欢迎来到:遇见蓝桥遇见你,不负代码不负卿!
目录
推荐老铁们两个学习网站:
面试利器&算法学习:牛客网
风趣幽默的学习人工智能:人工智能学习
下半部分已经更新咯,补充了很多内容,爆肝两万字,快来康康吧。
【声明】
这里更新的STL并不是全部哦,毕竟太多了,不过这一章的STL只是对于应对算法编程竞赛完全是够了的,所以请铁汁们放心啦。
【前言】
有铁汁要求更新STL这块内容,考虑到很多蓝桥杯C/C++组参赛者选用的大都是C语言和STL搭配使用去编写代码,正好之前发布的算法没有多久,给大家一些练习的时间,注意哦,在这里笔者又要唠叨了,铁汁们一定要把刷题量跟上去呀,单单仅靠我这里的基础知识和几道典型例题讲解是完全不够的,可以先通过我的博文对每个知识点有个大体上的认识,然后再刷题去感受知识点的深度。一定要自己多多实现哟!因为大家都花费自己的时间来看我的博文,笔者很感激,所以不想浪费大家的时间,每片博文我都会认真去编写,绝不辜负铁汁们哦,一起加油鸭!

这里要说一下,有的铁汁叫我换一些妹子的图片,可是我翻来覆去的找就这么几张,哪个铁汁有,可以私发我点哦,感谢感谢,图穷了。
下面是蓝桥杯历年考题,可以看到搜索类题目出现得很多,而且主要集中在第7, 第8两道大题,重要程度可想而知,当然动态规划、简单数学等后面笔者都会讲解到哦,铁汁们请放心好啦。
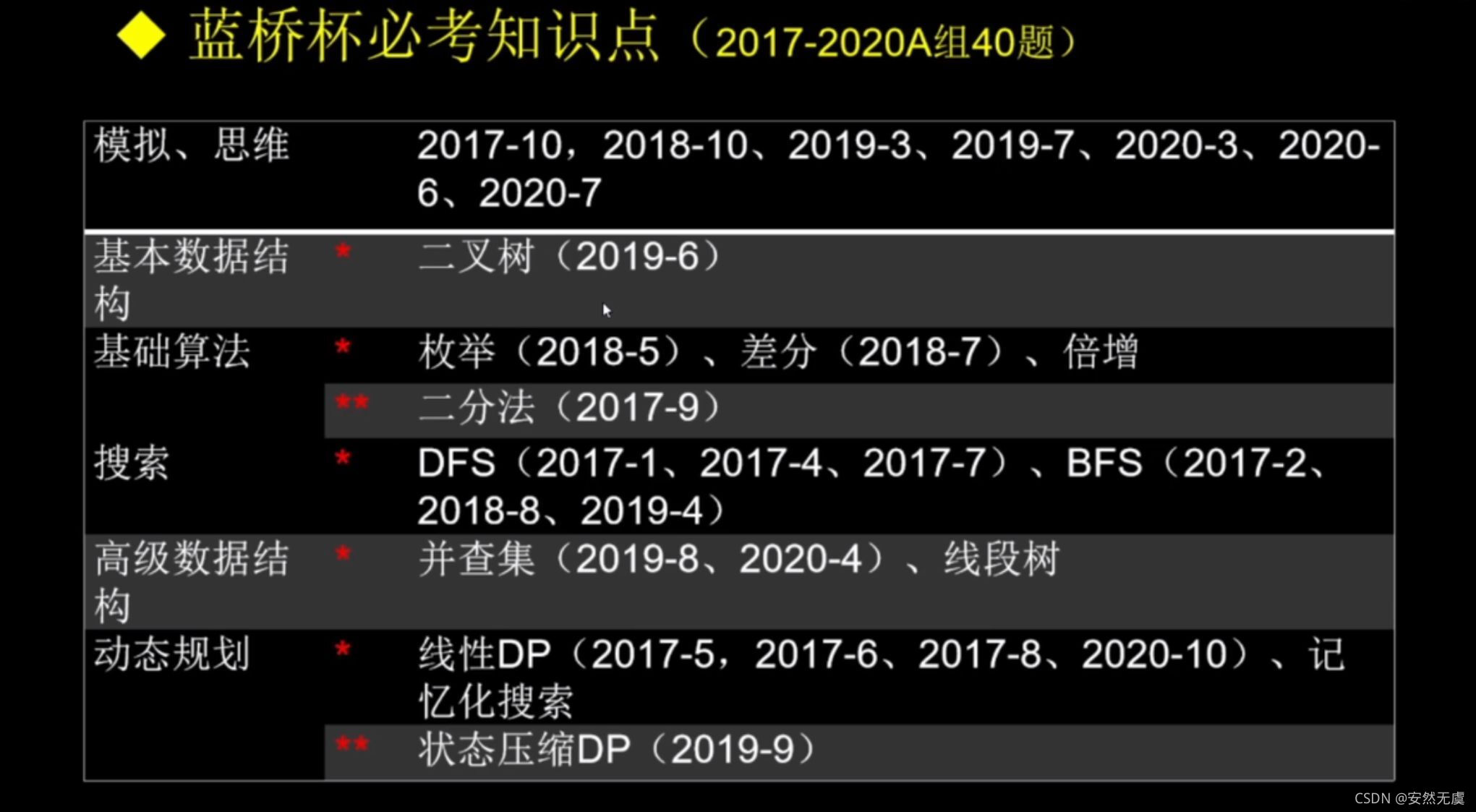
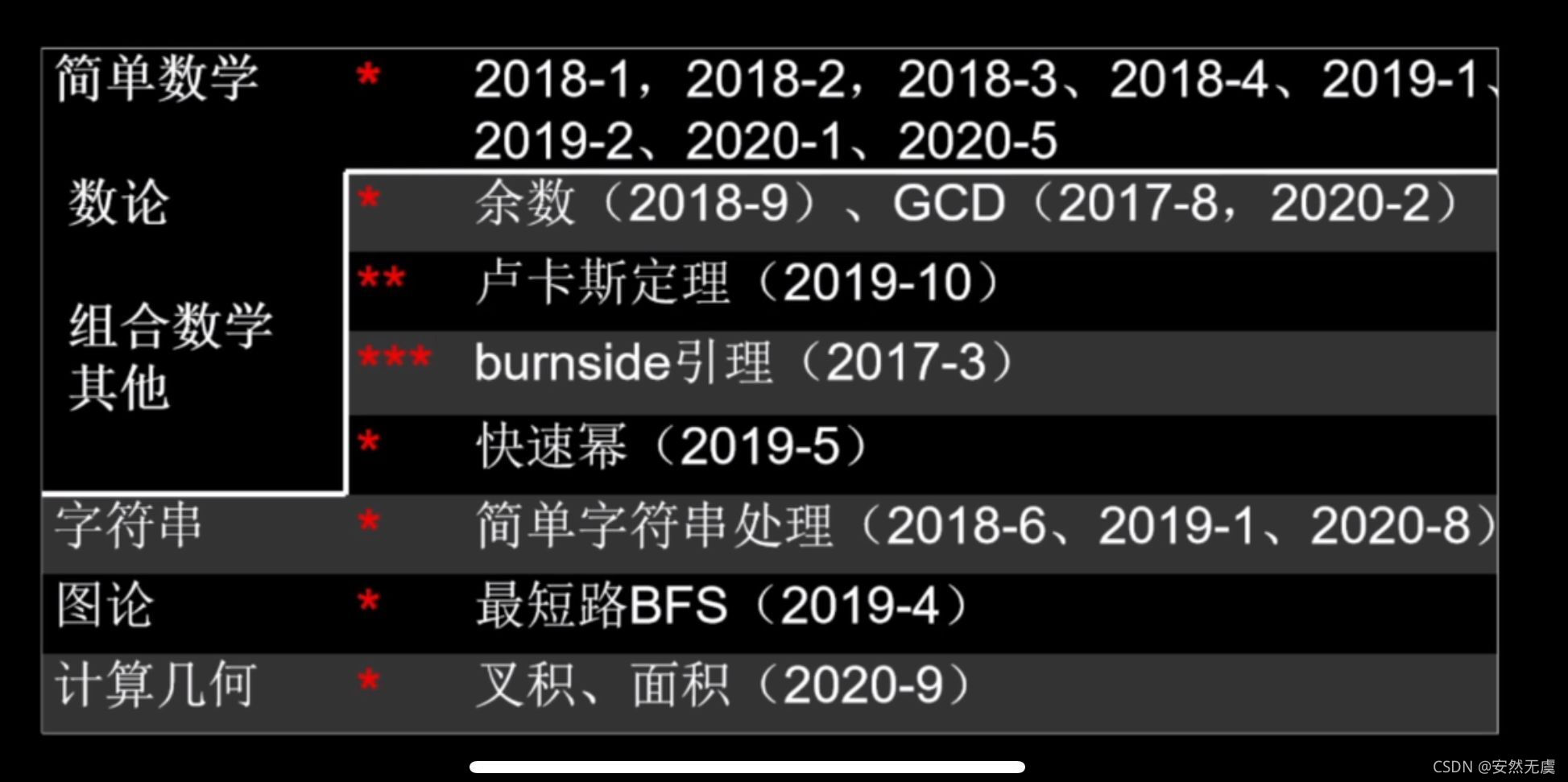
综上所述:

这是上次写的深度优先搜索(DFS),不是很熟悉的小伙伴可以康康哦。
蓝桥杯算法竞赛系列第五章——拔高篇之深度优先搜索(DFS)_安然无虞的博客-CSDN博客
需要强调的是,单单熟悉这些基础知识点是远远不够的,一定要多刷题!刷题!!题!!!
加把劲哦,好,下面说一下竞赛常备的STL

在C语言中,很多东西都需要读者自己去实现,并且实现不好的话还特容易出错,而且有些复杂的操作写起来相当麻烦。因此,作为C语言的plusplus版本的C++,它为使用者提供了标准模板库(STL),其中封装了很多相当实用的容器(铁汁们可以先把容器理解成能够实现很多功能的东西),不需要费力去实现他们的细节而直接调用函数来实现很多功能,十分方便。我们在初学时,不应该被STL这个名字吓到,实际上这是很简单的东西,学会它,对程序的简化有着非常显著的效果。下面介绍几个常用的容器,大家要学会自己动手实现哦,这对掌握它们大有帮助。
STL在广义上分为:容器(contains)、算法(algorithm)和迭代器(iterator);
容器和算法之间通过迭代器进行无缝链接;
容器就是各种数据结构,如vevtor, set, string, map, queue, stack等,用来存放数据,从实现角度来说,STL容器是一种class template(类模板);
算法:各种常用的算法,如sort, find, copy, for_each(遍历)等,从实现的角度来说,STL算法是一种function template(函数模板);
迭代器:扮演了容器和算法之间的胶合剂,可简单地认为它就是指针。
由于都是基础知识点,下面的内容大都是参考胡凡、曾磊老师编写的《算法笔记》一书。
vector翻译为向量,但是这里使用“变长数组”的叫法更容易理解,即“长度根据需要而自动改变的数组”。在考试题中,有时会碰到使用普通数组出现越界访问的情况,这样的话使用vector会让问题的解决便捷许多,而且vector本身可以作为数组使用,在一些元素个数不确定的场合可以更好的节省空间。
如果要使用vector,则需要添加vector头文件,即#include<vector>。除此之外,还需要在头文件下面加上一句"using namespace std;",这样就可以在代码中使用vector了,下面来看vector的一些常用用法。
单独定义一个vector:
vector<typename> name;上面这个定义其实相当于一维数组name[SIZE],只不过其长度可以根据需要进行变化,比较节省空间,通俗来说就是“变长数组”。
和一维数组一样,这里的typename可以是任何基本类型,例如int,double,char,结构体等,也可以是STL标准容器,例如vector,set,queue等。需要注意的是,如果typename也是一个STL容器,定义的时候一定要在>>符号之间加上空格,因为一些比较老的编译器会将它视为移位操作,导致编译错误。下面看一些简单的例子:
vector<int> name;
vector<double> name;
vector<char> name;
vector<node> name;//node是结构体的类型如果typename是vector,就要定义成下面这样:
vector<vector<int> > name;//注意哦,>>之间要加上空格这样的话,很容易联想到二维数组的定义,即元素类型是一维数组的数组。那么vector数组也是一样,即Arrayname[ ]中的每一个元素都是一个vector。初学者可以把vector数组当作两个维都可以变长的二维数组理解。
下面是定义vector数组的方法:
vector<typename> Arrayname[arraySize];例如:
vector<int> vi[100];这样Arrayname[0]~Arrayname[arraySize - 1]中每一个都是一个vector容器。
与vector<vector<int> > name不同的是,这种写法的一维长度已经固定为arraySize,另一维才是“变长”的(注意体会着两种写法的区别哦)
vector一般有两种访问方式:通过下标访问或者通过迭代器访问。下面分别讨论这两种访问方式:
和访问普通的数组是一样的,对一个定义为vector<typename> vi 的vector容器来说,直接访问vi[index]即可(例如vi[0],vi[1])。当然,这里下标是从0 ~ vi.size() - 1。
迭代器(iterator)可以理解为一种类似指针的东西,其定义是:
vector<typename>::iterator it;这样it就是一个vector<typename>::iterator型的变量(虽然这个类型看起来很长),其中typename就是定义vector时填写的类型。下面是typename为int和double的举例:
vector<int>::iterator it;
vector<double>::iterator it;这样就得到了迭代器it,并且可以通过*it来访问vector里的元素。
#include<stdio.h>
#include<vector>
using namespace std;
int main() {
vector<int> vi;
for (int i = 1; i <= 5; i++) {
vi.push_back(i);//push_back(i)在vi的末尾添加元素i,即依次添加1 2 3 4 5
}
//vi.begin()为取vi得首元素地址,而it指向这个地址
vector<int>::iterator it = vi.begin();
for (int i = 0; i < 5; i++) {
printf("%d ", *(it + i));//输出vi[i]
}
return 0;
}输出结果:1 2 3 4 5
不难看出,vi[i] 和 *(vi.begin() + i) 是等价的
既然上面说到了begin()函数的作用是取vi的首元素地址,那么这里还要提到end()函数。不过,和begin()不同的是,end()并不是取vi尾元素的地址,而是取尾元素地址的下一个地址。end()作为迭代器的末尾标志,不储存任何元素。米国人思维比较习惯左闭右开,在这里begin()和end()也是如此。
可能概念听起来太生硬,那我就用三种遍历方式促进大家对上面迭代器的理解。代码里用到的一些常用函数在后面会详细介绍。
第一种遍历方式:利用while循环,定义起始迭代器和结束迭代器。
#include<stdio.h>
#include<vector>
using namespace std;
int main()
{
vector<int> vi;
vi.push_back(10);//push_back()尾插
vi.push_back(20);
vi.push_back(30);
vi.push_back(40);
vector<int>::iterator iBegin = vi.begin();//vi.begin()起始迭代器--指向容器的第一个元素(指针)
vector<int>::iterator iEnd = vi.end();//vi.end()结束迭代器(指向容器的最后一个元素的下一个位置)!!!这里需要特别注意一下
while (iBegin != iEnd)
{
printf("%d ", *(iBegin));
iBegin++;
}
return 0;
}第二种遍历方式:利用for循环
#include<stdio.h>
#include<vector>
using namespace std;
int main()
{
vector<int> vi;
for (int i = 10; i < 50; i += 10)
{
vi.push_back(i);
}
for (vector<int>::iterator it = vi.begin(); it != vi.end(); it++)//起始迭代器-取出容器首元素的地址,而it指向这个地址
{
printf("%d ", *it);
}
return 0;
}【敲黑板】:vector的迭代器不支持it < vi.end()写法,因此循环条件只能用 it != vi.end()
第三种遍历方式:利用专门的遍历算法
#include<stdio.h>
#include<vector>
#include<algorithm>
using namespace std;
void myPrint(int val)
{
printf("%d ", val);
}
int main()
{
vector<int> v;
for (int i = 10; i < 50; i += 10)
{
v.push_back(i);
}
for_each(v.begin(), v.end(), myPrint);
return 0;
}【敲黑板】:最后需要指出的是,在常用STL容器中,只有在vector和string中,才允许使用vi.begin()+3 这种迭代器加上整数的写法。
- push_back()
- pop_back()
- size()
- clear()
- insert()
- erase()
顾名思义,push_back(x) 就是在vector后面添加一个元素x, 时间复杂度为O(1)
示例如下:
#include<stdio.h>
#include<vector>
using namespace std;
int main()
{
vector<int> vi;
for (int i = 1; i <= 3; i++)
{
vi.push_back(i);//将1、2、3依次插入vi末尾
}
for (int i = 0; i < vi.size(); i++)//sizeof()函数会给出vi中元素的个数
{
printf("%d ", vi[i]);
}
return 0;
}有添加自然就有删除,pop_back()用以删除vector的尾元素,时间复杂度为O(1)
示例如下:
#include<stdio.h>
#include<vector>
using namespace std;
int main()
{
vector<int> vi;
for (int i = 1; i <= 3; i++)
{
vi.push_back(i);//将1、2、3依次插入vi末尾
}
vi.pop_back();//删除vi的尾元素3
for (int i = 0; i < vi.size(); i++)
{
printf("%d ", vi[i]);
}
return 0;
}size()用来获得vector中元素的个数,时间复杂度为O(1)。size()返回的是unsigned类型,应该使用%u, 不过一般来说用%d 也不会出现很大问题,这一点对所有STL容器都是一样的。
示例如下:
#include<stdio.h>
#include<vector>
using namespace std;
int main()
{
vector<int> vi;
for (int i = 1; i <= 3; i++)
{
vi.push_back(i);
}
printf("%d\n", vi.size());
return 0;
}clear()用来清空vector中的所有元素,时间复杂度为O(N), 其中N为vector中元素个数
示例如下:
#include<stdio.h>
#include<vector>
using namespace std;
int main()
{
vector<int> vi;
for (int i = 1; i <= 3; i++)
{
vi.push_back(i);
}
vi.clear();
printf("%d\n", vi.size());//0
return 0;
}insert(it, x) 用来向vector的任意迭代器it处插入一个元素x, 时间复杂度为O(N)
示例如下:
#include<stdio.h>
#include<vector>
using namespace std;
int main()
{
vector<int> vi;
for (int i = 1; i <= 5; i++)
{
vi.push_back(i);
}
vi.insert(vi.begin() + 2, -1);//将-1插入vi[2]的位置
for (int i = 0; i < vi.size(); i++)
{
printf("%d ", vi[i]);
}
return 0;
}erase()有两种用法:删除单个元素、删除一个区间内的所有元素。时间复杂度均为O(N)
1.删除单个元素:erase(it) 即删除迭代器为it 处的元素
示例如下:
#include<stdio.h>
#include<vector>
using namespace std;
int main()
{
vector<int> vi;
for (int i = 5; i <= 9; i++)
{
vi.push_back(i);//插入元素5 6 7 8 9
}
//删除8(因为vi.begin()对应的是vi[0], 所以8不是对应vi.begin() + 4)
vi.erase(vi.begin() + 3);
for (int i = 0; i < vi.size(); i++)
{
printf("%d ", vi[i]);//输出5 6 7 9
}
return 0;
}2.删除一个区间内的所有元素,erase(first, last), 即删除[first, last)内的所有元素,注意哦,不包括last
示例如下:
#include<stdio.h>
#include<vector>
using namespace std;
int main()
{
vector<int> vi;
for (int i = 5; i <= 9; i++)
{
vi.push_back(i);//插入5、6、7、8、9
}
vi.erase(vi.begin() + 1, vi.begin() + 4);//删除vi[1],vi[2],v[3]
for (int i = 0; i < vi.size(); i++)
{
printf("%d ", vi[i]);//输出5 9
}
return 0;
}由上面的说法可以知道,如果要删除这个vector内的所有元素,正确的写法应该是vi.erase(vi.begin(), vi.end()),这正对应前面所说,vi.end()就是尾元素地址的下一个地址。当然啦,更方便的清空vector的方法是使用vi.clear()
是不是挺好理解的,哈哈,后面还有呢...别嫌长哦,没多少啦

set翻译为集合,是一个内部自动有序且不含重复元素的容器。在考试中,有可能出现需要去掉重复元素的情况,而且有可能因这些元素比较大或者类型不是int型而不能直接开散列表,在这种情况下就可以用set来保留元素本身而不去考虑它的个数。当然,上面说的情况也可以通过再开一个数组进行下标和元素的对应来解决,但是set提供了更为直观的接口,并且加入set之后可以实现自动排序,因此熟练使用set可以在做某些题时减少思维量。
set最主要的作用是自动去重并按升序排序,因此当我们碰到去重但是不方便直接开数组的情况,可以尝试用set解决。
如果要使用set,需要添加set 头文件,即#include<set> 。除此之外,还需要在头文件下面加上一句:"using namespace std;" ,这样就可以在代码中使用set了。
单独定义一个set:
set<typename> name;其定义的写法其实和vector基本是一样的,或者说其实大部分STL都是这样定义的。在里的typename 依然可以是任何基本类型,例如int, double, char, 结构体等。或者是STL标准容器,例如vector, set, queue等。
和前面vector 中提到的一样,如果typename 是一个STL容器,那么定义是要记得在>>符号之间加上空格。
下面是一些简单的例子:
set<int> name;
set<double> name;
set<char> name;
set<node> name;//node是结构体的类型set数组的定义和vector相同:
set<typename> Arrayname[arraySize];例如:
set<int> a[100];这样a[0] ~ a[99] 中的每一个都是一个set容器。
注意哦,set只能通过迭代器(iterator)访问:
set<typename>::iterator it;例如:
set<int>::iterator:: it;
set<char>::iterator it;这样就得到了it, 并且可以通过*it 来访问set 里的元素。
由于除了vector 和 string 之外的STL容器都不支持*(it + i) 的访问方式,因此只能按如下方式枚举:
#include<stdio.h>
#include<set>
using namespace std;
int main()
{
set<int> st;
st.insert(3);//insert(x)将x插入set中
st.insert(5);
st.insert(2);
st.insert(3);
//注意,不支持it < st.end()的写法
for (set<int>::iterator it = st.begin(); it != st.end(); it++)
{
printf("%d ", *it);//输出2 3 5
}
return 0;
}输出结果:2 3 5
可以发现,set内的元素自动递增排序,且自动去除了重复元素
insert()
find()
erase()
size()
clear()
insert(x),将x插入set容器中,并自动递增排序和去重,时间复杂度为O(logN),其中N为set容器内元素的个数,注意insert()和vector中用法的不同
find(value), 返回set中对应值为value的迭代器,时间复杂度为O(logN),N为set内的元素个数
示例如下:
#include<stdio.h>
#include<set>
using namespace std;
int main()
{
set<int> st;
for (int i = 1; i <= 3; i++)
{
st.insert(i);
}
set<int>::iterator it = st.find(2);//在set中查找2,返回其迭代器
printf("%d\n", *it);//输出200
//也可以写成printf("%d\n", *(st.find(2));
return 0;
}erase()有两种用法:删除单个元素、删除一个区间内的所有元素
1.删除单个元素:删除单个元素也有两种方法
方法一:st.erase(it), it为所需要删除元素的迭代器。时间复杂度为O(1)。结合find()函数来使用
示例如下:
#include<stdio.h>
#include<set>
using namespace std;
int main()
{
set<int> st;
st.insert(100);
st.insert(200);
st.insert(100);
st.insert(300);
st.erase(st.find(100));//利用find()函数找到100,然后用erase()删除它
st.erase(st.find(200));//利用find()函数找到200,然后用erase()删除它
for (set<int>::iterator it = st.begin(); it != st.end(); it++)
{
printf("%d\n", *it);//输出300
}
return 0;
}方法二:st.erase(value), value为所需要删除元素的值。时间复杂度为O(logN),N为set内的元素个数。
示例如下:
#include<stdio.h>
#include<set>
using namespace std;
int main()
{
set<int> st;
st.insert(100);
st.insert(200);
st.erase(100);
for (set<int>::iterator it = st.begin(); it != st.end(); it++)
{
printf("%d\n", *it);//输出200
}
return 0;
}2.删除一个区间内的所有元素:st.erase(first, last)可以删除一个区间内的所有元素,其中first为所需要删除区间的起始迭代器,而last则为所需要删除区间的末尾迭代器的下一个地址,即为删除[first, last),时间复杂度为O(last - first)。注意哦,不包括last。
示例如下:
#include<stdio.h>
#include<set>
using namespace std;
int main()
{
set<int> st;
st.insert(20);
st.insert(10);
st.insert(40);
st.insert(30);
set<int>::iterator it = st.find(30);
st.erase(it, st.end());//删除元素30至末尾之间的元素,即30和40
for (it = st.begin(); it != st.end(); it++)
{
printf("%d ", *it);//输出10 20
}
return 0;
}size()用来获得set内的元素个数,时间复杂度为O(1)
示例如下:
#include<stdio.h>
#include<set>
using namespace std;
int main()
{
set<int> st;
st.insert(2);
st.insert(5);
st.insert(4);
printf("%d\n", st.size());//输出3
return 0;
}clear()用来清空set中的所有元素,时间复杂度为O(N),其中N为set内的元素个数
示例如下:
#include<stdio.h>
#include<set>
using namespace std;
int main()
{
set<int> st;
st.insert(2);
st.insert(5);
st.insert(4);
st.clear();//清空set
printf("%d\n", st.size());//输出0
return 0;
}呃呃,后面还有几个重要的容器,等到过几天再发吧,大家记得将上面的代码自己敲一两遍哦,不要觉得简单就不敲了,锻炼自己的手感很重要哦。
希望上面的内容对大家有所帮助,更加感谢铁汁们花费自己的时间来看我的博文,如果铁汁们能再动动小手给我个三连那就更好啦,码字不易,感谢感谢。求求啦

我想使用spawn(针对多个并发子进程)在Ruby中执行一个外部进程,并将标准输出或标准错误收集到一个字符串中,其方式类似于使用Python的子进程Popen.communicate()可以完成的操作。我尝试将:out/:err重定向到一个新的StringIO对象,但这会生成一个ArgumentError,并且临时重新定义$stdxxx会混淆子进程的输出。 最佳答案 如果你不喜欢popen,这是我的方法:r,w=IO.pipepid=Process.spawn(command,:out=>w,:err=>[:child,:out])
我正在尝试找到一种方法来规范化字符串以将其作为文件名传递。到目前为止我有这个:my_string.mb_chars.normalize(:kd).gsub(/[^\x00-\x7F]/n,'').downcase.gsub(/[^a-z]/,'_')但第一个问题:-字符。我猜这个方法还有更多问题。我不控制名称,名称字符串可以有重音符、空格和特殊字符。我想删除所有这些,用相应的字母('é'=>'e')替换重音符号,并将其余的替换为'_'字符。名字是这样的:“Prélèvements-常规”“健康证”...我希望它们像一个没有空格/特殊字符的文件名:“prelevements_routin
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
我正在使用Maruku,将Markdown(超集)转换为HTML,你知道我该怎么做才能从HTML转换为Markdown吗? 最佳答案 Google发现了一个名为reverse_markdown的ruby脚本.它似乎可以满足您的需求。 关于ruby-on-rails-我需要从HTML转到markdown,有什么建议吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/175162
如何获取外部命令的输出并从中提取值?我有这样的东西:stdin,stdout,stderr,wait_thr=Open3.popen3("#{path}/foobar",configfile)if/exit0/=~wait_thr.value.to_srunlog.puts("Foobarexitednormally.\n")puts"Testcompleted."someoutputvalue=stdout.read("TX.*\s+(\d+)\s+")puts"Outputvalue:"+someoutputvalueend我没有在标准输出上使用正确的方法,因为Ruby告诉我它不能
我遇到了同样的问题here对于python,但对于ruby。我需要输出这样一个小数字:0.00001,而不是1e-5。有关我的特定问题的更多信息,我正在使用f.write("Mynumber:"+small_number.to_s+"\n")输出到一个文件对于我的问题,准确性不是什么大问题,所以只做一个if语句来检查是否small_number那么更通用的方法是什么? 最佳答案 f.printf"Mynumber:%.5f\n",small_number您可以将.5(小数点右侧5位数字)替换为您喜欢的任何特定格式大小,例如,%8
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva