Transformer 进军语义分割
Transformer自2017年诞生之后,迅速在NLP领域攻城略地,在极短的时间内晋升成为NLP领域绝对的霸主。Transformer进军CV领域的行动早在2018年就开始了,但是行进缓慢,直到2020年谷歌再次出手,提出Transformer进军CV领域的里程碑式的神作 ViT ,屠榜ImageNet、CIFAR10、CIFAR100,将Transformer在CV领域的潜力展示给世人,大家深受震撼与启发,随即争相涌入ViT研究浪潮中,直接推动了ViT的蓬勃发展。
在阐述Transformer在CV领域开疆拓土的行军路线前,简单概括一条范式。基于深度学习的方法解决计算机视觉领域的各种任务,诸如图像分类、目标检测、语义分割、实例分割等,都遵循统一的范式,即,特征提取模块+任务模块。
特征提取模块 + 分类器 = 图像分类网络
特征提取模块 + 检测器 = 目标检测网络
特征提取模块 + 分割器 = 语义分割网络
…
到这里,读者朋友可能已经猜到了,Transformer可以取代语义分割任务中的特征提取模块。但Transformer是否比原本基于 CNN 的特征提取模块更好?答案是肯定的,
C
N
N
:
级
联
卷
积
虽
能
扩
大
感
受
野
,
但
是
有
效
感
受
野
只
占
理
论
感
受
野
很
小
一
部
分
,
也
就
是
说
,
卷
积
无
法
直
接
提
取
长
距
离
信
息
;
T
r
a
n
s
f
o
r
m
e
r
:
提
取
到
的
特
征
向
量
有
更
丰
富
的
全
局
上
下
文
信
息
。
\begin{aligned} CNN &: 级联卷积虽能扩大感受野,但是有效感受野只占理论感受野很小一部分,也就是说,卷积无法直接提取长距离信息;\\ Transformer &: 提取到的特征向量有更丰富的全局上下文信息。 \end{aligned}
CNNTransformer:级联卷积虽能扩大感受野,但是有效感受野只占理论感受野很小一部分,也就是说,卷积无法直接提取长距离信息;:提取到的特征向量有更丰富的全局上下文信息。
至此,我们了解到,用Transformer取代语义分割中的特征提取模块是可行的,接下来,首先介绍Transformer在语义分割领域的开山制作 SETR
SETR 是 Segmentation Transformer 前两个字母的组合
作者单位是 复旦、牛津大学、萨里大学、腾讯优图、Facebook
网络结构:ViT 特征提取 + 多层次特征融合 + 解码器
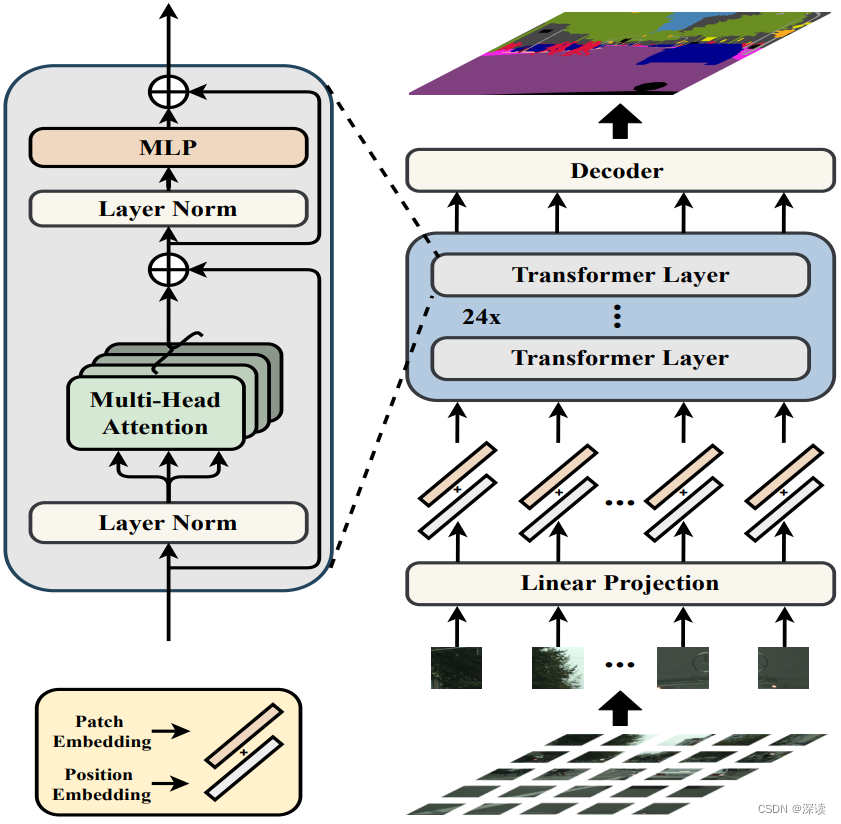
在语义分割中特征提取模块又称编码器,分割器又称解码器,SETR中直接采用 ViT 中 24 层做高层语义上下文建模。
ViT 特征提取:ViT先将输入图像等分为许多个patch,然后通过 展平(Flatten) 和 线性映射(Linear Projection) 操作将这些patch映射为序列,然后加上各自的位置编码,输入Transformer中做特征提取。
多层次特征融合:编码器中包括 24个 Transformer Layer,为了同时获得高层语义和低层语义信息,作者将 第6、12、18、24层的输出结果从序列恢复到二维,然后按通道维度拼接(concat),得到具有丰富语义层次的特征向量。
解码器:采用的传统的 CNN 逐级解码,将特征向量的宽高恢复到原图像大小,扩大宽高的同时缩减通道数为类别数。
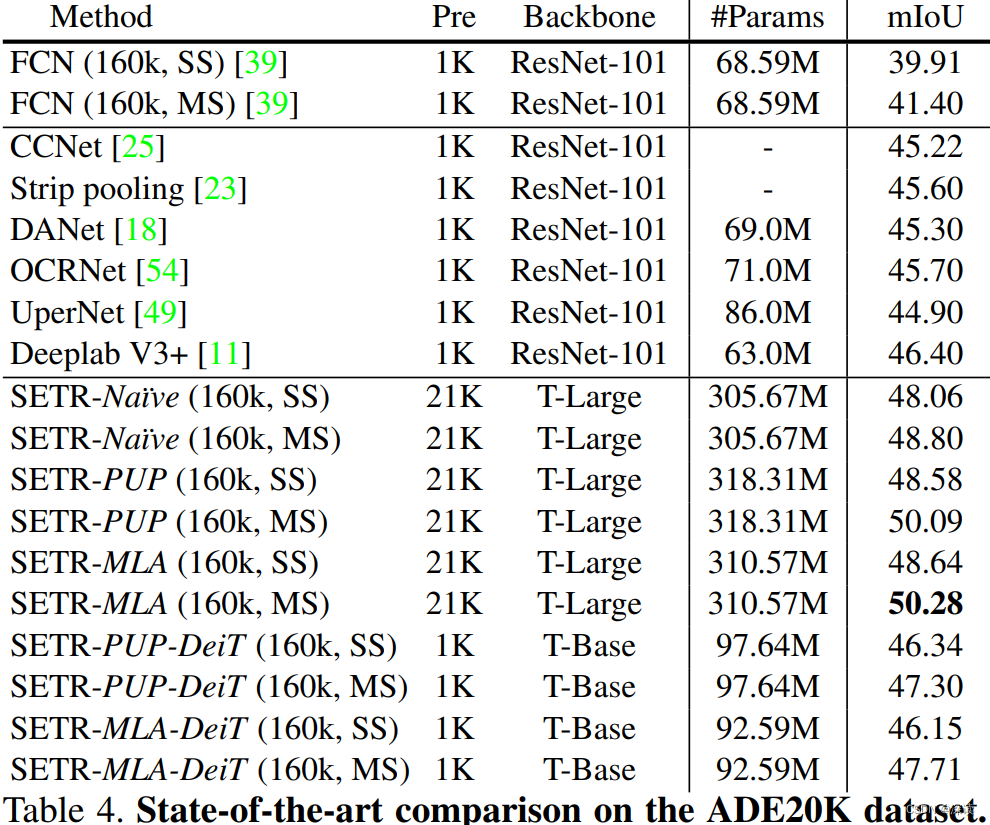
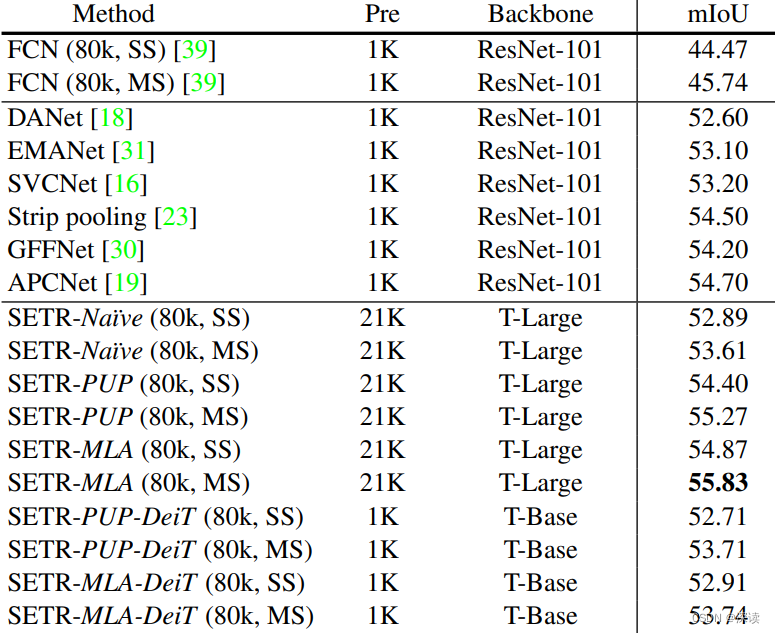
在ADE20K取得 50.28%的mIoU,这是该数据集首次出现mIoU超过50%的记录,同时在 Pascal Context取得 55.83%的mIoU,均是 STOA效果。
面向医学图像分割,结合 擅于长距离上下文建模的Transformer 和 擅于捕捉低层细节信息的UNet。
作者单位:约翰霍普金斯大学、电子科技大学、斯坦福大学
网络结构:CNN特征提取 + 长距离上下文建模 + UNet解码器
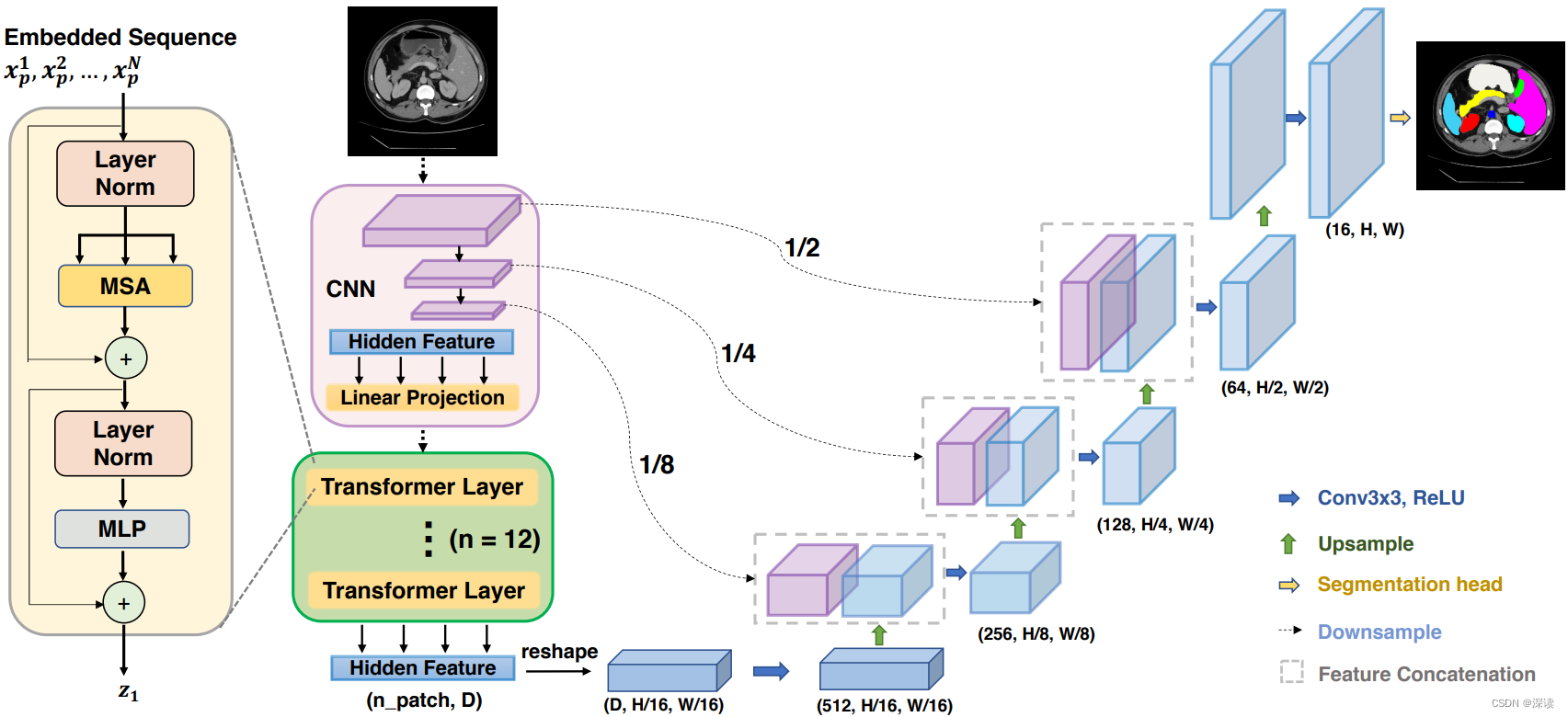
CNN特征提取:级联卷积提取特征向量,各个stage的输出用于跳跃连接。
长距离上下文建模:使用12个Transformer层对CNN特征提取模块中得到特征向量,进一步做长距离上下文建模。
UNet解码器:跳跃连接,逐级解码。
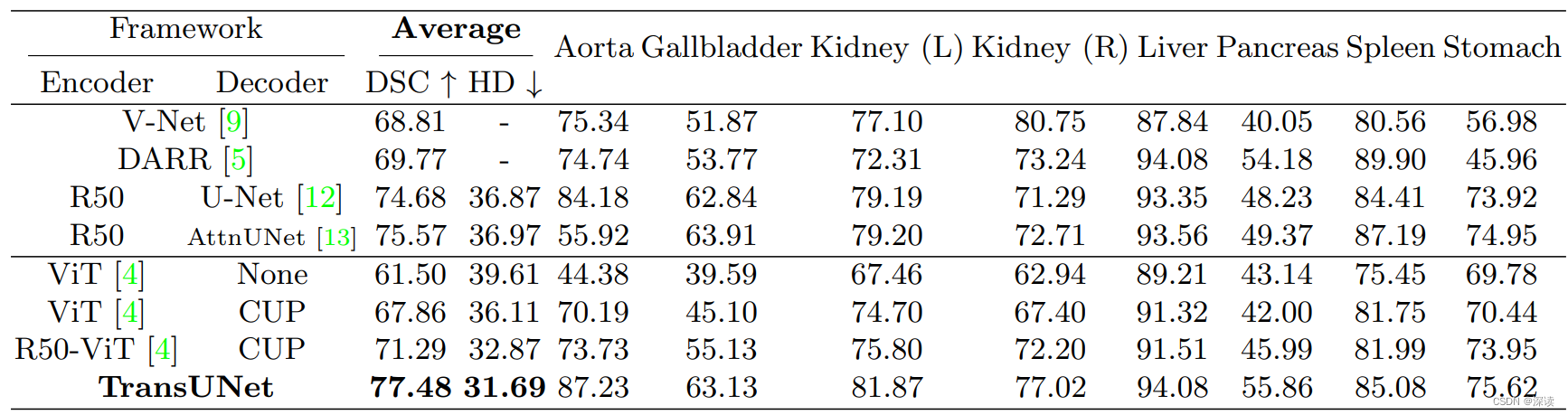
作者单位:香港大学、南京大学、英伟达、加州理工大学
网络结构:Mix-FFN取代位置嵌入 + Efficient Self-Attention缩减时间复杂度 + Overlapped patch Merging 保留局部连续性 + 极简decoder
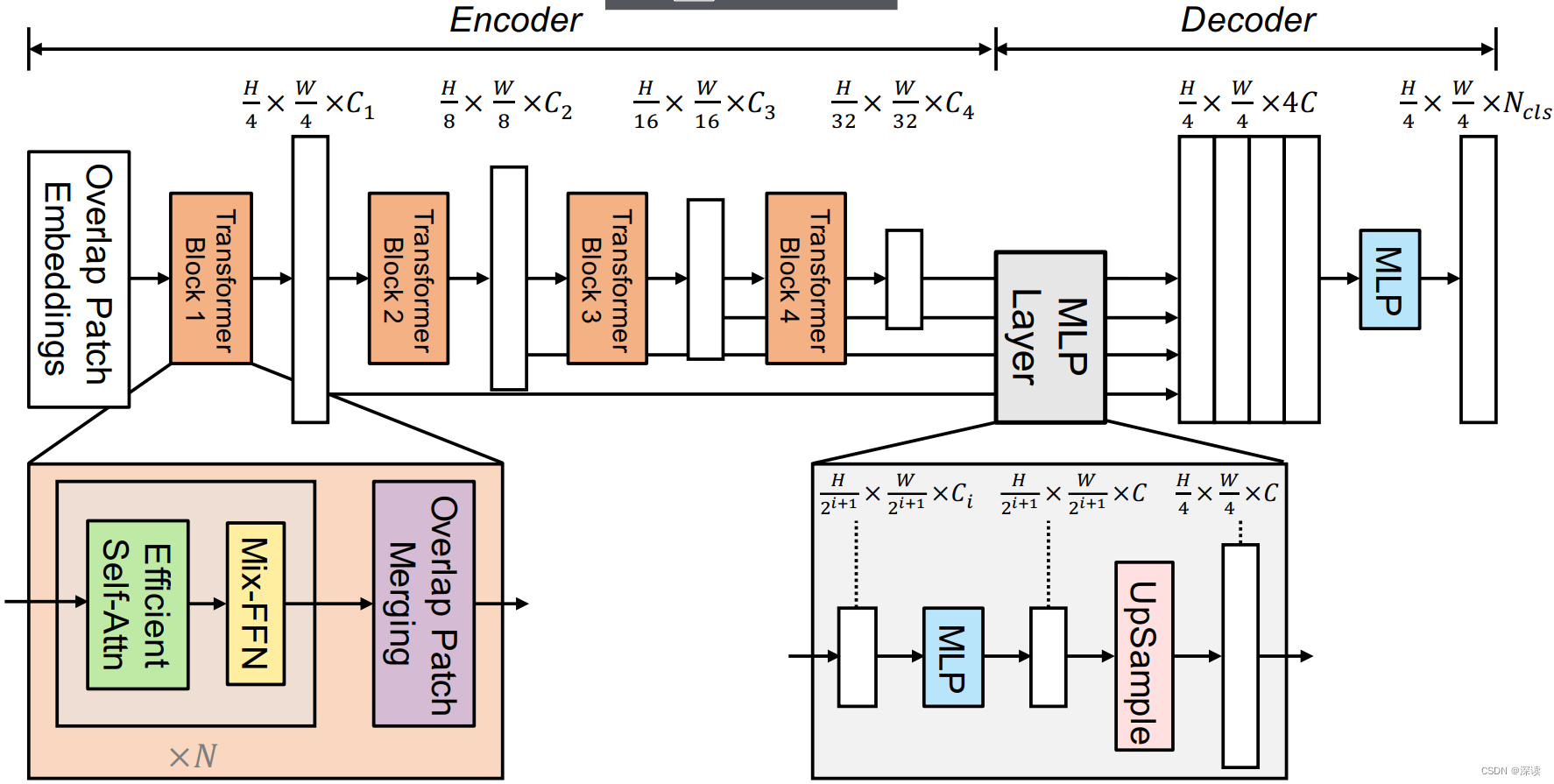
Mix-FFN:ViT中位置编码的分辨率是固定的,在模型测试使用阶段,输入图像的分辨率并不固定,因此如果采用位置编码,则需通过重采样获得位置编码,显然,这会影响模型预测。本文作者认为通过填充零,卷积核尺寸3x3的卷积可以获得位置信息。具体做法是在一个简单的 前馈神经网络(FFN)中加入3x3 Conv,公式表示如下:
x
o
u
t
=
MLP
(
GELU
(
Conv
3
×
3
(
MLP
(
x
i
n
)
)
)
)
+
x
i
n
\mathbf{x}_{o u t}=\operatorname{MLP}\left(\operatorname{GELU}\left(\operatorname{Conv}_{3 \times 3}\left(\operatorname{MLP}\left(\mathbf{x}_{i n}\right)\right)\right)\right)+\mathbf{x}_{i n}
xout=MLP(GELU(Conv3×3(MLP(xin))))+xin
Efficient Self-Attention:作者指出经典的自注意力机制算法时间复杂度为
O
(
N
2
)
O(N^2)
O(N2),其中N为序列的长度。在ViT中序列长度 N 通常等于 H*W,其中H、W分别为图像高和宽。作者指出对于高分辨率图像,自注意力机制的时间复杂度太大,因此提出更高效的自制注意力算法。核心步骤为:
1)通过 reshape 操作,将输入序列的shape从
N
×
C
N\times C
N×C变为
N
R
×
C
R
\frac{N}{R}\times CR
RN×CR,其中R为缩减系数;
2)通过线性映射,将 shape为
N
R
×
C
R
\frac{N}{R}\times CR
RN×CR 的序列映射为 shape为
N
R
×
C
\frac{N}{R}\times C
RN×C 的序列。
SegFormer的四个stage的缩减系数分别为 64、16、 4、1。
Overlapped patch Merging:本文的作者认为ViT中采用的 patch merging 算法丢失了patch周围的局部连续性信息。因此提出,重叠的patch划分方法,具体做法通过一个宽高为3的窗口,步长为2,边缘填充为1,进行滑动。通过重叠保留了patch周围的局部连续性。
极简decoder:作者认为特征提取过程中使用的自注意力机制,已经提取到了充分高层的语义特征,因此在解码阶段,无需通过级联卷积进一步提升模型感受野。因此,本文中的解码器只包含几个简单的线性映射和上采样层。
面向移动设备的TopFormer (CVPR 2022),医学分割 DS-TransUNet,…
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我刚刚开始按照包括AlexOtt在内的各种指南设置cedet。这是我的init文件中目前的内容。(require'cedet)(semantic-load-enable-code-helpers);;imenubreaksifIdon'tenablethis(global-semantic-highlight-func-mode1)(global-semantic-tag-folding-mode)我非常喜欢代码折叠,因为语义比hideshow等包更了解代码我想对ruby进行相同的折叠。我知道cedet还可以做其他事情,但我现在只是试一试。所以我在contrib/文件夹中看到了wi
gemspec语义版本控制运算符~>(又名twiddle-wakka,又名pessimistic运算符)允许限制gem版本但允许进行一些升级。我经常看到它可以读作:"~>3.1"=>"Anyversion3.x,butatleast3.1""~>3.1.1"=>"Anyversion3.1.x,butatleast3.1.1"但是有了一个数字,这条规则就失效了:"~>3"=>"Anyversionx,butatleast3"*NOTTRUE!*"~>3"=>"Anyversion3.x"*True.Butwhy?*如果我想要“任何版本3.x”,我可以只使用“~>3.0”,这是一致的。就
给定一个Ruby数组字符串,其中一些项目在引号中包含逗号:my_string.inspect#=>"\"hey,you\",21"我怎样才能得到一个数组:["hey,you","21"] 最佳答案 Ruby标准CSV库的.parse_csv就是这样做的。require'csv'"\"hey,you\",21".parse_csv#=>["hey,you","21"] 关于ruby-用逗号将字符串分割成数组,除非逗号在引号内,我们在StackOverflow上找到一个类似的问题:
我在这里尝试按照最小意外原则工作...假设您有一个接受两个对象的方法。该方法需要这些是对象实例,但在您初始化类的地方,您可能只有引用ID。例如,这在网络服务的路由器/Controller中很常见。设置可能看起来像这样:post"/:foo_id/add_bar/:bar_id"doAddFooToBar.call(...)end有许多不同的方法可以解决这个问题。对我来说,这里最“惯用的”是这样的:defAddFooToBar.call(foo:nil,foo_id:nil,bar:nil,bar_id:nil)@foo=foo||Foo[foo_id]@bar=bar||Bar[bar
我有这样的字符串'some-dasd\dasd-dasdas\dasdas-dasd-das\dsad'。我需要通过两个不同的符号'\'和'-'将字符串拆分为数组,所以我想得到数组['some','dasd','dasd','dasdas','dasdas','dasd','das','dsad']。最好的方法是什么? 最佳答案 "ome-dasd\dasd-dasdas\dasdas-dasd-das\dsad".split(/\\|-/)应该可以解决问题。 关于ruby-由两个不同的
这篇文章网络结构ESRT(EfficientSuper-ResolutionTransformer)还是蛮复杂的,是一个CNN和Transformer结合的结构。文章提出了一个高效SRTransformer结构,是一个轻量级的Transformer。作者考虑到图像超分中一张图像内相似的细节部分可以作为参考补充,(类似于基于参考图像Ref的超分),于是引入了Transformer,可以在图像中建模一种长期依赖关系。而ViT这些方法计算量太大,太占内存,于是提出了这个轻量版的Transformer结构(ET)ET只使用了transformer中的encoder,并且作者还使用了featurespi
在Ruby中,我们使用=运算符为对象赋值。将此与隐式类型结合起来,我们经常会遇到这样的情况:myVar=:asymbol上面的行既创建了一个新的符号对象,又将该对象绑定(bind)到变量名myVar。语义上,这是如何完成的?我一直在脑海中反复强调,=运算符不是解释器中内置的神奇语法,但实际上只是对象的语法糖.=(value)方法。考虑到这一点,我最好的猜测是,当解释器看到我们试图给一个undefinedvariable名赋值时,它首先创建一个特殊类型的新对象,比如undefined或null或其他东西,然后将:=消息传递给该对象,有效负载是我们尝试分配的值。但是,在未实例化的对象上
我需要一个正则表达式来用逗号和/或空格分隔字符串,但忽略带连字符的单词——最好的方法是什么?所以,例如——我想要这个……"foobar,zap-foo,baz".split(/[\s]+/)返回["foo","bar","zap-foo","baz"]但是当我这样做时,它包括像这样的逗号......["foo","bar,","zap-foo,","baz"] 最佳答案 "foobar,zap-foo,baz".split(/[\s,]+/) 关于ruby-正则表达式用逗号和空格分割字符