Minio是一个go编写基于Apache License v2.0开源协议的对象存储系统,是为海量数据存储、人工智能、大数据分析而设计,它完全兼容Amazon S3接口,十分符合存储大容量的非结构化数据从几十kb到最大5T不等。是一个小而美的开源分布式存储软件。
简单、可靠:Minio采用简单可靠的集群方案,摒弃复杂的大规模的集群调度管理,减少风险与性能瓶颈,聚焦产品的核心功能,打造高可用的集群、灵活的扩展能力以及超过的性能。建立众多的中小规模、易管理的集群,支持跨数据中心将多个集群聚合成超大资源池,而非直接采用大规模、统一管理的分布式集群。
功能完善:Minio支持云原生,能与Kubernetes、Docker、Swarm编排系统良好对接,实现灵活部署。且部署简单,只有一个可执行文件,参数极少,一条命令即可启动一个Minio系统。Minio为了高性能采取无元数据数据库设计,避免元数据库成为整个系统的性能瓶颈,并将故障限制在单个集群之内,从而不会涉及其他集群。Minio同时完全兼容S3接口,因此也可以作为网关使用,对外提供S3访问。同时使用Minio Erasure code和checksum 来防止硬件故障。即使损失一半以上的硬盘,但是仍然可以从中恢复。分布式中也允许(N/2)-1个节点故障。
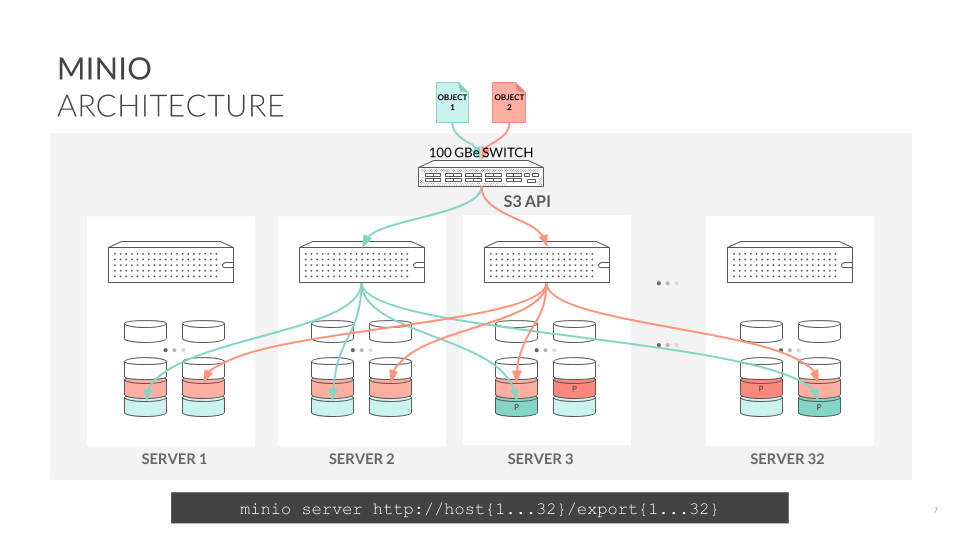
Minio采用去中心化的无共享架构,对象数据被打散存放在不同节点的多块硬盘,对外提供统一命名空间访问,并通过负载均衡或者DNS轮询在各个服务器之间实现负载均衡

Minio有两种集群部署方式,一种是常见的本地分布式集群部署,一种是联盟模式部署。本地分布式集群部署即在多个本地服务器节点部署Minio服务,并将其组成单套分布式存储集群,并提供统一命名空间和标注的S3访问接口。联盟部署则是将多个本地Minio集群在逻辑上组成了统一命名空间,实现近乎无线的扩展与海量的数据规模管理,这些集群都可以在本地或者分布在不同地域的数据中心。
与分布式数据库类似,Minio也会存在面临数据一致性的问题:一个客户端在读取一个对象的同时,另一个客户端可能正在修改或者删除这个对象。为了避免出现不一致的情况。Minio专门设计并实现了dsync分布式锁管理器,来控制数据一致性。
| EC2 Instance Type | Nodes | Locks/server/sec | Total Locks/sec | CPU Usage |
|---|---|---|---|---|
| c3.8xlarge(32 vCPU) | 8 | (min=2601, max=2898) | 21996 | 10% |
| c3.8xlarge(32 vCPU) | 8 | (min=4756, max=5227) | 39932 | 20% |
| c3.8xlarge(32 vCPU) | 8 | (min=7979, max=8517) | 65984 | 40% |
| c3.8xlarge(32 vCPU) | 8 | (min=9267, max=9469) | 74944 | 50% |
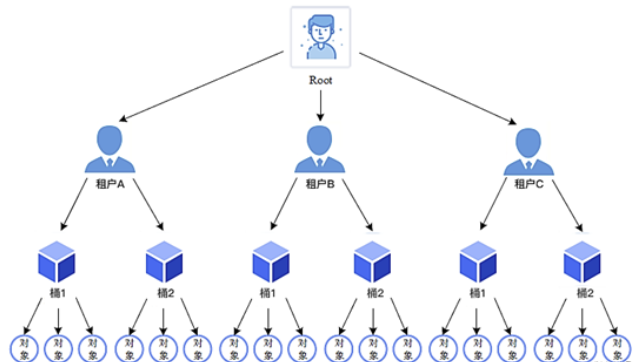
Minio对象存储系统把存储资源组织为租户-桶-对象的形式
Minio集群扩展加入了新的集群或者桶后,对象存储的客户端程序需要通过统一的域名/url来访问数据对象,这个过程涉及了etcd与CoreDns

Minio使用纠删码erasure code和checksum来保护数据免受硬件故障和无声数据损坏。即使丢失一半数量(N/2)的硬盘,仍然可以恢复数据。
纠删码是一种恢复丢失和损坏数据的数学算法,目前纠删码技术在分布式存储系统中的应用分为三类,阵列纠删码(Array code:RAID5、RAID6等)、RS(Reed-solomon)里德-所罗门类纠删码和LDPC(LowDensity Parity Check Code)低密度奇偶检验纠删码。ErasureCode是一种编码技术,它可以将份原始数据,增加M份数据,并能通过N+M份中的任意N分数据,还原原始数据。即如果有任意小于等于M份的数据丢失,仍然能通过剩下的数据还原。
Minio采用Reed-solomon code将对象拆分成N/2数据和N/2奇偶检验快,这就意味着如果是12块盘,一个对象将会被分成6个数据块、6个奇偶检验快,可以丢失任意6块盘(不管存放的数据快还是奇偶检验快),让然可以从剩下的盘中的数据恢复。
在一个N节点的分布式Minio中,只要有N/2个节点在线,你的数据就是安全的。不过至少需要N/2+1个节点才能进行写操作。
将一个文件上传至Minio后,对应磁盘上的信息如下:

其中xl.json为此对象的元数据文件。part.1为此对象的第一个数据分片。(分布式中每一个节点都会存在这两个文件分别是数据块和奇偶检验快)在读取数据时Minio会对编码快进行HighwayHash编码,然后进行校验,以确保每个编码的正确性。基于Erasure Code和Bit Rot Protection的HighwayHash这两个特性,所以Minio的数据可靠性很高。
Minio支持lambda计算通知机制,即桶中的对象支持事件通知机制。当前支持的事件类型有:对象上传、对象下载、对象删除、对象复制等。当前支持事件接受系统有:redis、NATS、AMQP、Kafka、mysql、elasticsearch等。
对象通知机制增强了Minio的扩展性,可以让用户通过自行开发来实现某些Minio未实现的功能。比如基于元数据的检索、与用户业务相关的计算等。同时也可以通过这个机制进行快速有效的增量备份。
Minio除了可以作为存储系统服务外,还可以作为网关,后端可以与NAS系统、HDFS系统等分布式文件系统或者S3、OSS这样的第三方存储系统。有了Minio网关,就可以为这些后端系统添加S3兼容的API,便于管理和移植,因为S3API已经是对象存储界事实的标注。

用户通过统一的S3 API请求存储资源,通过S3 API Router将各个请求路由到对应的ObjectLayer,每个ObjectLayer对应实现了各个存储系统的对象操作的所有API。例如GCS(Google cloud storage)实现了ObjectLayer接口后,它对于后端存储的操作就是通过GCS的SDK实现。当终端通过S3 API获取存储桶列表,那么最终的实现会通过GCS的SDK访问GCS服务获取存储桶列表,然后包装成S3标准的结构返回给终端。
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
我尝试用Ruby设计一个基于Web的应用程序。我开发了一个简单的核心应用程序,在没有框架和数据库的情况下在六边形架构中实现DCI范例。核心六边形中有小六边形和网络,数据库,日志等适配器。每个六边形都在没有数据库和框架的情况下自行运行。在这种方法中,我如何提供与数据库模型和实体类的关系作为独立于数据库的关系。我想在将来将框架从Rails更改为Sinatra或数据库。事实上,我如何在这个核心Hexagon中实现完全隔离的rails和mongodb的数据库适配器或框架适配器。有什么想法吗? 最佳答案 ROM呢?(Ruby对象映射器)。还有
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
“架设一个亿级高并发系统,是多数程序员、架构师的工作目标。许多的技术从业人员甚至有时会降薪去寻找这样的机会。但并不是所有人都有机会主导,甚至参与这样一个系统。今天我们用12306火车票购票这样一个业务场景来做DDD领域建模。”开篇要实现软件设计、软件开发在一个统一的思想、统一的节奏下进行,就应该有一个轻量级的框架对开发过程与代码编写做一定的约束。虽然DDD是一个软件开发的方法,而不是具体的技术或框架,但拥有一个轻量级的框架仍然是必要的,为了开发一个支持DDD的框架,首先需要理解DDD的基本概念和核心的组件。一.什么是领域驱动设计(DDD)首先要知道DDD是一种开发理念,核心是维护一个反应领域概
介绍pytest是一个非常成熟的全功能的Python测试框架,主要有以下几个特点:简单灵活,容易上手支持参数化能够支持简单的单元测试和复杂的功能测试,还可以用来做selenium/appnium等自动化测试、接口自动化测试(pytest+requests)pytest具有很多第三方插件,并且可以自定义扩展,比较好用的如pytest-selenium(集成selenium)、pytest-html(完美html测试报告生成)、pytest-rerunfailures(失败case重复执行)、pytest-xdist(多CPU分发)等测试用例的skip和xfail处理可以很好的和jenkins集成
我在当前项目中使用由Oracle数据库和memcached支持的RubyonRails。有一个非常常用的功能,它依赖于单个数据库View作为数据源,并且该数据源内部有其他数据库View和表。这是一个虚拟数据库View,能够从一个地方访问所有内容,而不是物化数据库View。大多数情况下,如果用户正在使用他们希望更新的功能,那么让数据保持最新很重要。从这个View获取数据时,我将安全表内部连接到View(安全表不是View本身的一部分),其中包含一些我们用来在更细粒度级别上控制数据访问的字段。例如,安全表有user_id,prop_1,prop_2列,其中prop_1,prop_2是数据库
📝学技术、更要掌握学习的方法,一起学习,让进步发生👩🏻作者:一只IT攻城狮。💐学习建议:1、养成习惯,学习java的任何一个技术,都可以先去官网先看看,更准确、更专业。💐学习建议:2、然后记住每个技术最关键的特性(通常一句话或者几个字),从主线入手,由浅入深学习。❤️《SpringCloud入门实战系列》解锁SpringCloud主流组件入门应用及关键特性。带你了解SpringCloud主流组件,是如何一战解决微服务诸多难题的。项目demo:源码地址👉🏻SpringCloud入门实战系列不迷路👈🏻:SpringCloud入门实战(一)什么是SpringCloud?SpringCloud入门实战
我正在开发一个包含大约10个不同功能组件的Sinatra应用程序。我们希望能够将这些组件混合并匹配到应用程序的单独实例中,完全从config.yaml文件配置,如下所示:components:-route:'/chunky'component_type:FoodListercomponent_settings:food_type:baconmax_items:400-route:'places/paris'component_type:Mappercomponent_settings:latitude:48.85387273165654longitude:2.340087890625-
文章目录⭐️赠书活动-《从程序员到架构师》⭐️编辑推荐⭐️作者简介⭐️赠书活动→获奖名单⭐️赠书活动-《从程序员到架构师》内容简介:《从程序员到架构师:大数据量、缓存、高并发、微服务、多团队协同等核心场景实战》分为数据持久化层场景实战、缓存层场景实战、基于常见组件的微服务场景实战、微服务进阶场景实战和开发运维场景实战5个部分。基于对十余个架构搭建与改造项目的经验总结,介绍了大数据量、缓存、高并发、微服务、多团队协同等核心场景下的架构设计常见问题及其通用技术方案,包含冷热分离、查询分离、分表分库、秒杀架构、注册发现、熔断、限流、微服务等具体需求下的技术选型、技术原理、技术应用、技术要点等内容,将