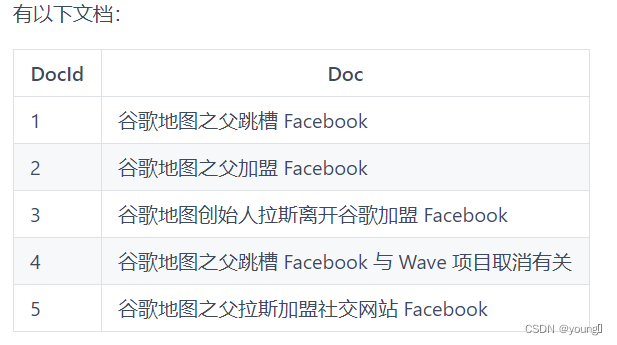
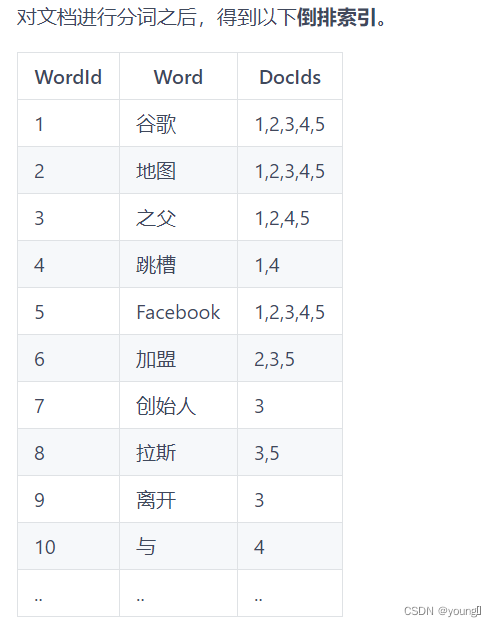
底层 lucene :lucene 就是一个 jar 包,里面包含了封装好的各种建立倒排索引的算法代码
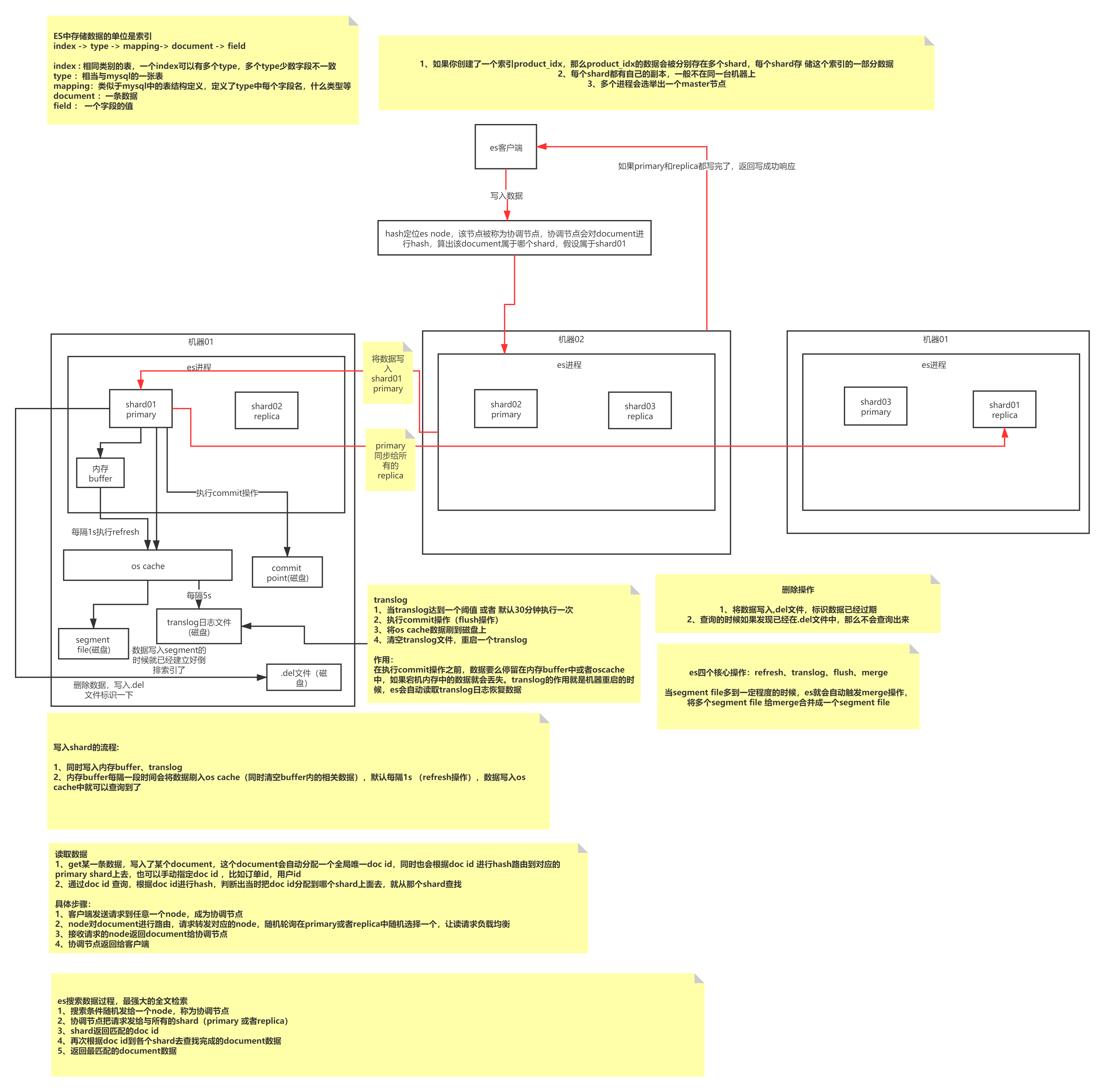
多台独立的机器上分别存在es进程,每个es进程中存在多个shard。shard分为primary和replica,replica是primary的从备份,每个primary的replica一般都分布在其他机器上,保证可用性。如果创建一个索引product_idx,那么该索引的数据就会保存在多个shard中。es 集群多个节点,会自动选举一个节点为 master 节点,这个 master 节点其实就是干一些管理的工作的,比如维护索引元数据、负责切换 primary shard 和 replica shard 身份等。要是 master 节点宕机了,那么会重新选举一个节点为 master 节点。如果某个非 master 节点宕机了。那么此节点上的 primary shard 不就没了。那好,master 会让 primary shard 对应的 replica shard(在其他机器上)切换为 primary shard。如果宕机的机器修复了,修复后的节点也不再是 primary shard,而是 replica shard。
那么什么时候进行物理删除呢?
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
我尝试用Ruby设计一个基于Web的应用程序。我开发了一个简单的核心应用程序,在没有框架和数据库的情况下在六边形架构中实现DCI范例。核心六边形中有小六边形和网络,数据库,日志等适配器。每个六边形都在没有数据库和框架的情况下自行运行。在这种方法中,我如何提供与数据库模型和实体类的关系作为独立于数据库的关系。我想在将来将框架从Rails更改为Sinatra或数据库。事实上,我如何在这个核心Hexagon中实现完全隔离的rails和mongodb的数据库适配器或框架适配器。有什么想法吗? 最佳答案 ROM呢?(Ruby对象映射器)。还有
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
“架设一个亿级高并发系统,是多数程序员、架构师的工作目标。许多的技术从业人员甚至有时会降薪去寻找这样的机会。但并不是所有人都有机会主导,甚至参与这样一个系统。今天我们用12306火车票购票这样一个业务场景来做DDD领域建模。”开篇要实现软件设计、软件开发在一个统一的思想、统一的节奏下进行,就应该有一个轻量级的框架对开发过程与代码编写做一定的约束。虽然DDD是一个软件开发的方法,而不是具体的技术或框架,但拥有一个轻量级的框架仍然是必要的,为了开发一个支持DDD的框架,首先需要理解DDD的基本概念和核心的组件。一.什么是领域驱动设计(DDD)首先要知道DDD是一种开发理念,核心是维护一个反应领域概
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172