本文主要描述reids数据结构和底层数据结构的实现,用于熟悉redis的底层数据结构实现原理,下图是reids的整个数据结构组成。这篇文章主要介绍value对象这部分数据结构
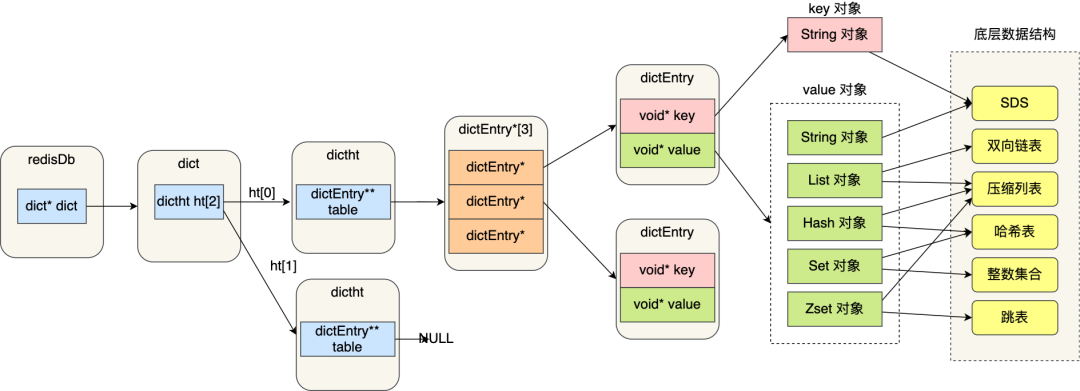
string结构对应底层SDS数据结构,SDS是redis最简单的数据结构,一般用于分布式锁和Json序列化对象存储。
SDS命令:
设置SDS的值 set <key> <value>:SET NAME XIAOMING
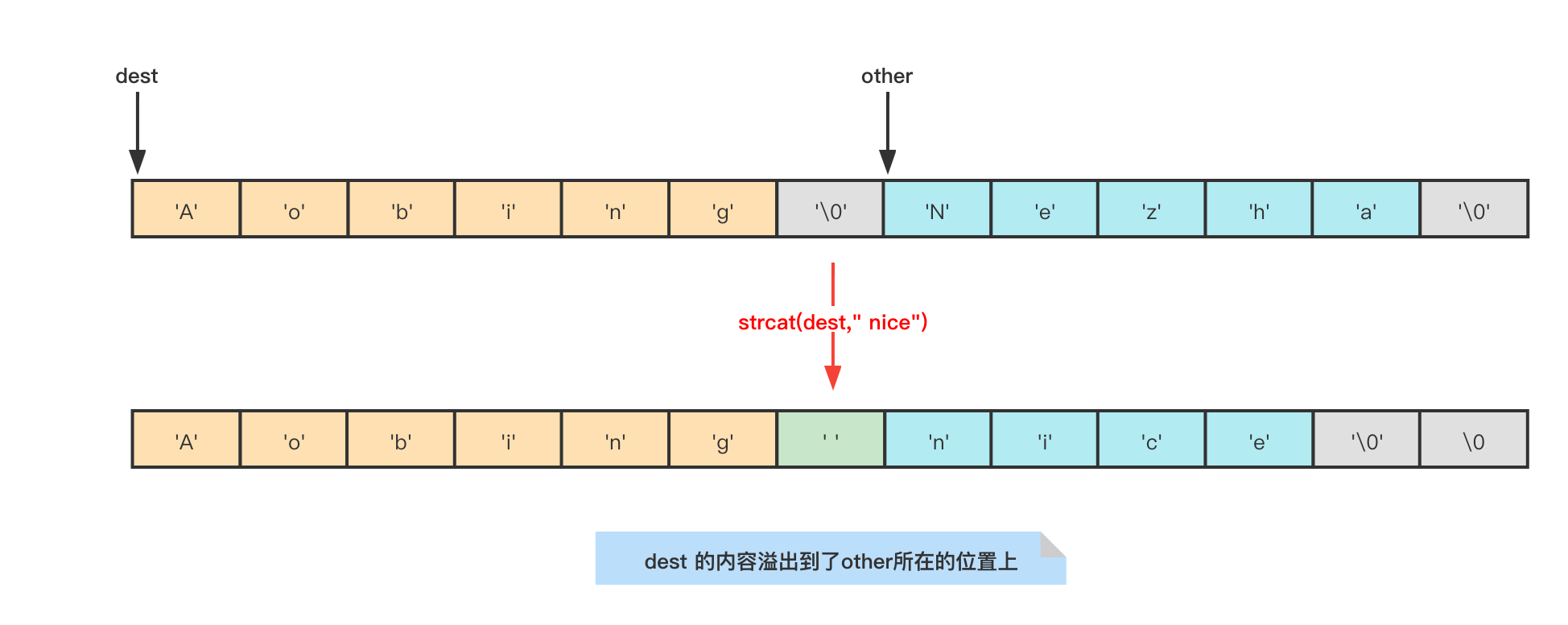
C语言字符串的问题
字符串合并时需要手动分配空间,容易导致内存溢出。
char * __cdecl strcat (char * dst, const char * src)
{
char * cp = dst;
while( *cp )
cp++;
while( *cp++ = *src++ ) ;
return( dst );
} 
SDS数据结构:

面对上述的几个问题,SDS如何解决:
字符串合并分配空间时,需要len相加,然后看当前字符串alloc中的空间是否足够承载合并后的字符,不够直接申请空间
sds sdscatsds(sds s, const sds t) {
return sdscatlen(s, t, sdslen(t));
}
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
极致的优化:
SDS实际还分为了物种类型的SDS,主要是用来分别SDS存储的数据大小使用哪种数据结构,他们分别是:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
typedef struct __attribute__ ((__packed__)) 设置内存不对齐,固定数据在内存分配的大小,不需要编译器优化补全
struct my
{
char ch;
int a;
} sizeof(int)=4;sizeof(my)=8;(非紧凑模式)
struct my{
char ch;
int a;
}__attrubte__ ((packed)) sizeof(int)=4;sizeof(my)=5
为什么Reids不补全?因为redis中的SDS中指针指的是buf数组,获取其他字段是只需要移动申明时的空间就可以得到其他字段,如果补全的话不清楚最大数组会补全到多少
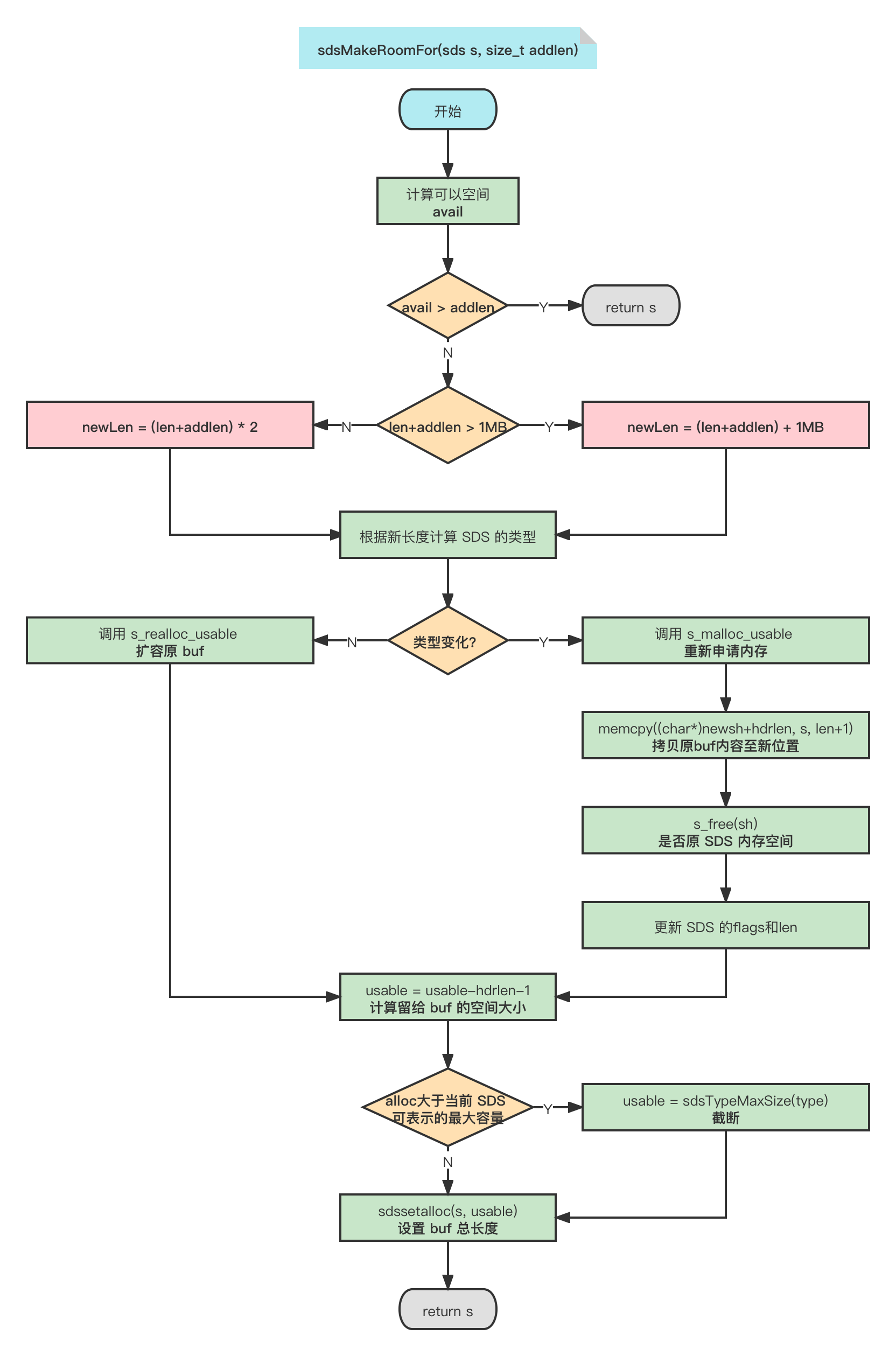
自动扩容机制总结:
扩容阶段:
若 SDS 中剩余空闲空间 avail 大于新增内容的长度 addlen,则无需扩容;
若 SDS 中剩余空闲空间 avail 小于或等于新增内容的长度 addlen:
若新增后总长度 len+addlen < 1MB,则按新长度的两倍扩容;
若新增后总长度 len+addlen > 1MB,则按新长度加上 1MB 扩容。
内存分配阶段:
根据扩容后的长度选择对应的 SDS 类型:
若类型不变,则只需通过 s_realloc_usable扩大 buf 数组即可;
若类型变化,则需要为整个 SDS 重新分配内存,并将原来的 SDS 内容拷贝至新位置。
压缩列表在Redis中的List和Hash中都有使用,一般存储一个序列的对象。
List命令:
Hash命令:
zipList数据结构:
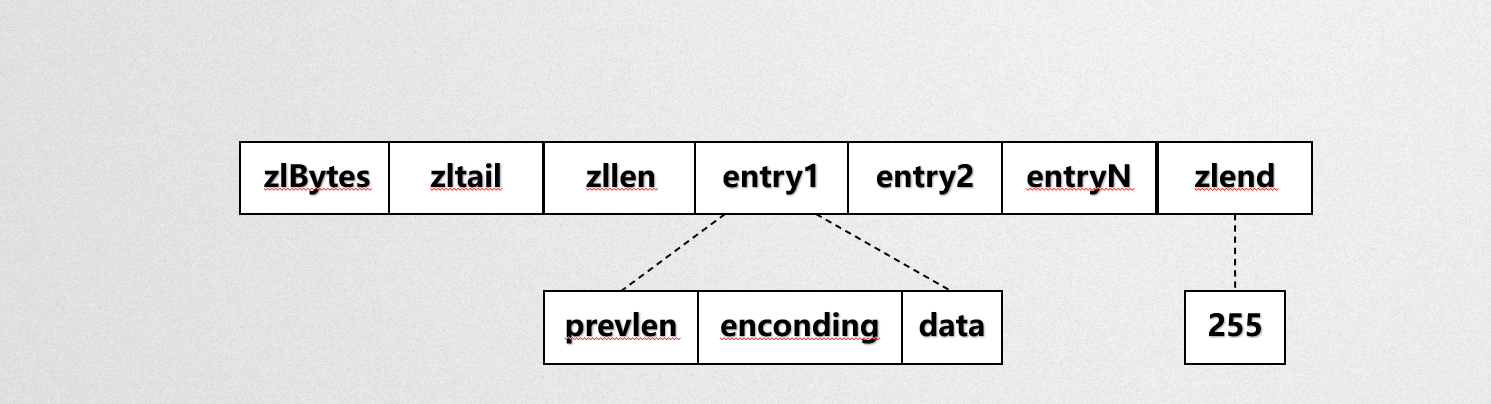
zlBytes:压缩列表存储的字节数
zltail:压缩列表尾部节点
zllen:压缩列表长度
entry:压缩列表元素
zlend:压缩列表结尾标识,永远都是255
entry:{
prevlen:前继节点长度
encoding:编码格式
data:数据内容
}
ziplist优点:
zipList数据结构解读:
Q:为什么结尾标识一直是255?
A:这个标识是redis中固定的结尾是255,在prevLen中存储的格式,当前前一个数据长度小于254,使用1个字节存储前一个节点的长度,如果大于254就用5个字节存储前一个节点的长度。定义成255是一个主要的标识,识别是否是结尾
prevlen:
|
字节长度
|
存储格式
|
|---|---|
| 1~253 | 8bit 1~253 |
| 254 |
8bit 32bit 254 prevLen |
Q:连锁更新的问题?
A:每个entry存储着前一个节点的长度,用于遍历查找时使用,这也就是说当一个节点更新内容时,需要更新后继节点中的prevlen,更新节点prevlen从1个字节到5个字节,后续的所有节点都需要更新,这就是典型的连锁更新问题。
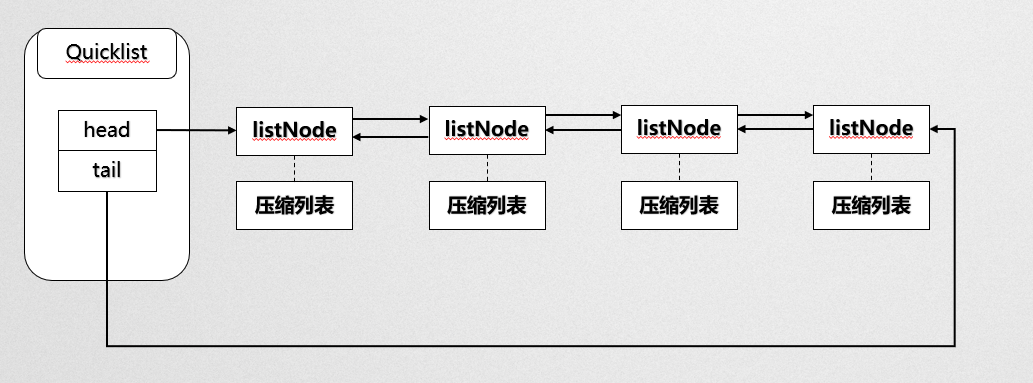
在 redis 3.2 之后,list 的底层实现变为快速列表 quicklist,快速列表是 linkedlist 与 ziplist 的结合: quicklist 包含多个内存不连续的节点,但每个节点本身就是一个 ziplist。
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz;
unsigned int count : 16;
unsigned int encoding : 2;
unsigned int container : 2;
unsigned int recompress : 1;
unsigned int attempted_compress : 1;
unsigned int extra : 10;
} quicklistNode;
typedef struct quicklistLZF {
unsigned int sz;
char compressed[];
} quicklistLZF;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count;
unsigned long len;
int fill : 16;
unsigned int compress : 16;
} quicklist;quick 中使用之前的LinkedList和ZipList存储数据,quicklist.compress 指定在双向列表中前后有几个节点不进行压缩,这是方便在遍历时不用从zipList寻址。
quickList数据结构优点:
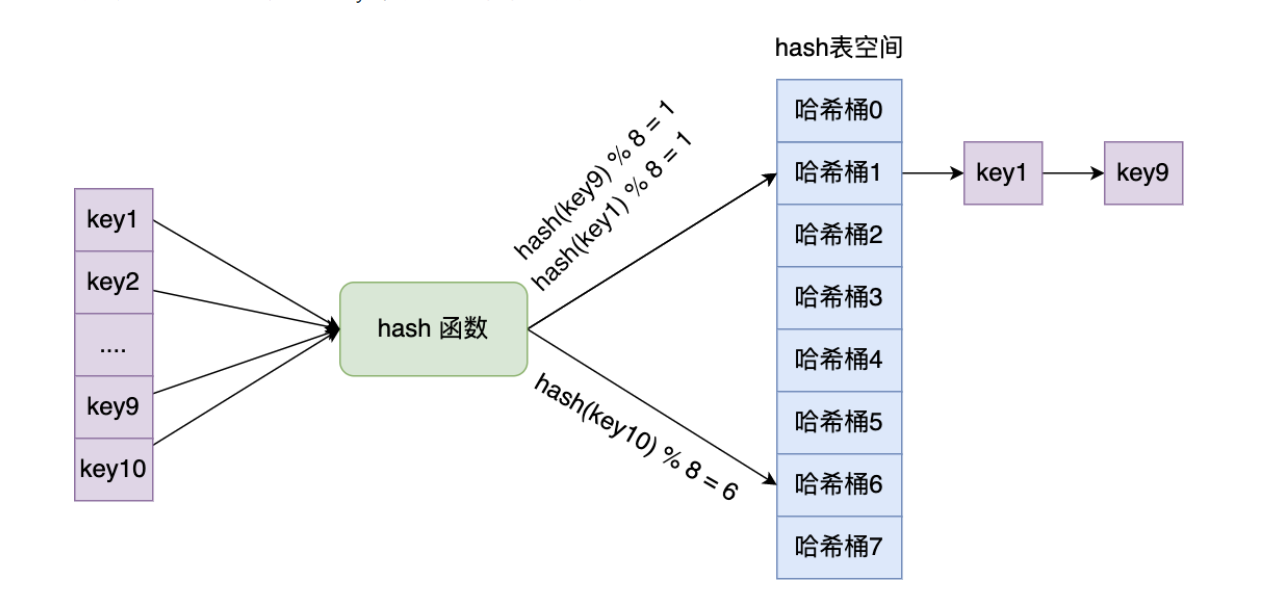
hash表中使用key:value这样的方式存储数据,next指针存储了下个entry数据地址,在redis中Hash、zset、set使用哈希表存储数据
set命令:
zset命令:
zrangebyscore <key> min max:ZRANGEBYSCORE XIAOMING 0 100
zremrangebyscore <key> min max:ZREMRANGEBYSCORE XIAOMING 0 1
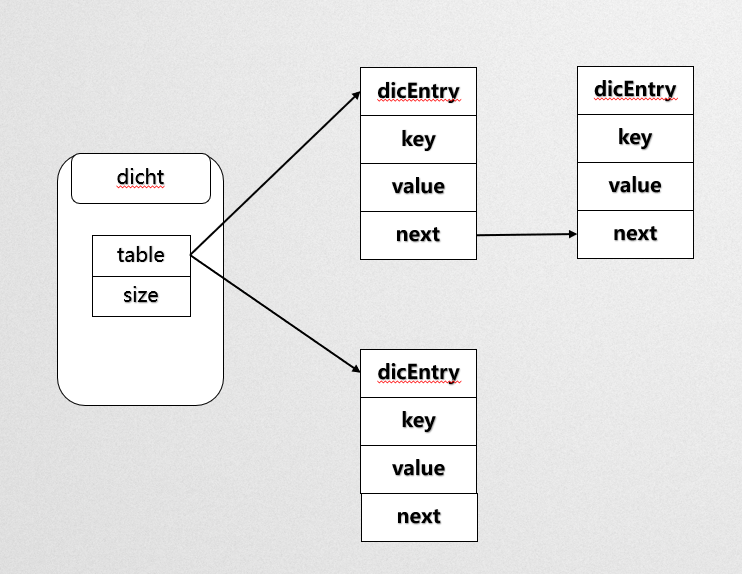
Dic数据解读
Dicht中的hash冲突
从数据结构中可以看到redis中的hash冲突使用链表寻址法,当前节点存储了在同一个bucket中的下个节点,这样处理hash冲突的优点是同一个Key只需要经过一次hash算法找到存储数据的Bucket就可以找到数据,缺点是在一个Dic中数据存储过多,冲突发生的较多时,获取数据需要耗费更多的O(n)的操作下完成
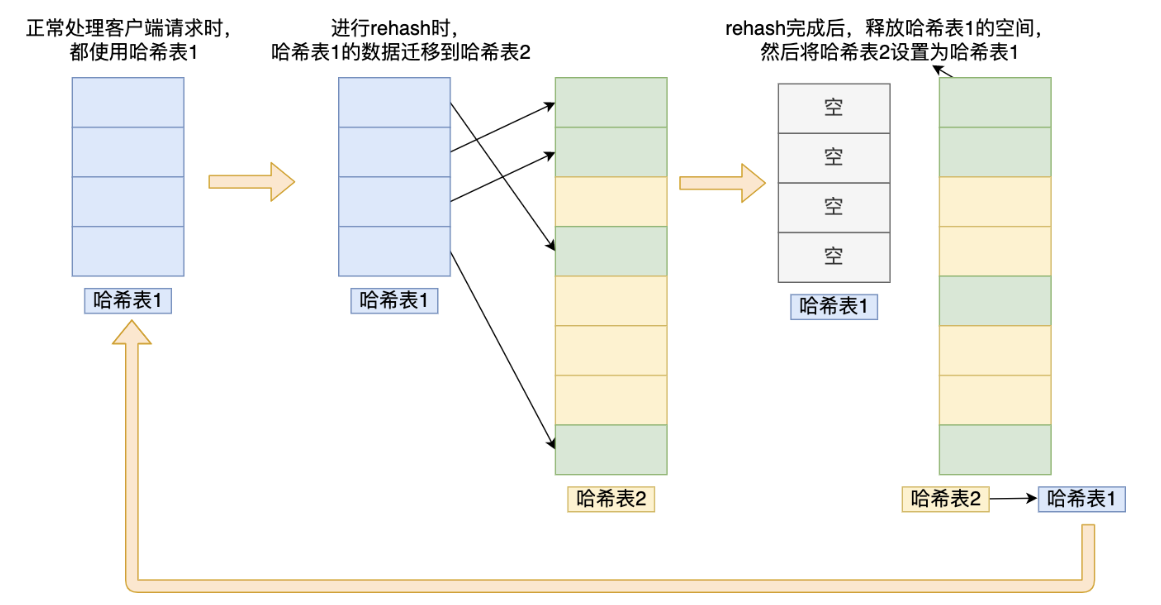
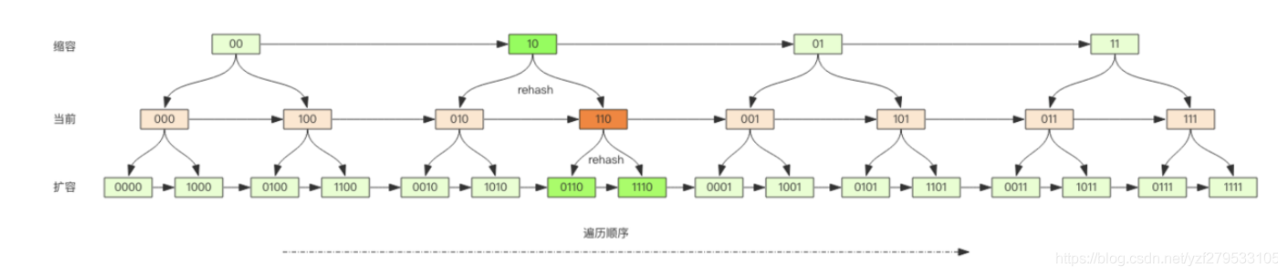
Dic中的rehash
第一个图中可以看到Dic中有两个table,在redis中所有的数据都是存储在dic中的,当dic进行扩容时,就需要进行rehash,也就是把key重新进行hash存储到扩容后的dic中。
Q:什么时候触发rehash
如果没有进行bgsave 元素数量达到hash长度时就会扩容(负载因子大于等于 1)
如果进行bgsave,元素数量达到hash长度的5倍会进行扩容(负载因子大于等于 5)
当哈希表的负载因子小于 0.1时, 程序自动开始对哈希表执行收缩操作。
Q:rehash执行了什么操作
A: 在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 , 表示 rehash 工作正式开始;
为 ht[1] 分配空间, 让字典同时持有 ht[0] 和 ht[1] 两个哈希表
将保存在 ht[0] 中的所有键值对 rehash 到 ht[1] 上
当 ht[0] 包含的所有键值对全部迁移到了 ht[1] 之后,释放 ht[0] ,将 ht[1] 设置为 ht[0],并重置 ht[1] ,最好将 rehashidx 属性的值设为 -1 , 表示 rehash 操作已完成。
rehashidx还有一个作用:记录的是ht[0]的下标位置的位置,下次rehash就从该位置继续进行。
Q:rehash大数据时阻塞请求?
A:redis在进行rehash进行了渐进式rehash操作,每次操作哈希表1中的数据时才会将数据添加到哈希表2中,每次之操作一个key。
Q:rehash算法是什么样的,如何保证rehash之后的顺序和不冲突?
A:redis采用高位加位法,在扩容之后之前相邻的key还是相邻的,缩容之后依旧相邻。
核心算法:
a mod 8 = a & (8-1) = a & 7
a mod 16 = a & (16-1) = a & 15
a mod 32 = a & (32-1) = a & 31
7,15,31也就是Mask,所谓的掩码,每个key在进行hash计算的时候都经过了相同的掩码。
跳表初识

redis中zset使用跳表存储数据,主要使用跳表计算score,支持按照score区间查找数据。
跳表数据结构解读
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;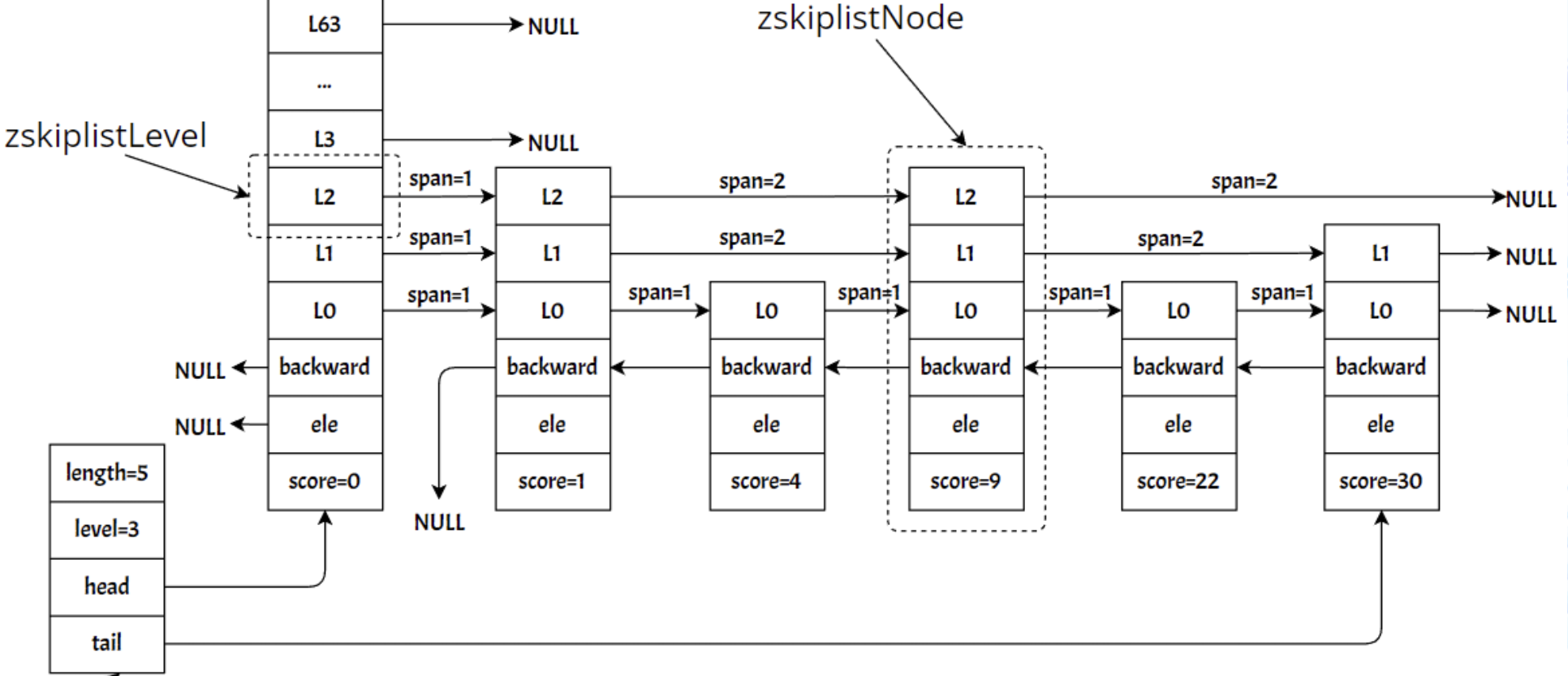
跳表由多个数组组成,每个数组代表一层,最底层的数组存储所有的数据,上面的每一层存储的是数据的索引(就好比B+ tree),redis中的跳表节点,存储了前继节点的指针、socre、和数据(在不同的跳表实现中会存储不同的节点信息,包括上层节点,前继节点,下层节点。)
跳表的来历
跳表的研究来源于,有一个1至9的数组,我需要查9。
第一次,从1到9一个一个查询,需要查询9次,才能返回我想要的9。
来如果我每次差两个数字,第5次就可以查到9。依次类推,每次多差一次,查询次数就是9/n次。n越大,循环的次数就越少。但是n很大时,直接跳过了我要寻找的数据,也是不行的,所以这个n是无法估量的一个数字,所以产生了跳表,由数据的数量决定每一层的n是多少。
如何升层
如何才能知道我当前的数据是否可以到更高层?这个有几种算法:
1.固定的间隔,固定的间隔会随着数据增多层数越来越高,每次查找数据都需要经过固定的间隔
2.随机升层,不稳定升层,有可能同一层的数据很多了,但是还是没有升层数据,查询发生O(n)的操作
reids使用抛硬币的原理计算是否在更高层建立索引,只要计算是小于0.25那么就在高层建立索引,但是也有一个最大层(64)的限制
int randomlevel() {
//初始化为一级索引
int level = 1;
//翻硬币,如果求余2等于1 则 level增加一层
while( rand() % 2 ) level++;
//如果level 没有超过最大层数就返回,否则就返回最大层数
level = ( maxlevel > level ) ? level : maxlevel;
return level;
}为何限制64层
跳表和树的比较
|
数据结构
|
简介
|
存储特性
|
查找复杂度
|
插入复杂度
|
|---|---|---|---|---|
| 跳表 | 使用层级创建索引,支持跳跃查询 | 最底层存储数据,上层建立索引 | logN | logN |
| 红黑树(AVL) | 平衡二叉树 | 每个数节点只能由两个叶节点组成,树节点存储数据 | log2N | log2N |
| B+树 | 索引平衡二叉树,叶子节点存储数据,树节点存储索引 | 每个树节点由两个叶子节点组成,最底层叶子节点存储数据,树节点存储索引 | logmN | logmN |
| B树 | 索引平衡二叉树,树节点存储数据 | 树节点有多个叶节点组成,树节点存储数据和索引 | logN | 近似logN |
在线测试redis命令:https://try.redis.io/
redis官网:https://redis.io/
书:《redis深度历险记》
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,