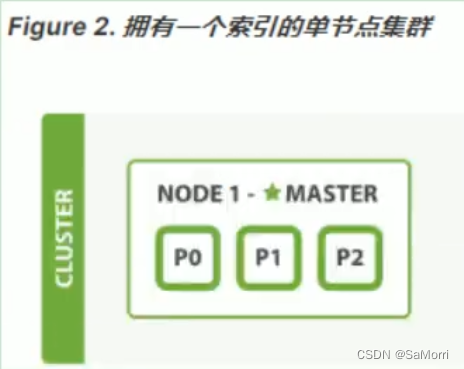
集群: 一个或者多个具有相同 cluster.name 配置的节点组成集群
节点:一个运行的Elasticsearch实例为一个节点
分片:底层的工作单元,简单来说它就是Lucene的一个实例
PUT /blogs{
"settings" : {
"number_of_shards" : 3, //blogs的数据分为3片存储
"number_of_replicas" : 1 //每一片的副本为1
}
}
Elasticsearch的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是集群健康﹐它在 status字段中展示为green、yellow、red
GET /_cluster/health
status字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
当你在同一台机器上启动了第二个节点时,只要它和第一个节点有同样的cluster.name配置,它就会自动发现集群并加入到其中。但是在不同机器上启动节点的时候,为了加入到同一集群,你需要配置一个可连接到的单播主机列表。详细信息请查看最好使用单播代替组播
 此时, cluster-health 现在展示的状态为green ,这表示所有6个分片(包括3个主分片和3个副本分片)都在正常运行。我们的集群现在不仅仅是正常运行的,并且还处于始终可用的状态。
此时, cluster-health 现在展示的状态为green ,这表示所有6个分片(包括3个主分片和3个副本分片)都在正常运行。我们的集群现在不仅仅是正常运行的,并且还处于始终可用的状态。

Node 1和Node 2上各有一个分片被迁移到了新的Node 3节点,现在每个节点上都拥有2个分片,而不是之前的3个。这表示每个节点的硬件资源(CPU, RAM, IO)将被更少的分片所共享,每个分片的性能(负载能力)将会得到提升。
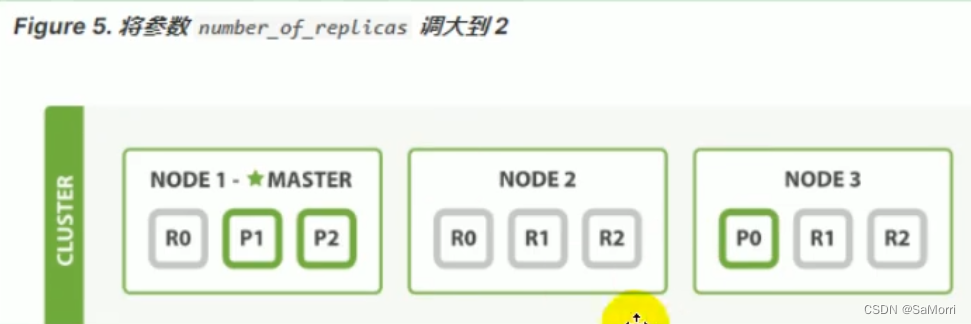
在运行中的集群上是可以动态调整副本分片数目的,我们可以按需伸缩集群。让我们把副本数从默认的1调整到2:
PUT /blogs/_settings{
"number_of_replicas" :2
}
blogs 索引现在拥有9个分片:3个主分片和6个副本分片。这意味着我们可以将集群扩容到9个节点,每个节点上一个分片。相比原来3个节点时,集群搜索性能可以提升3倍。

1、主节点
主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作。Elasticsearch,中的主节点的工作量相对较轻,用户的请求可以发往集群中任何一个节点,由该节点负责分发和返回结果,而不需要经过主节点转发。而主节点是由候选主节点通过ZenDiscovery,机制选举出来的,所以要想成为主节点,首先要先成为候选主节点。
2、候选主节点
在elasticsearch,集群初始化或者主节点宕机的情况下,由候选主节点中选举其中一个作为主节点。指定候选主节点的配置为: node.master: true(只要配置了这个,都有资格成为主节点)
当主节点负载压力过大,或者集中环境中的网络问题,导致其他节点与主节点通讯的时候,主节点没来的及响应,这样的话,某些节点就认为主节点宕机,重新选择新的主节点,这样的话整个集群的工作就有问题了,比如我们集群中有10个节点,其中7个候选主节点,1个候选主节点成为了主节点,这种情况是正常的情况。但是如果现在出现了我们上面所说的主节点响应不及时,导致其他某些节点认为主节点宕机而重选主节点,那就有问题了,这剩下的6个候选主节点可能有3个候选主节点去重选主节点,最后集群中就出现了两个主节点的情况,这种情况官方成为"脑裂现象";
集群中不同的节点对于master的选择出现了分歧,出现了多个master竞争,导致主分片和副本的识别也发生了分歧,对一些分歧中的分片标识为了坏片。
3、数据节点
数据节点负责数据的存储和相关具体操作,比如 CRUD、搜索、聚合。所以,数据节点对机器配置要求比较高,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统CPU、Memory和IO的性能消耗都很大。通常随着集群的扩大,需要增加更多的数据节点来提高可用性。指定数据节点的配置: node.data: true
elasticsearch是允许一个节点既做候选主节点也做数据节点的,但是数据节点的负载较重,所以需要考虑将二者分离开,设置专用的候选主节点和数据节点,避免因数据节点负载重导致主节点不响应。
4、客户端节点
客户端节点就是既不做候选主节点也不做数据节点的节点,只负责请求的分发、汇总等等,但是这样的工作,其实任何一个节点都可以完成,因为在elasticsearch,中一个集群内的节点都可以执行任何请求,其会负责将请求转发给对应的节点进行处理。所以单独增加这样的节点更多是为了负载均衡。指定该节点的配置为:
node.master: false
node.data: false
5、脑裂问题成因与解决方案
脑裂问题解决方案:
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
我有一个关于配置elasticsearch以连接AWSelasticsearch服务以在生产环境中运行项目的问题。我的gem文件:gem'searchkick'gem'faraday_middleware-aws-signers-v4'gem'aws-sdk','~>2'gem"elasticsearch",">=1.0.15"引用:https://github.com/ankane/searchkick我的config/initializers/elasticsearch.rb文件:require"faraday_middleware/aws_signers_v4"ENV["ELAS
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172