若依框架
# 进入项目目录
cd ruoyi-ui
# 安装依赖
npm install
# 强烈建议不要用直接使用 cnpm 安装,会有各种诡异的 bug,可以通过重新指定 registry 来解决 npm 安装速度慢的问题。
npm install --registry=https://registry.npmmirror.com
# 本地开发 启动项目
npm run dev
创建数据库ry-vue,导入ry_2021xxxx.sql,quartz.sql,加载好依赖直接启动。
后端技术
SpringBoot
Spring Security
JWT
MyBatis
Druid
Fastjson
- 分页实现
- 导入导出
- 上传下载(框架使用的简单,不做讲解)
- 权限控制
- 事务管理(这里使用@Transactional,不做讲解,具体和Spring的8种事务有关)
- 异常处理
- 系统日志
- 数据权限
- 多数据源
- 定时任务
- 系统接口(系统接口采用swagger2来生成文档以及注释,很简单,不做讲解)
- 防重复提交
- 国际化支持(这个不做讲解)
根据文档,对于每个list的方法,采用startPage()实现分页,该方法为BaseController(基础控制类)的一个方法。startPage()方法使用了TableSupport获取请求中的对应的分页参数
(注意resonable为合理化查询参数,当请求pageNum>maxpageNum,page为最后一页,当pageNum<0,page为第一页)
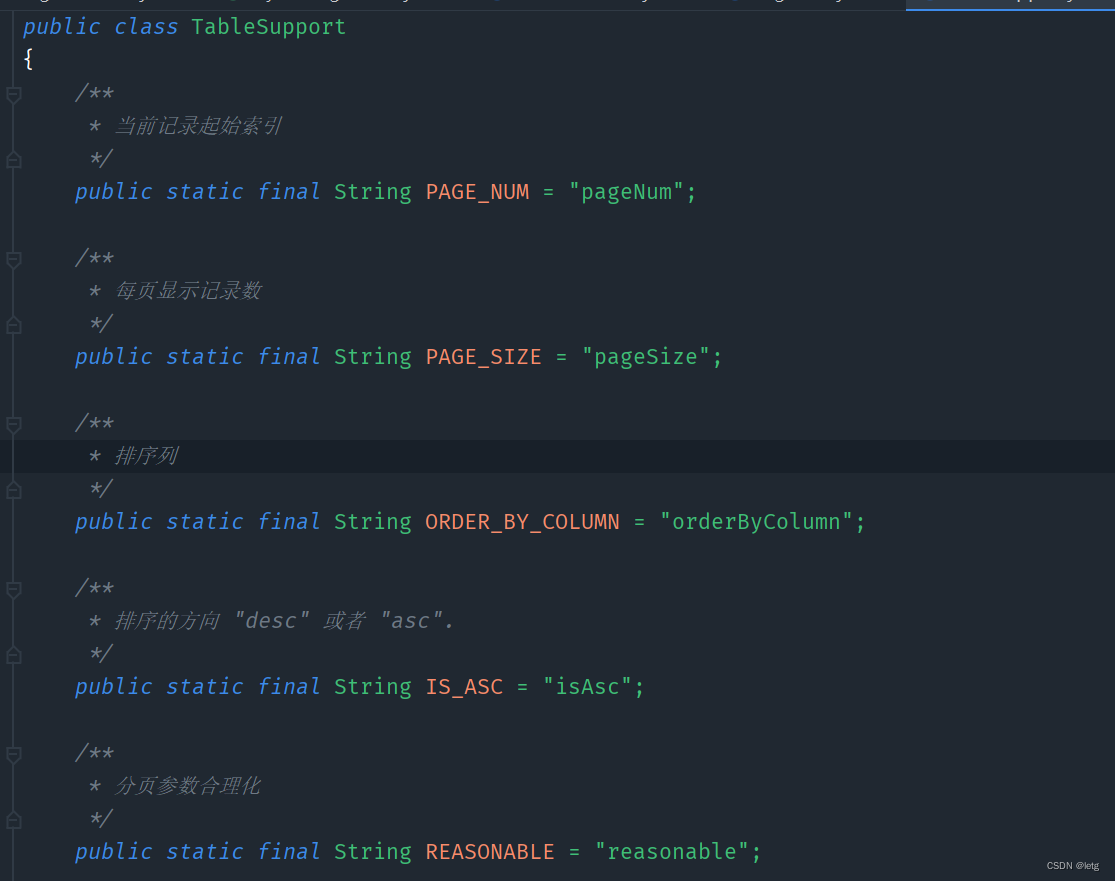
PageHelper只对最近的sql起作用,分页条件消费一次就消失,所有使用startPage()方法要紧跟着分页的方法,并且只要使用了startPage()方法就必须有分页方法,否则会使其他线程的方法莫名奇妙的分页。
excel是对org.apache.poi.xssf.usermodel进行封装实现的excel的导入导出功能。
在ExcelUtil中的exportExceL()方法中,init()方法对参数进行初始化,init的方法中初始化了很多参数,例如实体的Workbook、Fields等,Fields主要用于后面获取@Excel注解然后进行获取注解中的内容绘制Excel,然后使用Workbook对象进行数据的Excel导出。
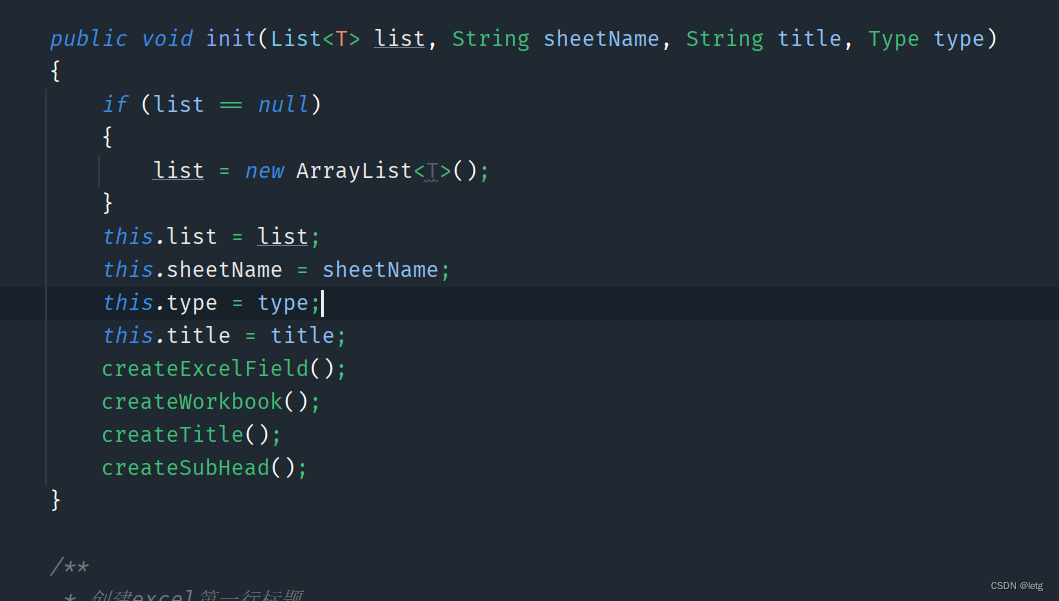
ExcelUtil的importExcel(String sheetName, InputStream is, int titleNum)方法中进行了解解析Excel表的操作,并且将导入的数据对照的着实体做了一个类型的转换,最后返回一个list集合。
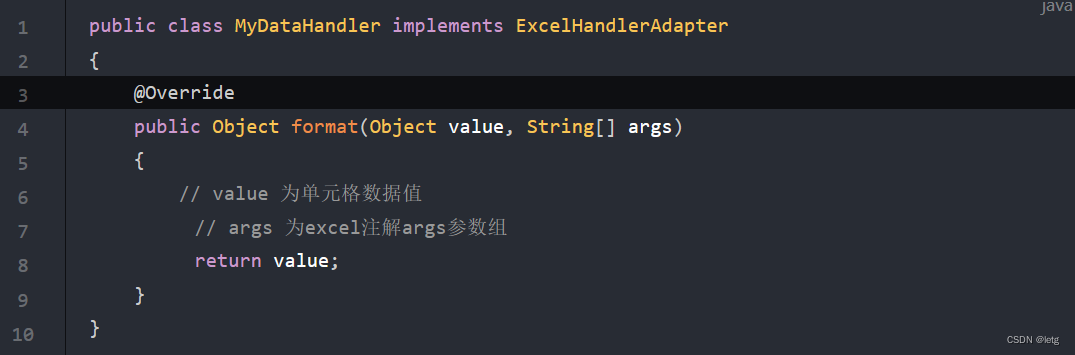
- 如果我们想对数据进行额外处理,需要配置字段的@Excel中的参数hanlder,需要继承ExcelHandlerAdapter实现format方法。该方法会在导出的时候使用dataFormatHandlerAdapter(val, attr)通过反射对数据进行最后的处理。
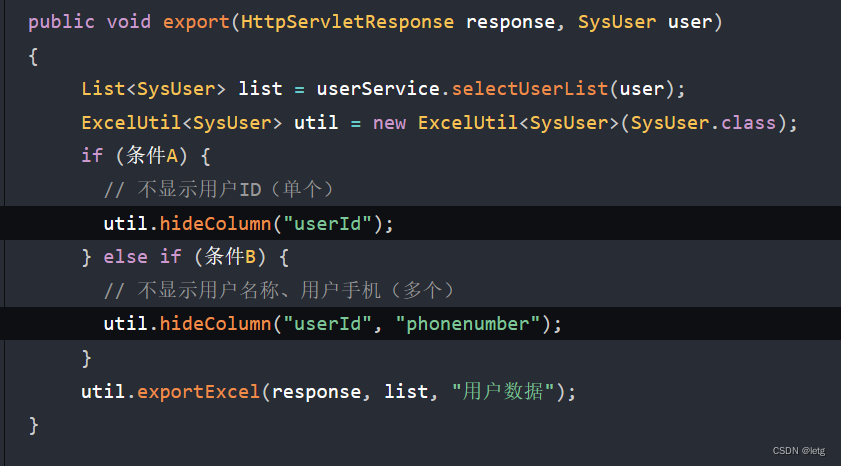
自定义隐藏列通过excludeFields数组来进行控制,在List<Object[]> getFields获取字段信息的时候将通过excludeFields来进行字段排除,使用hideColumn(“userId”)方法来隐藏,使用方法如下。
上传下载功能位于CommonController,这个很简单不做讲解。
根据文档所述,若依采用shiro的注解来控制权限,采用的是RBAC角色权限控制模型,但实际上看了源码(可能文档不一致),它采用的是springSecurity的PreAuthorize注解来实现。但是他的角色权限控制是处于一个静态的,无法动态控制某个方法需要哪些权限。
@PreAuthorize("@ss.hasPermi('system:dept:list')")
@GetMapping("/list")
public AjaxResult list(SysDept dept)
{
List<SysDept> depts = deptService.selectDeptList(dept);
return success(depts);
}
- 解析
ss为spring容器中的PermissionService,它为一个实例化的Bean,我们可以自定义权限的实现,若依框架自定义的权限在com.ruoyi.framework.web.service.PermissionService下,需要实现hasPermi()方法,同样的其他方法也能使用,只需要在注解中标注@ss.hasPermi(‘system:dept:list’),hasPermi可以替代为其他方法,参数为括号中的内容。
异常处理使用的@ControllerAdvice,对于异常,我们不需要在业务层捕捉异常,统一抛出给控制层。这个没有做封装,比较简单。
参数验证使用的是spring boot的Validated,只需要在请求的参数加上@Validated注解,对应的实体的字段上加上对应的验证注解。具体查询 所有的验证注解
我们可以进行自定义验证,若依自定义了XSS跨站脚本验证的注解XSS,注解@Constraint(validatedBy = { XssValidator.class }),指定验证的类。
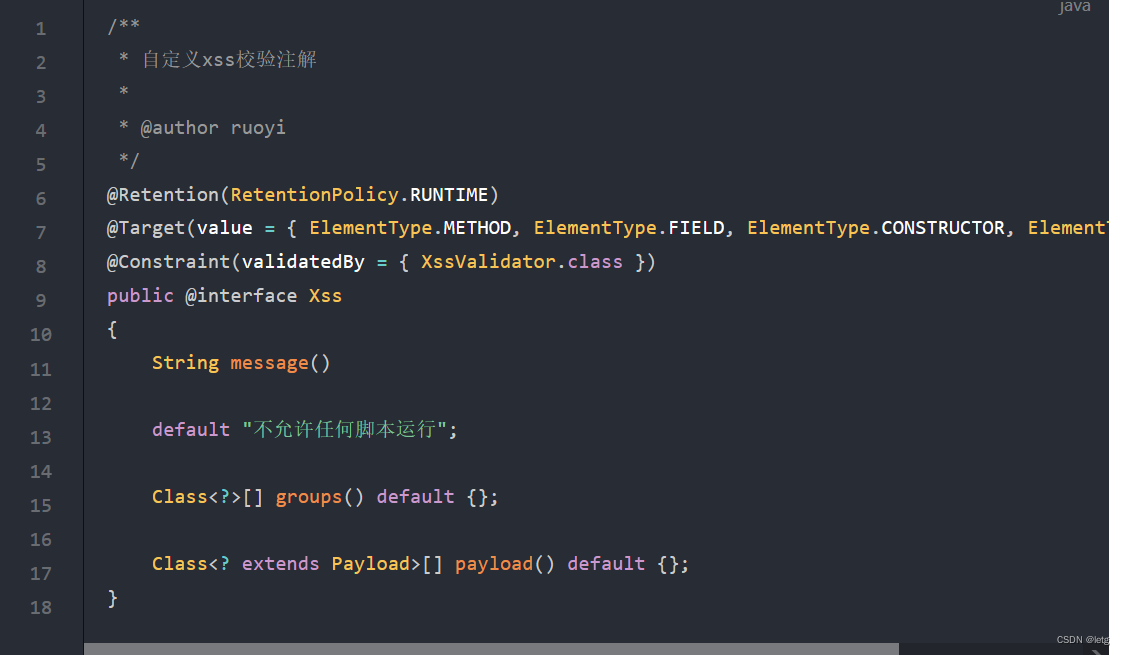
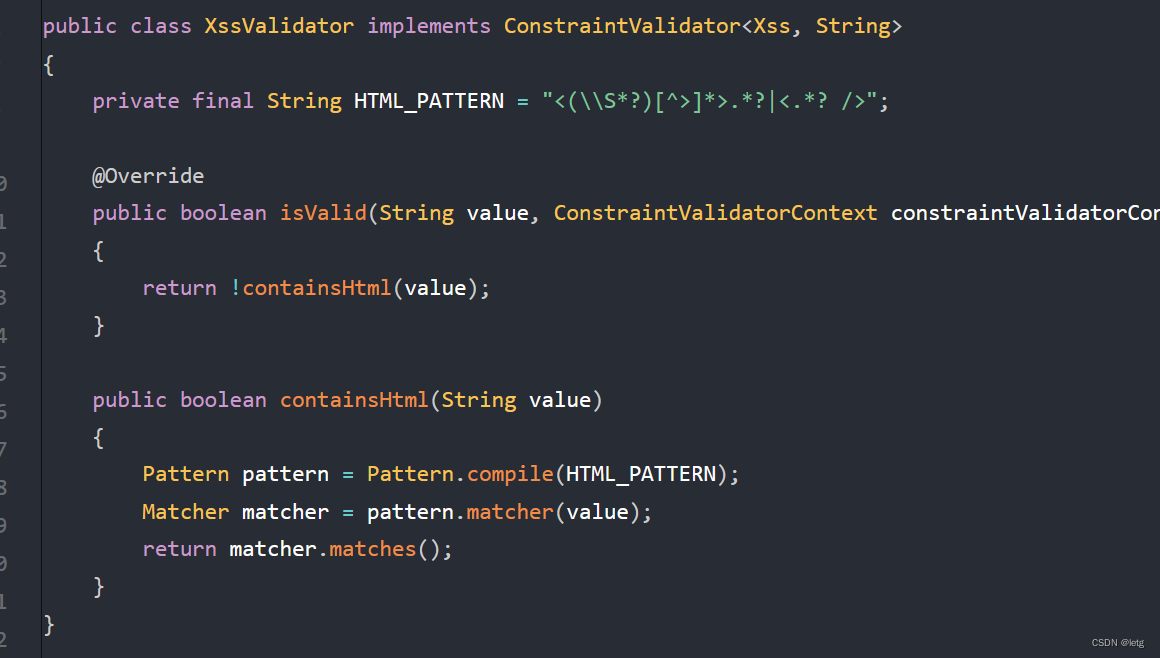
对于系统日志,若依采用的是自定@Log注解结合Aop进行实现,Log注解类在
com.ruoyi.common.annotation.Log,对应的Aop切面类在
com.ruoyi.framework.aspectj.LogAspect。系统采用了两个方式进行切面日志的实现,第一种为AfterReturning(返回前方法增强),第二种为AfterThrowing(抛出异常前方法增强)。系统的日志的实体为com.ruoyi.system.domainSysOperLog
具体实现在handleLog(final JoinPoint joinPoint, Log controllerLog, final Exception e, Object jsonResult)方法中,具体日志里处理的就是日志实体所需的参数,除了注解中的参数外,还有ip、用户、请求方式以及路径等,这个很简单不做讲解。
数据权限主要是为了一些敏感数据不能跨部门访问,admin为默认角色拥有所有数据权限,注解为@DataScope(deptAlias = “d”),切面类为com.ruoyi.framework.aspectj.DataScopeAspect。
数据过滤的方法在dataScopeFilter(JoinPoint joinPoint, SysUser user, String deptAlias, String userAlias, String permission),根据文档知道数据过滤主要是通过注入BaseEntity一个过滤sql,然后在mapper.xml将sql以参数的方式进行拼接完成数据过滤。(前提是过滤的数据的实体需要继承BaseEntity)

多数据源主要采用的是Aop,使用的是自定义的@DataSource注解。value用来表示数据源名称。
# 从库数据源
slave:
# 从数据源开关/默认关闭
enabled: true
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: password
/**
* 从库
*/
SLAVE
此操作会将yaml中的数据源的数据读取到DruidProperties,完成数据源的属性注入。
@Bean
@ConfigurationProperties("spring.datasource.druid.slave")
@ConditionalOnProperty(prefix = "spring.datasource.druid.slave", name = "enabled", havingValue = "true")
public DataSource slaveDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
setDataSource(targetDataSources, DataSourceType.SLAVE.name(), "slaveDataSource");
- 具体实现在com.ruoyi.framework.aspectj.DataSourceAspect中,这使用的是一个环绕增强,通过一个动态的数据源上下文对象DynamicDataSourceContextHolder去设置数据源的bean的名字,具体通过ThreadLocal完成参数的传递,并且使用完需要移除ThreadLocal中的值避免内存泄漏。
- 最核心的实现是位于com.ruoyi.framework.datasource.DynamicDataSource,它继承了Springboot的AbstractRoutingDataSource,需要设置defaultTargetDataSource和targetDataSources,这个实现类是在DruidConfig中进行初始化,在请求进来时,会根据determineCurrentLookupKey()这个方法区去获取数据源的bean名字来获取数据源。
public Connection getConnection() throws SQLException {
return this.determineTargetDataSource().getConnection();
}
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = this.determineCurrentLookupKey();
DataSource dataSource = (DataSource)this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
} else {
return dataSource;
}
}
这是一段AbstractRoutingDataSource中的连接代码,在连接会使用determineCurrentLookupKey()从resolvedDataSources容器中获取数据源。
定时任务底层采用的是quartz。任务实体为com.ruoyi.quartz.domain.SysJob,这个实体主要的字段有invokeTarget以及cronExpression来控制执行内容和时间。定时任务工具类在com.ruoyi.quartz.util.ScheduleUtils
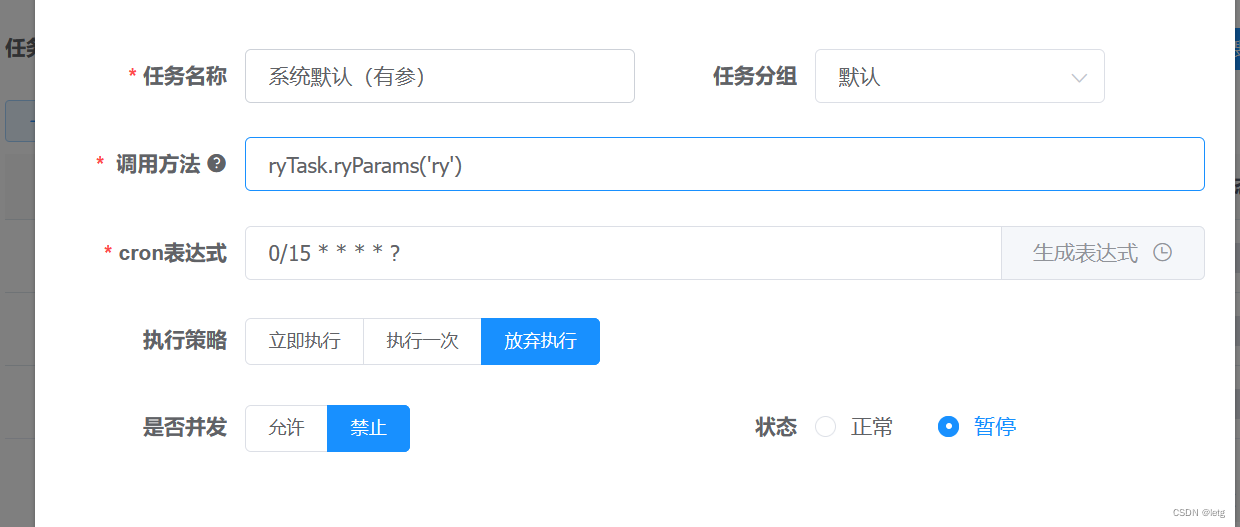
调用方法为Component指定名称,指定方法和参数。然后使用cron表达式确定定时的时间。具体的cron表达式可以看
cron表达式
- 新增定时任务首先会判断定时任务的执行表达式以及cron表达式,创建定时任务首先判断是否并发执行,选择合适的执行对象Job。QuartzJobExecution为并发执行的对象,QuartzDisallowConcurrentExecution相反。
- 传入定时任务的一些组和id以及执行类对象构造表达式调度构建器对象,实际上所有的定时任务是通过表达式调度对象scheduler来调度所有任务。
- scheduler为调度对象,里面有调度资源对象QuartzSchedulerResources来控制所有的任务资源,例如pauseJob方法,会使用this.notifySchedulerThread()来唤起定时任务线程,this.notifySchedulerListenersPausedJob()来唤醒监听器来停止任务。
- 在添加调度任务,底层会使用
this.resources.getJobStore().storeJobAndTrigger(jobDetail, trig);进行调度资源的添加,同样会唤起线程和监听器来监听执行任务。定时任务调度对象的具体实现类在org.quartz.core.QuartzScheduler,父接口为org.quartz.core.RemotableQuartzScheduler
防重复提交的实现在com.ruoyi.framework.interceptor.RepeatSubmitInterceptor下,是通过使用拦截器,获取执行方法的方法注解@RepeatSubmit,注解通过提交的间隔时间来进行判断重复提交
- 具体实现的方法在isRepeatSubmit(HttpServletRequest request, RepeatSubmit annotation)中,RepeatedlyRequestWrapper是为了设置请求和响应的编解码格式为UTF-8。
- 首先这个方法将请求的数据以字符串的形式获取,这里做了不同请求参数的获取处理,通过指定key + url + 消息头来拼成字符串组成key,使用map为value,map为url->datamap的结构,当key不存在时,则为新的请求数据,若不存在,则证明上一次存在相同方式的数据,则对数据以及请求的间隔时间进行判断。
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的