很多朋友都问我学完基础知识以后怎样提高编程水平?当然是
刷题啦!很多小伙伴都在纠结从哪里开始,今天给大家推荐一个身边朋友都在使用的刷题网站:点击进入牛客网刷题吧!

今天是Java进阶刷题的第三天,结合经典算法学习Java语法!一起升级打怪吧!!
文章目录
👉原题:对称二叉树
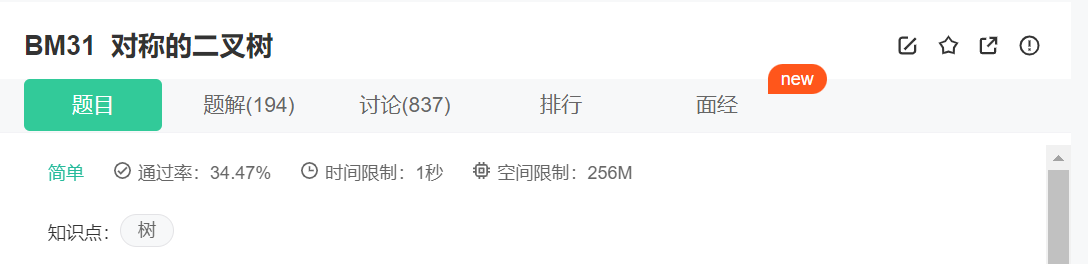
给定一棵二叉树,判断其是否是自身的镜像(即:是否对称)
例如: 下面这棵二叉树是对称的:
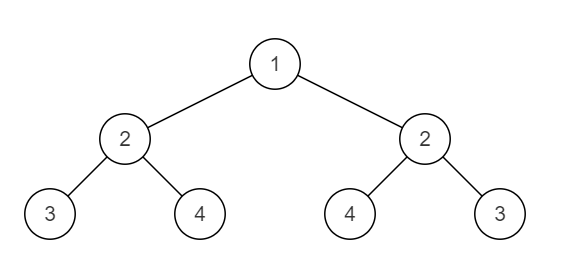
下面这棵二叉树不对称:
数据范围:节点数满足 0≤n≤1000,节点上的值满足 ∣val∣≤1000
要求:空间复杂度 O(n),时间复杂度 O(n)
备注:你可以用递归和迭代两种方法解决这个问题
示例1
输入:{1,2,2,3,4,4,3}
返回值:true
示例2
输入:{8,6,9,5,7,7,5}
返回值:false
Java代码实现:
public class Solution {
boolean recursion(TreeNode root1, TreeNode root2){
//可以两个都为空
if(root1 == null && root2 == null)
return true;
//只有一个为空或者节点值不同,必定不对称
if(root1 == null || root2 == null || root1.val != root2.val)
return false;
//每层对应的节点进入递归比较
return recursion(root1.left, root2.right) && recursion(root1.right, root2.left);
}
boolean isSymmetrical(TreeNode pRoot) {
return recursion(pRoot, pRoot);
}
}
思路:前序遍历的时候我们采用的是“根左右”的遍历次序,如果这棵二叉树是对称的,即相应的左右节点交换位置完全没有问题,那我们是不是可以尝试“根右左”遍历,按照轴对称图像的性质,这两种次序的遍历结果应该是一样的。
不同的方式遍历两次,将结果拿出来比较看起来是一种可行的方法,但也仅仅可行,太过于麻烦。我们不如在遍历的过程就结果比较了。而遍历方式依据前序递归可以使用递归。
👉原题:合并二叉树

已知两颗二叉树,将它们合并成一颗二叉树。合并规则是:都存在的结点,就将结点值加起来,否则空的位置就由另一个树的结点来代替。例如,两颗二叉树是:
Tree1:
Tree2:
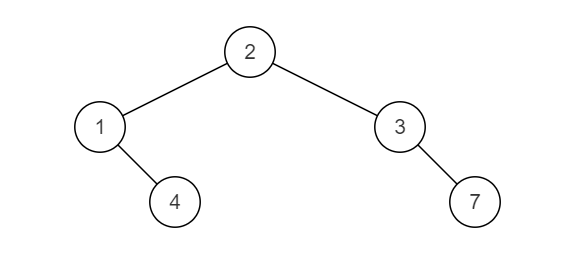
合并后的树为:
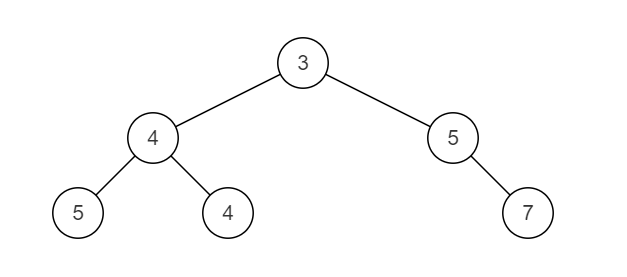
数据范围:树上节点数量满足 0≤n≤500,树上节点的值一定在32位整型范围内。
进阶:空间复杂度 O(1) ,时间复杂度 O(n)
示例1
输入:{1,3,2,5},{2,1,3,#,4,#,7}
返回值:{3,4,5,5,4,#,7}
说明:如题面图
示例2
输入:{1},{}
返回值:{1}
Java代码实现:
import java.util.*;
public class Solution {
public TreeNode mergeTrees (TreeNode t1, TreeNode t2) {
//若只有一个节点返回另一个,两个都为null自然返回null
if (t1 == null)
return t2;
if (t2 == null)
return t1;
//根左右的方式递归
TreeNode head = new TreeNode(t1.val + t2.val);
head.left = mergeTrees(t1.left, t2.left);
head.right = mergeTrees(t1.right, t2.right);
return head;
}
}
思路: 要将一棵二叉树的节点与另一棵二叉树相加合并,肯定需要遍历两棵二叉树,那我们可以考虑同步遍历两棵二叉树,这样就可以将每次遍历到的值相加在一起。遍历的方式有多种,这里推荐前序递归遍历。
👉原题:二叉树的镜像
操作给定的二叉树,将其变换为源二叉树的镜像。
数据范围:二叉树的节点数 0≤n≤1000 , 二叉树每个节点的值 0≤val≤1000
要求: 空间复杂度 O(n) 。本题也有原地操作,即空间复杂度 O(1) 的解法,时间复杂度 O(n)
比如:源二叉树
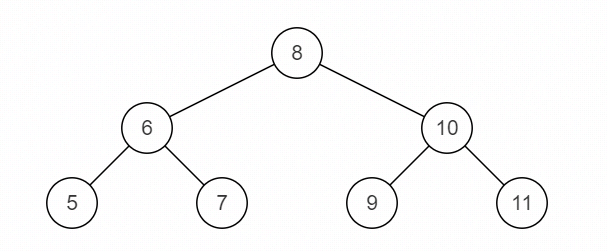
镜像二叉树
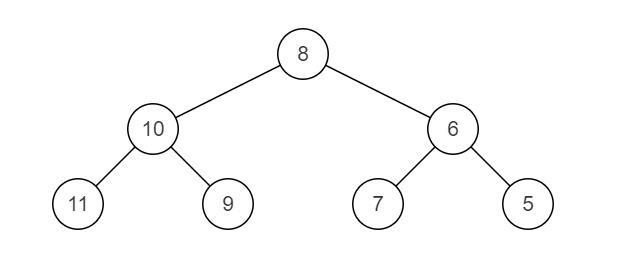
示例1
输入:{8,6,10,5,7,9,11}
返回值:{8,10,6,11,9,7,5}
说明:如题面所示
示例2
输入:{}
返回值:{}
Java代码实现:
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pRoot TreeNode类
* @return TreeNode类
*/
public TreeNode Mirror (TreeNode pRoot) {
// write code here
if(pRoot == null) return null;
// 构建辅助栈
Stack<TreeNode> stack = new Stack<>();
// 根节点入栈
stack.add(pRoot);
while(!stack.isEmpty()) {
// 节点出栈
TreeNode node = stack.pop();
// 根节点的左右子树入栈
if(node.left != null) stack.add(node.left);
if(node.right != null) stack.add(node.right);
// 左右子树交换
TreeNode tmp = node.left;
node.left = node.right;
node.right = tmp;
}
return pRoot;
}
}
思路:主要是利用栈(或队列)遍历树的所有节点 node ,并交换每个 node 的左 / 右子节点。
👉原题:重建二叉树
给定节点数为 n 的二叉树的前序遍历和中序遍历结果,请重建出该二叉树并返回它的头结点。
例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建出如下图所示。
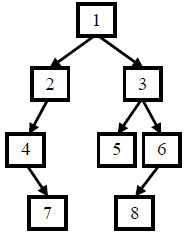
提示:
1.vin.length == pre.length
2.pre 和 vin 均无重复元素
3.vin出现的元素均出现在 pre里
4.只需要返回根结点,系统会自动输出整颗树做答案对比
数据范围:n≤2000,节点的值 −10000≤val≤10000
要求:空间复杂度 O(n),时间复杂度 O(n)
示例1
输入:[1,2,4,7,3,5,6,8],[4,7,2,1,5,3,8,6]
返回值:{1,2,3,4,#,5,6,#,7,#,#,8}
说明:返回根节点,系统会输出整颗二叉树对比结果,重建结果如题面图示
示例2
输入:[1],[1]
返回值:{1}
示例3
输入:[1,2,3,4,5,6,7],[3,2,4,1,6,5,7]
返回值:{1,2,5,3,4,6,7}
Java代码实现:
public class Solution {
public TreeNode reConstructBinaryTree(int [] pre,int [] in) {
return dfs(0, 0, in.length - 1, pre, in);
}
public TreeNode dfs(int preStart, int inStart, int inEnd, int[] preorder, int[] inorder) {
if (preStart > preorder.length - 1 || inStart > inEnd) {
return null;
}
//创建结点
TreeNode root = new TreeNode(preorder[preStart]);
int index = 0;
//找到当前节点root在中序遍历中的位置,然后再把数组分两半
for (int i = inStart; i <= inEnd; i++) { if (inorder[i] == root.val) { index = i; break; } } root.left = dfs(preStart + 1, inStart, index - 1, preorder, inorder); root.right = dfs(preStart + index - inStart + 1, index + 1, inEnd, preorder, inorder); return root; }
思路:二叉树的前序遍历:根左右;中序遍历:左根右。设置三个指针,一个是preStart,表示的是前序遍历开始的位置,一个是inStart,表示的是中序遍历开始的位置。一个是inEnd,表示的是中序遍历结束的位置,我们主要是对中序遍历的数组进行拆解
👉原题:二叉搜索树与双向链表
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。如下图所示
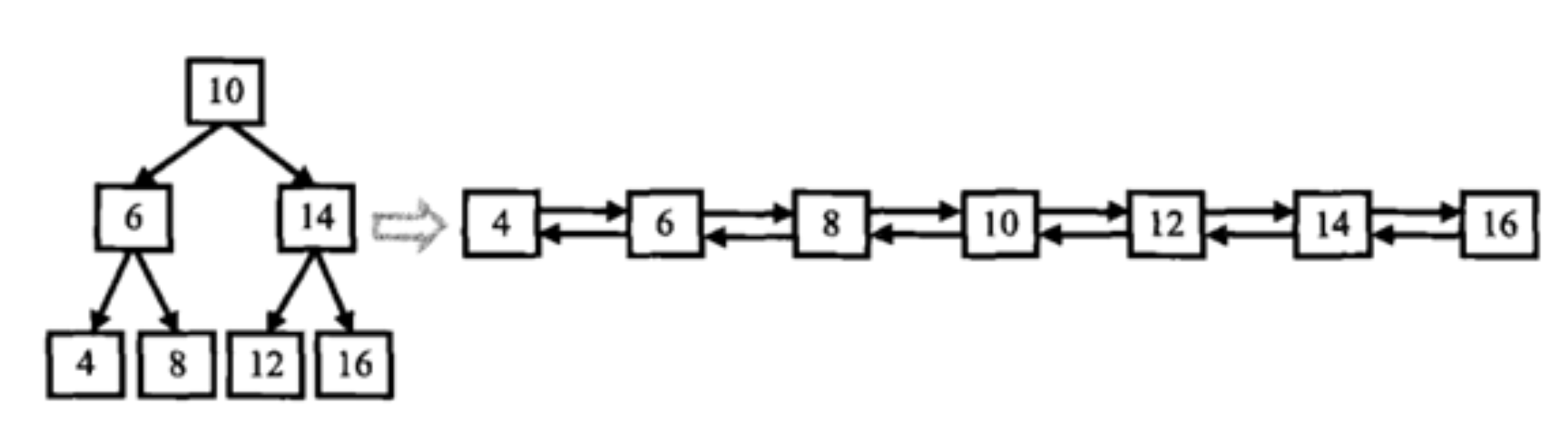
数据范围:输入二叉树的节点数 0≤n≤1000,二叉树中每个节点的值 0≤val≤1000
要求:空间复杂度O(1)(即在原树上操作),时间复杂度 O(n)
注意:
1.要求不能创建任何新的结点,只能调整树中结点指针的指向。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继
2.返回链表中的第一个节点的指针
3.函数返回的TreeNode,有左右指针,其实可以看成一个双向链表的数据结构
4.你不用输出双向链表,程序会根据你的返回值自动打印输出
输入描述: 二叉树的根节点
返回值描述: 双向链表的其中一个头节点。
示例1
输入:{10,6,14,4,8,12,16}
返回值:From left to right are:4,6,8,10,12,14,16;From right to left are:16,14,12,10,8,6,4;
说明:输入题面图中二叉树,输出的时候将双向链表的头节点返回即可。
示例2
输入:{5,4,#,3,#,2,#,1}
返回值:From left to right are:1,2,3,4,5;From right to left are:5,4,3,2,1;
Java代码实现:
public class Solution {
TreeNode pre=null;
TreeNode root=null;
public TreeNode Convert(TreeNode pRootOfTree) {
if (pRootOfTree==null)
return null;
// 递归遍历左子树
Convert(pRootOfTree.left);
// 判断特殊情况
if (root==null){
root=pRootOfTree;
}
// 修改遍历的结点为双向链表
if (pre!= null){
pRootOfTree.left=pre;
pre.right=pRootOfTree;
}
// 更新 pre
pre=pRootOfTree;
// 递归遍历右子树
Convert(pRootOfTree.right);
return root;
}
}
我一直在尝试在Ruby中实现BinaryTree类,但我得到了stackleveltoodeep错误,尽管我似乎没有在该特定代码段中使用任何递归:1.classBinaryTree2.includeEnumerable3.4.attr_accessor:value5.6.definitialize(value=nil)7.@value=value8.@left=BinaryTree.new#stackleveltoodeephere9.@right=BinaryTree.new#andhere10.end11.12.defempty?13.(self.value==nil)?true:
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我正在尝试训练一个前馈网络来使用Ruby库AI4R执行异或运算。然而,当我在训练后评估XOR时。我没有得到正确的输出。有没有人以前使用过这个库并得到它来学习异或运算。我使用了两个输入神经元,一个隐藏层中的三个神经元,一个输出层,正如我看到的预计算XOR前馈神经网络就像这样。require"rubygems"require"ai4r"#Createthenetworkwith:#2inputs#1hiddenlayerwith3neurons#1outputsnet=Ai4r::NeuralNetwork::Backpropagation.new([2,3,1])example=[[0,
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S
代码请进行一定修改后使用,本代码保证100%通过率,本题目提供了java、python、c++三种代码。复盘思路在文章的最后题目描述祖国西北部有一片大片荒地,其中零星的分布着一些湖泊,保护区,矿区;整体上常年光照良好,但是也有一些地区光照不太好。某电力公司希望在这里建设多个光伏电站,生产清洁能源对每平方公里的土地进行了发电评估,其中不能建设的区域发电量为0kw,可以发电的区域根据光照,地形等给出了每平方公里年发电量x千瓦。我们希望能够找到其中集中的矩形区域建设电站,能够获得良好的收益。输入描述第一行输入为调研的地区长,宽,以及准备建设的电站【长宽相等,为正方形】的边长最低要求的发电量之后每行为
原题链接https://www.dotcpp.com/oj/problem3162.html想直接看题解的,跳转到第三次尝试即可。已AC。解析:(1)首先大家要知道什么叫互质:以及它们的性质:欧拉函数在数论中,对正整数n,欧拉函数φ(n)是小于或等于n的正整数中与n互质的数的数目。此函数以其首名研究者欧拉命名,它又称为φ函数(由高斯所命名)或是欧拉总计函数(totientfunction,由西尔维斯特所命名)。例如φ(8)=4,因为1,3,5,7均和8互质。也可以从简化剩余系的角度来解释,简化剩余系(reducedresiduesystem)也称既约剩余系或缩系,是m的完全剩余系中与m互素的数
Java自学超全干货分享!学不学自己看着办吧!最近收到了很多知友私信我:”0基础有什么推荐的Java学习工具?”★作为ACM金牌选手,这些年在跟很多学员受教的过程中,积累了一些关于新手Java学习的经验和踩过的坑,今天来跟大家分享几点:1.找准学习路径和方法(选择不对,努力白费)2.合理规划学习时间,不在没必要的技术上浪费时间(找重点)3.找一些志同道合的朋友一起学习(相互鞭策)4.找一个前辈指点(方式方法)“还没开始就结束了”,作为java新手小白,最难自然是找对学习路径和方法……于是,本着一颗无私奉献的心,我连夜整理出了8个优质的Java免费学习网站,分享给大家。NO.1菜鸟教程国内小白入
趁着寒假期间稍微尝试跑了一下yolov5和yolov7的代码,由于自己用的笔记本没有独显,台式机虽有独显但用起来并不顺利,所以选择了租云服务器的方式,选择的平台是矩池云(价格合理,操作便捷)需要特别指出的是,如果需要用pycharm链接云服务器训练,必须要使用pycharm的专业版而不是社区版,专业版可以使用SSH服务连接云服务器。关于专业版的获取,据我所知一是可以买,二是如果你是在校大学生,可以用学生证向JetBrain申请专业版使用权,我就是通过这种方式激活专业版账户的,我记得当时两三天官方就发激活邮件了,还是很人性化的,使用期一年。下面开始正题本教程只涉及将yolov5及yolov7跑通