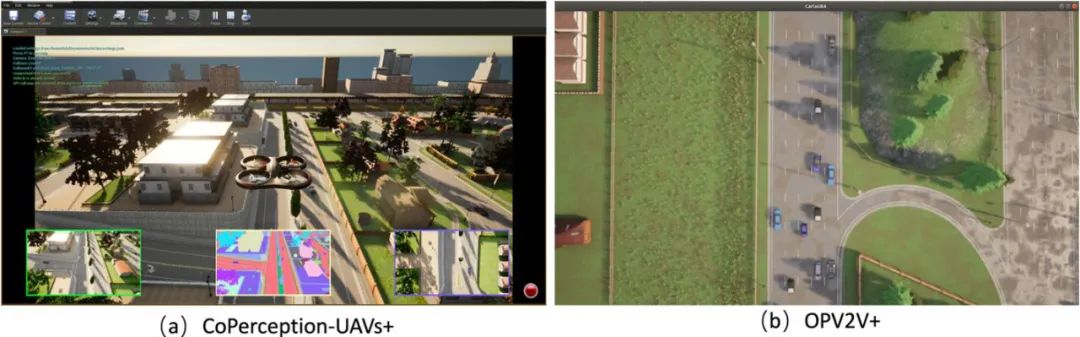
图 3. 数据集 CoPerception-UAVs + 和 OPV2V + 仿真环境

图 4. 数据集 CoPerception-UAVs+、DAIR-V2X 和 OPV2V + 样本可视化
为全面展示本文所提出的 CoCa3D 的优异性能,研究者在三个数据集上对其进行验证,包括无人飞机集群数据 CoPerception-UAVs+, 车路协同仿真数据集 OPV2V+,以及车路协同真实数据集 DAIR-V2X。其中 CoPerception-UAVs + 是原始的 CoPerception-UAVs(NeurIPS22)的扩展版本,包括更多的智能体(约 10 个),是更一个大规模无人机协同感知的数据集,由 AirSim 和 CARLA 共同模拟生成。OPV2V + 是原始的 OPV2V(ICRA 22)的扩展版本,包括更多的智能体(约 10 个),是更一个大规模车路协同的数据集,由 OpenCDA 和 CARLA 共同模拟生成。
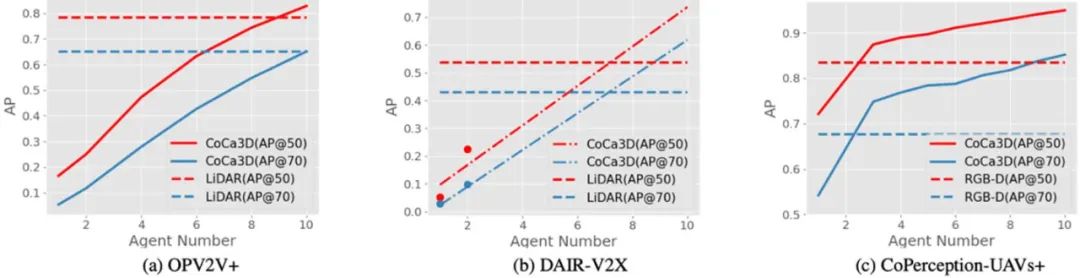
图 5. CoCa3D 在多数据集上均取得了接近激光雷达的 3D 目标检测效果
研究者发现,CoCa3D(实线)在 10 个相机的协作下在 OPV2V+ 上的 AP@0.5/0.7 都优于 LiDAR 3D 检测!由于真实车路协同数据集 DAIR-V2X 仅有 2 个协作相机,我们使用 OPV2V + 的斜率来拟合真实车路协同数据集上的检测性能与协作相机个数的函数,发现在实际场景中,仅 7 个协作相机即可实现优于 LiDAR 3D 检测的效果!此外,随着协作代理数量的增加,检测性能的稳步提高鼓励协作者积极协作并实现持续改进。
基于协同感知数据集 OPV2V+,研究者对比了单体感知和协作感知在 3D 目标探测任务的效果,如下面的动图所示(绿框为真值,红框为检测框)。a/b 图展示了单个相机 / 激光雷达的探测效果,受限于传感器的探测范围和物理遮挡,右侧路口的多量车难以被有效探测,c 图展示了多个无人车的相机协作探测的效果,基于本文提出的 CoCa3D 方法,实现了超视距的感知。由此可见,协作感知通过同一场景中多智能体之间互通有无,分享感知信息,使得单个智能体突破自身传感器的局限性获得对整个场景更为准确全面的理解。

图 6. 3D 检测结果 3D 视角和 BEV 视角可视化(红框为检测框,绿框为真值)。(a) 单个相机检测效果可视化,(b) 激光雷达检测效果可视化,(c) 协作相机检测效果可视化。
值得注意的是,相比之前的基线方法 V2X-ViT(ECCV 22),针对某个特定通信量进行了有针对性的模型训练,因此在通信量 - 探测效果的图中是一个单点。而 CoCa3D 可以自动调整和适应各个通信量,因此是一条曲线。由此可见,CoCa3D 实现了感知效果与通信消耗的有效权衡,能自适应资源多变的通信环境,且在各种通信条件下均取得了优于基线方法 Where2comm(NeurIPS 22)的感知效果。
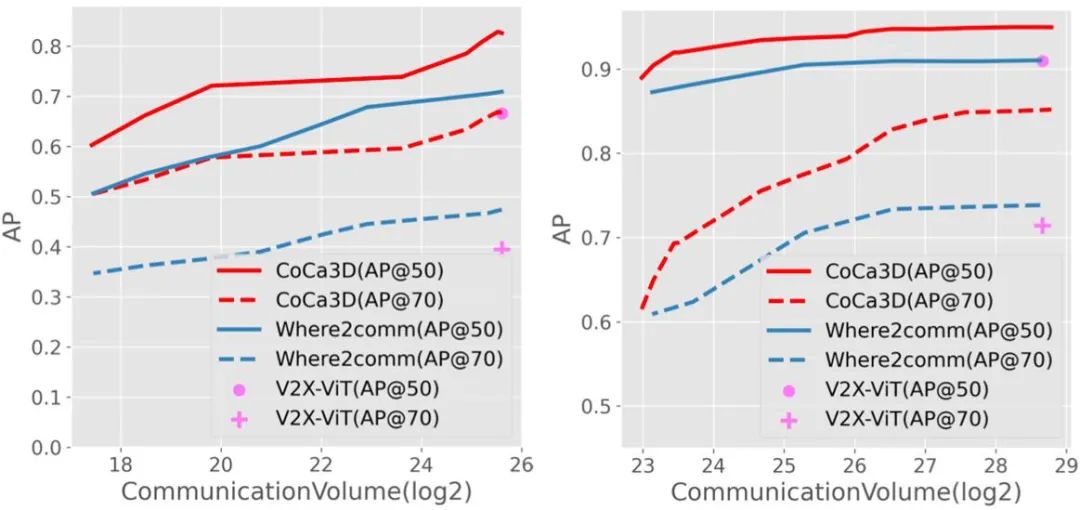
图 7. CoCa3D 在多个数据集上多种通信带宽条件下均取得最优的 3D 感知效果
研究者发现:i)单个视角下深度估计可以估计相对深度,但无法精确地定位深度绝对位置,例如,车辆比其所在的平面更高,但这个平面没有正确分类;ii)通过协作的深度信息分享,引入多视图几何,协作估计的深度可以平稳而准确地定位平面;iii)对于远距离和背景区域,深度的不确定性较大。原因是远处的区域很难定位,因为它们占用的图像像素太少,而背景区域由于没有纹理表面而难以定位。

图 8 深度和不确定性的可视化
CoCa3D 聚焦在核心思想是引入多体协作来提高纯视觉的 3D 目标检测能力。同时,优化了通信成本,每个协作者都仔细选择空间稀疏但关键的消息进行共享。相关技术方法将 AI 和通信技术高度整合,对车路协同,无人集群等群体智能应用有着深刻影响。在未来,也期待这种思路可以被更广泛应用于高效提升单体的各类型能力,将协作感知拓展到协作自动系统,全方位地提升单体智能。
我好像记得Lua有类似Ruby的method_missing的东西。还是我记错了? 最佳答案 表的metatable的__index和__newindex可以用于与Ruby的method_missing相同的效果。 关于ruby-难道Lua没有和Ruby的method_missing相媲美的东西吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7732154/
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion是否有适用于这些的3d游戏引擎?
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
我是Ruby和Watir-Webdriver的新手。我有一套用VBScript编写的站点自动化程序,我想将其转换为Ruby/Watir,因为我现在必须支持Firefox。我发现我真的很喜欢Ruby,而且我正在研究Watir,但我已经花了一周时间试图让Webdriver显示我的登录屏幕。该站点以带有“我同意”区域的“警告屏幕”开头。用户点击我同意并显示登录屏幕。我需要单击该区域以显示登录屏幕(这是同一页面,实际上是一个表单,只是隐藏了)。我整天都在用VBScript这样做:objExplorer.Document.GetElementsByTagName("area")(0).click
我正在使用Rails5(Ruby2.4)。我想阅读.xls文档,我想将数据转换为CSV格式,就像它出现在Excel文件中一样。有人推荐我使用Roo,所以我有book=Roo::Spreadsheet.open(file_location)sheet=book.sheet(0)text=sheet.to_csvarr_of_arrs=CSV.parse(text)但是,返回的内容与我在电子表格中看到的内容不同。例如,电子表格中的一个单元格有16:45.81当我从上面获取CSV数据时,返回的是"0.011641319444444444"如何解析Excel文档并准确获取我所看到的内容?我不在
目录一、世界坐标系与本地坐标系二、srcGameObject.transform.TransformPoint(Vector3 vec)三、srcGameObject.transform.TransformVector(Vector3 vec)四、srcGameObject.transform.TransformDirection(Vector3 vec)五:示例一、世界坐标系与本地坐标系 世界坐标很好理解,就是模型的transform.position,通常在无父物体的情况下,创建出来的模型默认位置就是世界坐标系的原点。 每个物体都有自身的坐标系,此坐标系就是本地坐标系。本地坐标