 改进后的视觉服务使开发商能够在不同行业创建前沿的、适应市场的、负责任的计算机视觉应用程序。客户可以将他们的数据无缝地数字化、分析并连接到自然语言的交互中,从图像和视频内容中获取更精确的信息,保护用户远离有害内容,增强安全性,并提升事件响应速度。Florence的实际能力也很强大,用户可以在Vision Studio中进行「开箱即用」的体验。
改进后的视觉服务使开发商能够在不同行业创建前沿的、适应市场的、负责任的计算机视觉应用程序。客户可以将他们的数据无缝地数字化、分析并连接到自然语言的交互中,从图像和视频内容中获取更精确的信息,保护用户远离有害内容,增强安全性,并提升事件响应速度。Florence的实际能力也很强大,用户可以在Vision Studio中进行「开箱即用」的体验。 体验网址:https://portal.vision.cognitive.azure.com/gallery/featured具体包括:Dense Captions(详细的描述):可以自动提供内容丰富的描述信息、设计建议、可访问的替代文本、搜索引擎优化、智能照片管理等以支持数字化内容。图像检索:使用自然语言查询,无缝地度量图像和文本之间的相似性,从而改进搜索推荐和广告。背景去除:可以方便地从原始背景中分割出人物和物体,并替换为其他背景场景,从而改变图像的外观和感觉。模型定制:降低交付定制模型的成本和时间,能够以更高精度来匹配独特的业务需求,即便只有少量的可用图像。视频摘要:搜索和交互视频内容,与人类同样直观的方式进行思考和写作。可以帮助找到相关内容,并且不需要额外的元数据。RedditReddit消费品产品经理Tiffany Ong表示,通过微软的Vision技术,可以使用户更容易发现和理解Reddit上的内容。新创建的图片描述可以让用户更容易地访问Reddit,使用图像描述来帮助用户提高文章的搜索结果,让Reddit用户有更多机会来探索网站上的图片,参与对话,并最终建立联系和社区感知。Florence能够为每张图片生成多达10000个标签,使得Reddit能够更好地控制图片中的物体数量,并帮助生成更好的图像描述。Microsoft 365除了微软数据中心之外,微软也正在提升Microsoft 365应用程序(包括 Teams、 PowerPoint、 Outlook、 Word、 Designer、 OneDrive)中视觉服务的能力。在图像分割能力的帮助下,Teams正在推动数字空间的创新型,把虚拟会议的体验提升到新高度。PowerPoint、 Outlook和Word利用自动替换文本的图像描述来提高可访问性。Microsoft Designer和OneDrive正在使用改进的图像描述、图像搜索和背景生成来简化图像的可发现性和编辑。Microsoft数据中心正在利用Vision Services来增强安全性和基础设施的可靠性。LinkedInLinkedIn的无障碍工程负责人Jennison Asuncon表示,LinkedIn上有超过40%的帖子中包含至少一张图片,对于盲人或是低视力的用户来说,视觉服务能够让所有用户都有平等的阅读机会,并使他们能够参与到在线对话中。
体验网址:https://portal.vision.cognitive.azure.com/gallery/featured具体包括:Dense Captions(详细的描述):可以自动提供内容丰富的描述信息、设计建议、可访问的替代文本、搜索引擎优化、智能照片管理等以支持数字化内容。图像检索:使用自然语言查询,无缝地度量图像和文本之间的相似性,从而改进搜索推荐和广告。背景去除:可以方便地从原始背景中分割出人物和物体,并替换为其他背景场景,从而改变图像的外观和感觉。模型定制:降低交付定制模型的成本和时间,能够以更高精度来匹配独特的业务需求,即便只有少量的可用图像。视频摘要:搜索和交互视频内容,与人类同样直观的方式进行思考和写作。可以帮助找到相关内容,并且不需要额外的元数据。RedditReddit消费品产品经理Tiffany Ong表示,通过微软的Vision技术,可以使用户更容易发现和理解Reddit上的内容。新创建的图片描述可以让用户更容易地访问Reddit,使用图像描述来帮助用户提高文章的搜索结果,让Reddit用户有更多机会来探索网站上的图片,参与对话,并最终建立联系和社区感知。Florence能够为每张图片生成多达10000个标签,使得Reddit能够更好地控制图片中的物体数量,并帮助生成更好的图像描述。Microsoft 365除了微软数据中心之外,微软也正在提升Microsoft 365应用程序(包括 Teams、 PowerPoint、 Outlook、 Word、 Designer、 OneDrive)中视觉服务的能力。在图像分割能力的帮助下,Teams正在推动数字空间的创新型,把虚拟会议的体验提升到新高度。PowerPoint、 Outlook和Word利用自动替换文本的图像描述来提高可访问性。Microsoft Designer和OneDrive正在使用改进的图像描述、图像搜索和背景生成来简化图像的可发现性和编辑。Microsoft数据中心正在利用Vision Services来增强安全性和基础设施的可靠性。LinkedInLinkedIn的无障碍工程负责人Jennison Asuncon表示,LinkedIn上有超过40%的帖子中包含至少一张图片,对于盲人或是低视力的用户来说,视觉服务能够让所有用户都有平等的阅读机会,并使他们能够参与到在线对话中。 通过Azure视觉认知服务,LinkedIn可以提供自动图像描述来编辑和支持可选文本,这是一种全新的体验。不仅我对此感到兴奋,我的同事刚刚分享了一个他们参加活动的照片,LinkedIn的首席执行官Ryan Roslansky也在照片里。负责任地创新回顾负责任的人工智能原则,可以了解到微软是如何致力于开发人工智能系统,以提升世界的可访问性。
通过Azure视觉认知服务,LinkedIn可以提供自动图像描述来编辑和支持可选文本,这是一种全新的体验。不仅我对此感到兴奋,我的同事刚刚分享了一个他们参加活动的照片,LinkedIn的首席执行官Ryan Roslansky也在照片里。负责任地创新回顾负责任的人工智能原则,可以了解到微软是如何致力于开发人工智能系统,以提升世界的可访问性。 微软致力于帮助各个组织充分利用人工智能,并正在大力投资于提供技术、资源和专业知识的项目,以增强那些致力于创造一个更可持续、更安全和更容易进入的世界的人的能力。
微软致力于帮助各个组织充分利用人工智能,并正在大力投资于提供技术、资源和专业知识的项目,以增强那些致力于创造一个更可持续、更安全和更容易进入的世界的人的能力。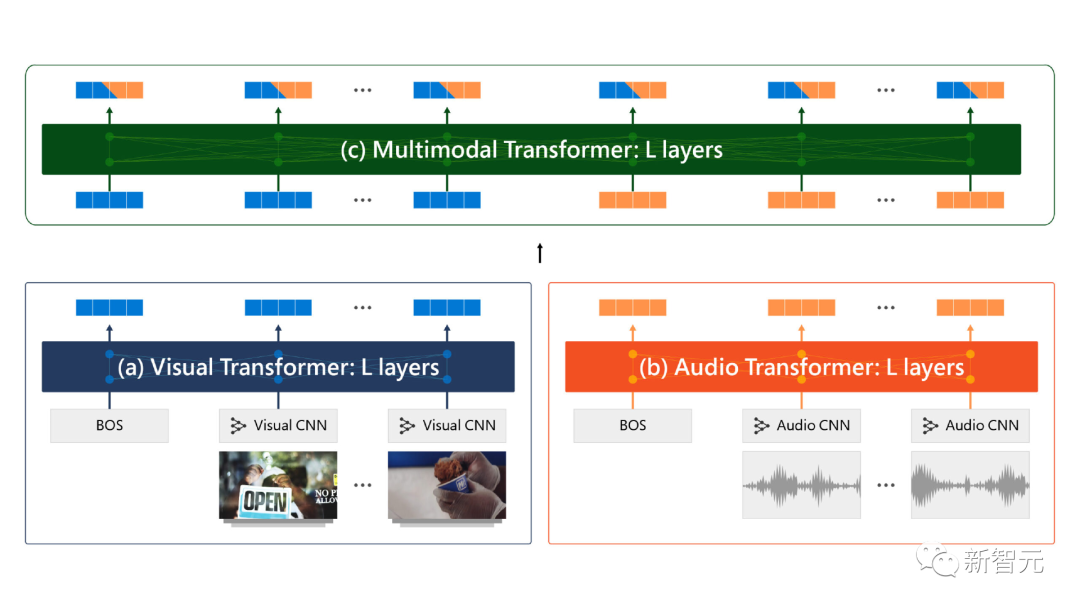 为什么不把几个「单模态」模型串在一起,以达到同样的目的,比如说用一个模型来理解图像,而另一个模型用来理解语言?第一个原因是,由其他模态提供的背景信息,多模态模型可以在某些情况下比单模态模型在同一任务中表现得更好。比如说,一个能够理解图像、定价数据和购买历史的人工智能助手可以比一个「只理解定价数据」的AI能够提供更好的个性化产品建议。并且从计算的角度来看,多模态模型往往更有效率,可以提升数据处理的速度,降低后端的成本。毫无疑问,所有商业公司都渴望降本增效。Florence能够理解图像、视频和语言以及这些模态之间的关系,从而可以做到一些单模态无法完成的任务,比如测量图像和文本之间的相似度,分割照片中的对象,然后把它们粘贴到另一个背景上。几乎所有AI模型的训练都面临数据版权问题,Azure AI的企业副总裁(CVP)John Montgomery在回答有关「Florence的训练数据」时没有透露太多信息,只是说Florence使用的是「负责任地获取」的数据源,包括来自合作伙伴的数据;此外,Montgomery表示,训练数据中删除了可能存在问题的内容,也是公开训练数据集的常见特点。
为什么不把几个「单模态」模型串在一起,以达到同样的目的,比如说用一个模型来理解图像,而另一个模型用来理解语言?第一个原因是,由其他模态提供的背景信息,多模态模型可以在某些情况下比单模态模型在同一任务中表现得更好。比如说,一个能够理解图像、定价数据和购买历史的人工智能助手可以比一个「只理解定价数据」的AI能够提供更好的个性化产品建议。并且从计算的角度来看,多模态模型往往更有效率,可以提升数据处理的速度,降低后端的成本。毫无疑问,所有商业公司都渴望降本增效。Florence能够理解图像、视频和语言以及这些模态之间的关系,从而可以做到一些单模态无法完成的任务,比如测量图像和文本之间的相似度,分割照片中的对象,然后把它们粘贴到另一个背景上。几乎所有AI模型的训练都面临数据版权问题,Azure AI的企业副总裁(CVP)John Montgomery在回答有关「Florence的训练数据」时没有透露太多信息,只是说Florence使用的是「负责任地获取」的数据源,包括来自合作伙伴的数据;此外,Montgomery表示,训练数据中删除了可能存在问题的内容,也是公开训练数据集的常见特点。 Montgomery认为,当使用大型基础模型时,最重要的是要确保训练数据集的质量,为每个视觉任务的适应模型创建基础,微软针对每个视觉任务的调整模型都经过了公平性、对抗性和挑战性案例的测试,并实现了与 Azure Open AI Service 和 DALL-E 相同的内容审核服务。在未来,消费者可以使用Florence做更多的事情,比如检测制造过程中的缺陷,以及在零售店实现自助结账。不过Montgomery指出这些用例实际上并不需要多模态视觉模型,但他断言,多模态在这个过程中可以增加一些有价值的东西。Florence是一个经过「完全重新思考」的视觉模型,一旦在图像和文本之间实现了简单且高质量的翻译过程,就会打开一个全新的、充满未知可能性的世界。客户能够体验到显著改进的图像搜索,将图像和视觉模型以及语言和语音等其它模型类型训练成全新类型的应用,并轻松提高自定义模型的质量。
Montgomery认为,当使用大型基础模型时,最重要的是要确保训练数据集的质量,为每个视觉任务的适应模型创建基础,微软针对每个视觉任务的调整模型都经过了公平性、对抗性和挑战性案例的测试,并实现了与 Azure Open AI Service 和 DALL-E 相同的内容审核服务。在未来,消费者可以使用Florence做更多的事情,比如检测制造过程中的缺陷,以及在零售店实现自助结账。不过Montgomery指出这些用例实际上并不需要多模态视觉模型,但他断言,多模态在这个过程中可以增加一些有价值的东西。Florence是一个经过「完全重新思考」的视觉模型,一旦在图像和文本之间实现了简单且高质量的翻译过程,就会打开一个全新的、充满未知可能性的世界。客户能够体验到显著改进的图像搜索,将图像和视觉模型以及语言和语音等其它模型类型训练成全新类型的应用,并轻松提高自定义模型的质量。 我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我正在尝试训练一个前馈网络来使用Ruby库AI4R执行异或运算。然而,当我在训练后评估XOR时。我没有得到正确的输出。有没有人以前使用过这个库并得到它来学习异或运算。我使用了两个输入神经元,一个隐藏层中的三个神经元,一个输出层,正如我看到的预计算XOR前馈神经网络就像这样。require"rubygems"require"ai4r"#Createthenetworkwith:#2inputs#1hiddenlayerwith3neurons#1outputsnet=Ai4r::NeuralNetwork::Backpropagation.new([2,3,1])example=[[0,
我正在使用RABL输出Sunspot/SOLR结果集,搜索结果对象由多种模型类型组成。目前在rablView中我有:objectfalsechild@search.results=>:resultsdoattribute:id,:resource,:upccodeattribute:display_description=>:descriptioncode:start_datedo|r|r.utc_start_date.to_iendcode:end_datedo|r|r.utc_end_date.to_iendendchild@search=>:statsdoattribute:to
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S
我有一个连接表create_table"combine_tags",force:truedo|t|t.integer"user_id"t.integer"habit_id"t.integer"valuation_id"t.integer"goal_id"t.integer"quantified_id"end其目的是让tag_cloud为多个模型工作。我把它放在application_controllerdeftag_cloud@tags=CombineTag.tag_counts_on(:tags)end我的tag_cloud看起来像这样:css_class%>#orthisdepen
我需要编写一个ruby脚本来连接到MSSQLServer数据库,但我发现的所有线程都指向gems以将ActiveRecord绑定(bind)到MSSQL。是否有任何gems可以让我像pg那样做这个(对于postgreshttps://github.com/ged/ruby-pg)?我只需要做一些非常简单的远程查询,非常感谢! 最佳答案 最好的方法是使用tiny_tdsgemhttps://github.com/rails-sqlserver/tiny_tds 关于ruby-微软SQL
首先让我确认这不是重复的(因为那里发布的答案没有解决我的问题)。Thispost本质上是我的确切问题:Capybara无法在Stripe模式中找到表单字段来填写它们。这是我的capybara规范:describe'checkout',type::feature,js:truedoit'checksoutcorrectly'dovisit'/'page.shouldhave_content'Amount:$20.00'page.find('#button-two').click_button'PaywithCard'Capybara.within_frame'stripe_checkou
我有一个Web应用程序,该应用程序可以通过MFA在登录策略级别(此时在用户级别禁用MFA)的B2C租户进行身份验证,并且该策略被配置为使用“用户名”来登录。该应用程序正常工作并且用户能够登录...我要完成的工作是在用户级别上拥有MFA,这意味着只有某些用户可以使用MFA,而其他用户可以在没有MFA的情况下登录。当我在用户级别打开MFA并在登录策略级别上关闭MFA时,我面临的问题是MFA在用户级别第一个密码身份验证屏幕后,重定向到多因素身份验证屏幕,要求用户将代码发送到失败。取而代之的是,它将返回第一个密码身份验证屏幕,并且似乎处于循环中。关闭两个MFA时,它可以通过密码身份验证效果很好,并且用