今日上午,值班同学发现airflow无法使用。查看时其部署的Node节点NotReady了。
马上查看K8S集群节点的状态,发现这个节点已经是NotReady状态了。第一反应就是ping下节点看是否宕机了?ping正常,于是登录到该节点查看kubelet状态。发现kubelet报runtime不可用,查看containerd的状态,一直在不断的重启,而且启动不成功。为了尽快恢复业务,决定先将containerd的数据目录清空后重新拉起。于是删除containerd数据目录下的文件夹:
# ls -lrth /xpu-k8s-data/containerd/
total 0
drwx------ 2 root root 6 Apr 28 10:54 io.containerd.snapshotter.v1.btrfs
drwx------ 3 root root 31 Apr 28 10:54 io.containerd.snapshotter.v1.aufs
drwx------ 3 root root 31 Apr 28 10:54 io.containerd.snapshotter.v1.native
drwx--x--x 2 root root 29 Apr 28 10:54 io.containerd.metadata.v1.bolt
drwx--x--x 2 root root 6 Apr 28 10:54 io.containerd.runtime.v1.linux
drwxr-xr-x 4 root root 45 Apr 28 10:54 io.containerd.content.v1.content
drwx------ 3 root root 54 Apr 28 10:54 io.containerd.snapshotter.v1.overlayfs
drwx--x--x 3 root root 28 Apr 28 10:54 io.containerd.runtime.v2.task
drwxr-xr-x 4 root root 53 Apr 28 10:55 io.containerd.grpc.v1.cri
drwx------ 2 root root 6 Apr 28 14:49 tmpmounts
# rm -rf /xpu-k8s-data/containerd/*发现执行的时间很长,超过几分钟。通过du命令统计该目录的大小也很久,我判断是这个目录下的小文件太多了。于是我ctrl+c掉rm和du命令。直接将该目录改个名字后重新创建一个目录。然后重新拉起containerd和kubelet进程后节点Ready了。pod也正常了。
然后接着再来删除之前的数据目录,执行删除后经过30min-60min才删除完成。通过rm -rfv 参数可以看到打印出来删除的文件信息,是pod中存在大量的python,go的.cache和.git的小文件。查看containerd的报错:
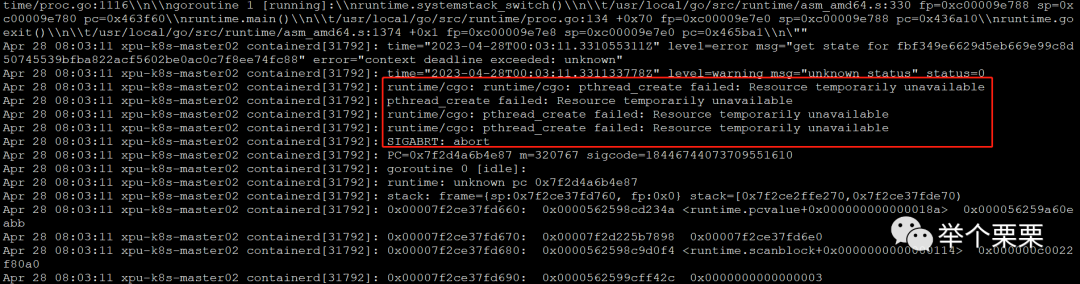
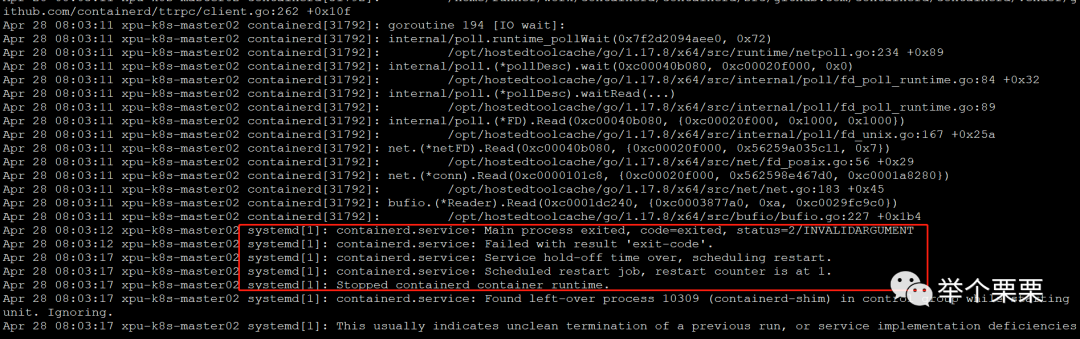
猜测是因为小文件数量过多,导致节点containerd停止后重启失败,不断重启导致节点NotReady的。
恢复一段时间后,airflow跑任务时,拉起个别的pod没有问题,但是当同时拉起几十个pod跑任务的时候有很多的pod无法启动。报如下错误:

该节点的pod网段IP地址已经用完,无法分配IP了。集群设计的时候给每个Node的子网掩码是25。可以部署125个pod。但是现在节点上的pod才十几个。猜测是之前节点故障的时候,直接删除了元数据后拉起containerd导致原来的pod在系统上的网络信息没有被删除。导致IP被占用了。我们的集群采用了flannel组件,并且开启了--kube-subnet-mgr参数。所以IP分配信息不会记录到etcd,而是直接记录到Node节点上的。
# ps -ef | grep flannel
root 6450 45116 0 14:59 pts/4 00:00:00 grep --color=auto flannel
root 53065 52700 0 13:02 ? 00:00:43 /opt/bin/flanneld --ip-masq --kube-subnet-mgrPod在Node上的网络信息主要有两点:
1)容器在Node侧的vethxxx接口;
2)容器在Node侧的IP地址;
所以,只要我们删除旧Pod的容器残留在Node上的以上网络信息应该就可以恢复了。
解决:
1)找到容器在Node侧的vethxxx接口并删除
我们知道,veth对一侧在容器里面,一侧在Node侧。通过命令ip addr可以查看到。这里我们需要找到不存在容器遗留在Node的vethxxx接口。
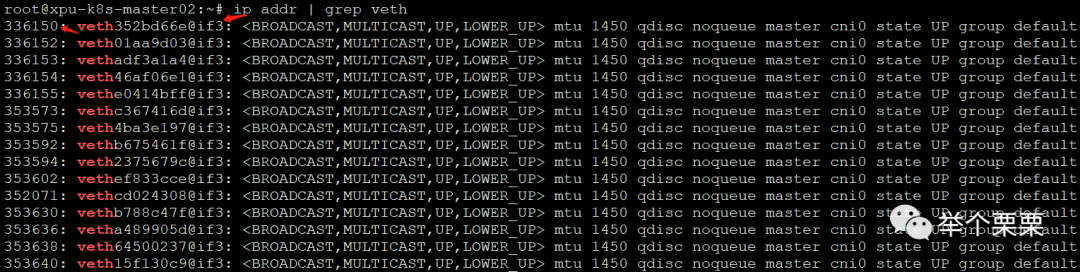
如上图所示,每个vethxxx接口都有一个Node侧的index ID(第一列数字),而vethxxx@if后面的数字3是该veth接口对应在容器侧的eth0网卡在容器内的index ID。容器和Node的veth接口对应关系如下:
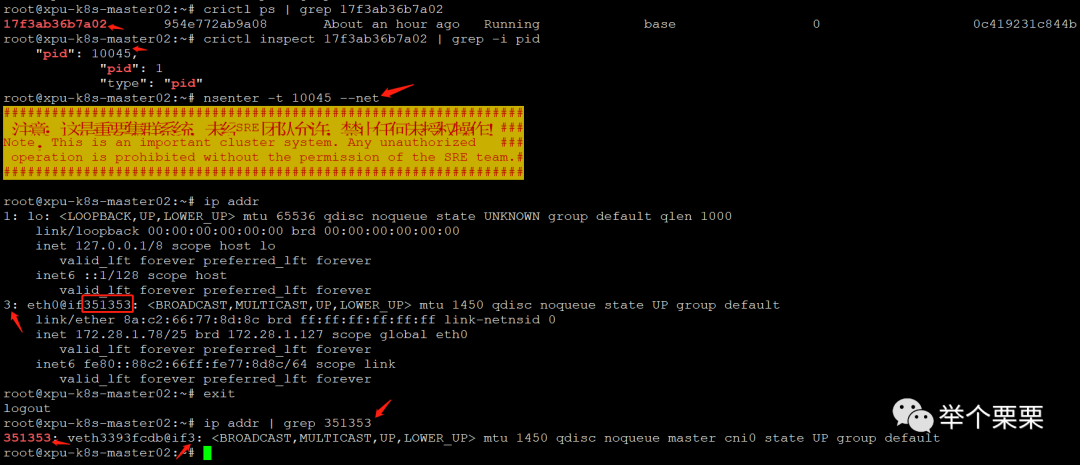
通过这样的方式找到其映射关系的。有了这个信息之后,我就可以去到该Node上所有的容器中拿到eth0对应的在Node的index ID,从而在Node侧过滤找出已经无效的vethxxx接口并删掉。操作如下:
for pid in $(for i in $(crictl ps | awk '{print $1}'); do crictl inspect $i | grep -i pid|grep , | awk '{print $2}' | sed 's/,//';done);do nsenter -t $pid --net ;done由于Node上现有的容器不多,十几个所以通过这种方式逐一登录拿到对应的index ID。如果容器较多,需要结合expect工具做自动识别处理。这里没有做。拿到所有有效的veth的index ID后报错到veth_yes文件中,把Node侧所有的veth信息报错到veth_all文件中:
ip add | grep veth > veth_all然后根据有效的index ID把其信息从veth_all中删除,得到所有要删除的vethxxx接口信息并删除:
// 删除有效的veth信息
#!/bin/bash
for i in $(cat veth_yes)
do
grep $i veth_all; sed -i "/$i/d" veth_all
done
// 删除所有无效的vethxxx接口信息
#!/bin/bash
for i in $(cat veth_all | awk '{print $2}' | awk -F@ '{print $1}')
do
ip link delete $i
done删除后,Node侧只剩下当前running容器的vethxxx接口了。
2)找到容器在Node侧记录的IP地址并删除
veth接口处理完,那么IP地址没有释放该如何处理呢?
查阅资料后得知,IPAM插件已分配的IP地址保存在/var/lib/cni/networks/cbr0文件中。如下:
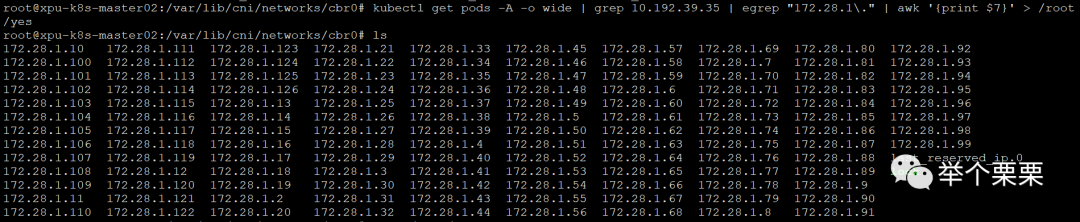
于是,将其中未真正在使用的IP地址文件删除即可。删除后如下:

此时,所有无法分配IP的Pod都可以正常获取IP从creating状态变为Running状态了。
至此,问题修复!略略略略略~~~
文章目录一、污点(Taint)1、污点简介2、污点的组成3、污点的设置和去除二、容忍(Tolerations)1、容忍简介2、容忍的基本用法3、示例4、多污点与多容忍配置三、警戒(cordon)和转移(drain)四、Pod启动阶段(相位phase)五、故障排除步骤一、污点(Taint)节点亲和性,是Pod的一种属性(偏好或硬性要求),它使Pod被吸引到一类特定的节点Taint则相反,它使节点能够排斥一类特定的PodTaint和Toleration相互配合,可以用来避免Pod被分配到不合适的节点上。每个节点上都可以应用一个或多个taint,这表示对于那些不能容忍这些taint的Pod,是不会被
我正在试验RSpec并考虑一个仅在测试套件通过时才更改随机种子的系统。我试图在after(:suite)block中实现它,该block在RSpec::Core::ExampleGroup对象的上下文中执行。虽然RSpec::Core::Example有一个方法“exception”,允许您检查是否有任何测试失败,但在上似乎没有类似的方法RSpec::Core::ExampleGroup或示例列表的任何访问器。那么,如何检查测试是通过还是失败?我知道这可以使用自定义格式化程序来跟踪是否有任何测试失败,但格式化过程影响测试的实际运行似乎不是一个好主意。 最佳答
文章目录Kubernetes(k8s)工作负载一、Workloads二、Pod三、Deployment四、RC、RS、DaemonSet、StatefulSet五、Job、CronJob1、Job2、CronJob六、GCKubernetes(k8s)工作负载一、Workloads什么是工作负载(Workloads)工作负载是运行在Kubernetes上的一个应用程序。一个应用很复杂,可能由单个组件或者多个组件共同完成。无论怎样我们可以用一组Pod来表示一个应用,也就是一个工作负载Pod又是一组容器(Containers)所以关系又像是这样工作负载(Workloads)控制一组PodPod控制
前言 前端时间PHP项目部署升级需要,需要把Laravel开发的项目部署K8s上,下面以laravel项目为例,讲解采用yaml文件方式部署项目。一、部署步骤1.创建Dockerfile文件Dockerfile是一个用来构建镜像的文本文件,在容器运行时,需要把项目文件和项目运行所必须的组件安装其中。#基础镜像FROMphp:7.4-fpm#时区ARGTZ=Asia/Shanghai#更换容器时区RUNcp"/usr/share/zoneinfo/$TZ"/etc/localtime&&echo"$TZ">/etc/timezone#替换成阿里apt-get源RUNsed-i"s@http
1.现象服务重启后,通过dockerstart方式无法启动实例,报出错误:Errorresponsefromdaemon:errorcreatingoverlaymountto/var/lib/docker/overlay2/xxx/merged:nosuchfileordirectorydockersave导出镜像也报出2.网上各种尝试摸索无效果修改daemon.json中的storage-driver为overlay,重启无效果。禁用selinux,临时或永久方式都无效果。修改/etc/docker/daemon.json中的storage-driver为overlay2,无效果。修改/l
我正在使用RubyonRails3.0.9、RSpec-rails2和FactoryGirl。我正在尝试陈述一个工厂协会模型,但我遇到了麻烦。我有一个factories/user.rb文件,如下所示:FactoryGirl.definedofactory:user,:class=>Userdoattribute_1attribute_2...association:account,:factory=>:users_account,:method=>:build,:email=>'foo@bar.com'endend和一个factories/users/account.rb文件,如下所示
急促的告警铃声响彻寂静的夜晚。对运维人来说,晚间值守耗费更大的精力,往往一个简单的磁盘使用率告警通知,就不得不爬起来进行处理,毕竟告警无小事,对于小问题,运维人也不能心存侥幸心理。虽然有着值班人员和团队的支撑,但频繁的告警还是让运维人员精疲力竭,如何让系统的稳定性提高,减轻一线人员的工作量,减轻一线人员的压力?通过智能运维,实现故障自愈将成为不可避免的选择。故障自愈是提升企业网络系统可用性和降低故障处理的人力投入,实现故障自愈从"人工处理"到"无人值守"的变革。通过实时发现告警,进行预诊断分析,判断告警类型和级别,如果是一般告警,平台进行自动恢复,如果是严重复杂告警则通过告警通知、运维工单等形
【车载开发系列】UDS诊断—DTC故障码基础回顾UDS诊断---DTC故障码基础回顾【车载开发系列】UDS诊断---DTC故障码基础回顾一.什么是DTC故障码二.DTC故障码的作用三.什么是自诊断需求四.故障自诊断范围是什么五.DTC故障码的格式及组成六.DTC之故障所属系统七.DTC之故障类型八.DTC之所属子系统九.DTC之故障失效类型十.DTC故障码的表示十一.故障指示的概念十二.什么是故障快照信息十三.什么是故障扩展信息十四.故障扩展信息和快照信息的作用十五.DTC故障码的状态位十六.状态码的作用是什么十七.DTC故障信息存储机制十八.什么是故障自恢复策略十九.与操作DTC故障码相关的
目录前言安装containerd解压安装配置成systemd任务安装runc编辑安装cni配置containerd镜像源containerd基本使用拓展阅读nerdctl工具安装及使用整体脚本总结写在后面前言上一篇文章,我们介绍了虚拟机的基础环境以及基础的网络配置,还有一些k8s节点要用到基础环境配置。本文将带领大家把containerd给安装了containerd的项目官方地址https://github.com/containerd/containerdcontainerd的发布版本地址如下https://github.com/containerd/containerd/releases
文章目录一.k8s集群修改config1.1备份当前k8s集群配置文件1.2删除当前k8s集群的apiserver的cert和key1.3生成新的apiserver的cert和key1.4刷新admin.conf1.5重启apiserver1.6刷新.kube/config二.安装kubectl2.1下载kubectl2.2配置kubectl三.使用kubernetes-client操作k8s集群3.1依赖3.2注意(可忽略)3.3创建StatefulSet3.4运行shell命令3.5删除StatefulSet3.6线上运行注意一.k8s集群修改config因为默认的是内网IP,复制出来后,