学习笔记根据百度飞浆课程学习
人工智能、机器学习和深度学习覆盖的技术范畴是逐层递减的,三者的关系如下图所示,即:人工智能 > 机器学习 > 深度学习。
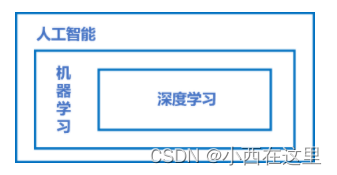
人工智能(ArtificialIntelligence,AI)是最宽泛的概念,是研发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。由于这个定义只阐述了目标,而没有限定方法,因此实现人工智能存在的诸多方法和分支,导致其变成一个“大杂烩”式的学科。
机器学习(MachineLearning,ML)是当前比较有效的一种实现人工智能的方式。
深度学习(DeepLearning,DL)是机器学习算法中最热门的一个分支,近些年取得了显著的进展,并替代了大多数传统机器学习算法。
- 分类问题::图像识别、垃圾邮件识别、世界杯中摄像头选择的切换画面
- 回归问题:股价预测、房价预测
- 排序问题:点击率预估、推荐
- 生成问题:图像生成、图像风格转换、图像文字描述生成
- 数据处理(数据采集 + 数据去噪)
- 模型训练(提取特征 + 训练模型)
- 模型评估和优化(MSE、F1-score、AUC+调参)
- 模型应用(A/B 测试)
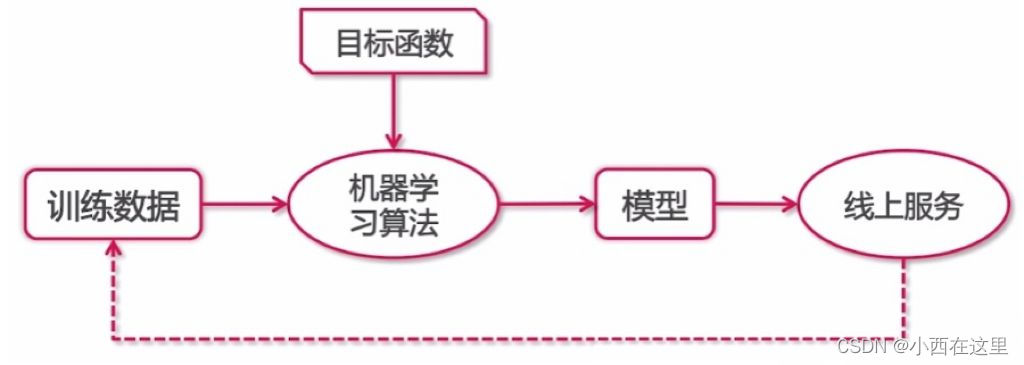
机器学习的实现可以分成两步:训练和预测,类似于归纳和演绎:
“机器思考”的过程中确定模型的三个关键要素:假设、评价、优化
模型有效的基本条件是能够拟合已知的样本
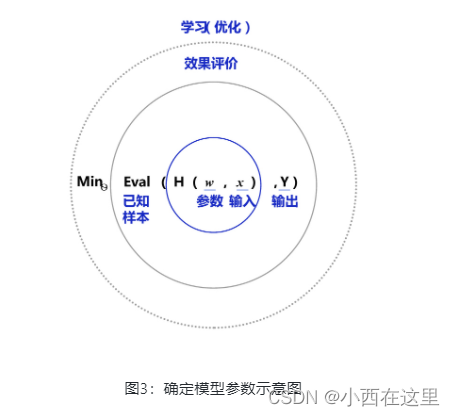
损失函数(损失Loss):衡量模型预测值和真实值差距的评价函数
图3 是以H为模型的假设,它是一个关于参数w和输入x的函数,用H(w,x) 表示。模型的优化目标是H(w,x)的输出与真实输出Y尽量一致,两者的相差程度即是模型效果的评价函数(相差越小越好)。那么,确定参数的过程就是在已知的样本上,不断减小该评价函数(H和Y的差距)的过程。直到模型学习到一个参数w,使得评价函数的值最小,衡量模型预测值和真实值差距的评价函数也被称为损失函数(损失Loss)。
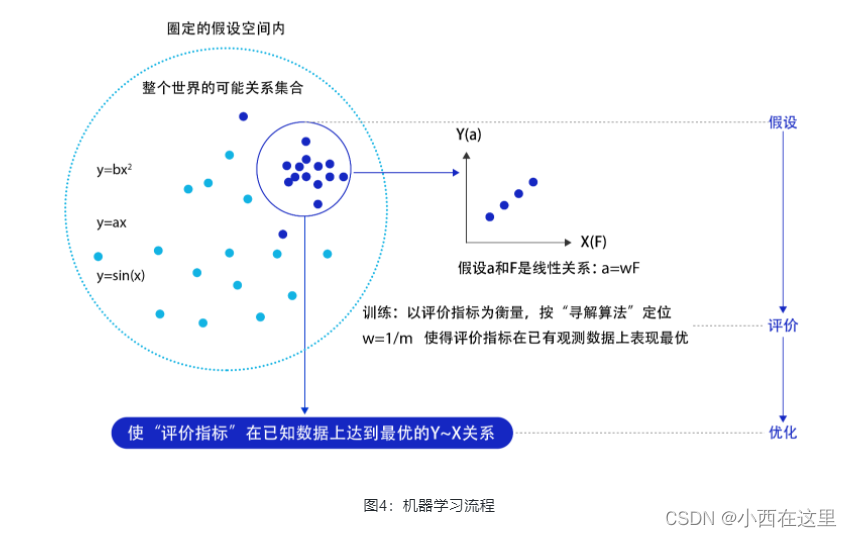
假设机器通过尝试答对(最小化损失)大量的习题(已知样本)来学习知识(模型参数w),并期望用学习到的知识所代表的模型H(w,x),回答不知道答案的考试题(未知样本)。最小化损失是模型的优化目标,实现损失最小化的方法称为优化算法,也称为寻解算法(找到使得损失函数最小的参数解)。参数w和输入x组成公式的基本结构称为假设。在牛顿第二定律的案例中,基于对数据的观测,我们提出了线性假设,即作用力和加速度是线性关系,用线性方程表示。由此可见,模型假设、评价函数(损失/优化目标)和优化算法是构成模型的三个关键要素。
模型假设、评价函数和优化算法是如何支撑机器学习流程的呢?如图4 所示。
机器执行学习任务的框架体现了其学习的本质是“参数估计”(Learning is parameter estimation)。
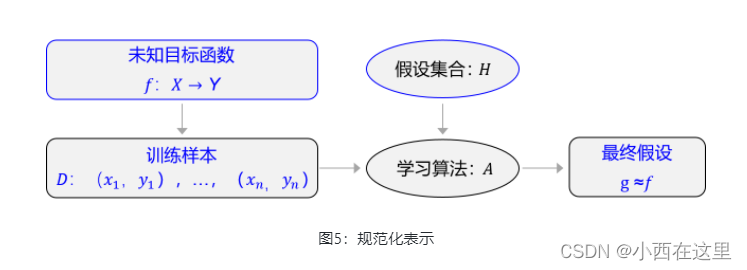
上述方法论使用更规范化的表示如图5所示,未知目标函数f,以训练样本D=(x1,y1),…,(xn,yn)为依据。从假设集合H中,通过学习算法A找到一个函数g。如果g能够最大程度的拟合训练样本D,那么可以认为函数g就接近于目标函数f。
相比传统的机器学习算法,深度学习做出了哪些改进呢?其实两者在理论结构上是一致的,即:模型假设、评价函数和优化算法,其根本差别在于假设的复杂度。
神经网络的基本概念
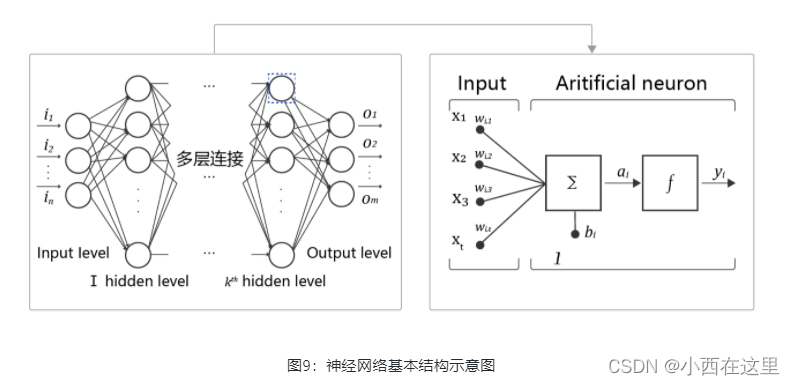
人工神经网络包括多个神经网络层,如:卷积层、全连接层、LSTM等,每一层又包括很多神经元,超过三层的非线性神经网络都可以被称为深度神经网络。通俗的讲,深度学习的模型可以视为是输入到输出的映射函数,足够深的神经网络理论上可以拟合任何复杂的函数。因此神经网络非常适合学习样本数据的内在规律和表示层次,对文字、图像和语音任务有很好的适用性。这几个领域的任务是人工智能的基础模块,因此深度学习被称为实现人工智能的基础也就不足为奇了。
神经网络基本结构如 图9 所示。
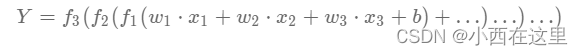
实现了端到端的学习
在数据充足的情况下,深度学习模型可以实现端到端的学习,即不需要专门做特征工程,将原始的特征输入模型中,模型可同时完成特征提取和分类任务,如 图14 所示。
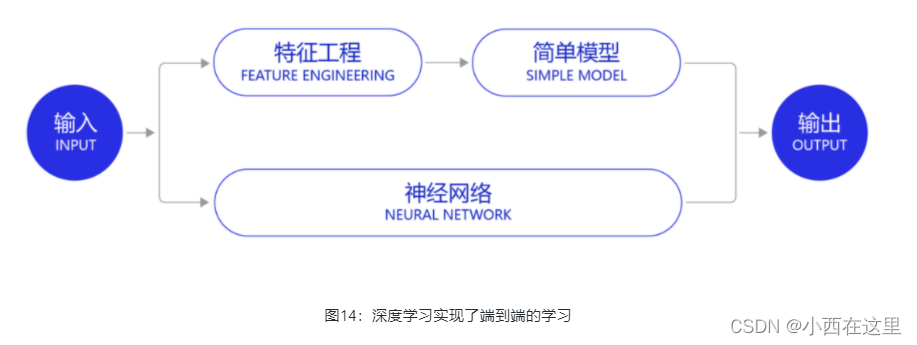
以计算机视觉任务为例,特征工程是诸多图像科学家基于人类对视觉理论的理解,设计出来的一系列提取特征的计算步骤,典型如SIFT特征。在2010年之前的计算机视觉领域,人们普遍使用SIFT一类特征+SVM一类的简单浅层模型完成建模任务。
说明:
SIFT特征由David Lowe在1999年提出,在2004年加以完善。SIFT特征是基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关。对于光线、噪声、微视角改变的容忍度也相当高。基于这些特性,它们是高度显著而且相对容易撷取,在母数庞大的特征数据库中,很容易辨识物体而且鲜有误认。使用SIFT特征描述对于部分物体遮蔽的侦测率也相当高,甚至只需要3个以上的SIFT物体特征就足以计算出位置与方位。在现今的电脑硬件速度下和小型的特征数据库条件下,辨识速度可接近即时运算。SIFT特征的信息量大,适合在海量数据库中快速准确匹配。
实现了深度学习框架标准化
除了应用广泛的特点外,深度学习还推动人工智能进入工业大生产阶段,算法的通用性导致标准化、自动化和模块化的框架产生,如 图15 所示。
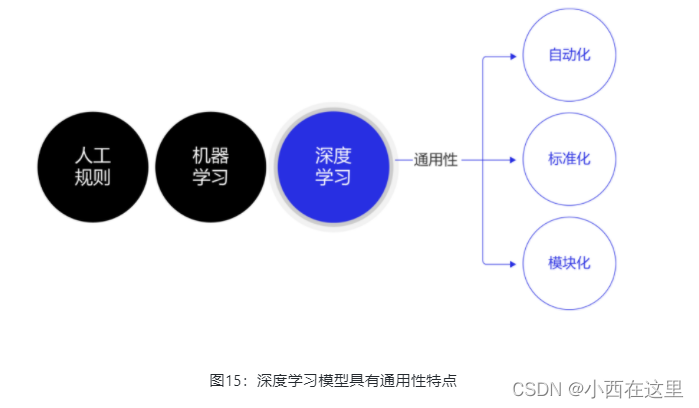
在此之前,不同流派的机器学习算法理论和实现均不同,导致每个算法均要独立实现,如随机森林和支撑向量机(SVM)。但在深度学习框架下,不同模型的算法结构有较大的通用性,如常用于计算机视觉的卷积神经网络模型(CNN)和常用于自然语言处理的长期短期记忆模型(LSTM),都可以分为组网模块、梯度下降的优化模块和预测模块等。这使得抽象出统一的框架成为了可能,并大大降低了编写建模代码的成本。一些相对通用的模块,如网络基础算子的实现、各种优化算法等都可以由框架实现。建模者只需要关注数据处理,配置组网的方式,以及用少量代码串起训练和预测的流程即可。
教程链接:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞