
今天,我无聊的时候做了一个搜索文章的软件,有没有更加的方便快捷不知道,好玩就行了。基于Python tkinter 制作文章搜索软件,都是一些基础的应用。🍖 🍗 🥩

我们首先做到第一件事是导入模块。
import tkinter as tk
import webbrowser
from tkinter import ttk
import requests
root = tk.Tk()
root.title('CSDN问题搜索')
root.geometry('1000x700+100+100')
root.iconbitmap('search.ico')
root.mainloop()这段代码创建了一个名为root的Tkinter窗口对象,并设置了窗口的标题和大小。然后,它使用root.iconbitmap()方法将一个名为search.ico的图标图像设置为窗口的图标。
root.geometry()方法用于设置窗口的位置和大小,它接受一个参数,即窗口的位置和大小。在这个例子中,我们将窗口的位置设置为(1000, 700)并将大小设置为(100, 100)

img = tk.PhotoImage(file='benjing.png')
tk.Label(root, image=img).pack()这行代码创建了一个名为img的PhotoImage对象,并将其设置为根窗口对象root的图像。然后,它使用tk.Label创建一个标签对象,并将图像设置为该标签的图像。最后,它使用pack()方法将标签对象放置在根窗口对象中。

search_frame = tk.Frame(root)
search_frame.pack(pady=12)
# 创建一个字符串变量
search_va = tk.StringVar()
tk.Label(search_frame, text='CSDN搜索', font=('黑体', 12)).pack(side=tk.LEFT, padx=6)
tk.Entry(search_frame, relief='flat', width=30, textvariable=search_va).pack(side=tk.LEFT, padx=5, fill='both')
tk.Button(search_frame, text='C一下', font=('黑体', 12), relief='flat', bg='#fe6b00').pack(side=tk.LEFT, padx=5)这段代码创建了一个名为search_frame的Tkinter窗口对象,并将其放置在根窗口对象root中。然后,它创建了一个StringVar对象search_va,并将其设置为一个字符串变量。接下来,它创建了一个Label对象tk.Label,并将其放置在search_frame中。tk.Label对象具有一个文本属性和一个字体属性,这里使用了一个黑体字体和12号字号。tk.Entry对象具有一个文本属性和一个宽度属性,这里使用了一个30像素的宽度和一个StringVar对象search_va。最后,它创建了一个Button对象tk.Button,并将其放置在search_frame中。tk.Button对象具有一个文本属性、一个字体属性和一个背景属性,这里使用了一个黑体字体、12号字号和一个背景颜色为#fe6b00。
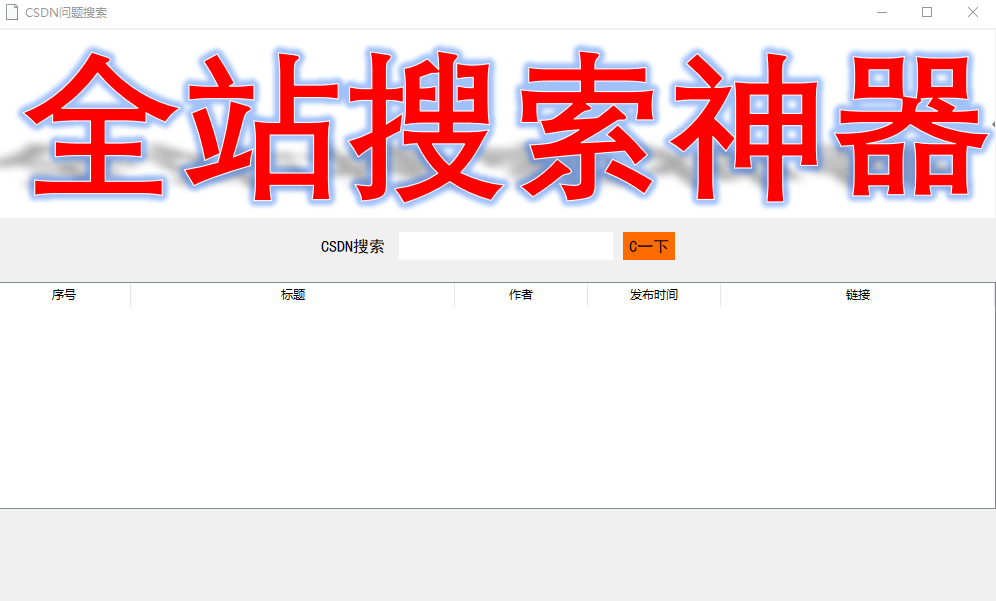
tree_view = ttk.Treeview(root,show="headings", columns=('num', 'title', 'author', 'date', 'link'))
tree_view.column("num", width=10, anchor='center')
tree_view.column('title', width=200, anchor='w')
tree_view.column('author', width=10, anchor='center')
tree_view.column('date', width=10, anchor='center')
tree_view.column('link', width=150, anchor='center')
tree_view.heading('num', text='序号')
tree_view.heading('title', text='标题')
tree_view.heading('author', text='作者')
tree_view.heading('date', text='发布时间')
tree_view.heading('link', text='链接')
tree_view.pack(fill=tk.BOTH, expand=False, pady=10)这段代码创建了一个名为tree_view的Tkinter Treeview对象,并将根节点设置为root。show参数设置为"headings",表示显示节点的标题。columns参数设置为一个包含节点标题、作者、发布时间和链接的列表。tree_view.column()方法用于设置每个列的宽度和锚点。tree_view.column()方法接受一个参数,即要设置宽度和锚点的列的名称。tree_view.heading()方法用于设置每个列的标题。tree_view.pack()方法用于设置节点的位置和大小,并将节点放置在根窗口对象中。tree_view.fill参数设置为"both",表示填充整个窗口,expand参数设置为True,表示展开节点,pady参数设置为10,表示节点之间的间距。
到了这里,我们这个框架就写好了,那么,我们如何获取搜索功能呢。、
def search(word):
search_list = []
num = 1
for page in range(1, 3):
url = 'https://so.csdn.net/api/v3/search'
data = {
'q': word,
'p': page,
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
response = requests.get(url=url, params=data, headers=headers)
for index in response.json()['result_vos']:
title = index["title"].replace('<em>', '').replace('</em>', '')
author = index["nickname"].replace('<em>', '').replace('</em>', '')
dit = {
'num': num,
'title': title,
'author': author,
'date': index['create_time_str'],
'link': index['url'],
}
num += 1
search_list.append(dit)
return search_list这段代码定义了一个名为search的函数,该函数接受一个字符串参数word,并返回一个字符串列表,其中包含符合给定字符串的所有文档的标题、作者和发布时间。
该函数首先创建一个空字符串列表search_list,然后使用一个循环来搜索所有可能的页面。在每个页面上,它使用requests库发送一个HTTP GET请求,并将搜索参数作为请求的一部分传递。然后,它将响应的JSON数据解析为一个字典,其中包含每个文档的标题、作者和发布时间。然后,它将每个字典添加到search_list中,并将搜索列表的长度增加1。
最后,该函数返回search_list,该列表包含符合给定字符串的所有文档的标题、作者和发布时间。
比如讲,搜索博主“爱吃饼干的小白鼠”,我们看看网站反馈的数据是不是和我们一样的。
接下来,我们就要把上面的内容展示到界面里面。
def show(search_list):
# 往树状图中插入数据
for index, li in enumerate(search_list):
tree_view.insert('', index + 1,values=(li['num'], li['title'], li['author'], li['date'], li['link']))
这段代码定义了一个名为show的函数,该函数接受一个字符串列表参数search_list,该列表包含每个文档的标题、作者和发布时间,用于插入树状图中。
该函数首先使用一个循环来遍历search_list,并使用tree_view.insert()方法将每个文档插入到树状图中。tree_view.insert()方法接受一个参数,即要插入的节点的索引和值列表。values参数用于指定节点的值列表。
上面我们讲述了搜索功能代码,以及展示代码。接下来,我们就要实现这样的功能——我们在文本框输入“爱吃饼干的小白鼠”,然后,我们点击C一下,就会在界面显示内容。
(PS—如果大家感兴趣,可以实现一个回车的功能)
def click():
key_word = search_va.get()
if key_word:
search_list = search(word=key_word)
show(search_list)这段代码定义了一个名为click的函数,该函数用于查找键盘上输入的字符串。如果找到了相应的字符串,则调用search()函数查找包含该字符串的文档并显示它们。get()方法用于从缓冲区中获取字符串。if key_word语句检查输入字符串是否包含在search_va中,如果是,则将search_list更新为包含相关文档的字符串列表。然后调用show()函数将其显示在树状图中。
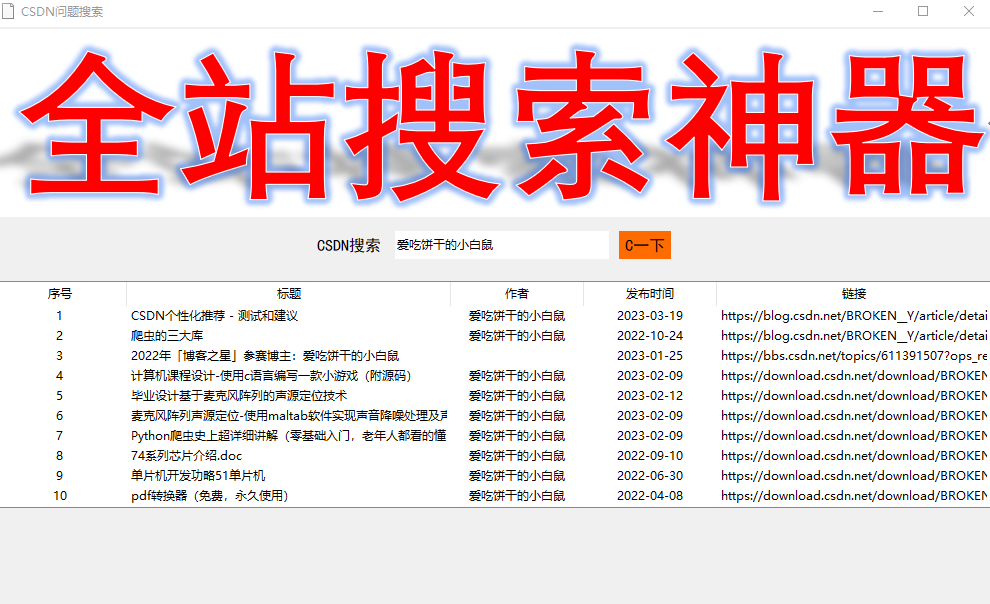
我们接下来,就实现点击某一行就会访问该文章。
def tree_view_click():
for item in tree_view.selection():
item_text = tree_view.item(item, "values")
webbrowser.open(item_text[-1])这段代码定义了一个名为tree_view_click的函数,该函数用于在树状图中选择节点并打开相应的网页。它使用tree_view.selection()方法获取选中的节点,并使用tree_view.item()方法获取节点的文本值。然后,它使用webbrowser.open()方法打开相应的网页。
tree_view.bind("<Button-1>",tree_view_click)在 Python 中,可以使用 tkinter 模块中的 ttk 子模块来创建树形视图控件。要为树形视图添加点击函数,可以使用 ttk.Treeview 的 __init__ 方法来设置点击事件处理函数。
到了这里,我们这个功能就实现了,是不是很神奇。搜索文章的软件就实现了,有的人说了,何必这么麻烦,直接去官网搜索就好了啊。确实,可是通过这个练习,我们可以学到很多东西。

我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是
给定一个元素和一个数组,Ruby#index方法返回元素在数组中的位置。我使用二进制搜索实现了我自己的索引方法,期望我的方法会优于内置方法。令我惊讶的是,内置的在实验中的运行速度大约是我的三倍。有Rubyist知道原因吗? 最佳答案 内置#indexisnotabinarysearch,这只是一个简单的迭代搜索。但是,它是用C而不是Ruby实现的,因此自然可以快几个数量级。 关于Ruby#index方法VS二进制搜索,我们在StackOverflow上找到一个类似的问题:
我有一个表,'jobs'和一个枚举字段'status'。status具有以下枚举集:enumstatus:[:draft,:active,:archived]使用ransack,我如何过滤表,比如说,所有事件记录? 最佳答案 你可以像这样在模型中声明自己的掠夺者:ransacker:status,formatter:proc{|v|statuses[v]}do|parent|parent.table[:status]end然后您可以使用默认的搜索语法_eq来检查相等性,如下所示:Model.ransack(status_eq:'ac
我一直在使用postgres关注railscast的全文搜索,但我不断收到以下错误#的未定义局部变量或方法“作用域”我关注了railscast确切地。我安装了所有正确的gem。(pg_search,pg)。这是我的代码文章Controller(我在这里也使用acts_as_taggable)defindex@articles=Article.text_search(params[:query]).page(params[:page]).per_page(3)ifparams[:tag]@articles=Article.tagged_with(params[:tag])else@art