
目录
哈夫曼树(Huffman Tree)是一种带权路径长度最短的二叉树。哈夫曼树常常用于数据压缩,其压缩效率比较高。
哈夫曼树的构建过程主要有两个步骤:(1)选取权值最小的两个节点构造新的二叉树,其权值为两个节点权值之和;(2)将新生成的节点加入到原来的节点集合中,重复执行步骤一和步骤二,直到只剩下一个节点,这个节点就是哈夫曼树的根节点。哈夫曼树的构建过程可以用贪心算法实现,构建出的哈夫曼树可以保证带权路径长度最短。
树的带权路径长度(weighted path length)是指树中所有叶子节点深度乘以它们对应的权值之和。对于一棵有n个叶子节点的树,其带权路径长度为:
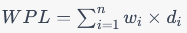
权路径长度是一种衡量树结构紧密程度的指标,一棵紧密结构的树的带权路径长度通常比较小,相对来说能够更好地利用树的结构进行数据压缩等操作。在哈夫曼编码中,带权路径长度是一个重要的概念,因为哈夫曼编码的目的就是要最小化树的带权路径长度,以达到最优编码的效果。
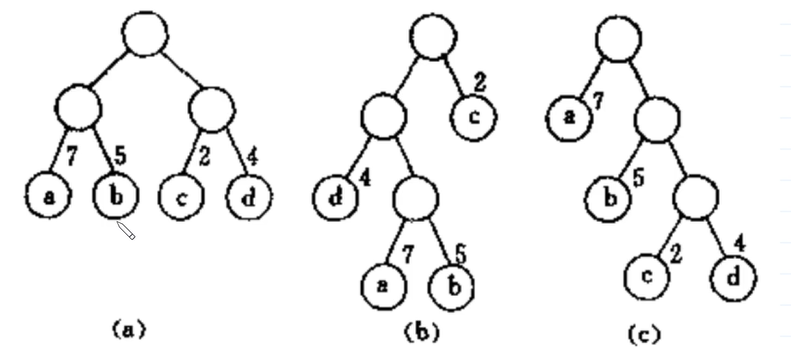
(a) wpl : 7 * 2 + 5 * 2 + 2 * 2 + 4 * 2 = 36
(b) wpl : 7 * 3 + 5 * 3 + 2 * 1 + 4 * 2 = 46
(c) wpl : 7 * 1 + 5 * 2 + 2 * 3 + 4 * 3 = 35
哈夫曼编码(Huffman coding)是一种可变长度编码(variable-length encoding)方法,是一种最优编码,用于无损数据压缩。该方法的核心思想是,将出现频率较高的字符用较短的编码表示,出现频率较低的字符用较长的编码表示,以达到压缩数据的目的。
哈夫曼编码的实现过程可以分为两个阶段:
(1)建立哈夫曼树。将输入字符串中每个字符出现的频率作为权重,构建一个哈夫曼树,使得出现频率较高的字符对应的节点在哈夫曼树的深度较浅,出现频率较低的字符对应的节点在哈夫曼树的深度较深。哈夫曼树的叶子节点对应输入字符串中的每个字符,从根节点到叶子节点的路径上的边表示该字符的编码。
(2)对输入字符串进行编码。根据哈夫曼树的构建结果,生成每个字符的编码,并将输入字符串中每个字符替换为其对应的编码,得到压缩后的字符串。
由于哈夫曼编码是一种最优编码方法,因此它具有以下优点:
(1)压缩率高。使用哈夫曼编码进行压缩可以达到很高的压缩率,特别是对于包含大量重复字符的文本文件,哈夫曼编码的效果更加明显。
(2)无损压缩。哈夫曼编码是一种无损压缩方法,压缩后的数据可以完全恢复为原始数据。
(3)可逆性好。哈夫曼编码的编码和解码过程都可以通过哈夫曼树实现,因此哈夫曼编码具有很好的可逆性。
例如我们给定原文 A B A C C D A,使其变成二进制存储,我们就可以使用等长的编码方式,A:00 B:01 C:10 D:11,那么我们的原文就可以转换成00010010101100,len=14.所以我们想要缩短长度的话就需要用另一种编码方式,那就是让出现次数多的字母对应更短的二进制数,如A出现了三次,所以A:0 C出现了两次,所以C:1,那么B:00,D:01,这样原文就可以转换成000011010,len=9,但这样的缺点就是0000可以是AAAA,也可以是BB等多种情况。
所以我们就可以使用哈夫曼编码,也就是最优无前缀编码。
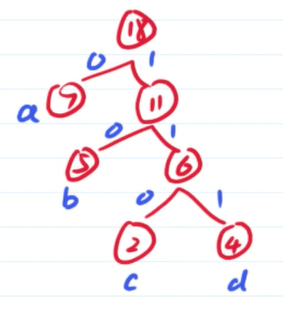
通过这个哈夫曼树得到A:0 B:10 C:110 D:111,原文也就转换成了01001101101110,len= 14。
class HuffmanNode implements Comparable<HuffmanNode> {
public int value; // 节点的值
public int frequency; // 节点出现的次数
public HuffmanNode left; // 左子节点
public HuffmanNode right; // 右子节点
public HuffmanNode(int value, int frequency) {
this.value = value;
this.frequency = frequency;
}
// 按照频率从小到大排序
@Override
public int compareTo(HuffmanNode o) {
return this.frequency - o.frequency;
}
}import java.util.PriorityQueue;
public class HuffmanTree {
// 构建哈夫曼树
public static HuffmanNode buildHuffmanTree(int[] frequencies) {
PriorityQueue<HuffmanNode> queue = new PriorityQueue<>();
// 将所有出现的数字及其频率作为叶子节点加入到优先队列中
for (int i = 0; i < frequencies.length; i++) {
if (frequencies[i] > 0) {
queue.offer(new HuffmanNode(i, frequencies[i]));
}
}
// 构建哈夫曼树
while (queue.size() > 1) {
HuffmanNode left = queue.poll();
HuffmanNode right = queue.poll();
HuffmanNode parent = new HuffmanNode(-1, left.frequency + right.frequency);
parent.left = left;
parent.right = right;
queue.offer(parent);
}
// 返回哈夫曼树的根节点
return queue.poll();
}
public static void main(String[] args) {
int[] frequencies = new int[]{3, 2, 1, 4, 5, 6};
HuffmanNode root = buildHuffmanTree(frequencies);
// do something with the root node of the Huffman tree
}
}字典树(Trie树),也称为前缀树(Prefix Tree),是一种用于高效存储和检索字符串的树形数据结构。它的基本思想是利用字符串的公共前缀,将具有相同前缀的字符串存储在一起,从而达到节省空间、提高查询效率的目的。
字典树的每个节点都表示一个字符,从根节点开始到某个节点路径上的所有字符连接起来,就构成了从根节点到该节点所表示的字符串。每个节点还包含一个计数器,用于记录以该节点结尾的字符串的个数。
在字典树中,每个节点最多有26个子节点,对应着26个小写字母。为了实现高效的字符串检索,字典树通常是按照字典序排序的,即每个节点的子节点按照字母顺序排列。
字典树的主要优点是可以在O(m)的时间复杂度内(m为待查字符串的长度),完成字符串的检索操作,比其他数据结构如哈希表等具有更高的效率。同时,字典树还可以支持前缀匹配查询和自动补全功能,因此在搜索引擎、输入法、单词拼写检查等应用中广泛使用。
字典树(Trie 树)是一种特殊的树型数据结构,用于快速检索和查找字符串集合中的单词或前缀。它的执行流程如下:
(1)初始化字典树,创建一个根节点,根节点不包含任何值。
(2)将所有的字符串依次插入到字典树中。对于每个字符串,从根节点开始,依次遍历字符串中的每个字符。如果该字符对应的节点已经存在,则直接向下遍历;否则,创建一个新节点,并将该节点作为当前节点的子节点。重复该过程,直到遍历完整个字符串。
(3)在字典树中查找指定的单词或前缀。从根节点开始,依次遍历待查找的单词或前缀中的每个字符,如果存在当前字符对应的节点,则向下遍历;否则,直接返回空。
(4)如果是查找单词,则需要判断查找到的最后一个节点是否为一个单词的结束节点。如果是,则说明该单词存在于字典树中;否则,不存在。
(5)如果是查找前缀,则不需要判断最后一个节点是否为一个单词的结束节点,只需要返回查找到的最后一个节点的子树中所有单词即可。
字典树的优点是可以快速的插入、查找和删除字符串集合中的单词,时间复杂度为 O(m),其中 m 为单词的长度。但是它的缺点是会消耗大量的存储空间,因为每个节点都需要存储一个字符和若干个指针,如果字符串集合中的单词数量较多,则会占用大量的存储空间。
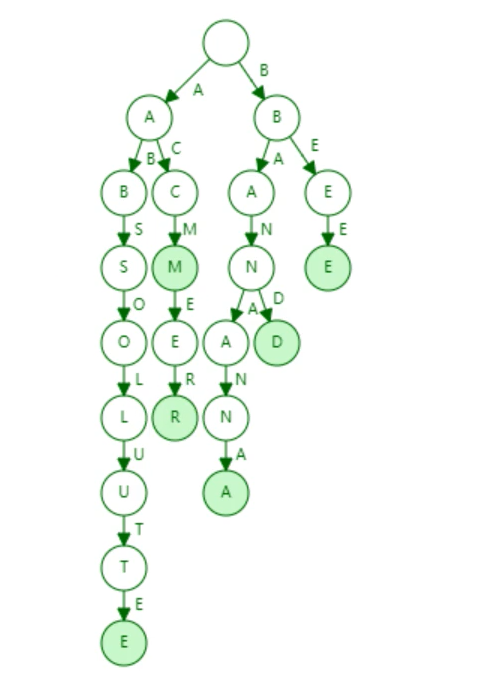
例如下图中已经出现过一遍的字母就会被存到字典树中,在下次遇到时就不会从新创建,加快了存储时间,但会占用较大的空间。
public class TrieNode {
char value;//当前节点存储的字符
int num;//有多少个单词经过了当前这个字符,从当前到根就是这num个单词的前缀
TrieNode[] son;//所有叶子存放在一个对象数组里,默认为26叉,因为只有26个英文字母
boolean isword;//是否构成一个完整的单词,如acm acmer
public TrieNode() {
num = 1;//至少有一个字符是经过本身的
isword = false;//默认为false
son = new TrieNode[26];//26个英文单词
}
}public class TrieTree {
public static void main(String[] args) {
TrieTree trieNode = new TrieTree();
String[] strs = {"banana","band","bee","absolute","acm","acmer"};
String[] prefix = {"ba","b","band","abc","acm"};
for (String str : strs) trieNode.insertTrieTree(str);
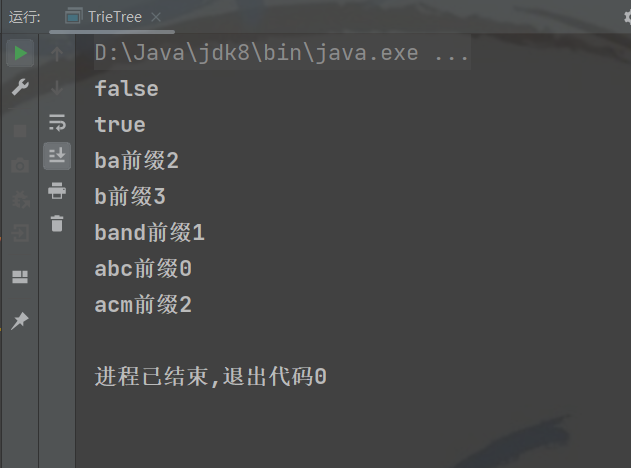
System.out.println(trieNode.isContains("abc"));
System.out.println(trieNode.isContains("acm"));
for (String str : prefix) System.out.printf("%s前缀%d\n",str,trieNode.getPreFixNum(str));
}
TrieNode root = new TrieNode();//字典树的根
//建树的过程就是不断的往字典树里插入单词
public void insertTrieTree(String s) {
if (s == null || s.length() == 0) return;//空串直接返回
TrieNode node = root;//获取根节点,因为在插入的时候根节点是变化的
char[] words = s.toCharArray();//得到字符数组给words
for (int i = 0; i < words.length; i++) {
int distance = words[i] - 'a';//计算当前字符是当前根的第多少个孩子,所以要-'a'
if (node.son[distance] == null) {//当当前字符不存在时候
node.son[distance] = new TrieNode();
node.son[distance].value = words[i];
} else {
node.son[distance].num++;//经过当前字符的次数++
}
node = node.son[distance];//已经存储了,那么根就要做变化
}
node.isword = true;//当最后一个字符存储完毕后,这个字符就变成了一个完整的字符了
}
//给定单词,查找是否在字典树中
public boolean isContains(String s) {
if (s == null ||s.length() == 0) return false;//空串直接返回false
TrieNode node = root;//获取根节点,因为在插入的时候根节点是变化的
char[] words = s.toCharArray();//得到字符数组给words
for (int i = 0; i < words.length; i++) {
int distance = words[i] - 'a';//计算当前字符是当前根的第多少个孩子,所以要-'a'
if (node.son[distance] != null) node = node.son[distance];//继续往下再找
else return false;
}
return node.isword;//返回是否构成完整的单词
}
//给定前缀返回有多少个单词以它作为前缀
public int getPreFixNum(String prefix) {
if (prefix == null ||prefix.length() == 0) return 0;//空串直接返回false
TrieNode node = root;//获取根节点,因为在插入的时候根节点是变化的
char[] words = prefix.toCharArray();//得到字符数组给words
for (int i = 0; i < words.length; i++) {
int distance = words[i] - 'a';//计算当前字符是当前根的第多少个孩子,所以要-'a'
if (node.son[distance] != null) node = node.son[distance];//继续往下再找
else return 0;
}
return node.num;//返回多少个单词经过当前这个字符的个数
}
}得到abc不在字典树中,acm在字典树中。以及以ba、b、band、abc、acm做前缀的单词个数

我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我正在尝试在Ruby中复制Convert.ToBase64String()行为。这是我的C#代码:varsha1=newSHA1CryptoServiceProvider();varpasswordBytes=Encoding.UTF8.GetBytes("password");varpasswordHash=sha1.ComputeHash(passwordBytes);returnConvert.ToBase64String(passwordHash);//returns"W6ph5Mm5Pz8GgiULbPgzG37mj9g="当我在Ruby中尝试同样的事情时,我得到了相同sha
前言一般来说,前端根据后台返回code码展示对应内容只需要在前台判断code值展示对应的内容即可,但要是匹配的code码比较多或者多个页面用到时,为了便于后期维护,后台就会使用字典表让前端匹配,下面我将在微信小程序中通过wxs的方法实现这个操作。为什么要使用wxs?{{method(a,b)}}可以看到,上述代码是一个调用方法传值的操作,在vue中很常见,多用于数据之间的转换,但由于微信小程序诸多限制的原因,你并不能优雅的这样操作,可能有人会说,为什么不用if判断实现呢?但是if判断的局限性在于如果存在数据量过大时,大量重复性操作和if判断会让你的代码显得异常冗余。wxswxs相当于是一个独立
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
查看Ruby代码,它具有以下proc_arity:staticVALUEproc_arity(VALUEself){intarity=rb_proc_arity(self);returnINT2FIX(arity);}更多的是C编码风格问题,但为什么staticVALUE在单独的一行而不是像这样的:staticVALUEproc_arity(VALUEself) 最佳答案 它来自UNIX世界,因为它有助于轻松grep函数的定义:$grep-n'^proc_arity'*.c或使用vim:/^proc_arity
我创建了一个由于“在运行时执行的单例元类定义”而无法编码的对象(这段代码的描述是否正确?)。这是通过以下代码执行的:#defineclassXthatmyusesingletonclassmetaprogrammingfeatures#throughcallofmethod:break_marshalling!classXdefbreak_marshalling!meta_class=class我该怎么做才能使对象编码正确?是否可以从对象instance_of_x的classX中“移除”单例组件?我真的需要一个建议,因为我们的一些对象需要通过Marshal.dump序列化机制进行缓存。
我在使用Ruby1.9.2p290更改文本文件的编码时遇到问题。我收到错误消息invalidbytesequenceinUTF-8(ArgumentError)。问题(我认为)在于字符集似乎是未知的。如果我执行以下操作,则从命令行:$filetest.txt我得到:Non-ISOextended-ASCIIEnglishtext,withCRLFlineterminators或者,或者,如果我这样做:$file-itest.txt我得到:test.txt:text/plain;charset=unknown但是,如果我这样做,在Ruby中:data=File.open("test.tx
我正在向我的Controller发送一个base64图像并按原样保存它。现在我需要显示该图像。这是我要显示的内容,但未显示图像:"/>为了编码,我使用了这个java脚本函数encodeURIComponent();我的编码图像格式:data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/........ 最佳答案 你不需要解码base64应该可以 关于ruby-on-rails-在rails中显示base64编码的图像,我们在StackOve
我正在处理一些作为Ruby哈希字符串返回的命令输出。(来自名为mcollective的东西)。这是我收到的示例字符串:{:changes=>{"total"=>0},:events=>{"failure"=>0,"success"=>0,"total"=>0},:version=>{"puppet"=>"2.7.21(PuppetEnterprise2.8.1)","config"=>1381497648},:time=>{"filebucket"=>0.000287,"cron"=>0.00212,"package"=>0.398982,"exec"=>0.001314,"confi