视频防抖有很多种技术,各有优劣,主流的目前分为三种:
EIS电子防抖
EIS电子防抖是通过软件算法实现防抖的。其技术运作原理是通过加速度传感器和陀螺仪模块侦测手机抖动的幅度,从而来动态调节整ISO、快门以及成像算法来做模糊修正。
优点:成本低
缺点:画面会被裁切,牺牲图像分辨率
OIS光学防抖
OIS光学防抖是通过处理器、陀螺仪和相机防抖模组之间的配合,在拍照抖动时用以驱动防抖组件快速向抖动的相反方向移动镜头模组,由此来抵消发生的抖动,进而实现最终的稳定成像。
优点:画面不会被裁切,原生画质图像效果最好
缺点:成本较高、镜头非常容易损坏、镜头无法做小
AIS智能防抖
AIS防抖是一种基于人工智能的图像防抖技术,可以在相机拍摄过程中,减少因为手抖动造成的画面模糊,获得更加稳定,清晰的画面。即使在拍摄视频或者拍摄夜景时,也可取得良好的防抖效果。
优点:健壮性可以做到很强
缺点:性能低、尚未普及
本文主要讨论的是最AIS智能防抖的基础部分,不涉及到AI的部分,而只是最原始的基于图像特征点抖动检测加以纠偏的防抖技术。
第一步:对每一帧(逐帧)图像做角点检测,又称为关键点检测。也就是将图像上所有的关键点角点识别出来。
如下图所示,蓝色圈出来的部分,就是图像上的关键点。

关键点检测有很多种算法:
1. FAST
2. Agast
3. GFTT
4. SimpleBlob
5. Affine
6. SIFT
7. BRISK
8. ORB
9. MSER
10. KAZE
11. AKAZE
第二步:逐一将前后两帧的角点(关键点)做比对,计算出两两之间的向量差(仿射变换)。
如下图红色箭头所示方向,既是两帧相比对得到的向量方向。
先使用OpenCV里的光流法函数 calcOpticalFlowPyrLK() 函数得到前后得到当前帧相对上一帧的所有关键点变化信息。
再使用OpenCV里的 estimateRigidTransform() 函数传入上一个函数的两帧的结果,可以挑选出前后两帧两个2D点集矩阵之间的最佳仿射变换。

第三步:将第二步算出的最佳仿射变换矩阵数据的整体平均方向,套用低通滤波或者高斯滤波,抹平突变的波峰波谷。
在OpenCV里面还分成 单程稳定器(OnePassStabilizer)和双程稳定器(TwoPassStabilizer),
且支持设置两种滤波方式:低通滤波(LpMotionStabilizer)和高斯滤波(GaussianMotionFilter)。
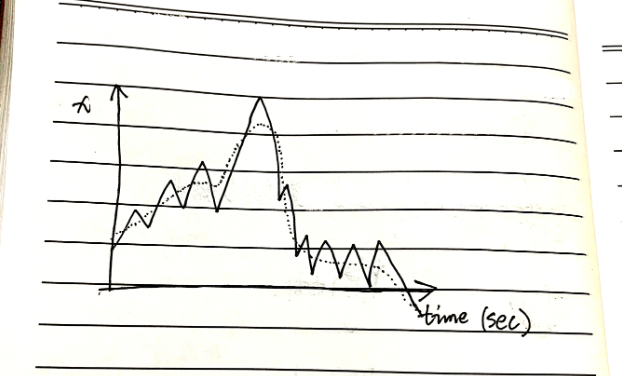
如下图所示,
横坐标是时间轴,纵坐标轴是视频基于第一帧的画面的水平方向变化的像素位移量。
实线是实际根据光流法计算出来的像素位移量。
虚线是使用高斯滤波抹平后的相对较为稳定的像素位移量。
第四步,使用均值滤波抹平之后的仿射变换矩阵数据对视频帧进行图像变换(缩放、旋转、平移等全放射变换)和裁切。
在OpenCV里面使用invertAffineTransform() 和 warpAffine()直接对图像进行仿射变换,得到变换后的图像结果。
比如说视频这一帧,有检测到明显的左移倾向,那么会调用仿射变换,将原视频帧变成下图这样:


第五步,将裁切后的视频resize回原视频的大小。
此步骤涉及到多种BorderMode(边界模式):
1. CONSTANT
2. REPLICATE
3. REFLECT
4. WRAP
5. REFLECT_101
6. TRANSPARENT
至于各自有什么差异无非就是各种填充方式有差异,有些是镜面反射,有些是透明,有些是纯黑色,自行去看OpenCV的文档,一般最常见的是REPLICATE Mode。
所有OpenCV中实现视频防抖可能涉及到的参数或类别:
运动估计器:
1. MotionEstimatorL1 描述最小化 L1 误差的全局 2D 运动估计方法。
2. MotionEstimatorRansacL2 描述了一种稳健的基于 RANSAC 的全局 2D 运动估计方法,可最大限度地减少 L2 误差。
角点检测器:
1. FAST
2. Agast
3. GFTT
4. SimpleBlob
5. Affine
6. SIFT
7. BRISK
8. ORB
9. MSER
10. KAZE
11. AKAZE
平滑滤波方法:
1. GaussianMotionFilter 高斯滤波
2. LpMotionStabilizer 低通滤波
高斯滤波半径:
gaussian radius,也就是做滤波时参考左右多少帧的图像变换数据。
稳定器:
1. OnePassStabilizer 一程稳定器,仅顺向,适合处理实时的视频
2. TwoPassStabilizer 双程稳定器,双向,且首先会遍历一遍视频所有的帧,实测始终有问题
裁切视频比例:
trim ratio,防抖会裁切到视频边界的最大比例。
边界模式:
BorderTypes,枚举,代表对原视频帧图像进行了矩阵变换之后,边边角角的那些画面应该用什么颜色来填充的问题。
1. BORDER_CONSTANT
2. BORDER_REPLICATE
3. BORDER_REFLECT
4. BORDER_WRAP
5. BORDER_REFLECT_101
6. BORDER_TRANSPARENT
7. BORDER_REFLECT101
8. BORDER_DEFAULT
9. BORDER_ISOLATED
异常值拒绝器:
1. NullOutlierRejector 不设置异常拒绝值
2. TranslationBasedLocalOutlierRejector 基于转换的局部异常值拒绝器,可以设置单元格多少和Ransac的参数
运动模型:
1. MM_TRANSLATION(平移)
2. MM_TRANSLATION_AND_SCALE(平移 + 缩放)
3. MM_ROTATION(旋转)
4. MM_RIGID 刚体变换(欧式变换)(平移 + 旋转)
5. MM_SIMILARITY 相似变换(刚体 + 缩放)
6. MM_AFFINE 仿射变换(线性 + 平移)
7. MM_HOMOGRAPHY 单应变换(透视变换、射影变换)
8. MM_UNKNOWN 未知
demo1:

Before After
demo2:

Before After
demo3:

Before After
demo1中间处理过程演示完整视频:https://live.csdn.net/v/226519
以上就是一个视频软件防抖的全部步骤,希望能对你有帮助?
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
注:线性变换包括:平移(Translation)、缩放(Scale)、翻转(Mirror/Flip)、旋转(Rotation)和剪切(Shear),但平移不是线性变换。
刚体变换的英文全称是:rigid transformation (also called Euclidean transformation or Euclidean isometry)
https://en.wikipedia.org/wiki/Rigid_transformation
相似变换:Similarity transformation
https://en.wikipedia.org/wiki/Similarity_(geometry)
仿射变换:Affine transformation
https://en.wikipedia.org/wiki/Affine_transformation
透视变换:homography (also called transformation projectivity, projective transformation, or projective collineation)
https://en.wikipedia.org/wiki/Homography
感谢无法抗拒189纠正运动模型的翻译问题
还可以参考:
多视图几何——变换层次总结(射影变换,仿射变换,相似变换,欧式变换)
https://blog.csdn.net/pikachu_777/article/details/95095627