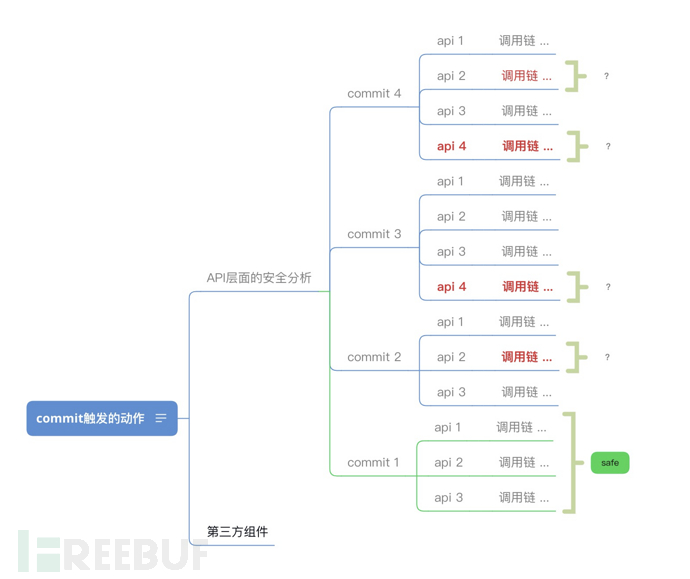
1 更新了pom文件,引入/消除了新的存在问题的二/三方组件理论上只要我们分析出以上两个变更就可以非常清楚的知道一次commit到底会不会带来新的风险,对于一些特殊场景,比如api下线,不仅仅意味着风险的消亡,同样意味着我们需要去更新我们的资产库标记相应的api已下线。
2 api或者api代码调用链发生了变化

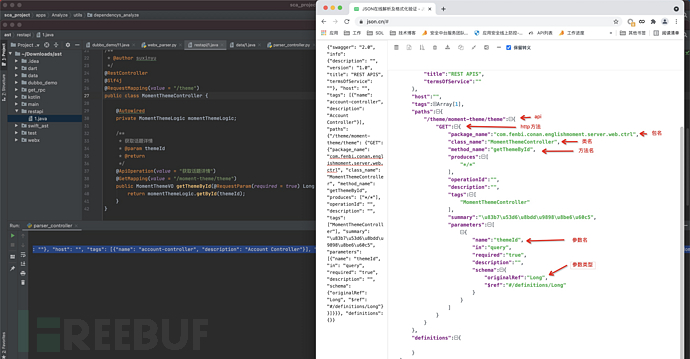
a. @Controller
b. @RestController
c. @ResourceMapping
e. servlet-mapping方式映射url和java类package com.xxx.xxxx.xxxx.server.web.ctrl;
import ... ...;
@RestController
@Slf4j
@RequestMapping(value = "/theme")
public class MomentThemeController {
@Autowired
private MomentThemeLogic momentThemeLogic;
/**
* 获取话题详情
* @param themeId
* @return
*/
@ApiOperation(value = "获取话题详情")
@GetMapping(value = "/moment-theme/theme")
public MomentThemeVO getThemeById(@RequestParam(required = true) Long themeId) {
return momentThemeLogic.getById(themeId);
}
}
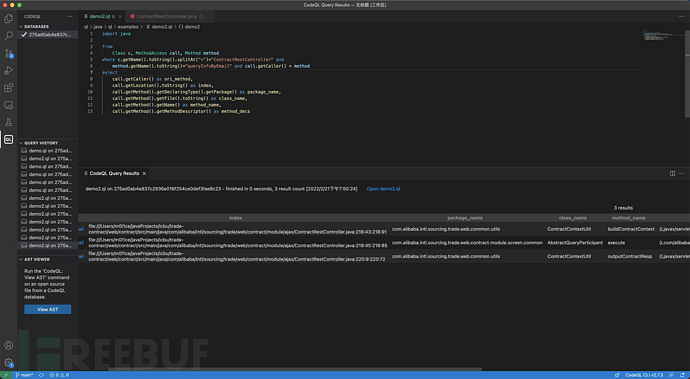
同样的道理hsf/dubbo接口也可以使用ast分析获取到,此处就不举例子了条条大路通罗马,获取调用链的方式有很多种,现在我用codeql简单的拿某个api演示下获取调用链以后可以做哪些事情@Verify
@RequestMapping(value = "/contract/buy/quxxxxyxeail.json",
produces = MediaType.APPLICATION_JSON_UTF8_VALUE)
public Object queryInfoByEmail(HttpServletRequest request, HttpServletResponse response) throws
TradeCreateaException {
ContractCaontext contraactContext = ContractContaextUtil.buildaContractContext(request);
TradxxeContractPartixxcipantDto retVal= queryxxxxmail.execute(contractContext);
ContraxactContextUtil.outputContractResp(request, contractContext);
return retVal;
}
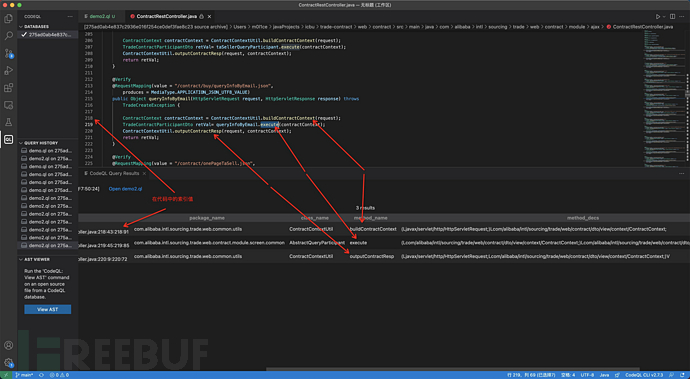 以上我们通过批量、递归操作就可以获取到一个api对应的入口方法开始其中调用链上的各个方法和在代码中的索引值,知道了索引值也就可以从源码中获取到每个方法的代码块和调用位置,就可以获取到类似以下的信息
以上我们通过批量、递归操作就可以获取到一个api对应的入口方法开始其中调用链上的各个方法和在代码中的索引值,知道了索引值也就可以从源码中获取到每个方法的代码块和调用位置,就可以获取到类似以下的信息 如此就可以获取到某个应用某个commitid下api对应的调用链信息和每个方法的具体代码了,当应用被更新时,重新执行以上流程就可以获取到在新的commitid下api信息以及调用链信息,对信息进行比对就可以获取到差异,而风险就存在于变化之中。
如此就可以获取到某个应用某个commitid下api对应的调用链信息和每个方法的具体代码了,当应用被更新时,重新执行以上流程就可以获取到在新的commitid下api信息以及调用链信息,对信息进行比对就可以获取到差异,而风险就存在于变化之中。我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我有用于控制用户任务的Rails5API项目,我有以下错误,但并非总是针对相同的Controller和路由。ActionController::RoutingError:uninitializedconstantApi::V1::ApiController我向您描述了一些我的项目,以更详细地解释错误。应用结构路线scopemodule:'api'donamespace:v1do#=>Loginroutesscopemodule:'login'domatch'login',to:'sessions#login',as:'login',via::postend#=>Teamroutessc
在Ruby中是否有Gem或安全删除文件的方法?我想避免系统上可能不存在的外部程序。“安全删除”指的是覆盖文件内容。 最佳答案 如果您使用的是*nix,一个很好的方法是使用exec/open3/open4调用shred:`shred-fxuz#{filename}`http://www.gnu.org/s/coreutils/manual/html_node/shred-invocation.html检查这个类似的帖子:Writingafileshredderinpythonorruby?
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
我正在使用Mandrill的RubyAPIGem并使用以下简单的测试模板:testastic按照Heroku指南中的示例,我有以下Ruby代码:require'mandrill'm=Mandrill::API.newrendered=m.templates.render'test-template',[{:header=>'someheadertext',:main_section=>'Themaincontentblock',:footer=>'asdf'}]mail(:to=>"JaysonLane",:subject=>"TestEmail")do|format|format.h
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
我正在尝试使用Ruby2.0.0和Rails4.0.0提供的API从imgur中提取图像。我已尝试按照Ruby2.0.0文档中列出的各种方式构建http请求,但均无济于事。代码如下:require'net/http'require'net/https'defimgurheaders={"Authorization"=>"Client-ID"+my_client_id}path="/3/gallery/image/#{img_id}.json"uri=URI("https://api.imgur.com"+path)request,data=Net::HTTP::Get.new(path
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我的公司有一个巨大的数据库,该数据库接收来自多个来源的(许多)事件,用于监控和报告目的。到目前为止,数据中的每个新仪表板或图形都是一个新的Rails应用程序,在巨大的数据库中有额外的表,并且可以完全访问数据库内容。最近,有一个想法让外部(不是我们公司,而是姊妹公司)客户访问我们的数据,并且决定我们应该公开一个只读的RESTfulAPI来查询我们的数据。我的观点是-我们是否也应该为我们的自己