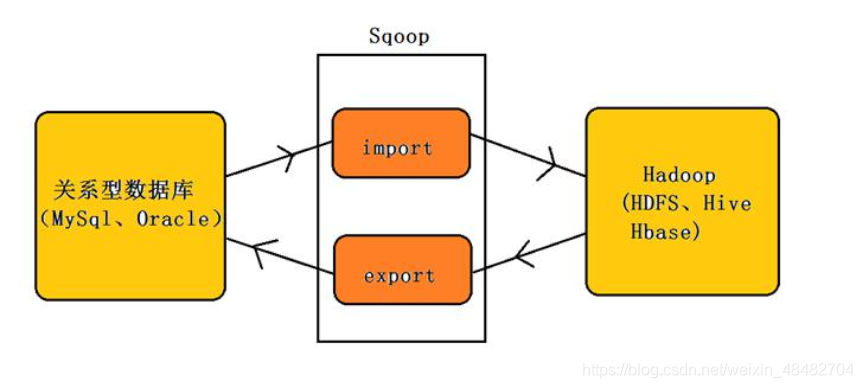
sqoop (sql to hadoop)是一款开源的工具,主要用于在 Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MSQL,Oracle,Postgres 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
将导入或导出命令翻译成mapreduce程序来实现。
Sqoop的主要功能如下:
导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
导出数据:从Hadoop的文件系统中导出数据到关系数据库
这里两个安装包 sqoop-1.4.7 bin_hadoop-2.6.0.tar.gz和sqoop-1.4.7.tar.gz
因为hadoop版本为3.1.3 所以sqoop的版本太低,需要自行配置


# 解压
[root@hadoop install]# tar -zxf sqoop-1.4.7.tar.gz -C ../soft/
# 切换目录
[root@hadoop install]# cd ../soft/
# 更名
[root@hadoop soft]# mv sqoop-1.4.7/ sqoop147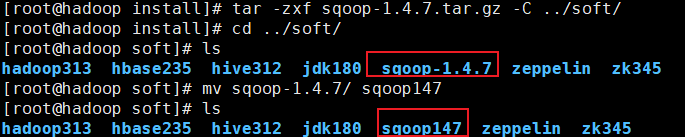
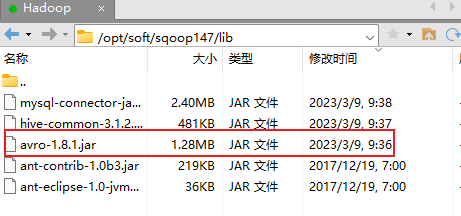
切换目录到 /opt/soft/sqoop147/lib/
添加avro-1.8.1.jar
# 将hive312/lib下的两个jar包拷贝过来
[root@hadoop lib]# cp /opt/soft/hive312/lib/hive-common-3.1.2.jar ./
[root@hadoop lib]# cp /opt/soft/hive312/lib/mysql-connector-java-8.0.29.jar ./

将sqoop-1.4.7.jar 拷贝到 /opt/soft/sqoop147/

切换到cd /opt/soft/sqoop147/conf
# 将配置文件复制并更名
[root@hadoop conf]# cp sqoop-env-template.sh sqoop-env.sh
# 编辑 sqoop-env.sh
[root@hadoop conf]# vim ./sqoop-env.sh
22 #Set path to where bin/hadoop is available
23 export HADOOP_COMMON_HOME=/opt/soft/hadoop313
24
25 #Set path to where hadoop-*-core.jar is available
26 export HADOOP_MAPRED_HOME=/opt/soft/hadoop313
27
28 #set the path to where bin/hbase is available
29 #export HBASE_HOME=
30
31 #Set the path to where bin/hive is available
32 export HIVE_HOME=/opt/soft/hive312
33 export HIVE_CONF_DIR=/opt/soft/hive312/conf
34
35 #Set the path for where zookeper config dir is
36 export ZOOCFGDIR=/opt/soft/zk345/conf


# 编辑/etc/profile
[root@hadoop conf]# vim /etc/profile
# SQOOP_HOME
export SQOOP_HOME=/opt/soft/sqoop147
export PATH=$PATH:$SQOOP_HOME/bin
# 刷新文件
[root@hadoop conf]# source /etc/profile

[root@hadoop conf]# sqoop version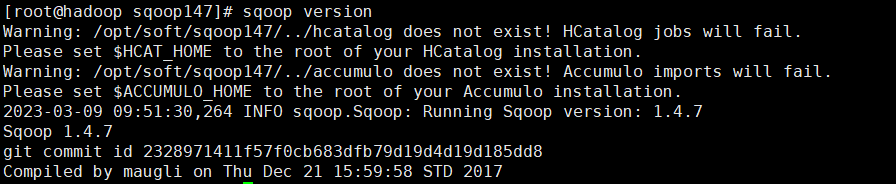
安装验证:
[root@hadoop conf]# sqoop list-databases \
[root@hadoop conf]# --connect jdbc:mysql://192.168.153.134:3306 \
[root@hadoop conf]# --username root \
[root@hadoop conf]# --password 123123
注:直接回车会执行代码。\的作用是连接符,用于连接两行代码
参数 | 说明 |
–connect | 连接关系型数据库的URL |
–username | 用户名 |
–password | 密码,考虑安全可使用 -P |
–driver | 指定jdbc驱动类 |
sqoop list-databases \
--connect jdbc:mysql://192.168.153.134:3306 \
--username root \
--password 123123sqoop list-tables \
--connect jdbc:mysql://hadoop02:3306/school \
--username root \
--password 123123
在 Sqoop 中,“导入”念指:从非大数据集(RDBMS)向大数据集群 (HDFS,HIVE,HBASE)中传输数据,叫做:导入,使用 import 关键字。
导入单个表从 RDBMS 到 HDFS。表中的每一行被视为 HDFS 的记导入工具记录。所有记录都存储为文本文件的文本数据。
1> 确定MySQL服务开启正常
2> 在MySQL中新建一张表并插入一些数据
3> 导入数据
参数说明:
参数 | 说明 |
import | 从一个数据库中将一个表格导入到HDFS |
import-all-tables | 从一个数据库中将全部表格导入到HDFS |
list-databases | 列出服务器上的可用数据库 |
list-tables | 列出数据库中的可用表 |
# 将mysql表数据导入到hdfs
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--target-dir /tmp/school/student \ --用来指定导出数据存放至HDFS的目录
--table student
--fields-terminated-by '\t' \ --指定分隔符。HDFS上默认用逗号分隔数据和字段。
--m 1 --表示map task的个数。如果不写,默认为4
注意:
使用-m 进行切分时,默认按照主键进行切割。如果表格中没有主键,需要指定切割列。
--split-by Sage
验证:
[root@hadoop02 ~]# hdfs dfs -cat /tmp/school/student02/part-m-00000
2023-03-10 02:26:38,581 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1990-01-01,01,赵雷,男
1990-12-21,02,钱电,男
1990-05-20,03,孙风,男
1990-08-06,04,李云,男
1991-12-01,05,周梅,女
1992-03-01,06,吴兰,女
1989-07-01,07,郑竹,女
1990-01-20,08,王菊,女
1> mysql的地址尽量不要使用localhost 请使用ip或者host
2> 如果不指定,导入到hdfs默认分隔符是“,"
3> 可以通过--fields-terminated-by '\t' 指定具体的分隔符
4> 如果表的数据比较大,可以并行启动多个maptask执行导入操作。如果没有主键,需要指定根据哪个字段进行切分。
sqoop create-hive-table \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table teacher \ --数据库school中的表
--hive-table teacher_hive --hive中新建的表名称sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table teacher \
--hive-import \
--hive-table teacher_hive \
--m 1
sqoop import \
# 如果不指定maptast数,需要加如下代码:
-Dorg.apache.sqoop.splitter.allow_text_splitter=top.splitter.allow_text_splitter=true
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table teacher \
--hive-import \
--hive-database teacher_hive
--m 1 \sqoop import \
--connect jdbc:mysql://hadoop02:3306/school \
--username root \
--password 123123 \
--table teacher \
--hive-import \
--hive-database bigdata teacher_hive
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--where "id=01" \
--target-dir /tmp/school/student01
--table student
sqoop import
--connect jdbc:mysql://192.168.153.134:3306/school
--username root
--password 123123
--target-dir /tmp/school/users01
--query 'select name from users where cardId="1111" and $CONDITIONS'
--m 11> 使用query sql语句来进行查找不能加参数--table,且必须要添加 where条件;
2> 并且 where 条件后面必须带一个$CONDITIONS 这个字符串
3> 并且这个 sql 语句必须用单引号,不能用双引号;
在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据每次都全部导入到 hive 或者 hdfs 当中去这样会造成数据重复的问题。因此一般都是选用一些字段进行增量的导入, sqoop 支持增量的导入数据。
-- 所谓的增量数据指的是上次至今中间新增加的数据
-- sqoop支持两种模式的增量导入
append追加 根据数值类型字段进行追加导入, 大于指定的last-value
lastmodified 根据时间戳类型字段进行追加, 大于等于指定的last-value
注意在lastmodified模式下,还分为两种情形: append merge-key
增量导入是仅导入新添加的表中的行的技术。
--check-column(col)
用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系型数据库中的自增字段及时间戳类似。
注意:这些被指定的列的类型不能使任意字符类型,如 char、varchar 等类型都是不可以的,同时-- check-column 可以去指定多个列。
--incremental(mode)
append:追加,比如对大于 last-value 指定的值之后的记录进行追加导入。
lastmodified:最后的修改时间,追加 last-value 指定的日期之后的记录。
--last-value(value)
指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值。
原始数据:
注意:实现增量导入
mysql> desc real_estate;
+-------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| cardId | varchar(18) | NO | | NULL | |
| projectName | varchar(50) | NO | | NULL | |
| address | varchar(200) | NO | | NULL | |
| houseType | varchar(20) | NO | | NULL | |
| area | int | NO | | NULL | |
| buildTime | date | NO | | NULL | |
+-------------+--------------+------+-----+---------+----------------+
7 rows in set (0.00 sec)
mysql> select * from real_estate;
+----+--------+--------------+-------------------+-----------+------+------------+
| id | cardId | projectName | address | houseType | area | buildTime |
+----+--------+--------------+-------------------+-----------+------+------------+
| 1 | 1111 | 天虹庄园 | 庄派路12号 | 三室 | 89 | 2023-01-31 |
| 2 | 2222 | 中粮家园 | 经天路21号 | 二室 | 68 | 2023-01-31 |
| 3 | 3333 | 招商公寓 | 宏运大道33号 | 四室 | 118 | 2023-01-31 |
| 4 | 4444 | 金地名筑 | 天景路12号 | 三室 | 89 | 2023-01-31 |
| 5 | 1111 | 浦发庄园 | 经天路13号 | 三室 | 98 | 2023-01-31 |
| 6 | 2222 | 中兴家园 | 通天路21号 | 二室 | 60 | 2023-01-31 |
| 7 | 1111 | 粮油公寓 | 宏运大道33号 | 四室 | 118 | 2023-01-31 |
| 8 | 2222 | 金地名筑 | 天景路12号 | 三室 | 89 | 2023-01-31 |
+----+--------+--------------+-------------------+-----------+------+------------+
8 rows in set (0.00 sec)
# 导入初始数据
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table real_estate \
--target-dir /tmp/school/re \
--m 1
# hdfs中查看数据,数据成功导入
[root@hadoop02 ~]# hdfs dfs -cat /tmp/school/re/part-m-00000
2023-03-10 17:00:26,770 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1,1111,天虹庄园,庄派路12号,三室,89,2023-01-31
2,2222,中粮家园,经天路21号,二室,68,2023-01-31
3,3333,招商公寓,宏运大道33号,四室,118,2023-01-31
4,4444,金地名筑,天景路12号,三室,89,2023-01-31
5,1111,浦发庄园,经天路13号,三室,98,2023-01-31
6,2222,中兴家园,通天路21号,二室,60,2023-01-31
7,1111,粮油公寓,宏运大道33号,四室,118,2023-01-31
8,2222,金地名筑,天景路12号,三室,89,2023-01-31
# mysql中添加数据
mysql> insert into real_estate values(9,'2222','碧桂园','北京路888号','别墅',888,'2023-02-01');
Query OK, 1 row affected (0.00 sec)
mysql> select * from real_estate;
+----+--------+--------------+-------------------+-----------+------+------------+
| id | cardId | projectName | address | houseType | area | buildTime |
+----+--------+--------------+-------------------+-----------+------+------------+
| 1 | 1111 | 天虹庄园 | 庄派路12号 | 三室 | 89 | 2023-01-31 |
| 2 | 2222 | 中粮家园 | 经天路21号 | 二室 | 68 | 2023-01-31 |
| 3 | 3333 | 招商公寓 | 宏运大道33号 | 四室 | 118 | 2023-01-31 |
| 4 | 4444 | 金地名筑 | 天景路12号 | 三室 | 89 | 2023-01-31 |
| 5 | 1111 | 浦发庄园 | 经天路13号 | 三室 | 98 | 2023-01-31 |
| 6 | 2222 | 中兴家园 | 通天路21号 | 二室 | 60 | 2023-01-31 |
| 7 | 1111 | 粮油公寓 | 宏运大道33号 | 四室 | 118 | 2023-01-31 |
| 8 | 2222 | 金地名筑 | 天景路12号 | 三室 | 89 | 2023-01-31 |
| 9 | 2222 | 碧桂园 | 北京路888号 | 别墅 | 888 | 2023-02-01 |
+----+--------+--------------+-------------------+-----------+------+------------+
9 rows in set (0.00 sec)
# 实现增量的导入
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table real_estate \
--target-dir /tmp/school/real_estate \
--incremental append \ ——increment-追加模式
--check-column id \ ——追加的字段
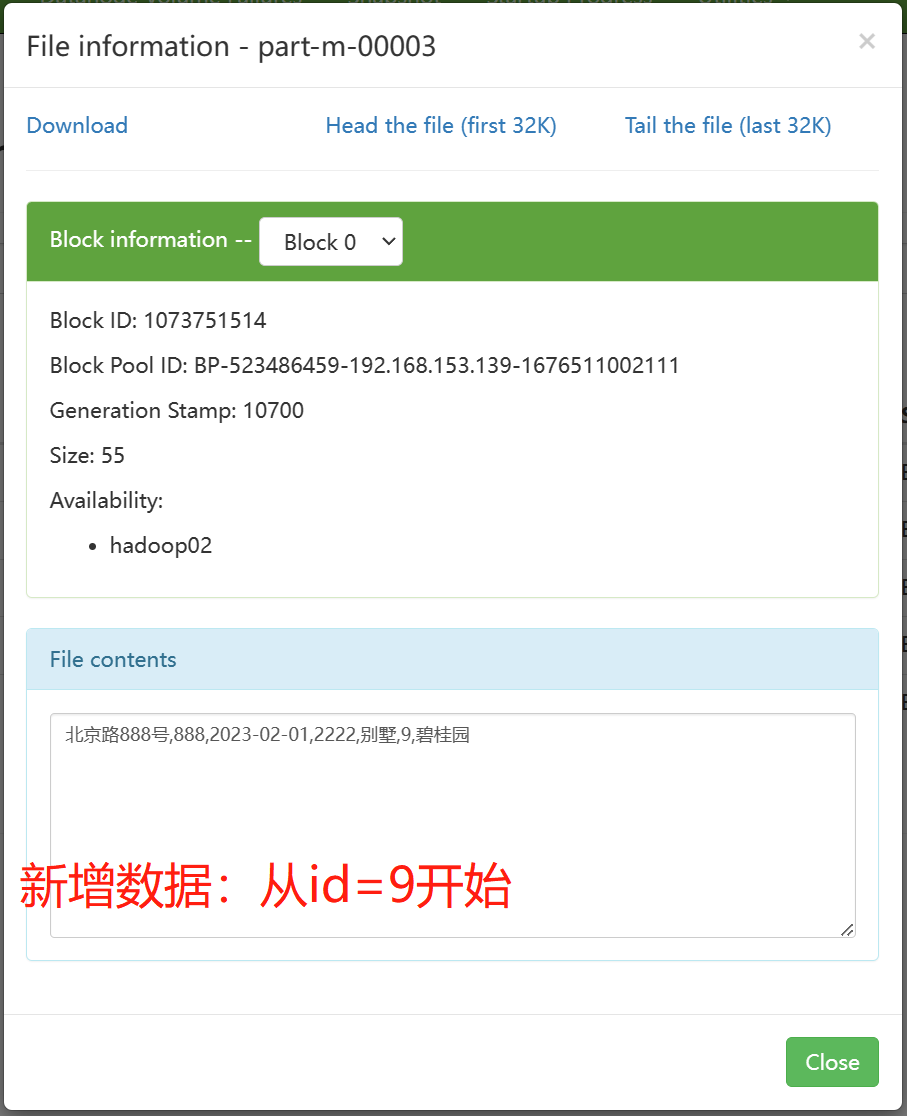
--last-value 8 \ ——last-value=8,输出从9开始
--m 1
验证导入数据目录,可以发现多了一个文件,里面就是增量数据。
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table real_estate \
--target-dir /tmp/school/re \
--check-column buildTime \
--incremental lastmodified \
--last-value '2023-02-01' \ ——"lastmodified"模式
--m 1 \
--append导入最后插入的一条数据,但却此处却插入了两条数据。
采用lastmodified模式处理增量时,会将大于等于last-value值的数据当作增量插入。
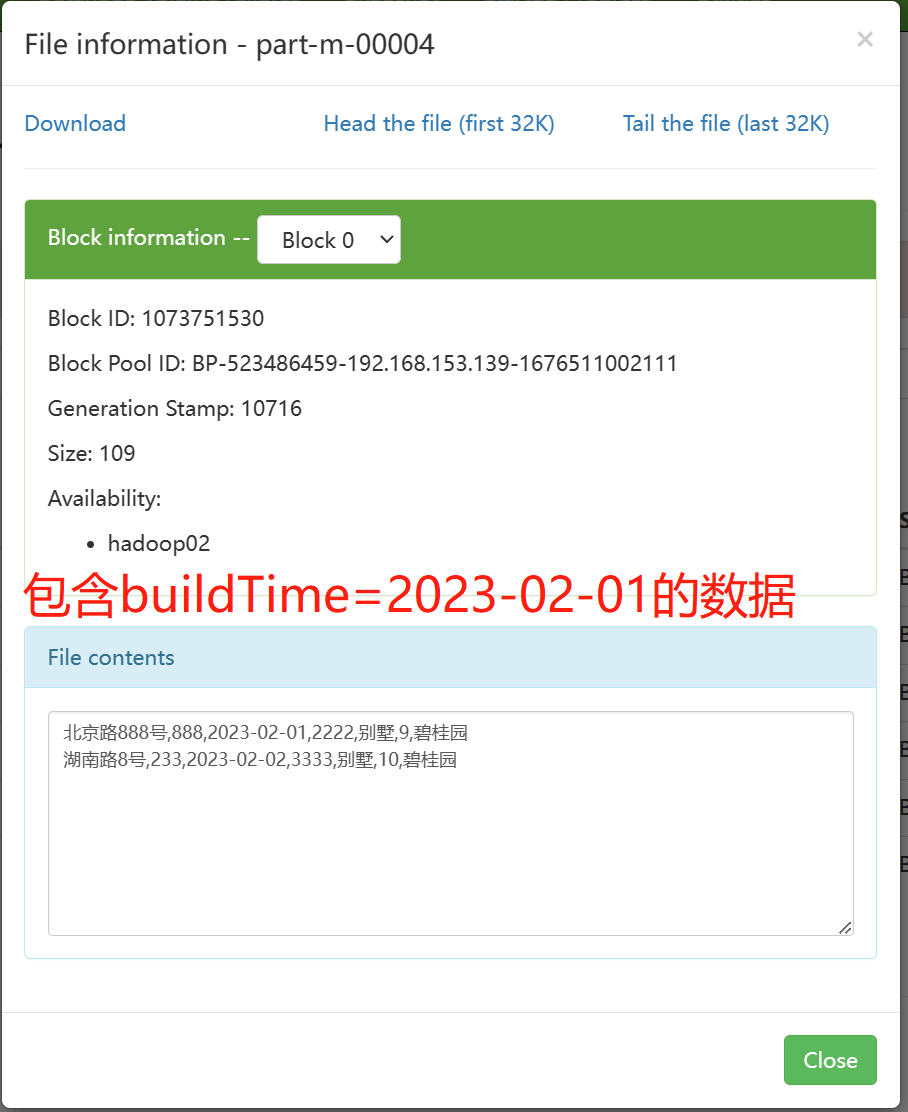
使用lastmodified 模式进行增量处理要指定增量数据是以append 模式(附加)还是 merge-key(合并)模式添加。
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table real_estate \
--target-dir /tmp/school/re \
--check-column buildTime \
--incremental lastmodified \
--last-value '2023-02-01' \
--m 1 \
--merge-key idmerge-key模式进行了一次完整了mapreduce操作。
关于lasimodified中的两种模式:
append只会追加数据到一个新的文件中,并且会产生数据的重复问题
因为默认是从指定的last-value大于等于其值的数据开始导入
merge-key 把增量的数据合并到一个文件中。处理追加增量数据之外,如果之前的数据有变化,也可以进行修改操作。底层相当于进行了一次完整的mr作业,数据不会重复。
将数据从 Hadoop 生态体系导出到 RDBMS 数据库导出前,目标表必须存在于目标数据库中。也就是说,导出的目标表需要自己手动提前创建,sqoop并不会帮我们创建复制表结构。
export 有三种模式:
默认操作:是从将文件中的数据使用 INSERT 语句插入到表中
更新模式:Sqoop 将生成 UPDATE 替换数据库中现有记录的语句。
调用模式:Sqoop 将为每条记录创建一个存储过程调用。
默认情况下,sqoopexport 将每行输入记录转换成一条INSERT 语句,添加到目标数据库表中。如果数据库中的表具有约束条件(例如,其值必须唯一的主键列)并且已有数据存在,则必须注意避免插入违反这些约束条件的记录。如果INSERT 语句失败,导出过程将失败。此模式主要用于将记录导出到可以接收这些结果的空表中。通常用于全表数据导出。
导出时可以是将 Hive 表中的全部记录或者 HDFS 数据(可以是全部字段也可以部分字段)导出到 Mysql 目标表。
hdfs dfs -mkdir /emp_data
hdfs dfs -put emp_data.txt /emp_data
1. 手动创建MySQL中的目标表
mysql> create table employee (
id int not null primary key,
name varchar(10),
deg varchar(20),
salary int,
dept varchar(10));
2. 执行导出命令
sqoop export \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--table employee \
--export-dir /emp_data/相关配置参数
--input-fields-terminated-by '\t'
指定文件中的分隔符。
--columns
选择列并控制它们的排序。当导出数据文件和目标表字段列顺序完全致的时候可以不写。否则以逗号为间隔选择和排列各个列。没有被包含在 -columns 后面列名或字段要么具备默认值,要么就允许插入空值,否则数据库会拒绝凌受 sqoop 导出的数据,导致 Sqoop 作业失败。
--export-dir
导出目录。在执行导出的时候,比如指定这个参数,同时需要具备--table 或 --call参数两者之一。
--table指的是导出数据库当中对应的表。--call指的是某个存储过程。
--input-null-string/ --input-null-non-string
如果没有指定第一个参数,对于字符串类型的列来说,“null”这个字符串就会被翻译成空值。
如果没有使用第二个参数,无论是“null”字符串还是空字符串,对于非字符串类型的字段来说,这两个类型的空串都会被翻译成空值。
如:--input-null-string "\\N"/ --input-null-non-string "\\N"
更新导出:
updateonly 只更新已经存在的数据,不会执行insert增加新的数据。
allowinsert 更新已有的数据,插入新的数据,底层相当于insert&update
--update-key
更新标识,即根据某个字段进行更新。例如id,可以指定多个更新标识的字段,多个字段之间用逗号分隔。
--updatemod
指定updateonly(默认模式),仅仅更新已存在的数据记录,不会插入新纪录。
sqoop export \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--table updateonly \
--export-dir /updateonly _1/
新增一个文件updateonly_2,修改前三条数据并新增一条记录。
执行更新导出:
sqoop export \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--table updateonly \
--export-dir /updateonly _2/
--update-key id \
--update-mode updateonlyupdateonly 只更新已经存在的数据,不会执行insert增加新的数据。
--update-key
更新标识,即根据某个字段进行更新。例如id,可以指定多个更新标识的字段,多个字段之间用逗号分隔。
--updatemod
指定allowinsert,更新已存在的数据记录,同时插入新纪录。实质上是一个insert&update的操作。
sqoop export \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--table updateonly \
--export-dir /updateonly _1/
新增一个文件updateonly_2,修改前三条数据并新增一条记录。
执行更新导出:
sqoop export \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--table updateonly \
--export-dir /updateonly _2/
--update-key id \
--update-mode allowinsertallowinsert 更新已有的数据,插入新的数据,底层相当于insert&update
创建一个从DB数据库的emp表导入到HDFS文件的作业。
注意:import前面要有空格。
bin/sqoop --create castjob \
-- import \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--target-dir /sqoopresult \
--table emp \
--m 1bin/sqoop job --listbin/sqoop job --show myjobbin/sqoop job --exec myjobsqoop 在创建 job 时,使用--password-file 参数,可以避免输入 mysql 密码,如果使用--password将出现警告,并且每次都要手动输入密码才能执行job,sqoop规定密码文件必须存放在 HDFS 上,并且权限必须是 400。
检查sqoop的sqoop-site.xml是否存在如下配置:
<property>
<name>sqoop.metastore.client.record.password</name>
<value>true</value>
<description>If true, allow saved passwords in the metastore.
</description>
</property>bin/sqoop job --create castjob1 -- import \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password-file /input/sqoop/pwd/castmysql.pwd \
--target-dirsqoopresule \
--table emp \
--m 1
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手