Kinect2相机标定与点云数据获取
相关的代码资料:
https://github.com/Rayso777(后续会陆续整理上传)
视频:
1、ElasticFusion TUM数据集&buntu16.04+kinect2演示流程.
2、RTAB-MAP实时三维重建-Kinect2
3、RTAB-MAP三维重建-基于gazebo仿真
4、ORB-SLAM2室内稀疏三维重建-基于gazebo仿真
5、ORB-SLAM2室外三维重建-gezebo仿真
6、三维重建视频集锦-视觉SLAM
对于机器人而言,获取目标物体和环境信息是它进行后续行为决策的基础,本章将主要对机器人的3D物体识别能力进行研究,对环境信息的感知研究将在后续章节进行。作为机器人完成功能任务的重要基础能力之一,目标识别在机器人技术中具有重要地位,像工业机器人需要准确识别出目标工件并计算其在工位上的位置姿态以便完成抓取放置任务,移动机器人需要识别出环境中障碍物的信息的完成避障,安防机器人需要准确识别出目标物进行报警等。
在(一)已经介绍到,3D物体识别的方式目前主要有模板匹配、形状匹配、点云匹配、机器学习等四种方式,并对四种方式的主流算法和优缺点进行了介绍,这里不再重复叙述。其中,模板匹配和点云匹配是现在工业生产中主要使用的方法,在无人驾驶、工业机器人、移动机器人中有广泛的应用,机器学习中基于深度学习的方法也正方兴未艾,像PointRCNN等识别模型取得了很好的效果。综合市场技术应用情况和现有的实验条件,本文主要研究基于模板匹配的3D物体识别方法。
本节内容是基于在Gazebo中构建的3D物体识别仿真环境中进行的,因为构建的仿真kinect相机采用默认的内参数即可,在这一部分中我们省略相了机标定的环节。虽然不进行该环节,但仍然要认识到相机标定在物体视觉识别过程中的重要性。在完成了仿真环境搭建后,分别进行了二维图像上的基于ORB特征的物体识别和基于LINEMOD算法的基于模板匹配的3D物体识别。

Gazebo是Dr. Andrew Howard等人于2002年创建的机器人仿真工具,它加速了机器人的设计、模拟、算法验证和创建的真实场景进行系统测试。它具备室内和室外的机器人仿真能力,有稳健的物理引擎、高质量的图形、编程接口,它的主要特性如上图所示。
1) 它以ODE等物理引擎为基础开发,可以进行各种刚体模拟诸如碰撞检测等。
2) 提供高质量的渲染功能,可以对光线、阴影和纹理贴图进行渲染。
3) 可以生成多种传感器的数据,像Kinect相机、激光雷达等,而且可以进行噪声的仿真。
4) 具备与ROS通讯的各种传感器插件。
5) Gazebo的模型库中具有PR2、Turtlebot等常用的机器人模型。
6) 可以进行TCP/IP通信。
7) 可在浏览器进行云端仿真。
8) 具备实用的各类命令行工具,方便我们进行机器人设计、算法验证等开发工作。
在gazebo中创建一个空的world文件,添加Turtlebot机器人URDF模型。通过Building Editor创建室内环境,添加桌子、啤酒、可乐等物体sdf模型,创建的室内仿真环境如下图所示。

因为创建的仿真环境用于物体识别,所以其中Kinect相机的仿真尤为重要。Kinect相机模型是通过URDF语言创建的,主要通过link、joint、gazebo、sensor、plugin等标签进行描述,并且在plugin标签中设置相机的内参和发布的话题。
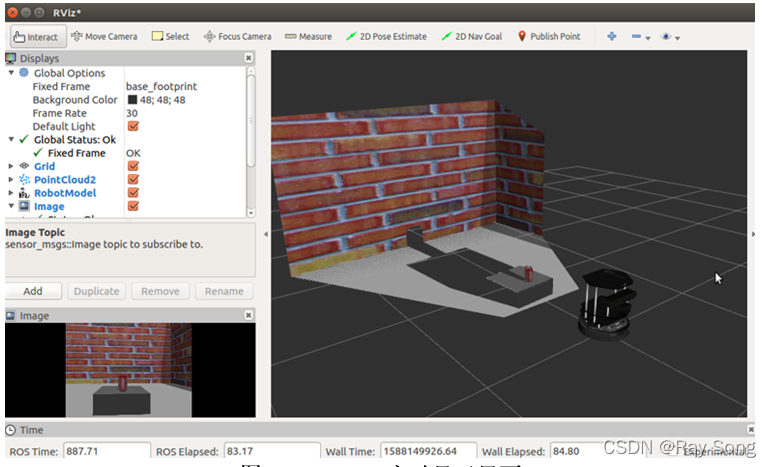
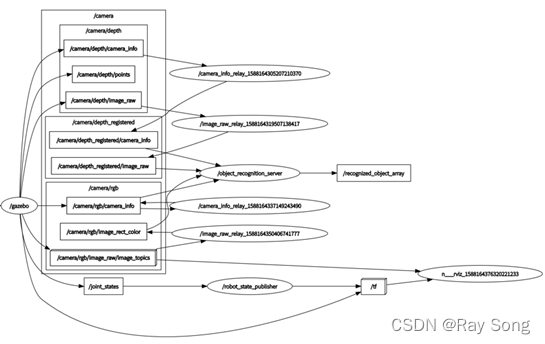
随后,需要控制机器人在仿真环境中移动,获取仿真环境中kinect相机的数据。通过安装Turtlebot第一代机器人的仿真包,编写key_teleop节点控制机器人在仿真世界中的运动,在rviz中添加RobotModel、Pointcloud2、Image等信息订阅相应的Topic话题。下面图3.2.3和图2.3.4分别展示了Rviz中信息的显示和话题节点通信。
完成仿真环境的搭建后,便可以基于此进行物体识别的研究。这部分主要采用模板匹配的思想来进行物体识别,模板匹配有离线的3D模型数据库构建和在线物体识别两个管线。
构建3D模型数据库主要有以下几种方式:
1) CAD几何重建。通过Solidworks、UG等建模软件对目标物进行重建,该方法适用于对尺寸已知的物体进行重建,主要用在机械领域。但也存在缺陷,需要对物体进行精确的测量,对测量技术要求较高,并且要浪费大量人力。
2) SfM重建。通过相机拍摄不同位置的目标物,通过运动恢复结构技术进行物体的模型重建。缺点是物体重建的计算机运算过程耗费时间过长。
3) 扫描设备重建。通过扫描仪进行物体重建,缺点是目前市面上的3D扫描仪价格十分难得昂贵,很难普及应用。
4) RGB-D相机视觉SLAM技术三维建模。通过视觉SLAM技术进行物体建模。这是近年来的研究热点,缺点是目前通过这种方法建模的精度并不是很高。
本部分我们主要采用CAD几何重建方法,使用Solidworks制作物体模型,保存为stl格式文件上传至离线数据库进行训练。在构建了物体的几何模型后,我们需要在这些模型上使用LINEMOD等方法提取特征并加以描述,将特征编码保存在离线数据库中。
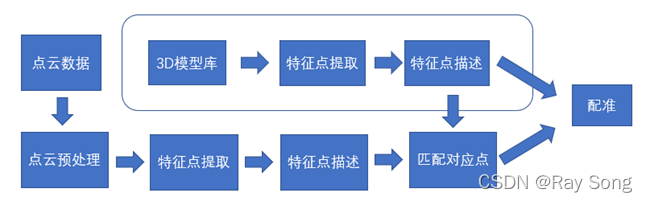
在线的管线主要是实时的获取点云数据,并进行滤波、去外点等处理,然后提取特征点并进行描述,然后使用kd-tree或ICP等算法进行匹配。
模板匹配中完整的流程如下图所示:
(一) ORB特征点介绍
物体识别的流程基本是一致的,大都经过特征点提取、特征描述、特征匹配等过程,基于模板匹配的算法中,3D视觉中的模板是物体的三维模型,二维的模板便是便是图像本身。在进行基于物体模型识别的研究之前,先探讨二维图像的识别,提取图像的特征点进行匹配,以了解物体识别的过程。
二维图像识别的特征点众多,本文我们主要采用ORB(Oriented FAST and Rotated BRIEF)特征,它对旋转和尺度具有很好的鲁棒性。该特征由改进的旋转FAST特征点和BRIEF描述子构成。因此,对一张图片进行ORB特征提取也就变成了提取FAST角点并计算方向,然后计算对应角点的BRIEF描述子的过程。下图描述了FAST特征的表现形式。图中,对像素位置p进行亮度提取,然后以其为原点的圆周选取了一定数量的像素,若存在连续一定数量的像素亮度与p位置亮度在一定阈值范围内明显区别,则确定该角点为FAST,在使用过程中需要对每个像素进行遍历操作。

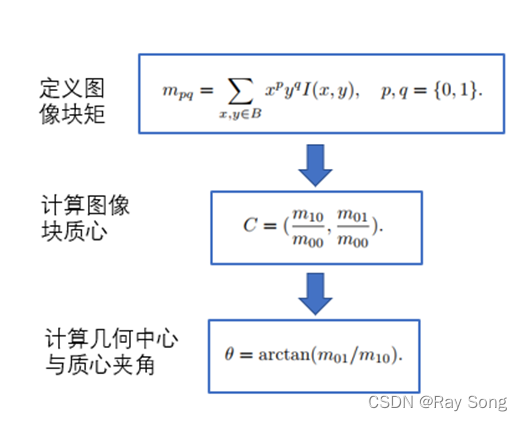
完成关键点提取后还需要使用灰度质心法来计算角点的主方向,具体计算过程在下图详细描述:
随后计算描述子,BRIEF是由0和1组成的128维的向量,记录了在关键点的图块区域内随机相邻两像素的大小比较结果,若某像素比一个像素大为1,小则为0。构建图像金字塔进行多层关键点和描述子的求解,而且还记录了上述求取的旋转方向,因此使用该描述子可以保证在尺度、旋转上的鲁棒性。
上述便是ORB特征点和描述子的整个提取过程,接下来使用通过OpenCV3库编写程序进行特征匹配的实验,程序算法流程如下图
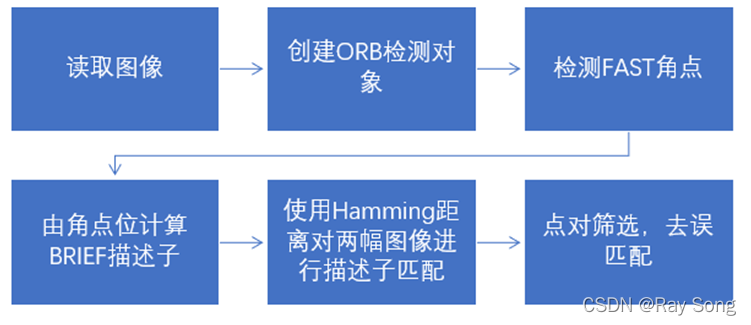
进行ORB特征提取后进行匹配的结果如下图3.3.5所示,可见该特征在匹配效果上对旋转、移动、尺度等具有良好的鲁棒性。

(二) Gazebo二维图像识别仿真
介绍完ORB特征后,接下来在3.2节创建好的Gazebo环境中进行基于二维模板的识别实现(识别场景中的啤酒罐模型)。Find_object_2d是ROS中常用于二维物体模板匹配识别功能包,可以对图像提取SURF、ORB、SIFT等主流特征,支持RGB相机和RGB-D两类相机,并且还可以对物体的尺寸大小和位姿进行估计,在基于二维模板匹配识别仿真中主要使用该库进行实验。
下面分别完成RGB相机和RGB-D相机的仿真:
1、RGB相机仿真
在gazebo创建好的环境中,添加啤酒罐的模型,启动仿真环境,在find_obect的节点中订阅camera/rgb/image_raw话题。随后对识别的物体进行二维图像的ORB特征点提取,结果如下图所示。

将提取的特征保存在数据库中,随后进行在线的识别,识别结果如下:
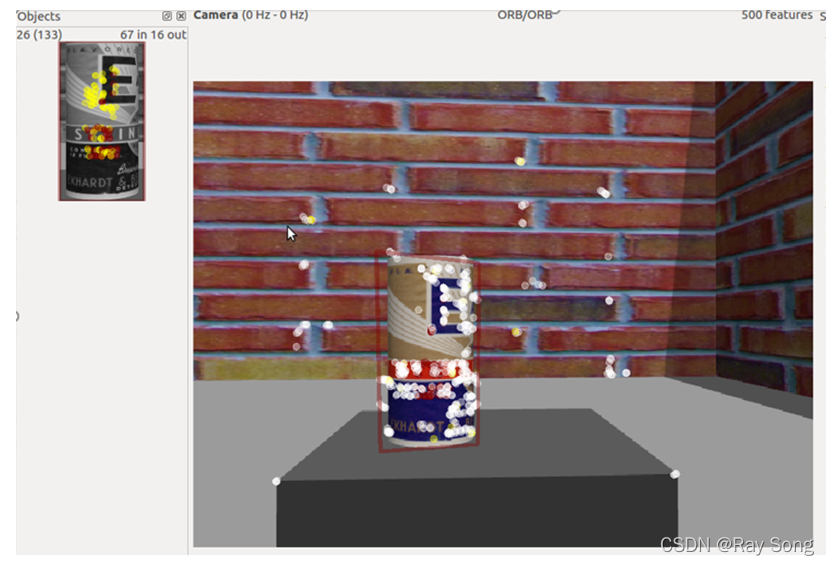
我们还可以输出尺寸大小、单应矩阵。由相机模型中对位姿求解部分的描述得知,单应矩阵可以表示两个平面之间的映射,所以我们可以该功能包输出的单应矩阵来恢复位移变换信息,所得结果如下表所示:

2、深度相机识别仿真
上述RGB相机的识别过程只能确定物体的二维坐标信息,并且尺度还不能确定,而通过深度相机可以很好的解决这些问题,下面是对深度相机的仿真。
流程同RGB相机物体识别过程类似,只是在find_object_2d节点订阅的话题中增加的深度图像话题/camera/depth/image_raw,识别结果如下图所示,图中白点为识别的ORB特征点,并将识别到的物体以粉色线框进行了标注。

在终端输出检测结果如下表,其中使用xyz表示空间位置,用四元数表示物体的旋转姿态。这里的四元数可以通过一定的公式转换成旋转矩阵R。

最后,利用现有Kinect2设备进行了真实情况下的物体识别,识别情况如下图,左侧图片为离线制作好的二维特征模板,右侧为实时物体识别用黄色边框标注出的目标物体。

(一)LINEMOD介绍
上小节介绍了二维模板的物体识别,但是在识别过程中只能识别特定角度的图像,在实际应用过程中受到了极大的限制,本小节将探讨基于三维模型的模板匹配识别方法,解决多角度识别问题。在模板匹配的众多算法中,LINEMOD已经得到了广泛的认可,在三维物体识别方面具有很好的稳定性。
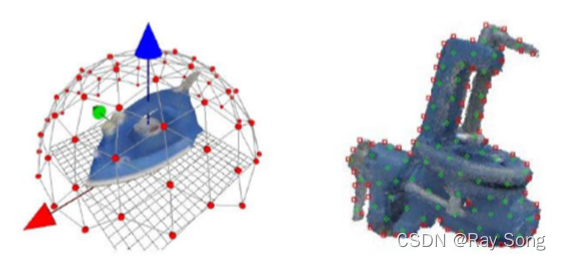
任何一种模板匹配算法都需要进行模板的渲染提取,LINEMOD算法类似,通常是通过相机围绕坐标系原点,采集不同角度和距离的模板,记录相对位姿,如 下图所示:
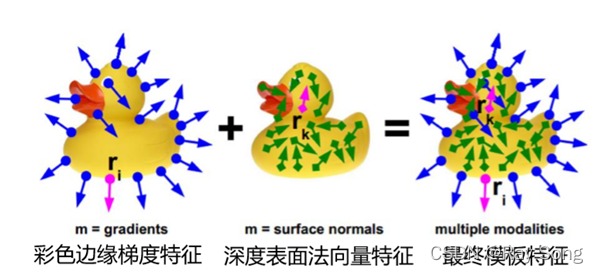
对不同角度和距离的模板提取过程如下图所示,主要提取彩色边缘的梯度特征和深度表面法向量特征,这是离线进行的,提取后会存储到数据库中,在绪论部分已经进行了介绍。
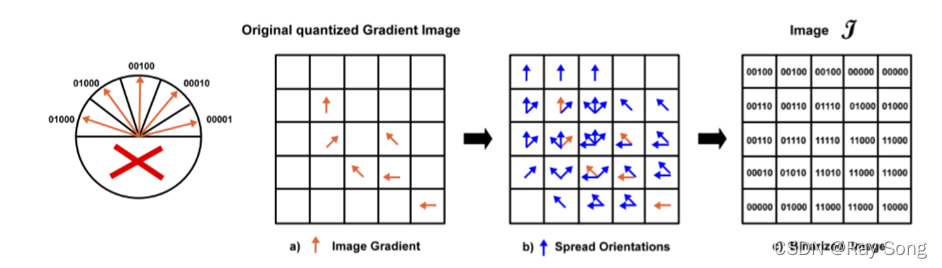
LINEMOD算法使用RGB图像的梯度方向作为特征,而不是梯度的大小,分别计算RGB三个通道的梯度,取梯度值最大的通道的梯度方向。采用滑窗的方式对图像进行一定邻域范围相似度计算。并且,在进行计算式采用了SSE的方式同步数据处理,因此速度更快。同时,采用了主方向扩散到邻域的方式增强算法对微小旋转平移的容错能力,扩散原理如下图所示。
(二)Gazebo中3D物体识别实验
由于在ORK(Object Recognition Kit)中集成了LINEMOD算法,所以接下来将使用ORK该ROS功能包完成对于coke模型的3D物体识别,仍在二维模板匹配小节中创建的仿真环境中进行。实验过程主要分为三个步骤,首先要创建物体的三维模型,通过UG或者Solidworks等CAD软件建立模型并将其上传至数据库,然后使用LINEMOD算法对这些模型进行训练,最后在物体识别程序选择LINEMOD方式进行3D物体识别。
因为ORK是基于CouchDB存储模型训练的数据,因此需要提前安装CouchDB,这是一个面向文档和WEB的数据库管理系统,可以很方便的通过浏览器进行进行管理。
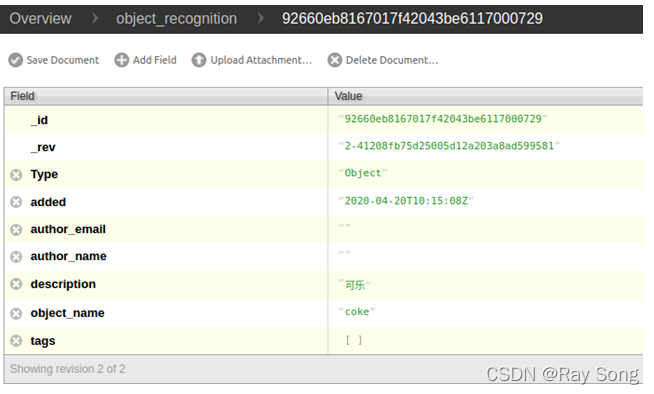
首先将创建好的可乐罐模型添加到数据库当中,如下图所示,图中左下方的数字串代表在数据库存储的ID号。

然后使用object_recognition_linemod下的training.ork进行模型的训练,然后保存在CouchDB数据库中,如下图所示:
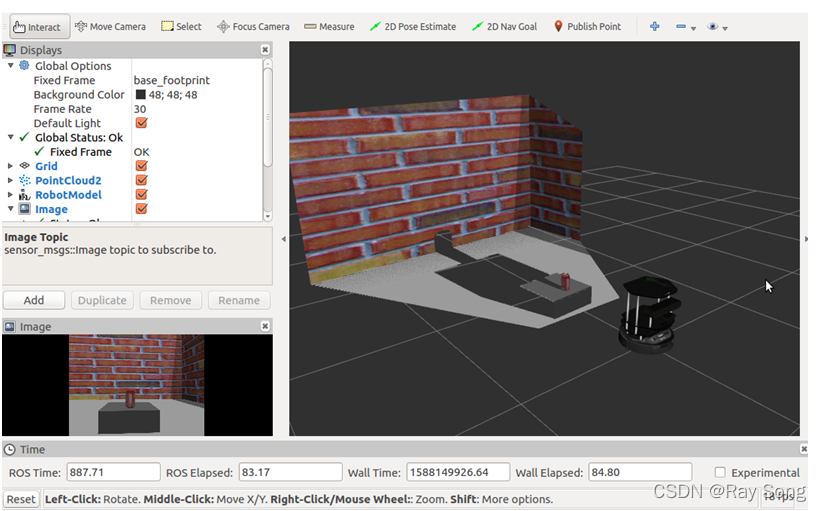
打开Gazebo中的识别仿真环境,通过ROS系统的的参数映射机制,将/camera/rgb/image_raw、/camera/rgb/image_info、/camera/depth/image_raw和/camera/depth/image_info等话题重映射到ORK可以订阅的话题,运行ORK中object_recognition_core模块的检测节点,识别方式选用LINEMOD,在RVIZ中添加Image、PointCloud2和Object_ork节点程序(若识别到物体该节点会发布消息)。RVIZ获取Gazebo仿真环境界面和识别效果分别如下图
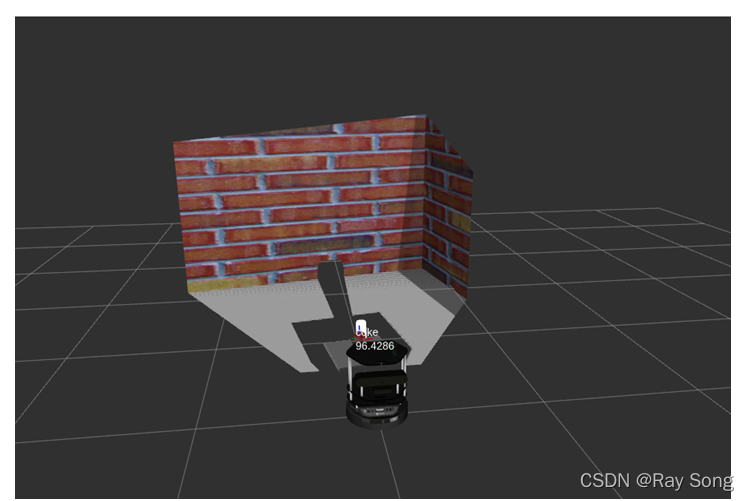
由图可以看出,通过LINEMOD对三维模型进行模板匹配,Turtlebot准确的识别出可乐罐的模型,图中白色覆盖部分为识别区域,并显示了coke字样,识别相似率达到了96.4%。
在之前通过基于ORB特征的find_object_2d和基于LINEMOD算法ORK实现了二维模板匹配和三维模板匹配的3D物体识别,这些都需要通过离线的方式制作好模板才可进行识别。但对于机器人而言,面对的物体不一定是提前获知的,仍需要对物体进行一定操作(比如抓取放置等),这便涉及到了目标检测的问题。由机器人的抓取大多是基于平面上的物体,所以本节将针对桌面物体检测这一特定背景的问题进行研究。
对桌面物体的检测可以分为以下几个步骤:
(1)通过标定好的Kinect相机获取点云数据,然而这些数据是ROS格式的,需要转换为PCL点云数据格式,方便使用PCL点云库进行数据处理。
(2)通过PCL点云库的segmentation模块将点云中所有的平面检测出,并通过设定一定范围内高度的阈值,检测出桌面。
(3)将检测出的桌面的点云删除,将其上方的一定范围高度的点云设定为物体的点云集合。
(4)在物体点云集合中通过KD-Tree进行搜索,把分割出的每一个点云簇当做是一个物体。
首先,在ROS工作空间下src中创建一个功能包object_detection,创建时需要添加roscpp 、 std_msgs 和 message_runtime 等依赖项,其中std_msgs用于输出string文字,message_runtime用于定义非标准消息类型输出检测物体的名称和坐标。随后编写在该功能包下创建msg文件夹,在该文件夹下创建Coord.msg非标准消息类型,内容如下图3.4.1所示,使用catkin_make编译后生成Coord.h文件,便完成了非标准消息类型的创建。

编写桌面物体检测的程序节点objects_3d,该程序流程如下:
(1) 首先在main函数中,订阅了turtlebot发布的/camera/depth/points话题,当检测到后将点云数据传到ProcCloudCB回调函数中(该函数是整个算法实现的核心部分,下面进行详细介绍),该函数进行物体检测,最后将检测的结果通过publish对象coord_pub发布到话题/objects_3d。同时,在main函数中还发布了一下的主题:
obj_maker 用于在RVIZ中标注物题的空间位置
segmented_plane 用于在RVIZ中显示检测出来的平面集合
segmented_objects 用于在RVIZ中显示检测出来的物体集合
(2)接下来对ProcCloudCB函数进行详细介绍:
下篇博客节介绍在视觉SLAM基础理论(主要是参考《视觉SLAM十四讲》,相当于学习笔记啦,哈哈 _)
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc