 论文地址:https://arxiv.org/pdf/2303.01506.pdf其实无论是「12 种提升对抗迁移性的算法」,还是「14 种输入单元重要性归因算法」,都是工程性算法的重灾区。在这两大领域内,大部分算法都是经验性的,人们根据实验经验或直觉认识,设计出一些似是而非的工程性算法。大部分研究没有对 “究竟什么是输入单元重要性” 做出严谨定义和理论论证,少数研究有一定的论证,但往往也很不完善。当然,“缺少严谨的定义和论证” 的问题充满了整个人工智能领域,只是在这两个方向上格外突出。
论文地址:https://arxiv.org/pdf/2303.01506.pdf其实无论是「12 种提升对抗迁移性的算法」,还是「14 种输入单元重要性归因算法」,都是工程性算法的重灾区。在这两大领域内,大部分算法都是经验性的,人们根据实验经验或直觉认识,设计出一些似是而非的工程性算法。大部分研究没有对 “究竟什么是输入单元重要性” 做出严谨定义和理论论证,少数研究有一定的论证,但往往也很不完善。当然,“缺少严谨的定义和论证” 的问题充满了整个人工智能领域,只是在这两个方向上格外突出。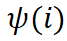 表示第 i 个输入单元的独立效应,
表示第 i 个输入单元的独立效应,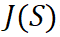 表示集合 S 内多个输入单元间的交互效应。针对第二个关键点,我们探究发现,所有 14 种现有经验性归因算法的内在机理,都可以表示对上述独立效用和交互效用的一种分配,而不同归因算法按不同的比例来分配神经网络输入单元的独立效用和交互效用。具体地,令
表示集合 S 内多个输入单元间的交互效应。针对第二个关键点,我们探究发现,所有 14 种现有经验性归因算法的内在机理,都可以表示对上述独立效用和交互效用的一种分配,而不同归因算法按不同的比例来分配神经网络输入单元的独立效用和交互效用。具体地,令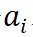 表示第 i 个输入单元的归因分数。我们严格证明了,所有 14 种经验性归因算法得到的
表示第 i 个输入单元的归因分数。我们严格证明了,所有 14 种经验性归因算法得到的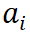 ,都可以统一表示为下列数学范式(即独立效用和交互效用的加权和):
,都可以统一表示为下列数学范式(即独立效用和交互效用的加权和):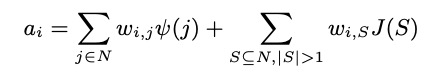 其中,
其中,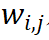 反映了将第 j 个输入单元的独立效应分配给第 i 个输入单元的比例,
反映了将第 j 个输入单元的独立效应分配给第 i 个输入单元的比例,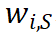 表示将集合 S 内多个输入单元间的交互效应分配给第 i 个输入单元的比例。众多归因算法的 “根本区别” 在于,不同归因算法对应着不同的分配比例
表示将集合 S 内多个输入单元间的交互效应分配给第 i 个输入单元的比例。众多归因算法的 “根本区别” 在于,不同归因算法对应着不同的分配比例 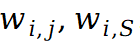 。表 1 展示了十四种不同的归因算法分别是如何对独立效应与交互效应进行分配。
。表 1 展示了十四种不同的归因算法分别是如何对独立效应与交互效应进行分配。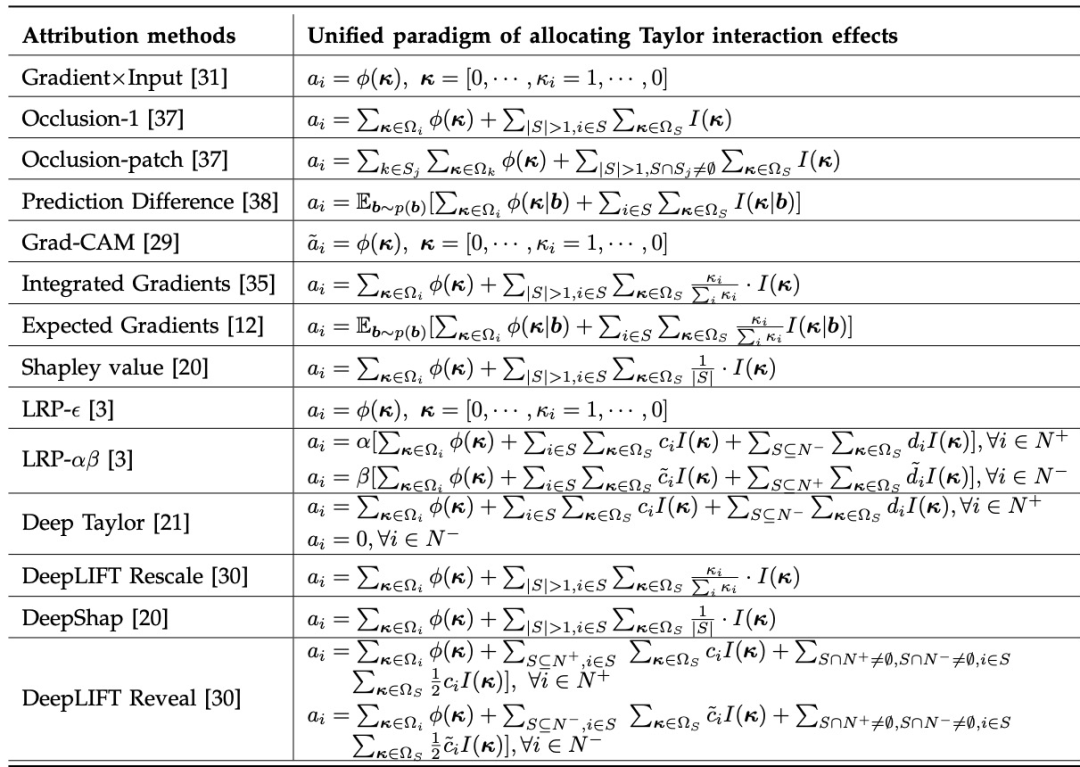 图表 1. 十四种归因算法均可以写成独立效应与交互效应加权和的数学范式。其中
图表 1. 十四种归因算法均可以写成独立效应与交互效应加权和的数学范式。其中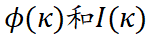 分别表示泰勒独立效应和泰勒交互效应,满足
分别表示泰勒独立效应和泰勒交互效应,满足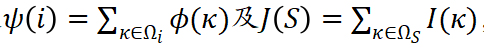 ,是对独立效应
,是对独立效应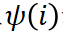 和
和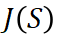 交互效的细化。
交互效的细化。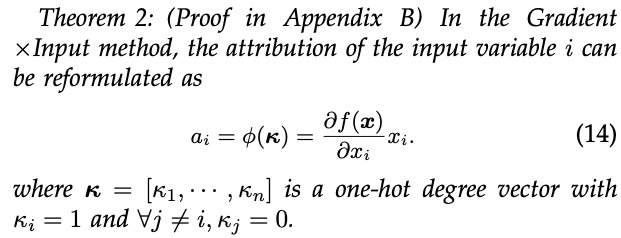
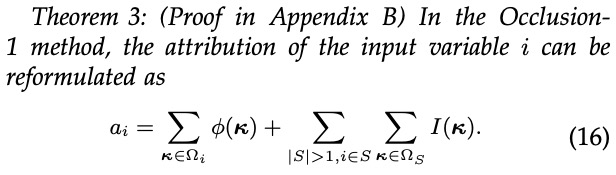




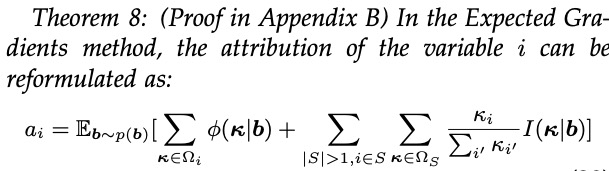








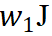 (not, happy) 给单词 not,同时分配一部分效应
(not, happy) 给单词 not,同时分配一部分效应 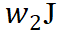 (not, happy) 给单词 happy。那么,分配比例应满足
(not, happy) 给单词 happy。那么,分配比例应满足 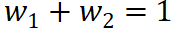 。接着,我们采用这三条评估准则,评估了上述 14 种不同归因算法(如表 2 所示)。我们发现,Integrated Gradients, Expected Gradients, Shapley value, Deep Shap, DeepLIFT Rescale, DeepLIFT RevealCancel 这些算法满足所有的可靠性准则。
。接着,我们采用这三条评估准则,评估了上述 14 种不同归因算法(如表 2 所示)。我们发现,Integrated Gradients, Expected Gradients, Shapley value, Deep Shap, DeepLIFT Rescale, DeepLIFT RevealCancel 这些算法满足所有的可靠性准则。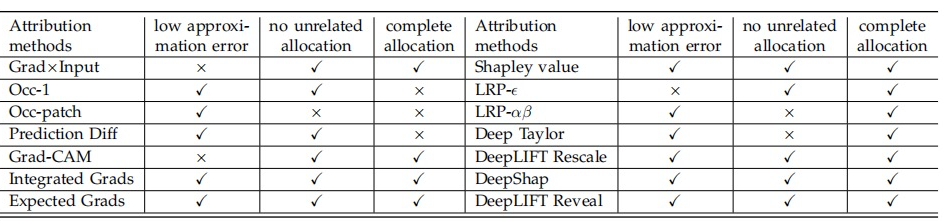 表 2. 总结 14 种不同归因算法是否满足三条可靠性评估准则。
表 2. 总结 14 种不同归因算法是否满足三条可靠性评估准则。我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我从用户Hirolau那里找到了这段代码:defsum_to_n?(a,n)a.combination(2).find{|x,y|x+y==n}enda=[1,2,3,4,5]sum_to_n?(a,9)#=>[4,5]sum_to_n?(a,11)#=>nil我如何知道何时可以将两个参数发送到预定义方法(如find)?我不清楚,因为有时它不起作用。这是重新定义的东西吗? 最佳答案 如果您查看Enumerable#find的文档,您会发现它只接受一个block参数。您可以将它发送两次的原因是因为Ruby可以方便地让您根据它的“并行赋
RSpec似乎按顺序匹配方法接收的消息。我不确定如何使以下代码工作:allow(a).toreceive(:f)expect(a).toreceive(:f).with(2)a.f(1)a.f(2)a.f(3)我问的原因是a.f的一些调用是由我的代码的上层控制的,所以我不能对这些方法调用添加期望。 最佳答案 RSpecspy是测试这种情况的一种方式。要监视一个方法,用allowstub,除了方法名称之外没有任何约束,调用该方法,然后expect确切的方法调用。例如:allow(a).toreceive(:f)a.f(2)a.f(1)
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭3年前。Improvethisquestion我正处于学习Ruby的阶段,我想查看一些小型库的源代码以了解它们是如何构建的。我不知道什么是小型图书馆,但希望SO能推荐一些易于理解的图书馆来学习。因此,如果有人知道一两个非常小的库,这是新手Rubyists学习的好例子,请推荐!我想使用Manveru'sInnatelib,因为它试图保持在2000LOC以下,但我还不熟悉其中经常使用的Ruby速记。也许大约100-5