在某些业务场景下,如果一个请求中,需要同时写入多张表的数据或者执行多条sql,为了保证操作的原子性(要么同时成功,要么同时失败),避免数据不一致的情况,我们一般都会用到事务;Spring框架下,我们经常会使用@Transactional注解来管理事务;
本篇介绍Spring的事务注解@Transactional相关的知识,包括事务简介、事务隔离级别、Spring声明式事务实现原理、事务的传播行为、@Transactional的用法及注意事项等,属于Spring的常用注解之一,需要掌握相关知识点;
Spring AOP是实现Spring声明式事务的基础,相关知识可参考我之前的文章《Spring AOP用到的代理模式&SpringAOP实现原理》;
事务指逻辑上的一组操作,组成这组操作的各个单元,要不全部成功,要不全部不成功;下面介绍事务相关的基本概念;
ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability);
在数据库系统中,一个事务是指:由一系列数据库操作组成的一个完整的逻辑过程;例如银行转帐,从原账户扣除金额,以及向目标账户添加金额,这两个数据库操作的总和,构成一个完整的逻辑过程,不可拆分;这个过程被称为一个事务,具有ACID特性;
Spring为事务管理提供了丰富的功能支持,Spring事务管理分为编码式和声明式的两种方式:
编程式事务管理使用TransactionTemplate或者直接使用底层的PlatformTransactionManager;对于编程式事务管理,Spring推荐使用TransactionTemplate;
其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务;声明式事务管理也有两种常用的方式,一种是在XML配置文件中做相关的事务规则声明,另一种是基于@Transactional注解的方式,显然基于注解的方式更简单易用,更清爽;
显然声明式事务要优于编程式事务,这正是Spring倡导的非侵入式的开发方式;声明式事务管理使业务代码不受污染,一个方法需要事务支持,只要加上注解即可;
和编程式事务相比,声明式事务也存在缺点,因为基于Spring AOP(动态代理),声明式事务最细粒度只能作用到方法级别,无法做到像编程式事务那样可以作用到代码块级别;当然也可以将需要进行事务管理的代码块独立为方法;此外,同类方法之间的调用不会被AOP拦截,从而导致事务注解失效;
由于编程式事务是侵入式事务管理,硬编码到项目代码中,影响业务逻辑代码,所以一般来说推荐使用声明式事务来实现事务,其中通过@Transactional注解实现事务被广泛使用;
Spring事务属性对应TransactionDefinition类里面的各个方法,如下所示:
// org.springframework.transaction.TransactionDefinition
public interface TransactionDefinition {
//...
/**
* 返回事务传播行为
*/
int getPropagationBehavior();
/**
* 返回事务的隔离级别,事务管理器根据它来控制另外一个事务可以看到本事务内的哪些数据
*/
int getIsolationLevel();
/**
* 事务超时时间,事务必须在多少秒之内完成
*/
int getTimeout();
/**
* 事务是否只读,事务管理器能够根据这个返回值进行优化,确保事务是只读的
*/
boolean isReadOnly();
/**
* 事务名字
*/
@Nullable
String getName();
}事务属性可以理解成事务的一些基本配置,描述了事务策略如何应用到方法上;事务属性包含了几个方面:传播行为、隔离规则、回滚规则、事务超时、是否只读;
事务的创建需要依赖这些事务属性,包括下面要介绍的@Transactional注解的属性其实就是在设置这些值;
1.3.1 传播方式
如果在开始当前事务之前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为;例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行;Spring定义了七种传播方式:
1. TransactionDefinition.PROPAGATION_REQUIRED:
"如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这是默认值。"
2. TransactionDefinition.PROPAGATION_REQUIRES_NEW:
"创建一个新的事务,如果当前存在事务,则把当前事务挂起。"
3. TransactionDefinition.PROPAGATION_SUPPORTS:
"如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。"
4. TransactionDefinition.PROPAGATION_NOT_SUPPORTED:
"以非事务方式运行,如果当前存在事务,则把当前事务挂起。"
5. TransactionDefinition.PROPAGATION_NEVER:
"以非事务方式运行,如果当前存在事务,则抛出异常。"
6. TransactionDefinition.PROPAGATION_MANDATORY:
"如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。"
7. TransactionDefinition.PROPAGATION_NESTED:
"如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;"
"如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。"工作开发中,我们最常用的就是默认的事务传播行为:如果外层方法有事务则加入进去,没有则在当前方法创建一个事务;关于这几种事务传播行为的测试验证和介绍,可以参考这篇文章《详解Spring事务的传播机制 - 知乎》;
1.3.2 隔离规则
事务的隔离级别是指若干个并发的事务之间的隔离程度,它定义了一个事务可能受其他并发事务影响的程度;多个事务并发运行,可能会导致以下的问题:
可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
为了避免事务并发状态下脏读、不可重复读、幻读的产生,Spring中定义了五种隔离规则:
1. @Transactional(isolation = Isolation.DEFAULT)
"使用后端数据库默认的隔离级别 对于MYSQL来说就是可重复读"
1. @Transactional(isolation = Isolation.READ_UNCOMMITTED)
"是最低的隔离级别,允许读取尚未提交的数据变更(会出现脏读,不可重复读),基本不使用"
2. @Transactional(isolation = Isolation.READ_COMMITTED)
"允许读取并发事务已经提交的数据(会出现不可重复读和幻读)"
3. @Transactional(isolation = Isolation.REPEATABLE_READ)
"事物开启后,对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改(会出现幻读)"
4. @Transactional(isolation = Isolation.SERIALIZABLE)
"最高的隔离级别,完全服从ACID的隔离级别,也是最慢的事务隔离级别,因为它通常是通过完全锁定事务相关的数据库表来实现的"说明:
1.3.3 回滚规则
事务回滚规则定义了哪些异常会导致事务回滚而哪些不会;默认情况下,只有未检查异常(RuntimeException和Error类型的异常)会导致事务回滚,而在遇到检查型异常时不会回滚; 但是可以声明事务在遇到特定的检查型异常时像遇到运行期异常那样回滚,并且相反,还可以声明事务遇到特定的异常不回滚,即使这些异常是运行期异常;
1.3.4 事务超时
为了使应用程序很好地运行,事务不能运行太长的时间,因为事务可能涉及对后端数据库的锁定,会占用数据库资源;事务超时就是事务的一个定时器,在特定时间内事务如果没有执行完毕,那么就会自动回滚,而不是一直等待其结束;
1.3.5 是否只读
如果在一个事务中所有关于数据库的操作都是只读的,也就是说,这些操作只读取数据库中的数据,而并不更新数据, 这个时候我们应该给该事务设置只读属性,这样可以帮助数据库引擎优化事务,从而提升数据库读写效率;
Spring AOP将通用的功能横向抽取出来作为切面,避免非业务代码侵入到业务代码中;通过@Transactional注解就能让Spring为我们管理事务,免去了重复的事务管理逻辑,减少对业务代码的侵入,让开发人员能够专注于业务层面开发;
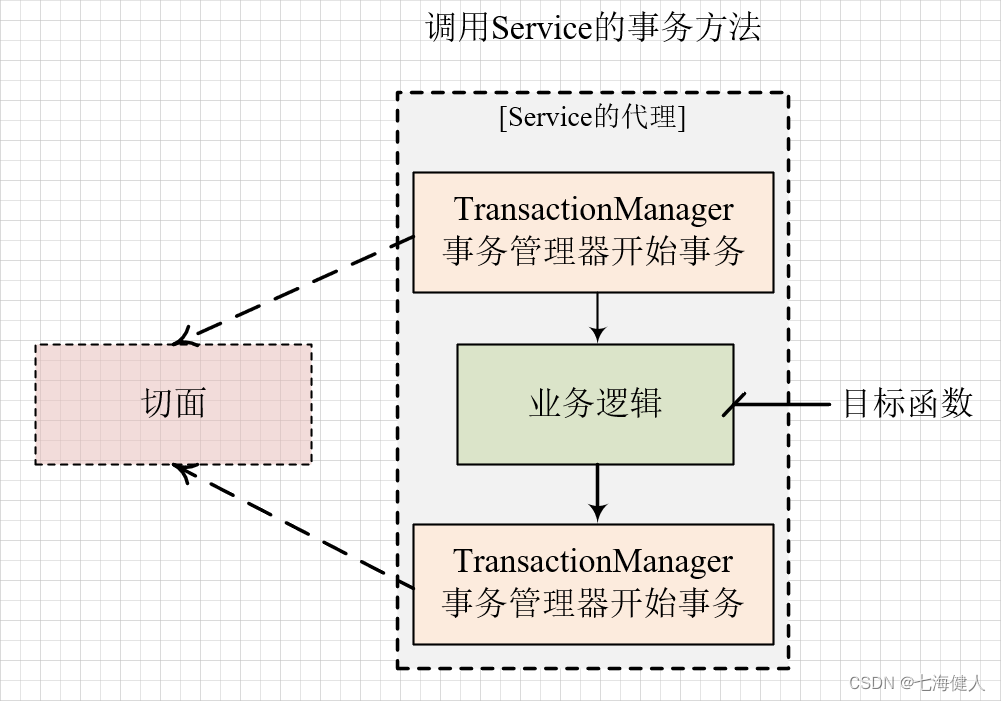
结合上面的图,我们关注两点:
(1)判断生成代理对象:通过@Transactional注解来标记方法(定义切点),在Bean初始化过程中判断是否要对当前Bean创建代理对象,并且拿到@Transactional注解的属性;
(2)定义代理对象的回调逻辑,即执行代理逻辑:在执行目标方法前打开事务,执行过程中捕获异常执行回滚逻辑,在执行完目标方法后提交事务;
源码分析请参考我的文章《Spring事务注解@Transactional的源码分析》,将源码的流画张图总结下:

下面介绍@Transctional的用法,包括:注解参数设置,事务方法调用的几种不同case,事务如何回滚,常见的事务失效的场景以及使用建议;
// org.springframework.transaction.annotation.Transactional
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Transactional {
/**
* 当在配置文件中有多个 TransactionManager , 可以用该属性指定选择哪个事务管理器。
*/
@AliasFor("transactionManager")
String value() default "";
/**
* 同上。
*/
@AliasFor("value")
String transactionManager() default "";
/**
* 事务的传播行为,默认值为 REQUIRED。
*/
Propagation propagation() default Propagation.REQUIRED;
/**
* 事务的隔离规则,默认值采用 DEFAULT。
*/
Isolation isolation() default Isolation.DEFAULT;
/**
* 事务超时时间。
*/
int timeout() default TransactionDefinition.TIMEOUT_DEFAULT;
/**
* 是否只读事务
*/
boolean readOnly() default false;
/**
* 用于指定能够触发事务回滚的异常类型。
*/
Class<? extends Throwable>[] rollbackFor() default {};
/**
* 同上,指定类名。
*/
String[] rollbackForClassName() default {};
/**
* 用于指定不会触发事务回滚的异常类型
*/
Class<? extends Throwable>[] noRollbackFor() default {};
/**
* 同上,指定类名
*/
String[] noRollbackForClassName() default {};
}关于value和transactionManager属性的说明
这两个属性是一个意思,当配置了多个事务管理器时,可以使用该属性指定选择哪个事务管理器;大多数项目只需要一个事务管理器,然而,有些项目为了提高效率、或者有多个完全不同又不相干的数据源,从而使用了多个事务管理器;
Spring的Transactional管理已经考虑到了这一点,首先定义多个transactional manager,并为qualifier属性指定不同的值;然后在需要使用@Transactional注解的时候指定TransactionManager的qualifier属性值或者直接使用bean名称,配置和代码使用的例子:
@Override
@Transactional(transactionManager = "txManager#singleton", rollbackFor = Exception.class)
public Boolean updateModuleStatus(Integer bizType, String moduleCode, Integer status) {
//如果数据库无此数据,返回异常,封装返回结果Boolean.FALSE
long moduleId = Optional.ofNullable(moduleDAO.selectByTypeAndCode(bizType, moduleCode))
.orElseThrow(() -> new BusinessException(ResultCodeEnum.DATABASE_NO_SUCH_RECORD, Boolean.FALSE))
.getId();
try {
moduleDAO.updateStatusByModuleId(moduleId, status);
// 更新缓存
bizCacheService.refreshModulesCache(bizType);
return Boolean.TRUE;
} catch (Exception e) {
log.error("[SERIOUS_BUSINESS]update module status error! e:{}", e);
throw new BusinessException(ResultCodeEnum.SERVER_BUSYNESS, Boolean.FALSE);
}
}@Transactional注解可以作用于哪些地方?
@Transactional可以作用在接口、类、类方法;
3.2.1 同一个类中函数相互调用
假设:同一个类AClass中,有两个方法aFunction、aInnerFunction;aFunction调用aInnerFunction;aFunction函数被其他类调用;
case1:两个方法都添加了@Transactional注解,aInnerFunction使用Propagation.REQUIRES_NEW传播方式;aInnerFunction抛异常;
@Transactional(rollbackFor = Exception.class)
public void aFunction() {
//todo: 数据库操作A(增,删,该)
aInnerFunction(); // 调用内部没有添加@Transactional注解的函数
}
@Transactional(propagation = Propagation.REQUIRES_NEW, rollbackFor = Exception.class)
public void aInnerFunction() {
//todo: 操作数据B(做了增,删,改 操作)
throw new RuntimeException("函数执行有异常!");
}结果:两个函数操作的数据都会回滚;同类调用,不涉及事务传播,相当于aInnerFunction的代码加到了aFunction方法内;
case2: aFunction不添加注解,aInnerFunction添加注解;aInnerFunction抛异常;
public void aFunction() {
//todo: 数据库操作A(增,删,该)
aInnerFunction(); // 调用内部没有添加@Transactional注解的函数
}
@Transactional(rollbackFor = Exception.class)
public void aInnerFunction() {
//todo: 操作数据B(做了增,删,改 操作)
throw new RuntimeException("函数执行有异常!");
}结果:两个函数对数据库的操作都不会回滚;因为同类方法调用不会调用代理对象的方法,@Transactional注解添加和没添加一样;
3.2.2 不同类中函数相互调用
假设:两个类AClass、BClass;AClass类有aFunction、BClass类有bFunction;AClass类aFunction调用BClass类bFunction;AClass类的aFunction被其他类调用;。
case1:aFunction添加注解,bFunction不添加注解;bFunction抛异常;
@Service
public class AClass {
@Autowired
private BClass bClass;
@Transactional(rollbackFor = Exception.class)
public void aFunction() {
//todo: 数据库操作A(增,删,该)
bClass.bFunction();
}
}
@Service
public class BClass {
public void bFunction() {
//todo: 数据库操作A(增,删,该)
throw new RuntimeException("函数执行有异常!");
}
}结果:两个函数对数据库的操作都回滚了;相当于aFunction执行时抛了异常;此时,bFunction如果打上事务注解并且使用默认的事务传播方式,结果也一样;因为两个方法处于同一个事务内;
case2:aFunction、bFunction两个函数都添加事务注解;bFunction抛异常;aFunction抓出异常并吞掉异常;
@Service
public class AClass {
@Autowired
private BClass bClass;
@Transactional(rollbackFor = Exception.class)
public void aFunction() {
//todo: 数据库操作A(增,删,该)
try {
bClass.bFunction();
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Service
public class BClass {
@Transactional(rollbackFor = Exception.class)
public void bFunction() {
//todo: 数据库操作A(增,删,该)
throw new RuntimeException("函数执行有异常!");
}
}结果:两个函数数据库操作都没成功,而且还抛异常了org.springframework.transaction.UnexpectedRollbackException: Transaction rolled back because it has been marked as rollback-only;
可以这么理解,两个函数用的是同一个事务;bFunction函数抛了异常,调了事务的rollback函数,并且事务被标记了只能rollback了;程序继续执行,aFunction函数里面把异常给抓出来了,这个时候aFunction函数没有抛出异常,既然你没有异常那事务就需要提交,会调事务的commit函数;而之前这个事务已经被标记了只能rollback-only(因为是同一个事务),因此直接就抛异常了,不让调了;
case3:aFunction、bFunction两个函数都添加注解;bFunction抛异常,aFunction抓出异常;这里要注意bFunction函数@Transactional注解我们是有变化的,加了一个参数propagation = Propagation.REQUIRES_NEW,控制事务的传播行为,表明是一个新的事务;其实情况3就是来解决情况2的问题的;
@Service
public class AClass {
@Autowired
private BClass bClass;
@Transactional(rollbackFor = Exception.class)
public void aFunction() {
//todo: 数据库操作A(增,删,该)
try {
bClass.bFunction();
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Service
public class BClass {
@Transactional(propagation = Propagation.REQUIRES_NEW, rollbackFor = Exception.class)
public void bFunction() {
//todo: 数据库操作A(增,删,该)
throw new RuntimeException("函数执行有异常!");
}
}结果:bFunction函数里面的操作回滚了,aFunction里面的操作成功了;有了前面情况2的理解。这种情况也很好解释,因为两个函数不是同一个事务了,所以bFunction抛异常只会导致bFunction的回滚,不影响aFunction所在事务的正常执行;
@Transactional默认只能回滚RuntimeException和RuntimeException下面的子类抛出的异常,不能回滚Exception异常;如果需要支持回滚Exception异常,需要显示的指明,如@Transactional(rollbackFor = Exception.class);
介绍几种常见的事务实效的场景,这里引用一张图来说明;

图转自:《Spring事务(注解 @Transactional )失效的12种场景_悬浮海的博客》
3.4.1 打了@Transactional但是事务不生效
(1)@Transactional注解未打在public方法上
Java的访问权限主要有四种:private、default、protected、public;如果事务方法定义了错误的访问权限(非public方法),会导致事务失效;
原因:根据我的文章《Spring事务注解@Transactional的源码分析》里面的判断当前方法适用于事务切面,计算事务属性的AbstractFallbackTransactionAttributeSource#computeTransactionAttribute方法里有段逻辑,如下,指出"事务不作用于非public方法";

(2)目标方法用final修饰
某个方法不想被子类重写,可以将该方法定义成final的;如果将事务方法定义成final,会导致事务失效;
原因:Spring事务基于Spring AOP,通过JDK动态代理或者CGlib代理,在代理类中实现的事务功能;但如果某个方法用final修饰了,那么在它的代理类中,就无法重写该方法;同样,static修饰的方法,同样无法通过动态代理,变成事务方法;
(3)同一个类中的方法直接内部调用
原因:方法被事务管理是因为Apring AOP为其生成代理了对象,但是直接this调用同类方法,调用的是目标类对象的方法,而非代理类方法,因此,在同类中的方法直接内部调用,会导致事务失效;
如果有些场景,确实想在同一个类的某个方法中,调用当前类的另外一个事务方法,该怎么办呢?
@Servcie
public class ServiceA {
public void save(User user) {
queryData1();
queryData2();
((ServiceA)AopContext.currentProxy()).doSave(user);
}
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
addData1();
updateData2();
}
}同一个类方法调用事务失效相关的文章:
(4)事务方法所在的类未被Spring管理
使用Spring事务的前提是:对象要被Spring IOC容器管理,需要创建bean实例;打了注解,但是忘了在当前类加@Service注解,导致事务不生效,也是小白常见的编码错误;
(5)多线程调用
如果两个方法不在同一个线程中,获取到的数据库连接不一样,从而是两个不同的事务;如果看过Spring事务源码,能会知道Spring的事务是通过数据库连接Connection来实现的;当前线程中保存了一个map,key是数据源,value是数据库连接;

我们说的同一个事务,其实是指同一个数据库连接,只有拥有同一个数据库连接才能同时提交和回滚;如果在不同的线程,拿到的数据库连接肯定是不一样的,所以是不同的事务;
(6)存储引擎不支持事务
如MYSQL的myisam存储引擎不支持事务,有些老项目中,可能还在用它;在开发的过程中,如果发现某张表的事务一直都没有生效,可以检查下那张表的存储引擎,看是否支持事务;
(7)未开启事务
这个原因极其容易被忽略;
如果你使用的是Springboot项目,那么你很幸运,因为Springboot通过DataSourceTransactionManagerAutoConfiguration类,已经默默的帮你开启了事务,只需要配置数据源spring.datasource相关参数即可;
但如果你使用的还是传统的老Spring项目,则需要在applicationContext.xml文件中,手动配置事务相关参数;
3.4.2 事务未回滚
(1)使用了错误的传播特性,如新开启了一个事物,可能导致新事物和原事务不会一起回滚;
(2)自己吞了异常,忘记抛出了;或者抛出了非运行时异常,但又没有配置到注解上;因为Spring事务默认情况下只会回滚RuntimeException(运行时异常)和Error(错误);
本节参考 :《Spring事务(注解 @Transactional )失效的12种场景_悬浮海的博客》
1. 要知道@Transactional注解里面每个属性的含义,@Transactional注解属性就是来控制事务属性的,通过这些属性来生成事务;
2. 要明确我们添加的@Transactional注解会不会起作用;如@Transactional注解在外部调用的函数上才有效果,直接内部调用无效;
3. 显示的指定rollbackFor注解属性,即使rollbackFor有默认值,但阿里巴巴开发者规范中,还是要求开发者重新指定该参数,因为如果使用默认值,一旦程序抛出了非运行时的其他Exception,事务不会回滚,这会出现很大的bug;
4. 要明确事务的作用范围,有@Transactional的函数调用有@Transactional的函数的时候,进入第二个函数的时候是新的事务,还是沿用之前的事务;稍不注意就会抛UnexpectedRollbackException异常;
5. 不要滥用事务,避免大事务,事务会影响数据库的读写性能,非必要场景不建议使用;适当的对方法里面的实务操作拆分执行;
上面的这些内容都是基于@Transactional注解的,这种事务使用方式叫做声明式事务;其实,Spring还提供了另外一种创建事务的方式,即通过硬编码的方式使用Spring中提供的事务相关的类来控制事务,这种方式叫做编程式事务;
编程式事务主要有两种用法:1)通过事务管理器PlatformTransactionManager控制事务 和2)通过事务模板TransactionTemplate控制事务;常用的是TransactionTemplate,如下:
@Resource
private DataSourceTransactionManager transactionManager;
// 同类方法调用 使用编程式事务
TransactionTemplate transactionTemplate = new TransactionTemplate(transactionManager);
transactionTemplate.execute(transactionStatus -> {
queryData();
insertData();
return Boolean.TRUE;
});
});的确,看起来比较复杂,代码中融入了大量Spring的代码;但是编程式事务有时候也能带来一些好处:
1. 避免由于Spring AOP问题导致的事务失效的问题,如同类事务方法调用;
2. 可以对代码块加事务,能够更小粒度的更精确的控制事务的范围,一定程度避免事务滥用;
建议:如果项目中有些业务逻辑比较简单,而且不经常变动,建议使用@Transactional注解开启事务,因为它更简单,开发效率更高,但是千万要小心事务失效的问题;而使用编程式事务有时可以帮我们解决@Transactional注解声明式事务解决不了的问题,如同类调用;二者可以配合使用;
(1)编程式事务
/**
* 执行投递并将重试次数+1 编程式事务
*
* @param reqDTO
* @param recordInDB
*/
public void deliverMessageThenUpdateRetryTimes(MessageDeliverTaskReqDTO reqDTO, MessageDeliverTaskDO recordInDB) {
// 同类方法调用使用 编程式事务
TransactionTemplate transactionTemplate = new TransactionTemplate(transactionManager);
transactionTemplate.execute(transactionStatus -> {
final Long recordId = recordInDB.getId();
// [投递消息-子类实现]
deliverMessage(reqDTO, recordInDB);
// 更新 不需要回执则更形成`已处理`
final Integer messageStatus = Boolean.FALSE.equals(reqDTO.getNeedCallback()) ? MessageStatusEnum.HANDLED.getType() : null;
final int update = messageDeliverTaskDAO.plusRetryTime(recordId, messageStatus);
log.warn("deliverMessageThenUpdateRetryTimes_suc. [recordId={} reqDTO={}]", recordId, JSON.toJSONString(reqDTO));
return update > 0;
});
}(2)先提交事务再执行RPC(RPC需要剥离出事务)
/**
* 会员订单后置处理
*/
private void postProcessHandleMemberOrder(MemberOrderDO memberOrderDO) {
if (MemberOrderStatusEnum.PAID.getStatus().equals(memberOrderDO.getStatus())) {
// fixme 要求一定要更新订单表和消息入库 才能发消息 极端情况RPC发消息调用瞬间 core回调 但是DB事务还没有提交完成 RPC应该剥离出事务 在事务提交后执行
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronizationAdapter() {
@Override
public void afterCommit() {
// 支付成功发消息
Map<String, String> msgBody = buildPaySucMsgBody(memberOrderDO);
boolean sendMsgResult = notifyService.sendPayMsg(msgBody);
if (sendMsgResult) {
log.warn("send paySucMsg to core sus.[orderNo={} msg={}]", memberOrderDO.getOrderNo(), JSON.toJSONString(msgBody));
} else {
log.warn("send paySucMsg to core failed.[orderNo={} msg={}]", memberOrderDO.getOrderNo(), JSON.toJSONString(msgBody));
}
if (StringUtils.isNotBlank(memberOrderDO.getAgreementNo())) {
// 支付成功后,查询是否有需要投递的签约信息,用于处理微信纯签约,新用户购买,在收到支付回调之后,需要进行处理
MessageDeliverDO messageDeliverDO = messageDeliverDAO.queryByOrderAndType(memberOrderDO.getAgreementNo(), MessageDeliverOrderTypeEnum.AGREEMENT.getType());
if (messageDeliverDO != null) {
// 发送签约信息
Map<String, String> signedMsgBody = JSON.parseObject(messageDeliverDO.getMsgBody(), Map.class);
boolean sendSignedMsgResult = notifyService.sendSignMsg(signedMsgBody);
log.warn("pay_suc_send_signSucMsg_to_core_sus.[orderNo={} res={} msg={}]", memberOrderDO.getOrderNo(), sendSignedMsgResult, JSON.toJSONString(sendSignedMsgResult));
}
}
}
});
}
}
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
我正在使用Maruku,将Markdown(超集)转换为HTML,你知道我该怎么做才能从HTML转换为Markdown吗? 最佳答案 Google发现了一个名为reverse_markdown的ruby脚本.它似乎可以满足您的需求。 关于ruby-on-rails-我需要从HTML转到markdown,有什么建议吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/175162
保存成功后可以回滚吗?让我有一个带有属性名称、电子邮件等的用户模型。例如u=User.newu.name="test_name"u.email="test@email.com"u.save现在记录将成功保存在数据库中,之后我想回滚我的事务(不是销毁或删除)。有什么想法吗? 最佳答案 您可以通过交易来做到这一点,请参阅http://markdaggett.com/blog/2011/12/01/transactions-in-rails/例子:User.transactiondoUser.create(:username=>'Nemu
我无法运行Spring。这是错误日志。myid-no-MacBook-Pro:myid$spring/Users/myid/.rbenv/versions/1.9.3-p484/lib/ruby/gems/1.9.1/gems/spring-0.0.10/lib/spring/sid.rb:17:in`fiddle_func':uninitializedconstantSpring::SID::DL(NameError)from/Users/myid/.rbenv/versions/1.9.3-p484/lib/ruby/gems/1.9.1/gems/spring-0.0.10/li