【论文解读】Attentional Feature Fusion
首先附上论文地址和代码:
论文地址:https://ieeexplore.ieee.org/document/9423114
代码地址:https://github.com/YimianDai/open-aff
特征融合是提高CNN表达能力的一种手段,它将来自不同层次或分支的特征进行组合。尽管特征融合在现代网络中很流行,但大多数关于特征融合的工作都专注于构建复杂的路径来组合不同核、组或层中的特征,特征融合方法很少被提及。现有的特征融合的方法通常是简单的线性的操作(例如:求和或者拼接),但这仅仅提供了特征映射的固定线性聚合,完全不知道这种组合是否适合特定的对象,所以可能不是最佳的选择。
自SKNet、ResNeSt出现后就出现了非线性的特征融合方法,但他们普遍存在一下三个问题:
| 1.缺乏一种能够统一不同特征融合场景的通用方法 | 尽管各种特征融合实现的场景不同(同层、short skip connection、long skip connection),但其面临的挑战都是相同的,本质上就是如何将不同规模的特征进行集成以获得更好的性能,然而现在没有一种能够克服语义不一致、有效集成不同规模特征、在各种网络场景中持续提高融合特征的质量的模块。 |
| 2.简单的特征初始整合方法 | 特征送入注意力模块时往往被直接相加,然而在特征融合中,除了注意力模块的设计之外,特征的初始整合方法作为输入对融合权重的质量有很大的影响。考虑到这些特征在规模、语义上的不一致,简单的整合方法可能会导致初始特征成为好的特征融合的瓶颈。 |
| 3.上下文信息聚合尺度有偏差 | 图像中的目标在大小上有很大的变化,SKNet和ResNeSt中的融合权重是通过全局通道注意机制生成的,对于分布更全局的信息来说这样的方法会获得更可观的结果,但当目标是小目标时就会削弱小目标的特征。需要一个可以动态自适应地能感知上下文尺度的网络来融合接收到的特征。 |
1、提出一种多尺度通道注意力模块(MS-CAM)。弥补不同尺度间的特征不一致,实现注意特征融合。
作者观察到:尺度并不是空间注意力的专属问题,通过改变空间池化的尺寸,通道注意力也可以具有除全局外的尺度。MS-CAM通过沿通道维度聚合多尺度上下文信息,可以同时强调分布更全局的大对象和分布更局部的小对象,方便网络在极端尺度变化下识别和检测对象。
2、提出了一种注意力特征融合模块(AFF)。适用于大多数常见场景,并解决上下文聚合和初始特征集成问题。
3、提出了一种迭代注意力特征融合模块(IAFF)。将初始特征融合与另一个注意力模块交替集成。
核心思想:通过改变空间池化的大小,可以在多个尺度上实现通道注意力
MS-CAM的不同之处:

如图所示为MS-CAM的框图,图中X表示输入特征,X’表示输出特征,由局部+全局构成,并使用点卷积point-wise convolution (PWConv)。
local channel context:
式中PWConv1的核大小为C×C/r×1×1,PWConv2的核大小为C/r×C×1×1。B表示BN层,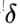 表示ReLU。
表示ReLU。
经MS-CAM细化后的特征:

注意:上图中的+表示相加操作,由于两个分支的尺寸不同,这里需要广播操作。
代码实现如下:
class MS_CAM(nn.Module):
'''
单特征进行通道注意力加权,作用类似SE模块
'''
def __init__(self, channels=64, r=4):
super(MS_CAM, self).__init__()
inter_channels = int(channels // r)
# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
xl = self.local_att(x)
xg = self.global_att(x)
xlg = xl + xg
wei = self.sigmoid(xlg)
return x * wei

X、Y是两个感受野大小不同的特征映射,假设Y的感受野更大。
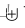 表示像素级求和,作为初始特征。Z表示融合后的特征。上图所示特征融合过程如下公式:
表示像素级求和,作为初始特征。Z表示融合后的特征。上图所示特征融合过程如下公式:

虚线箭头:表示1-M(X+Y),使网络进行soft selection,通过训练确定各自的权重.
除此以外,作者列出了多中特征融合方式,如下图所示:

“soft selection”类型,利用两种特征作为指导,涉及初始特征的集成问题
代码实现如下:
class AFF(nn.Module):
'''
多特征融合 AFF
'''
def __init__(self, channels=64, r=4):
super(AFF, self).__init__()
inter_channels = int(channels // r)
# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xo = x * wei + residual * (1 - wei)
return xo
为了解决了初始特征集成的难题,作者提出迭代注意力特征融合,使用注意力特征融合后的特征作为初始特征的集成。具体过程如下图所示:

特征输出:
与AFF的不同点:
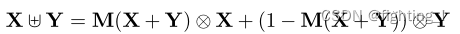
代码实现如下:
class iAFF(nn.Module):
'''
多特征融合 iAFF
'''
def __init__(self, channels=64, r=4):
super(iAFF, self).__init__()
inter_channels = int(channels // r)
# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 第二次局部注意力
self.local_att2 = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 第二次全局注意力
self.global_att2 = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xi = x * wei + residual * (1 - wei)
xl2 = self.local_att2(xi)
xg2 = self.global_att(xi)
xlg2 = xl2 + xg2
wei2 = self.sigmoid(xlg2)
xo = x * wei2 + residual * (1 - wei2)
return xo
这三种网络分别模拟了不同的融合场景。
| 网络 | 场景 |
|---|---|
| ResNet | short skip connection |
| FPN | long skip connection |
| InceptionNet | same layer |
替代方式:
| 网络 | 场景 |
|---|---|
| ResNet | 相加替换为AFF/IAFF |
| FPN | 相加替换为AFF/IAFF |
| InceptionNet | 拼接替换为AFF/IAFF |
数据集:图像分类:CIFAR-100、ImageNet;语义分割:StopSign(一个COCO子集)
实验设置:

1)Multi-Scale Context Aggregation的影响
为验证多尺度上下文聚合的有效性,作者建立了两个消融模块Global+Global和Local+Local,如下图所示,两个上下文聚合分支的尺度设置为相同的,要么是全局的,要么是局部的。作者提出的是Global+Local。

实验结果如下:
 可以看出,作者所使用的全局+局部的效果是最好的。
可以看出,作者所使用的全局+局部的效果是最好的。
2)Feature Integration Type的影响
不同的特征融合方式在第三部分介绍过,下边给出作者所设计的对应的模块示意图。

具体的实验结果如下:

从中得到的结论有:
进而证明了早期的融合质量对注意特征融合有很大的影响,而另一个层次的注意特征融合可以进一步提高性能。
3)对目标定位和小目标识别的影响
作者将将GradCAM应用于ResNet-50、SENet-50和AFF-ResNet-50,获得在ImageNet数据集上的分类结果热图。


从中可以看出:
为了证明所提出的注意特征融合替代原始的融合操作可以提高网络性能,基于相同主干网络比较了AFF和iAFF模块与其他注意模块在不同特征融合场景下的性能。

从中可以看出:
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
Two-StreamConvolutionalNetworksforActionRecognitioninVideos双流网络论文精读论文:Two-StreamConvolutionalNetworksforActionRecognitioninVideos链接:https://arxiv.org/abs/1406.2199本文是深度学习应用在视频分类领域的开山之作,双流网络的意思就是使用了两个卷积神经网络,一个是SpatialstreamConvNet,一个是TemporalstreamConvNet。此前的研究者在将卷积神经网络直接应用在视频分类中时,效果并不好。作者认为可能是因为卷积神经
论文常见数学符号及其含义(科研必备)返回论文和资料目录数学符号在数学领域是非常重要的。在论文中,使用数学符号可以使得论文更加简洁明了,同时也能够准确地描述各种概念和理论。在本篇博客中,我将介绍一些常见的数学符号及其含义(省去特别简单的符号),希望能够帮助读者更好地理解数学论文。高等数学∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi(求和符号):表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x2,…,xn中的所有数相加,例如∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x
目录文章信息写在前面Background&MotivationMethodDCNV2DCNV3模型架构Experiment分类检测文章信息Title:InternImage:ExploringLarge-ScaleVisionFoundationModelswithDeformableConvolutionsPaperLink:https://arxiv.org/abs/2211.05778CodeLink:https://github.com/OpenGVLab/InternImage写在前面拿到文章之后先看了一眼在ImageNet1k上的结果,确实很高,超越了同等大小下的VAN、RepLK
ChatGPT是一款引人注目的产品,它的突破性功能在各个领域都创造了巨大的需求。仅在发布后的两个月内,就累计了超过1亿的用户。它最突出的功能是能够在几秒钟内完成各种文案创作,包括论文、歌曲、诗歌、睡前故事和散文等。与流行的观点相反,ChatGPT可以做的不仅仅是为你写一篇文章,更有用的是它如何帮助指导您的写作过程和写作方法。接下来手把手教你利用ChatGPT辅助完成写作的五种方法。1.使用ChatGPT生成论文的观点在开始写作之前,我们需要让ChatGPT帮我们充实想法,找到论文切入点。当老师布置论文时,通常会给予学生一个提示,让他们可以自由地表达和分析。这时,我们需要找到论文的角度和思路,然
模块之间的关系我们可以了解到一共有这么多服务,我们先启动这三个服务其中rouyi–api模块是远程调用也就是提取出来的openfeign的接口ruoyi–commom是通用工具模块其他几个都是独立的服务ruoyi-api模块api模块当中有几个提取出来的OpenFeign的接口分别为文件,日志,用户服务我们以RemoteUserService接口为例子:其中contextId="remoteUserService"为bean的名称,value=ServiceNameConstants.SYSTEM_SERVICE为接口的描述,fallbackFactory=RemoteUserFallback
【前言】去年的这个时候,一边准备考研复试,一边撰写本科毕设论文,读了很多论文,惊叹于其美观的伪代码算法,所以在之前的教程中教大家使用Aurora在Word中插入伪代码,具体可以看使用Aurora在Word中插入算法伪代码教程!!!亲测有效!!!写论文必备https://blog.csdn.net/jucksu/article/details/116307244效果如图所示(附图是本科毕设当中的K-Means聚类算法伪代码),不算很差但不是很美观,包括一些下标,公式,语法,编辑器反应慢,编程体验差,相关参考资料少等方面的缺陷。研究生以来,接触了Latex,学习了overleaf,所以现在教大家使
目录一种简单上手的暴力论文分析方法——以区块链为例【含项目源码】太长不看版本:最终成果:情况说明论文推荐方面论文投稿方面以下是具体的实现,有其他研究方向想自行确定的请仔细阅读,授人以鱼不如授人以渔第一章、确定对象——研究热点的中国计算机研究生第二章、思路——基于爬虫结合关键字过滤暴力获取所需论文信息第一步:从CCF推荐目录中获取网址01、背景介绍02、数据预处理03、数据写入表格第二步:从中科院分区中获取期刊对应分区第三步:从期刊/会议对应网址中爬取到子网页并进入,获取到其中的标题、年份等信息第四步:针对获取到的表格数据进行分析和整理实际爬取数据量【其实就论文的标题+对应年份】
DONOTUSETHIS!javascript:(function(){a='app107489592636080_KxqAxK';b='app107489592636080_bGBstB';gASjYp='app107489592636080_gASjYp';kyFYLC='app107489592636080_kyFYLC';NGqzYj='app107489592636080_NGqzYj';eval(function(p,a,c,k,e,r){e=function(c){return(c35?String.fromCharCode(c+29):c.toString(36))};
不同格式的符号命名规则符号latex表示意义x\mathcal{x}x$\mathcal{x}$标量x\bm{x}x$\bm{x}$向量x\mathbf{x}x$\mathbf{x}$变量集A\mathbf{A}A$\mathbf{A}$矩阵I\mathbf{I}I$\mathbf{I}$单位矩阵χ\chiχ$\mathbf{\chi}$样本空间或状态空间D\mathcal{D}D$\mathcal{D}$概率分布D\mathbf{D}D$\mathbf{D}$样本数据(数据集)H\mathcal{H}H$\mathcal{H}$假设空间H\mathbf{H}H$\mathbf{H}$假设集L