目录
(一)下载VMware:VMware - Delivering a Digital Foundation For Businesses
(一)官网下载网址:http:// https://www.xshell.com/zh/free-for-home-school/
(七)安装Hadoop,官网下载地址:https://dlcdn.apache.org/hadoop/common/
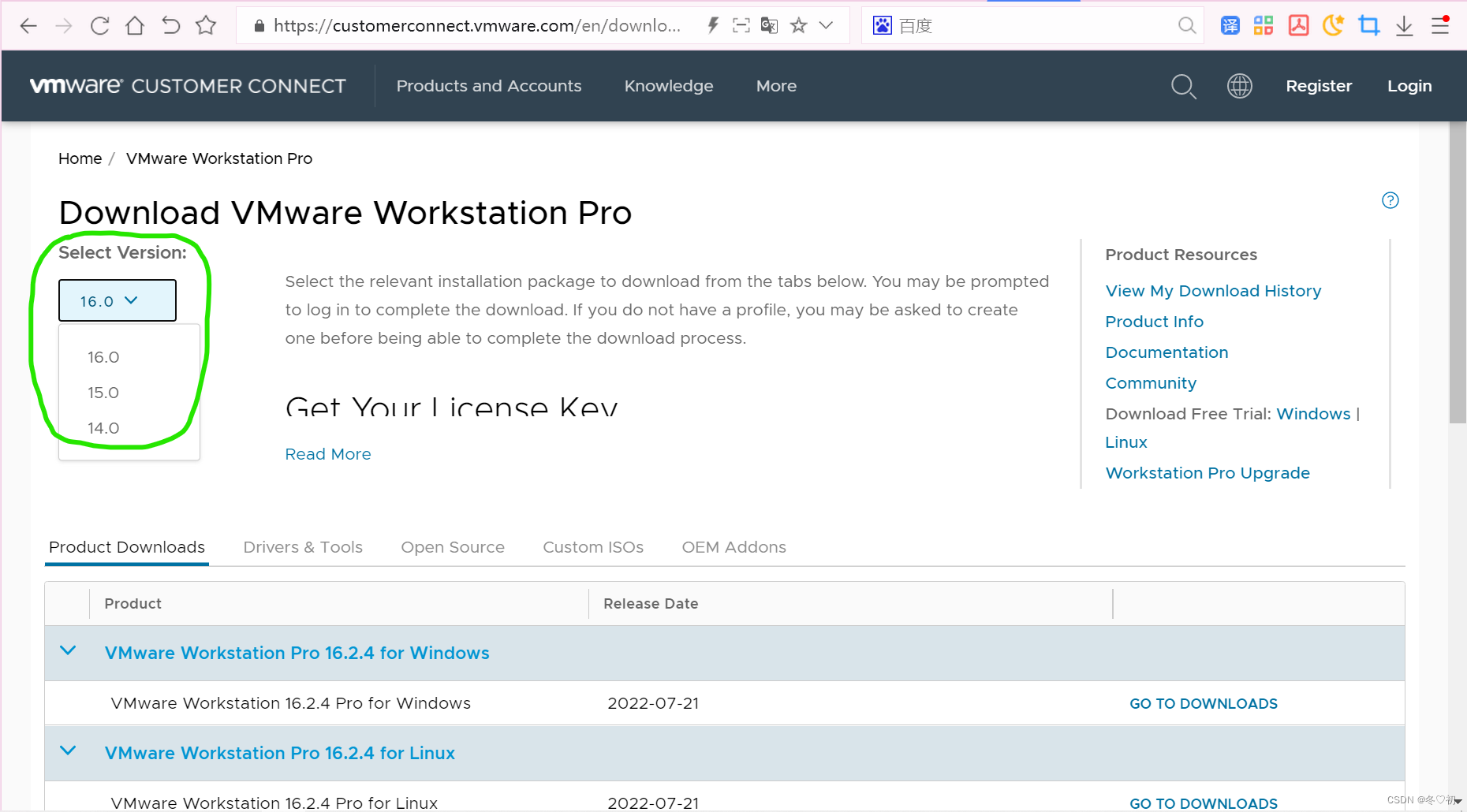
1.进入vmware官网,选择右上角的 Resources 。
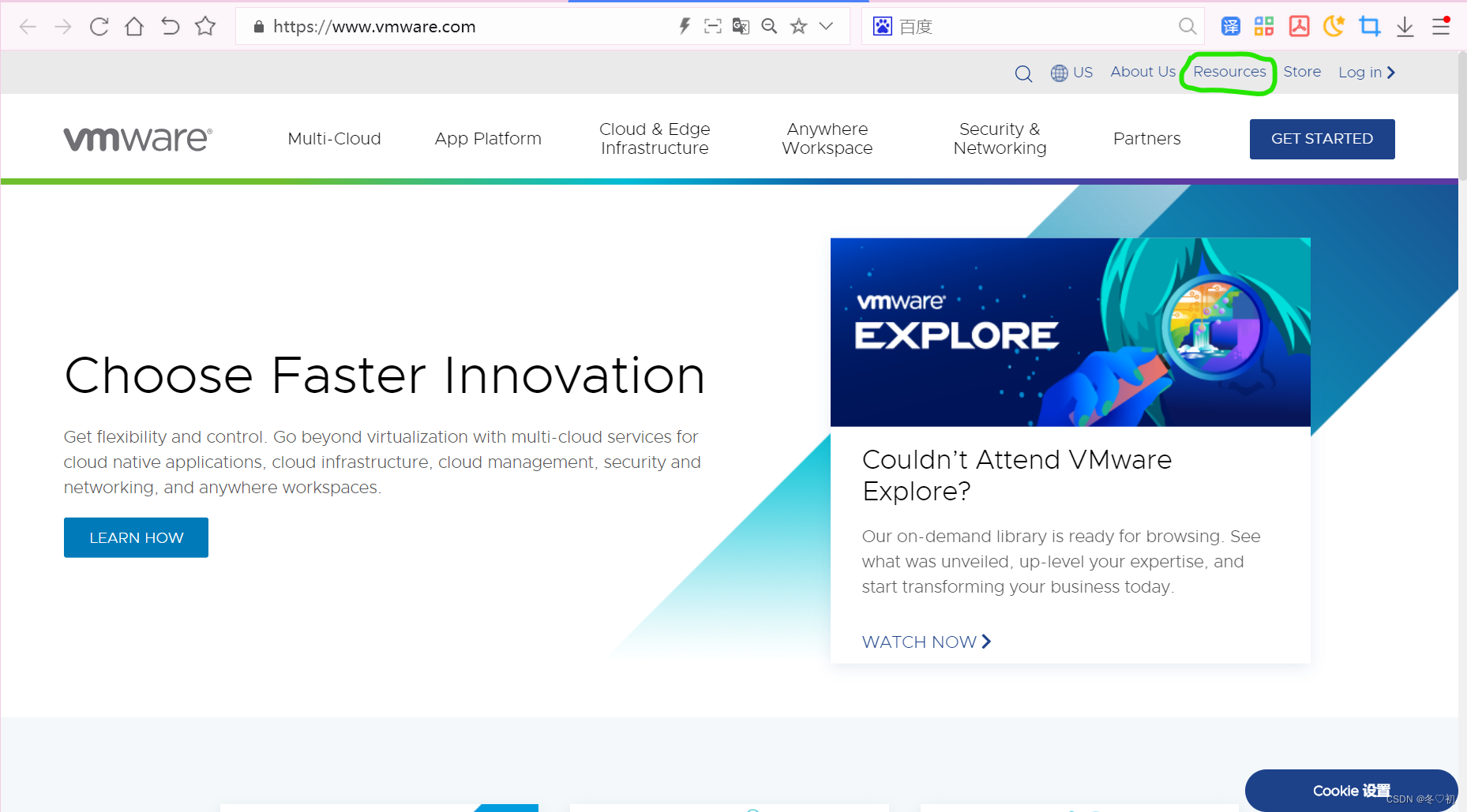
2.然后滑到最下面,选择 VIEW ALL PRODUCTS A-Z 。
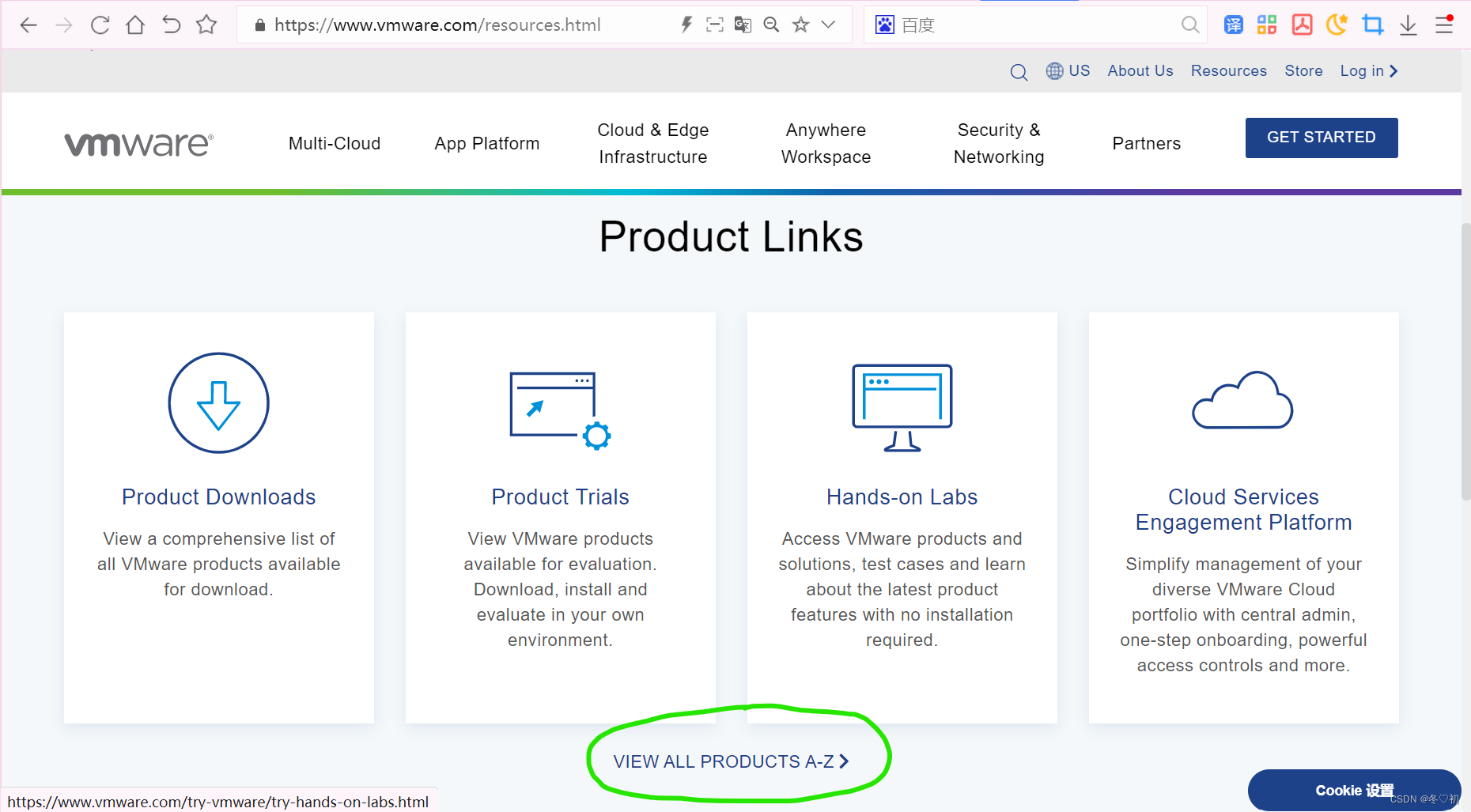
3. 然后滑道最下面,找到 VMware Workstation Pro ,选择 Download Product 。
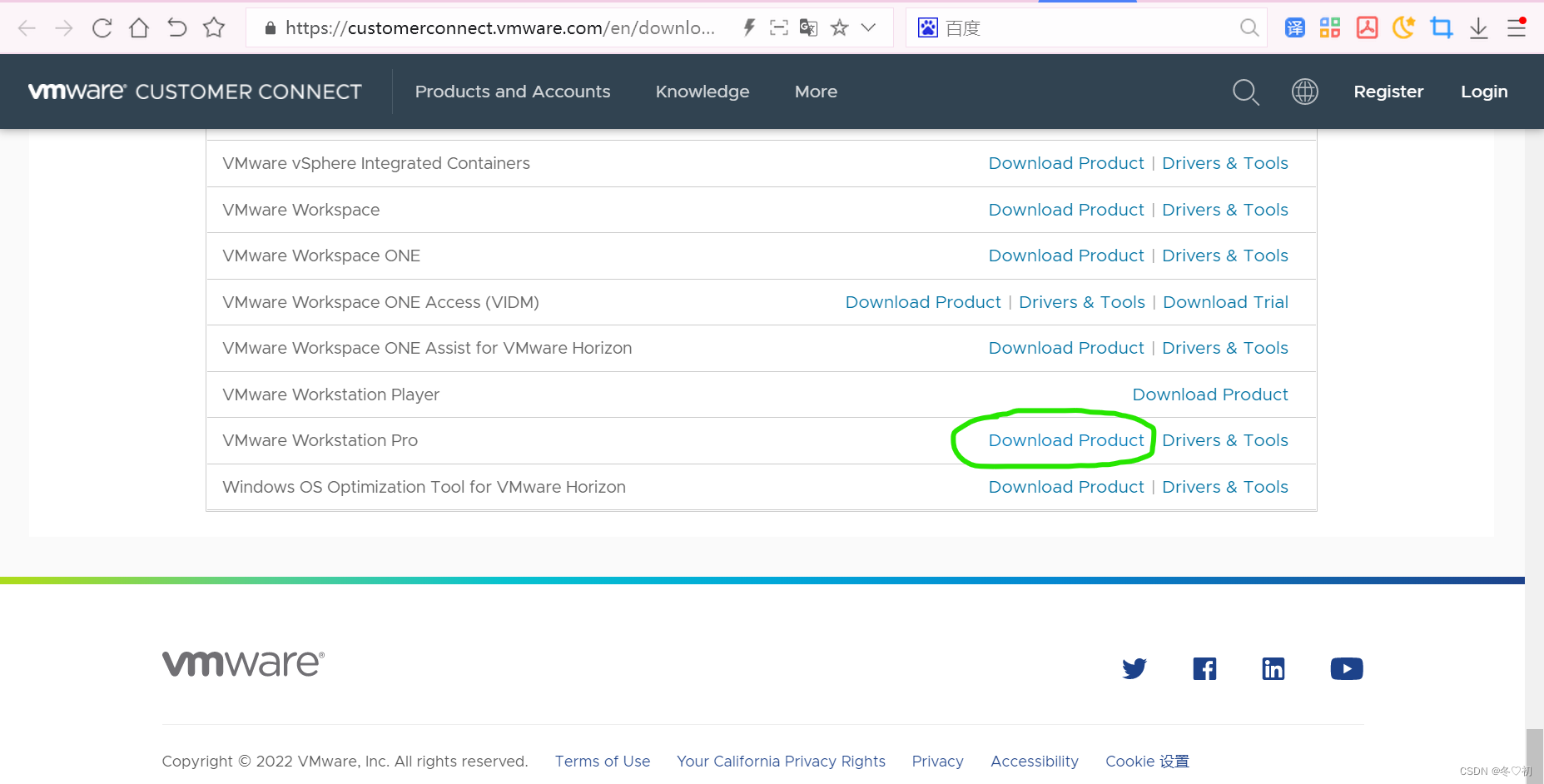
4.选择自己想要的版本,进行下载并安装(密匙在网上搜,有很多)。
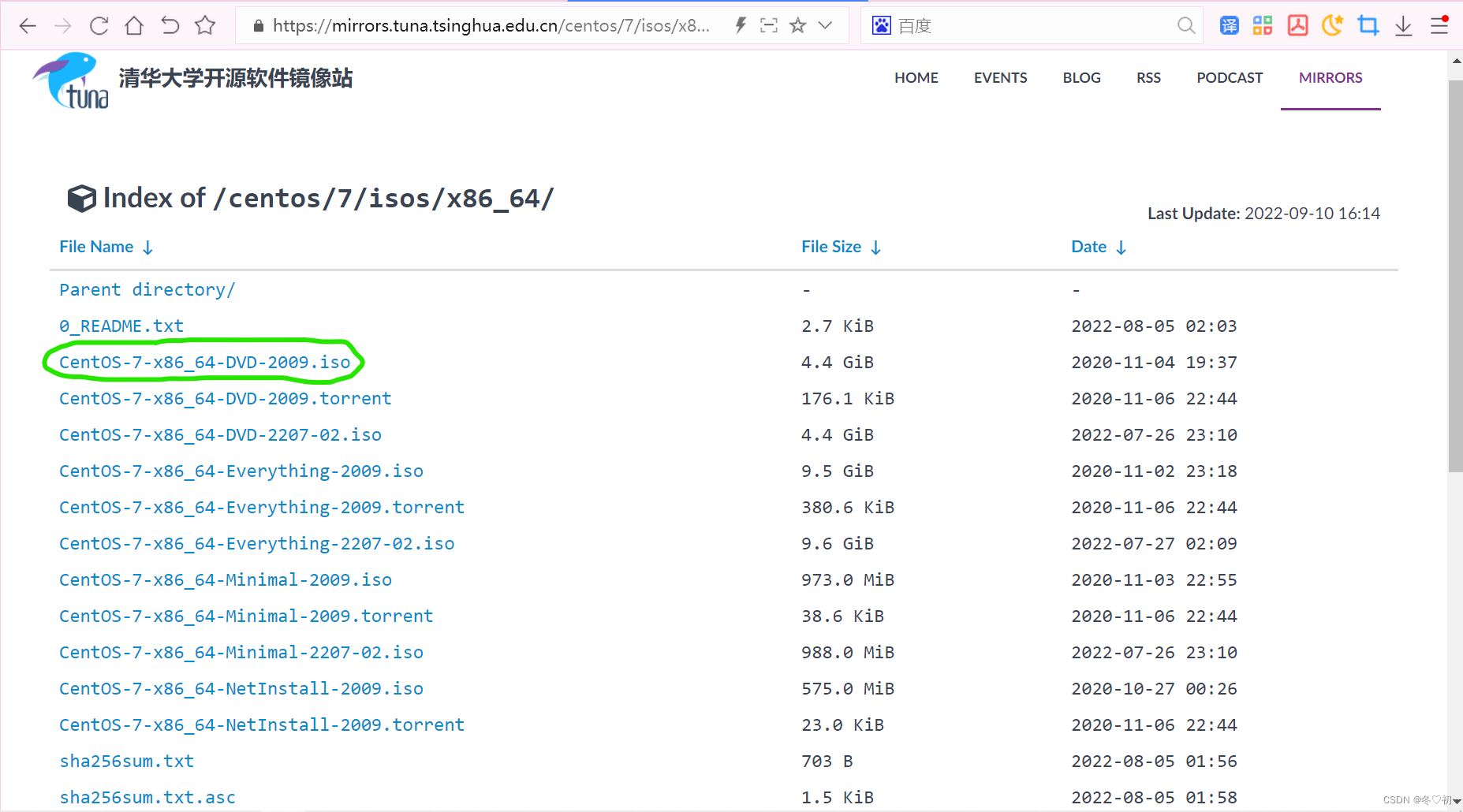
网址:https://mirrors.tuna.tsinghua.edu.cn/centos/7/isos/x86_64/。
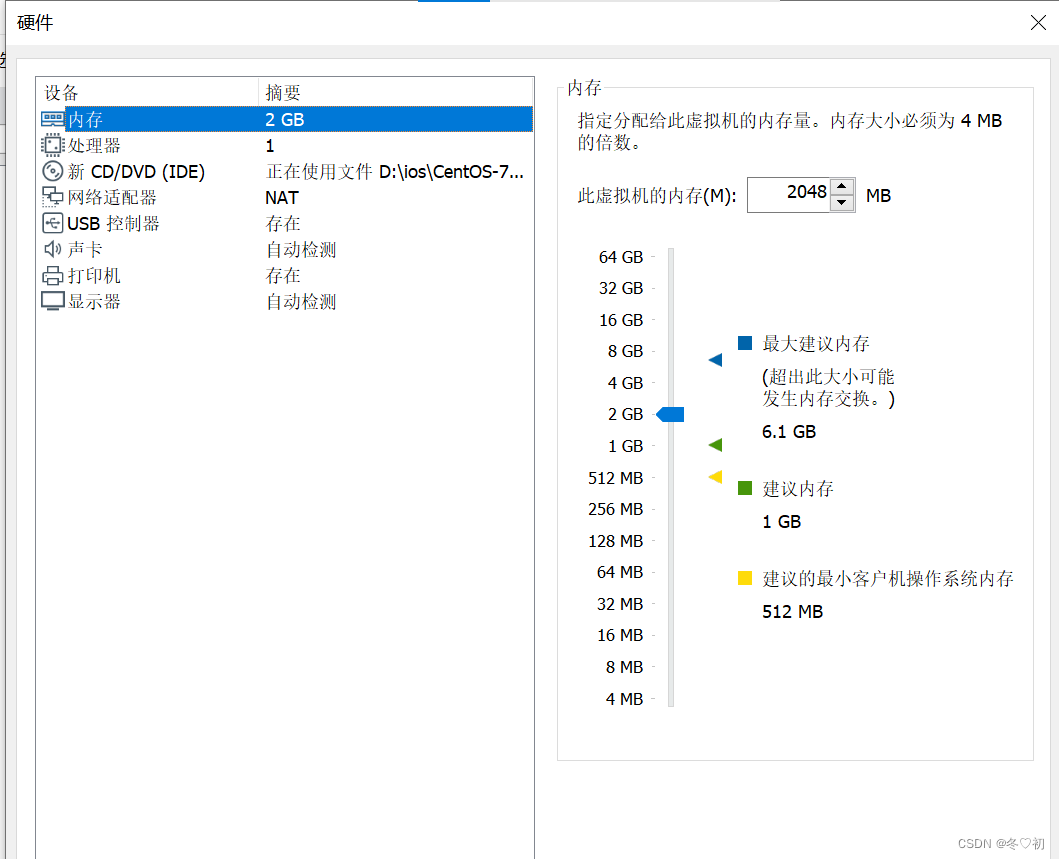
1.内存选2GB。
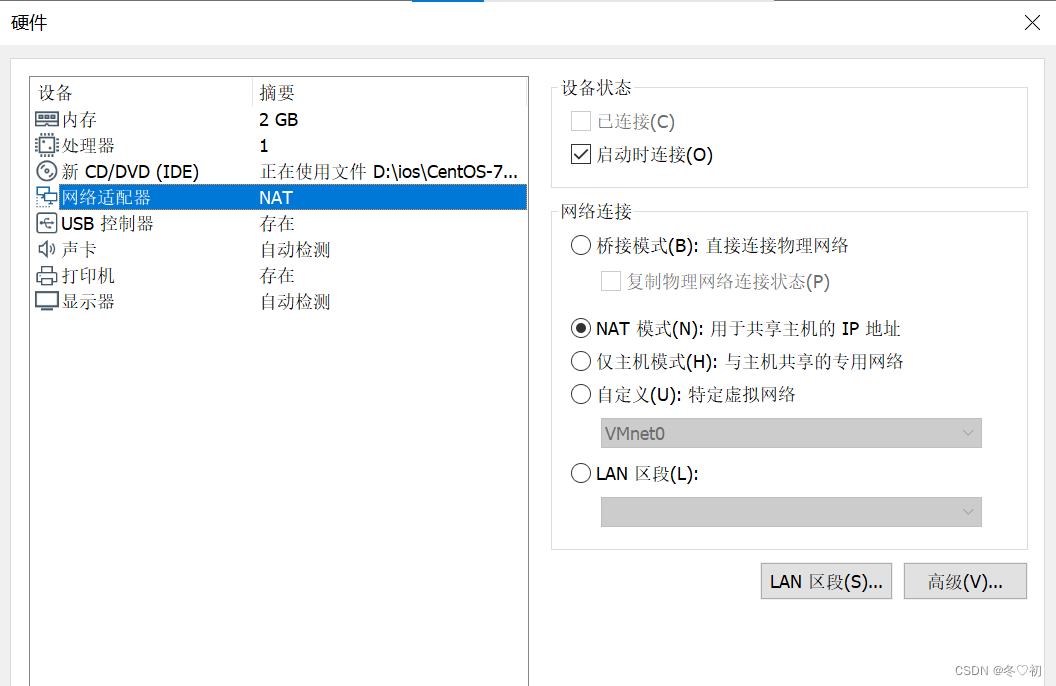
2.网络适配器选择NAT模式。
3.新CD/DVD(IDE)选择镜像文件所在路径。
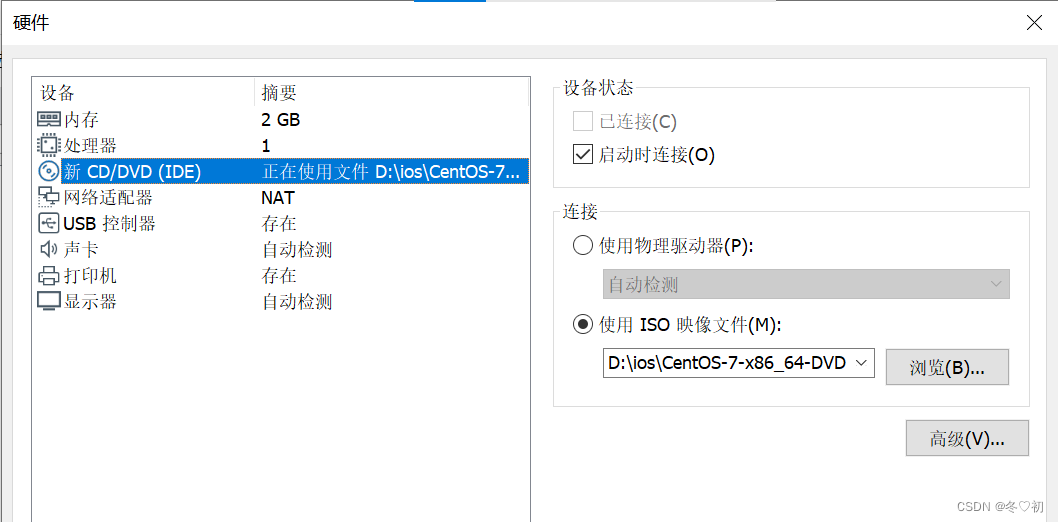
4.建好虚拟机后,选择“打开此虚拟机”,等待开机。
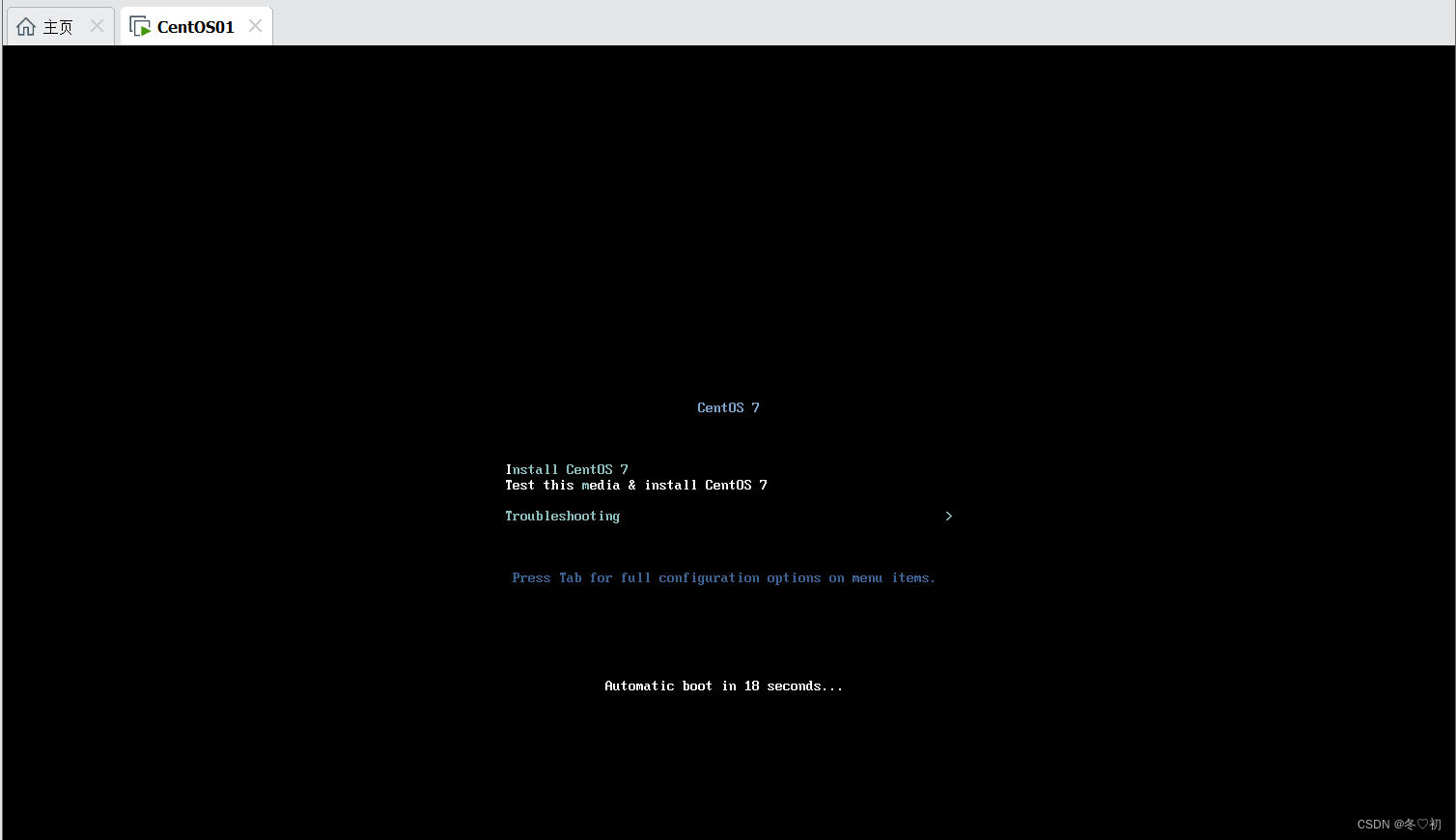
5.选择自己想要的语言,然后点继续。
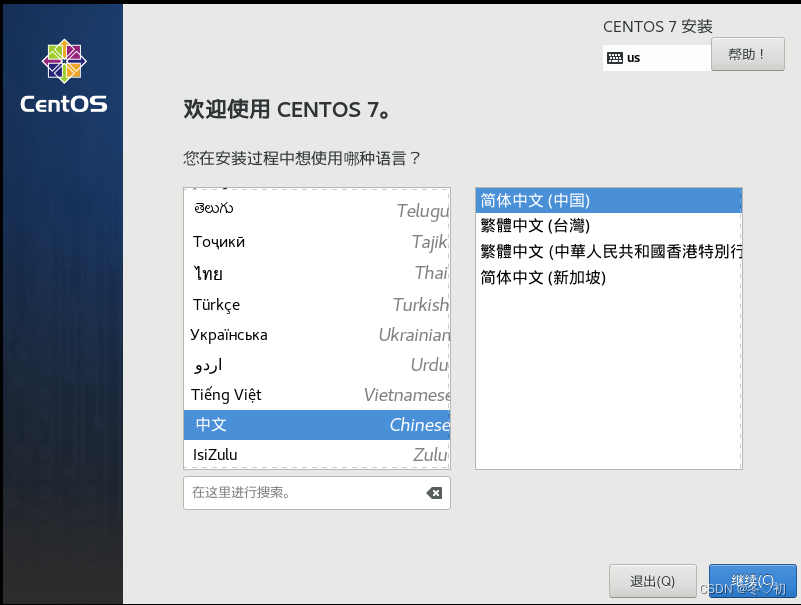
6.点击安装位置。
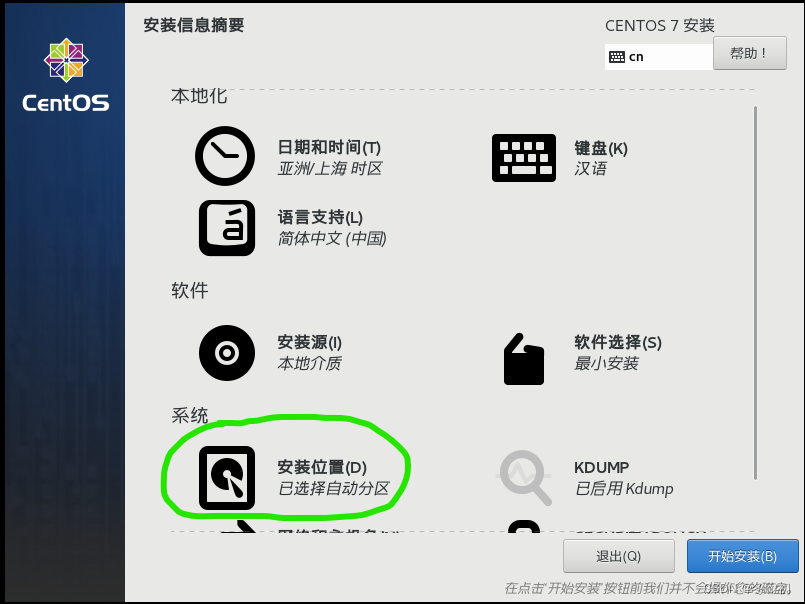
7.选择第二项:我要配置分区。
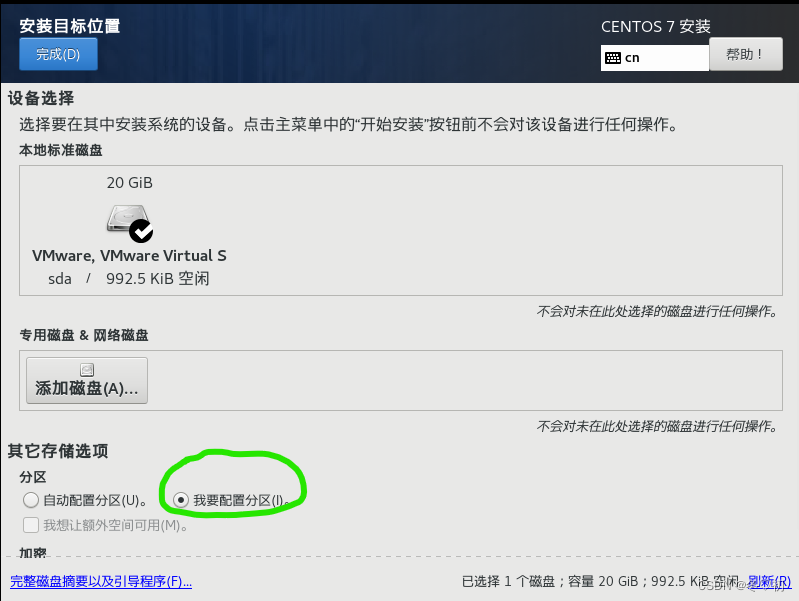
8.点击这里自动创建。
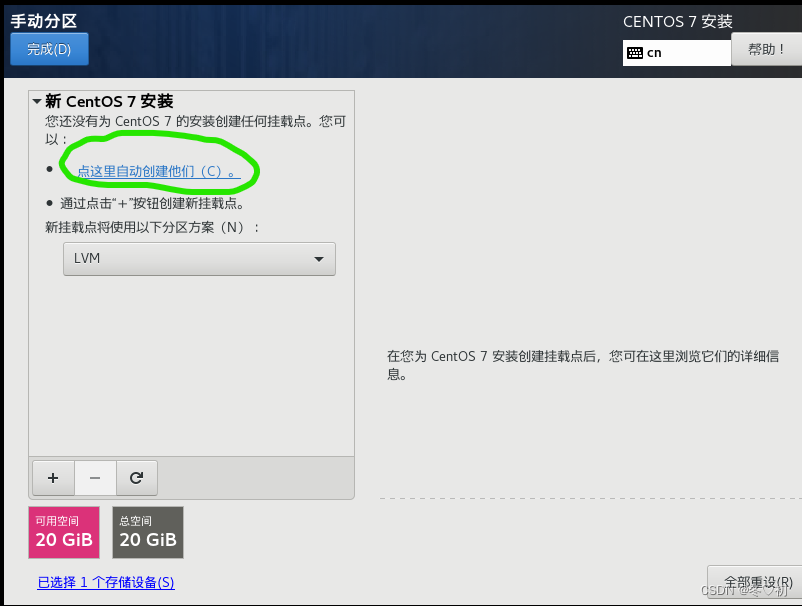
9.然后点完成。
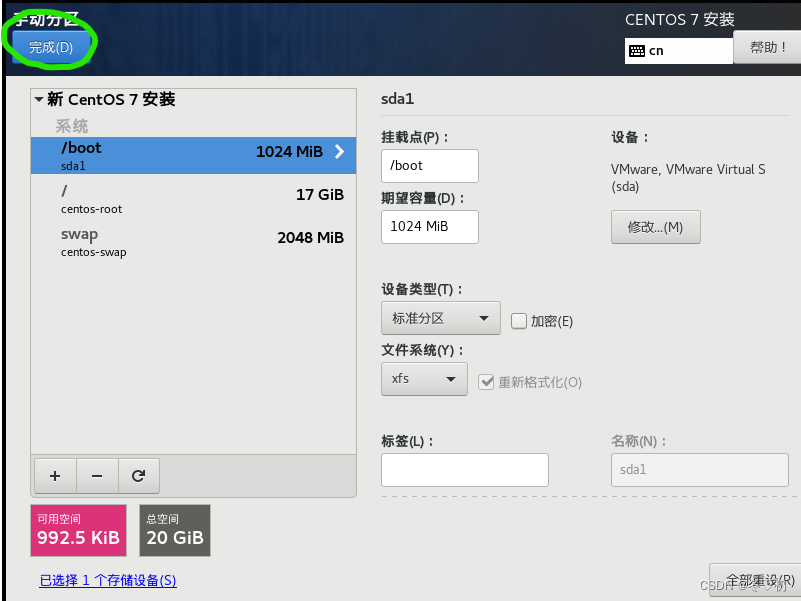
10.选择接受更改,然后选择开始安装。
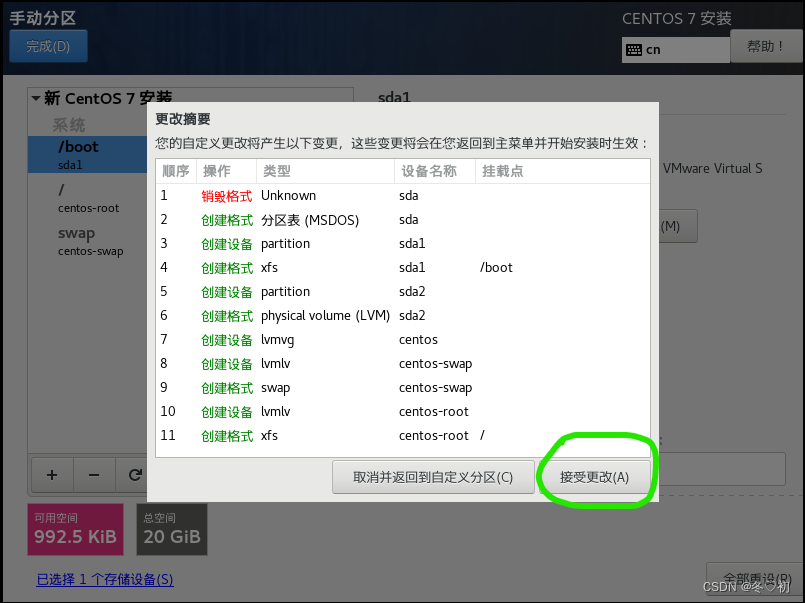
11.点击ROOT密码,进行设置,等待配置完成,最后配置完成选择重启。
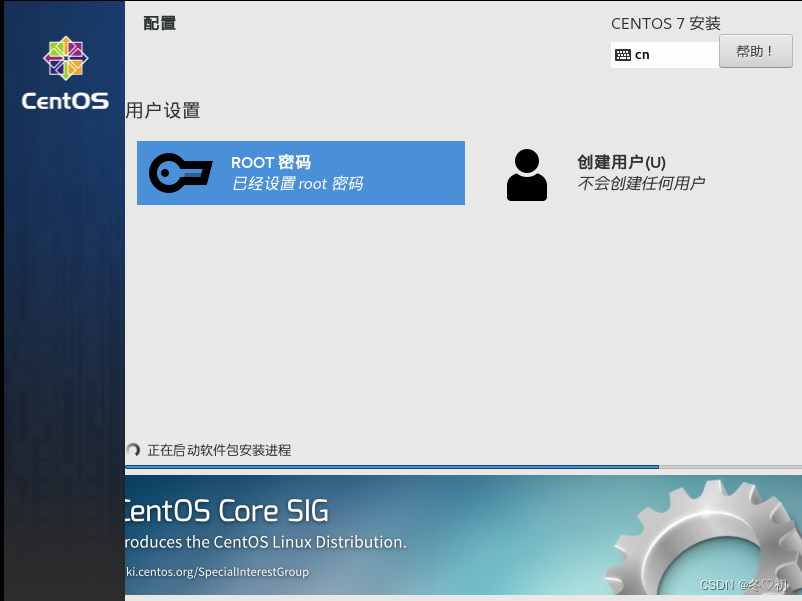
12.CentOs7最小化安装成功,关机,克隆两台虚拟机(选择完全克隆),三台虚拟机名称分别为Linux01,Linux02,Linux03。
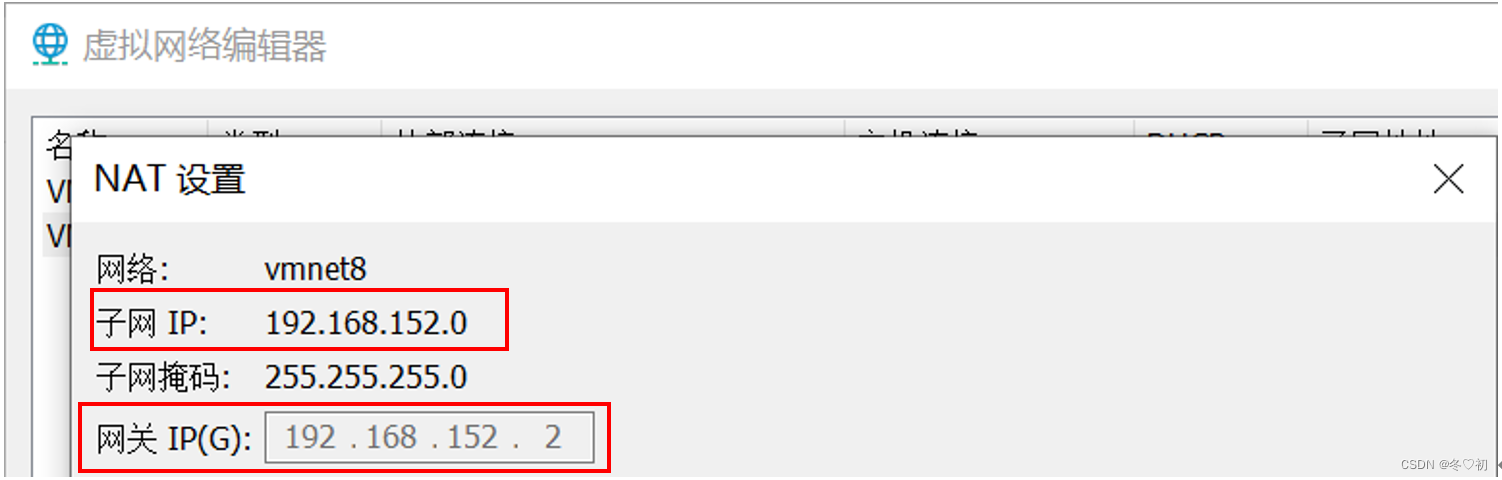
1.查看VMware的VMnet8所处的网段(NAT模式),我自己的Vmnet8的子网IP是192.168.152.0,网关是192.168.152.2。
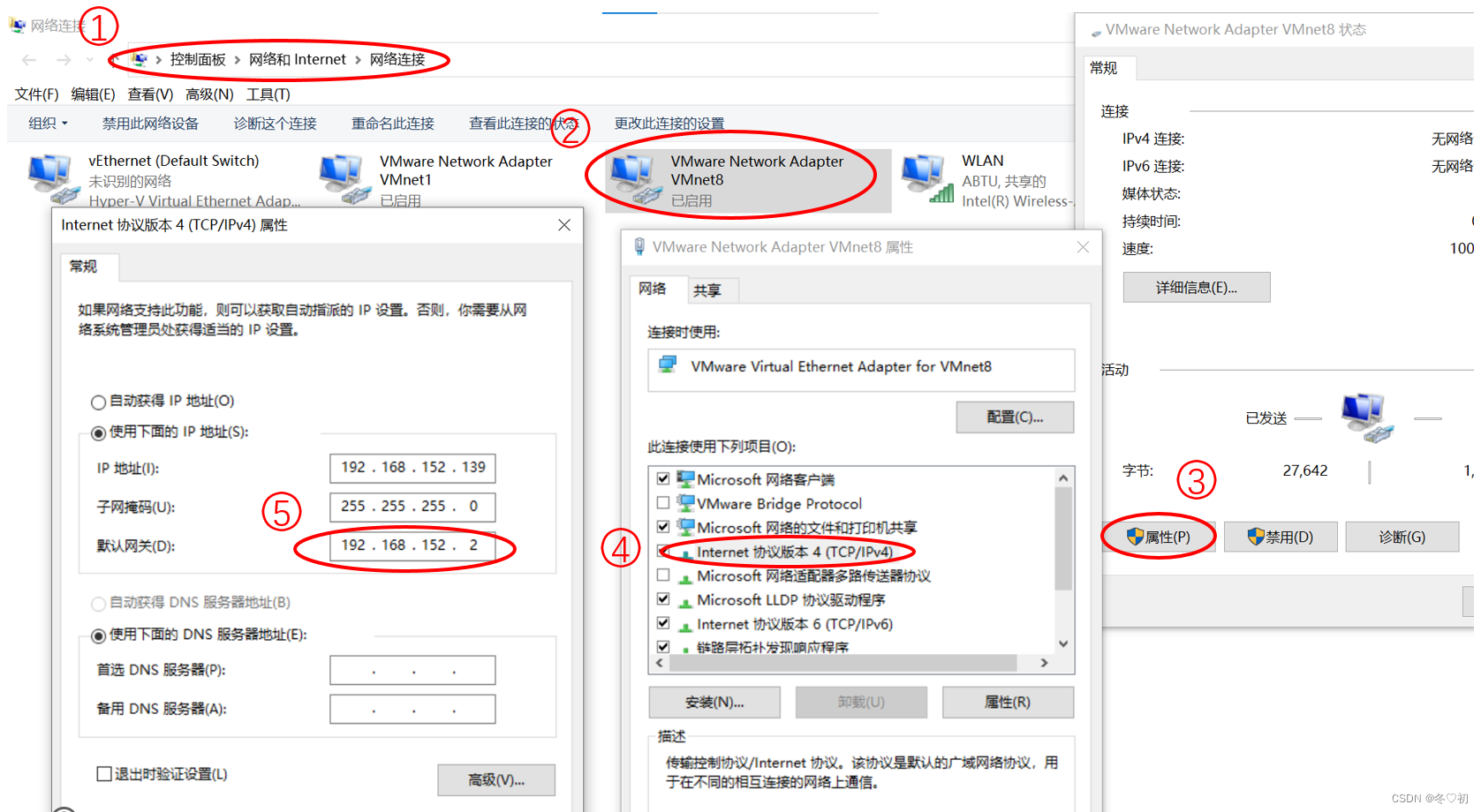
2.打开自己电脑的控制面板,选择网络和Internet,选择更改适配器,将VMnet8的网关设置成和虚拟机的一样。
3.打开虚拟机Linux01,输入用户名和密码后,再输入命令:
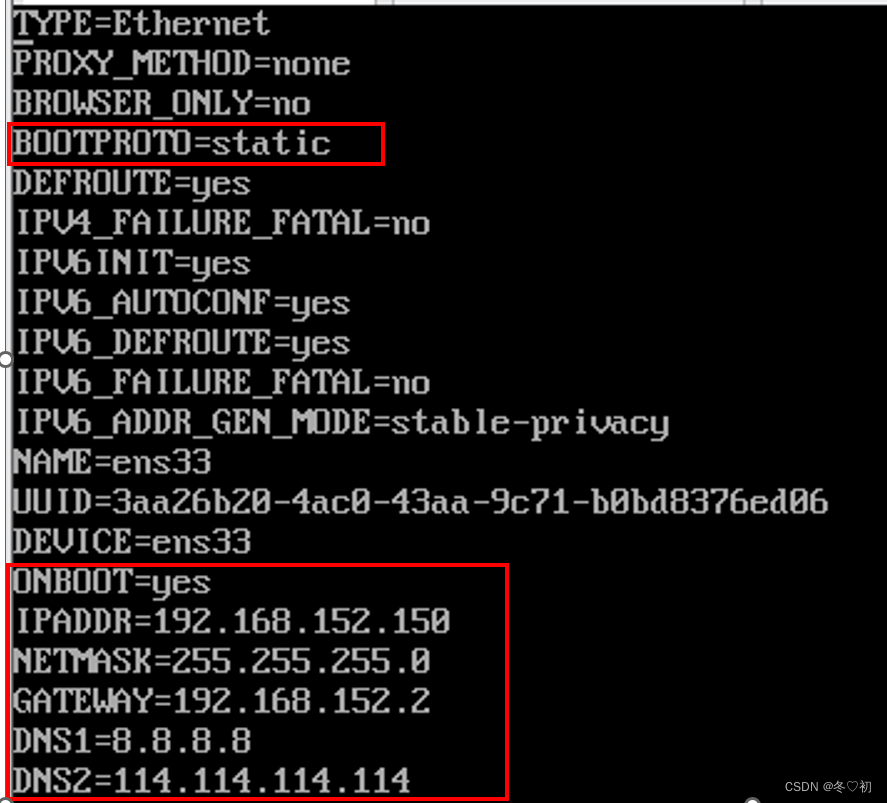
vi /etc/sysconfig/network-scripts/ifcfg-ens33,
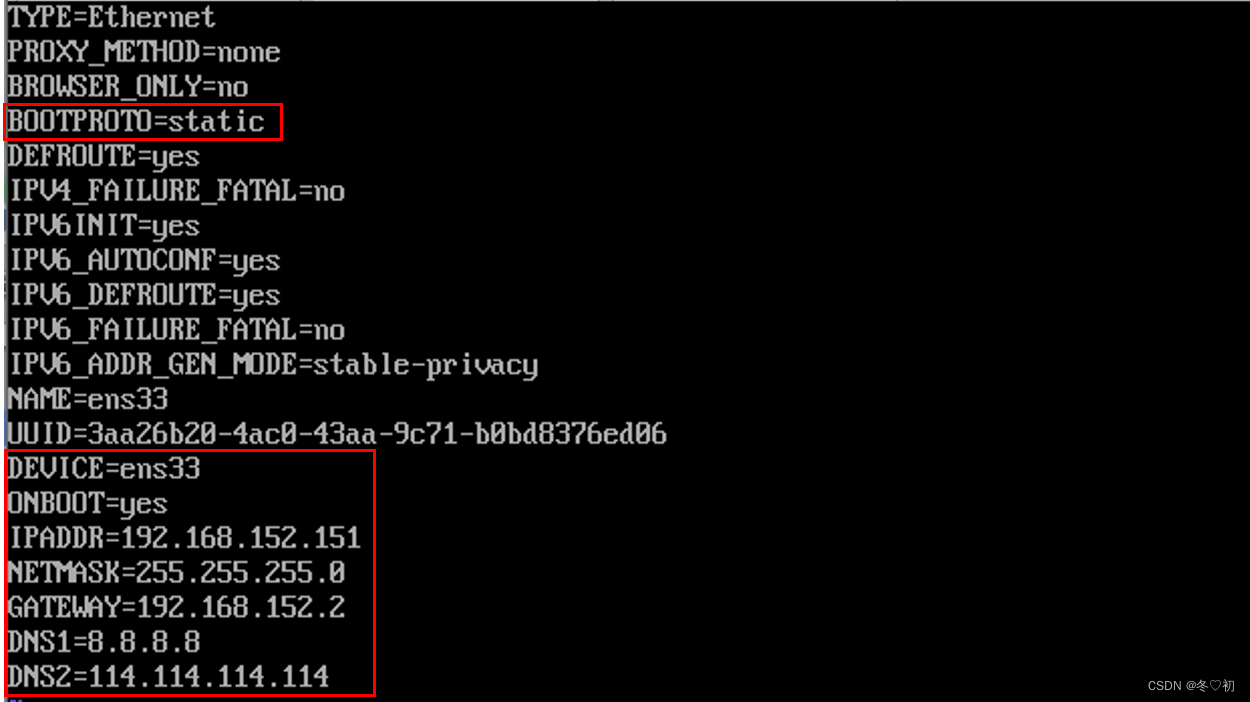
将 ONBOOT=no 改为 ONBOOT=yes,
将 BOOTPROTO=dhcp 改为 BOOTPROTO=static,
然后在文件末尾依次添加信息:
IPADDR=192.168.152.150
NETMASK=255.255.255.0
GATEWAY=192.168.152.2
DNS1=8.8.8.8
DNS2=114.114.114.114
按 ESC退出编辑模式后输入 :wq! 强制退出并保存。
4.重启网卡,输入命令:service network restart。

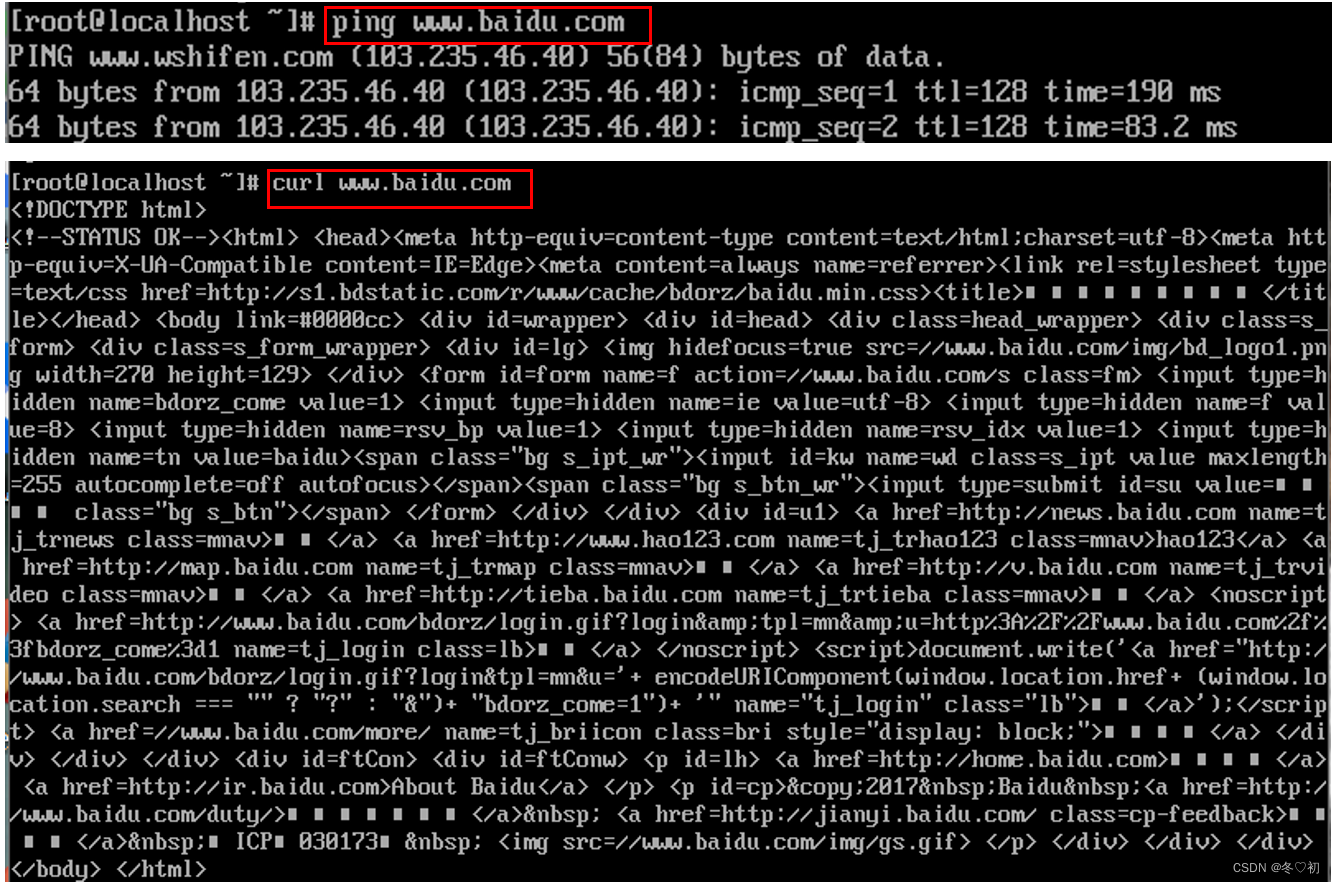
5.此时输入命令:ping www.baidu.com或者curl www.baidu.com(抓取百度页面)来验证可以连接上外网。
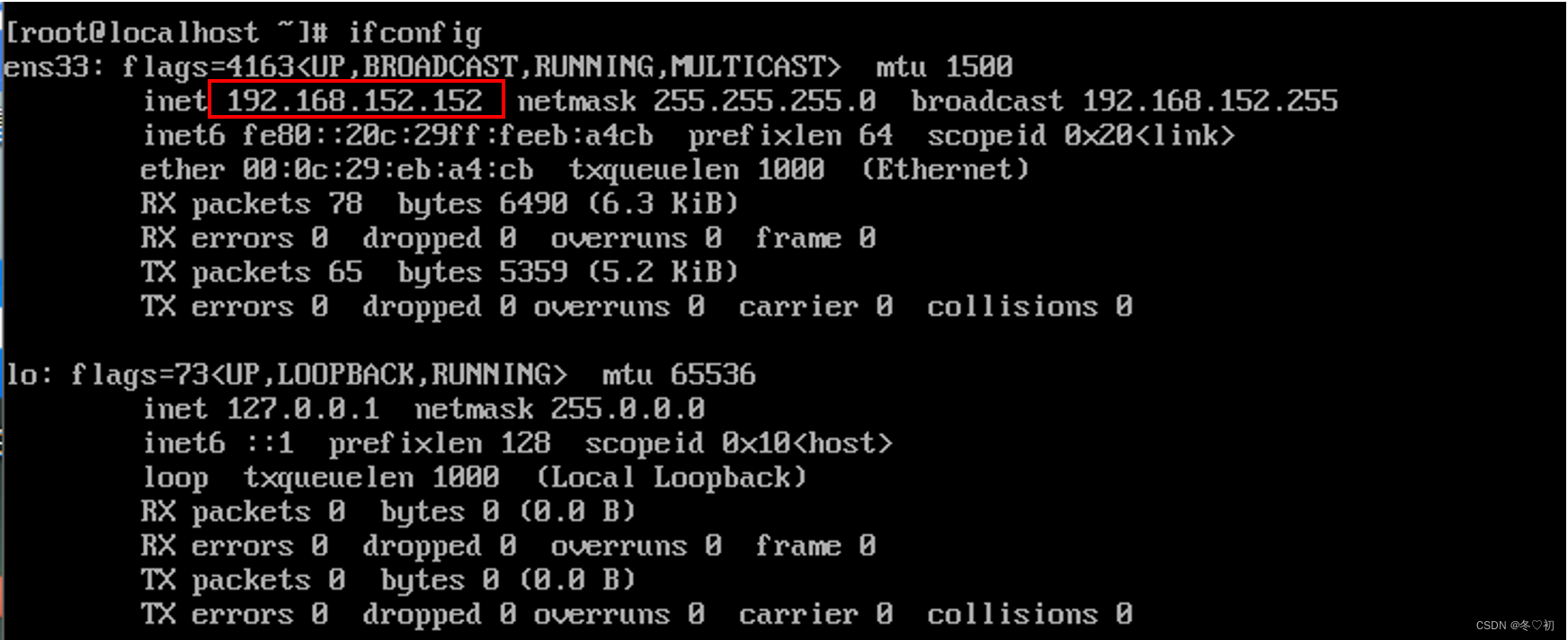
6.因为是选择的最小化安装,所以需要安装net-tools包才能使用ifconfig命令,否则会出现-bash:ifconfig not found,如图。

7.同样地,输入vim命令也是出现相同的提示,如图。
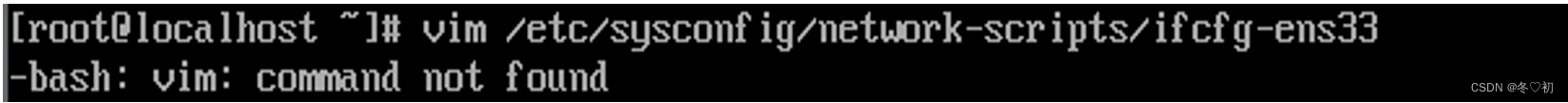
8.为了方便后面的操作,同时也把vim包安装好,首先输入命令:yum -y install net-tools。

9. 安装net-tool包成功后,显示结果如下图所示。

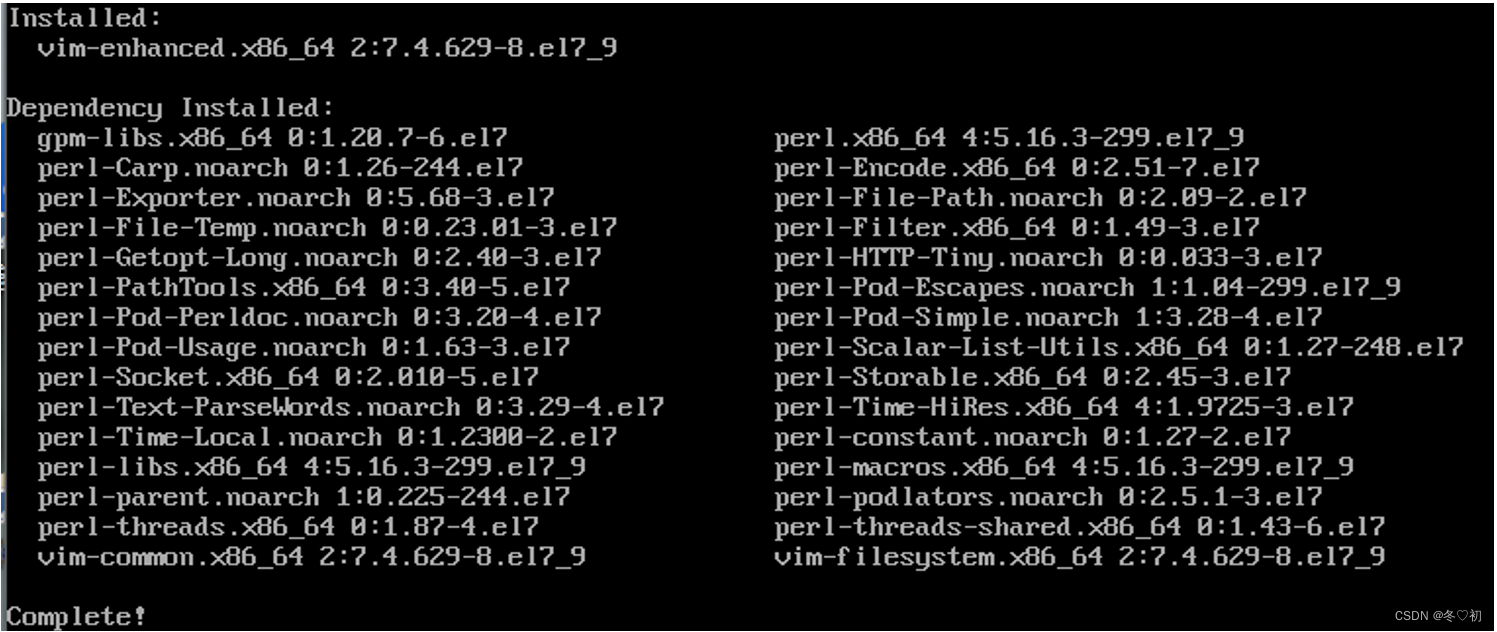
10.然后输入命令:yum install vim。

11.出现下面这个提示后输入y。
 12.安装vim包成功后,显示结果如下图所示。
12.安装vim包成功后,显示结果如下图所示。
13.输入命令:ifconfig 查询IP地址。
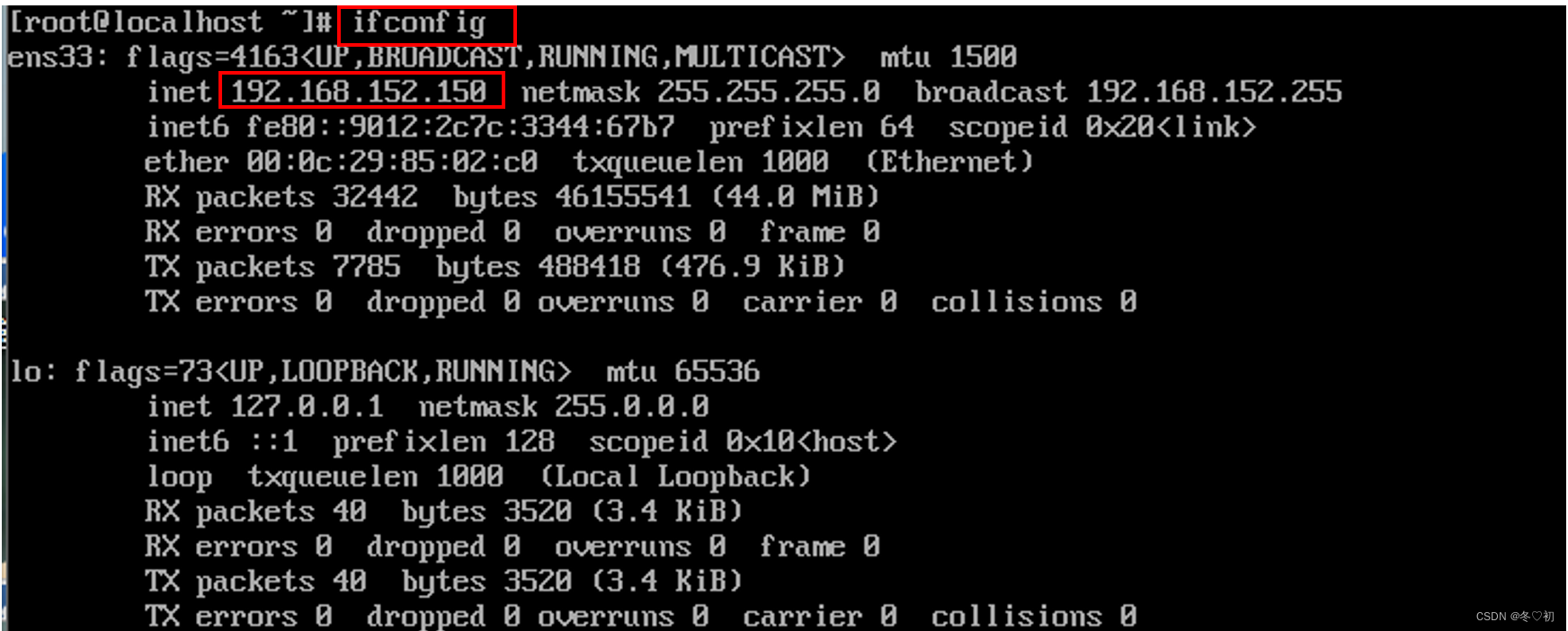
14.打开虚拟机Linux02和Linux03,重复步骤3~13。
(1)Linux02的IP地址是192.168.152.151。
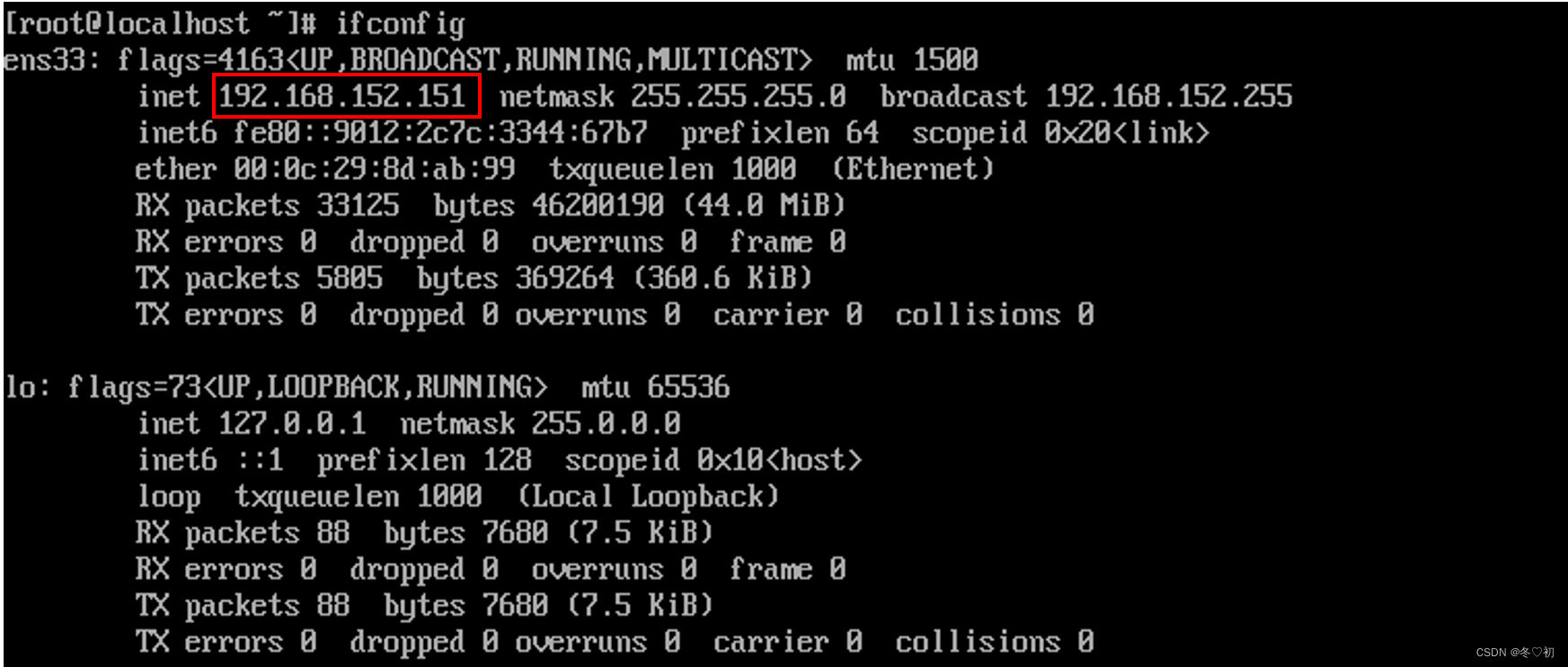
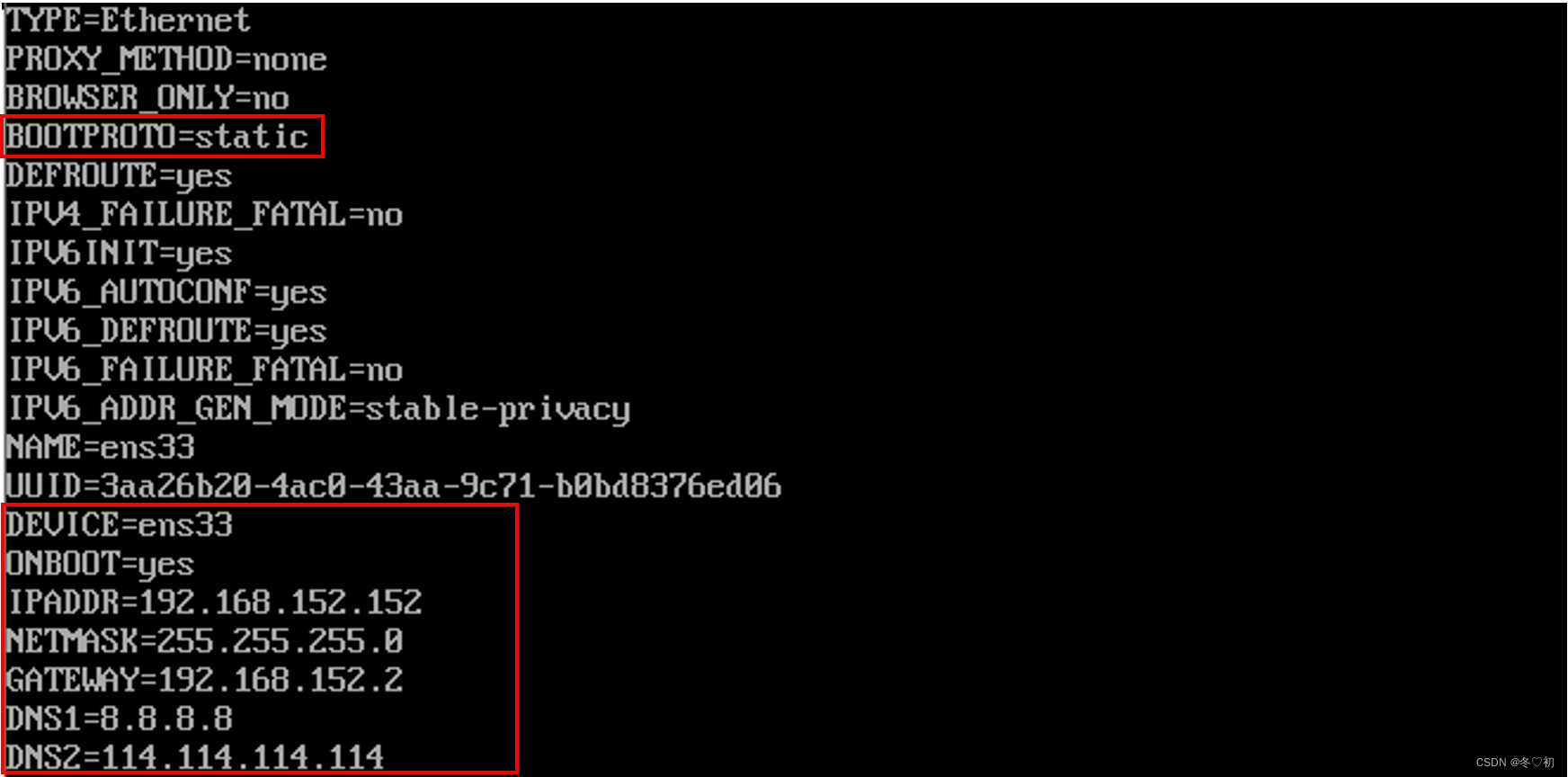
(2)Linux03的IP地址是192.168.152.152。
在官网进行下载,填写姓名和电子邮箱,然后勾选 两者 ,下载链接发到邮箱里。
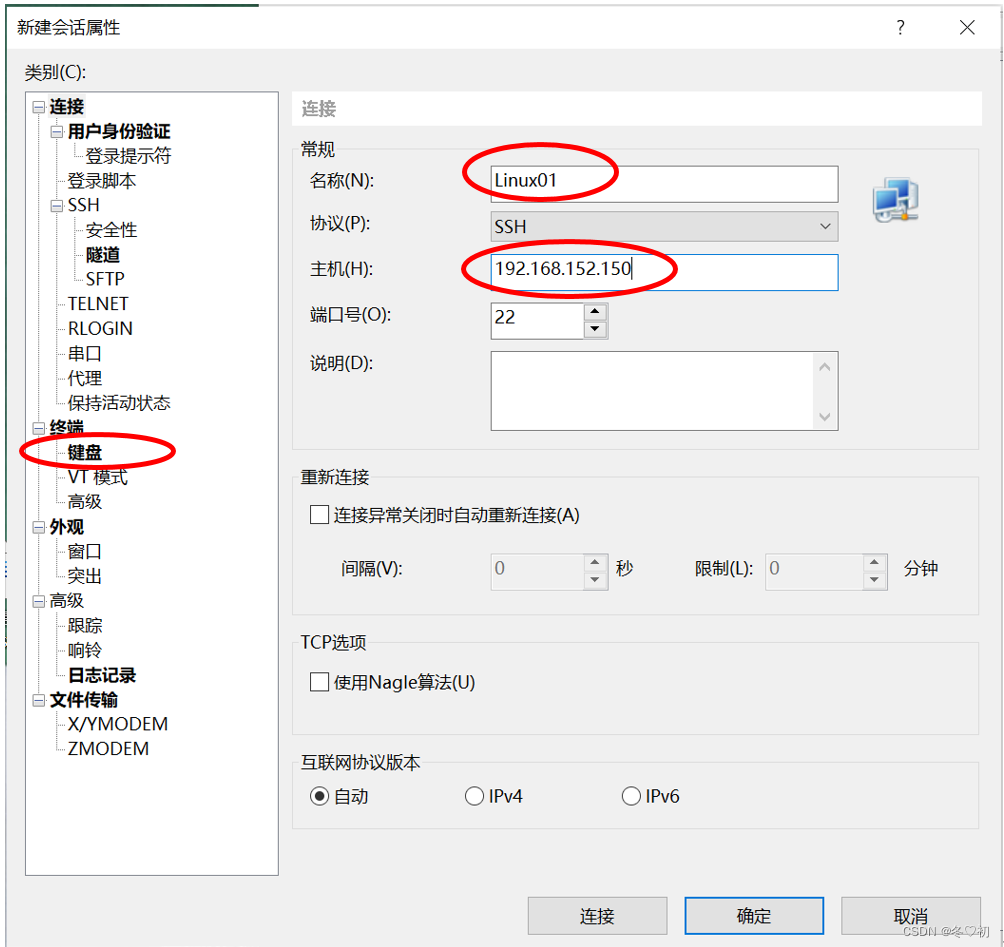
1.连接Xshell
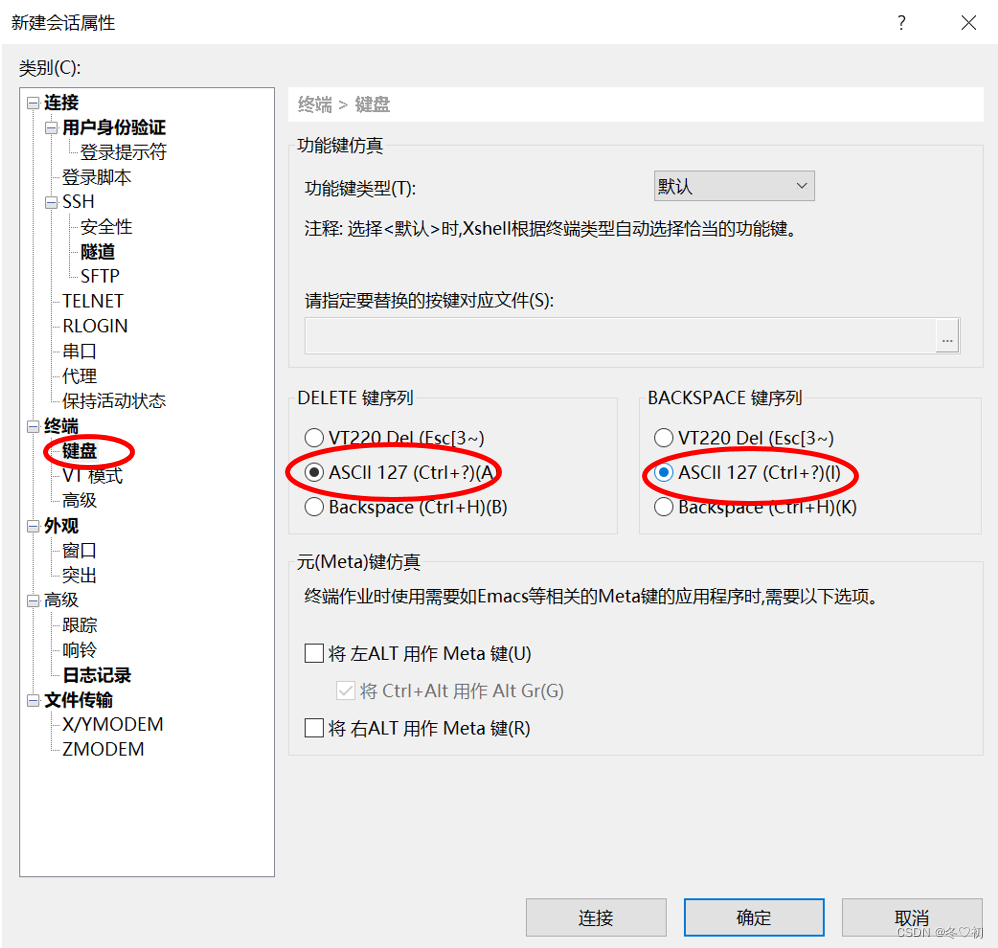
(1)新建会话,名称填Linux01,主机填Linux01的IP地址,然后选择键盘。
(2)两个都选ASCII 127,然后点连接,输入用户名(root)和密码并记住用户名和密码。
2.连接Xftp
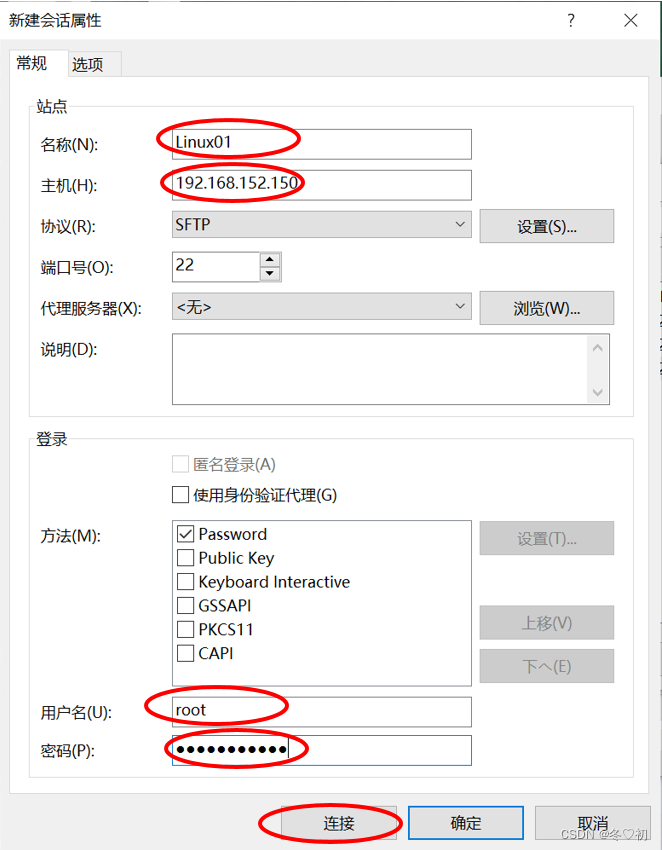
(1)新建会话,名称填Linux01,主机填Linux01的IP地址,然后输入用户名和密码,最后选择连接。
1.查看第一台虚拟机的主机名,输入命令:hostname。

2.修改主机名,输入命令:vim /etc/hostname,

3.删除旧主机名,输入新主机名(Linux01),ESC后冒号输入wq!保存并退出。

4. 然后输入reboot命令重启。

5.重启登录后,主机名变成Linux01。
6.对第二台和第三台虚拟机进行相同的操作,结果如下。


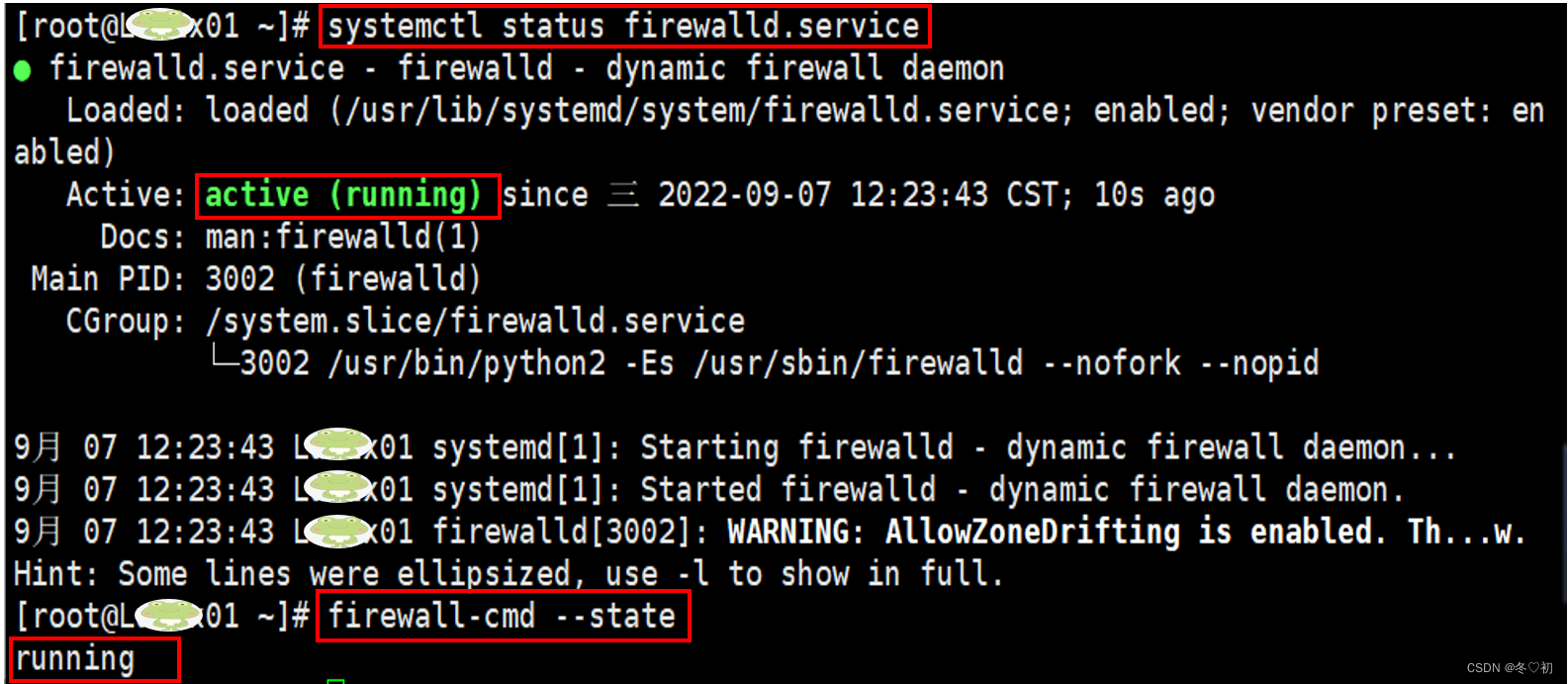
1.查看Linux01的防火墙状态。
输入命令:systemctl status firewalld.service或者firewall-cmd --state。
2.关闭防火墙,输入命令:systemctl stop firewalld.service并再次查看防火墙状态。

3.禁⽌防火墙开机启动(永久关闭防火墙),输入命令:systemctl disable firewalld.service。

4.打开Linux01,输入命令:vim /etc/selinux/config。
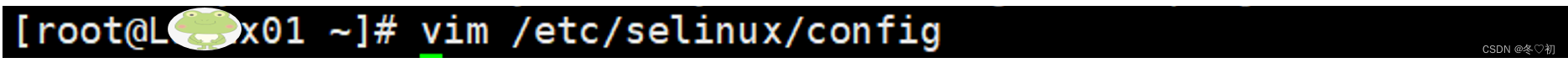
5. 将 SELINUX=enforcing 改为:SELINUX=disabled,ESC后冒号输入wq!保存并退出。
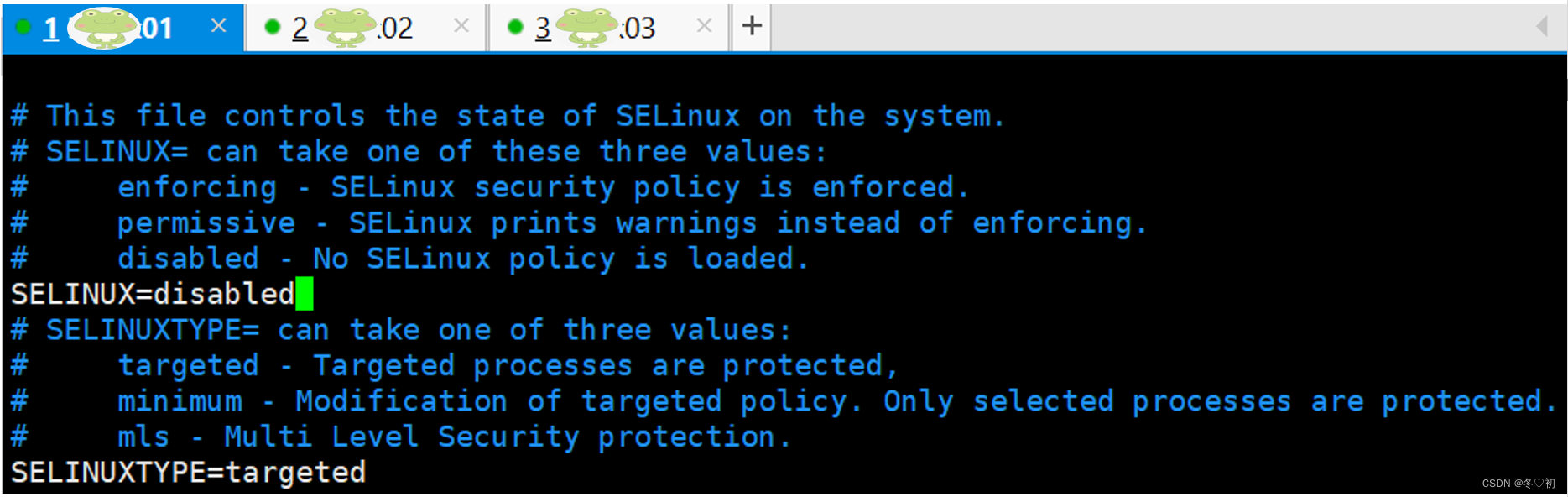
6.对虚拟机Linux02和虚拟机Linux03重复步骤1~5。
1.首先在Linux01上,生成ssh密匙。执行命令:ssh-keygen -t rsa,回车,在接下来的提示中一直回车,不用输入内容。

最后出现如下界面:
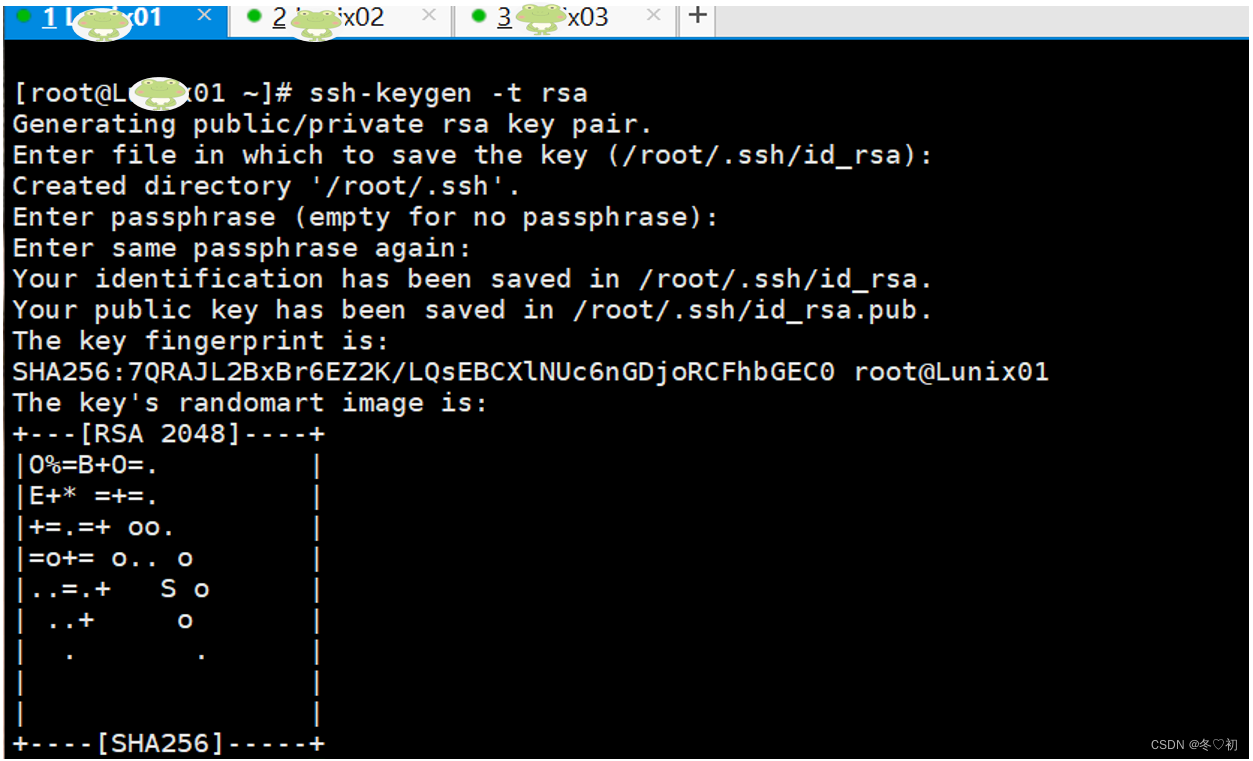
2.输入命令:cd .ssh,然后再输入ls,在家目录下的.ssh目录中出现以下两个密钥文件:

3.对Linux02、Linux03重复步骤1~2。
4.在Linux01机器上,将目录切换到.ssh目录下,输入命令:cd ~/.ssh 。

5.在.ssh目录下新建文件authorized_keys文件,输入命令:touch authorized_keys。

6.将id_rsa.pub文件内容拷贝到authorized_keys文件中,输入命令:cat id_rsa.pub >> authorized_keys,查看authorized_keys文件中的内容,输入命令:cat authorized_keys。

7.将Linux01上.ssh目录下的authorized_keys文件发送到Linux02相应的目录下,输入命令:scp authorized_keys 192.168.152.151:$PWD,然后在提示后面输入yes,回车,然后输入密码,回车,完成传输。

8.切换到Linux02机器上,进入~/.ssh目录中。

9.将Linux02上.ssh目录中id_rsa.pub文件内容拷贝到authorized_keys文件中,输入命令:cat id_rsa.pub >> authorized_keys,然后查看authorized_keys。
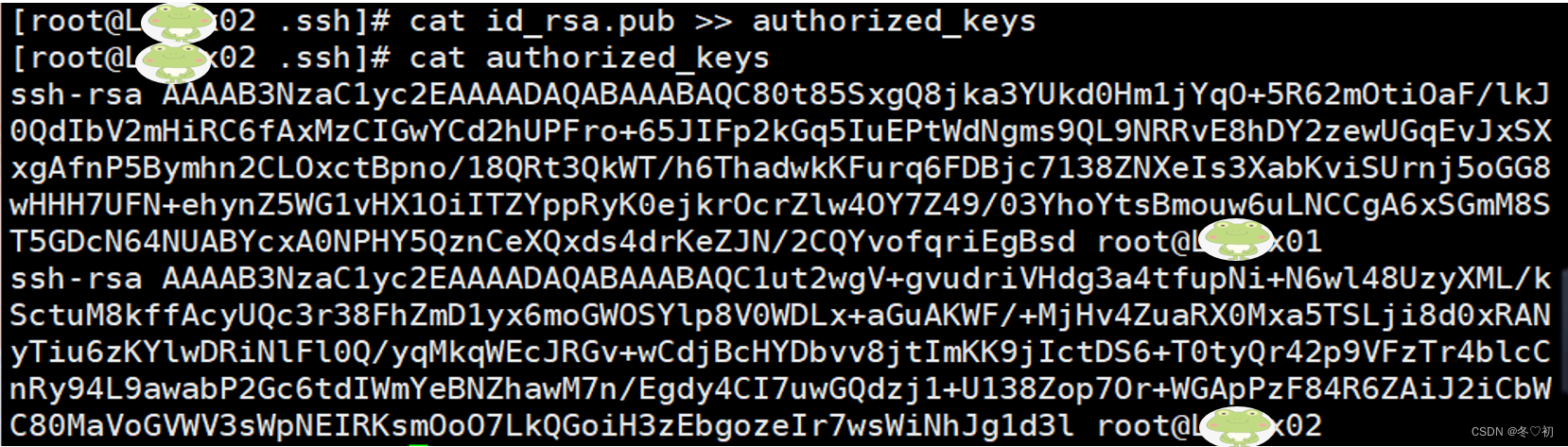
10.Linux02上.ssh目录中的authorized_keys文件发送到Linux03相应的目录下,输入命令:scp authorized_keys 192.168.152.152:$PWD。在提示中输入yes,回车,然后输入密码,回车,传输完成。
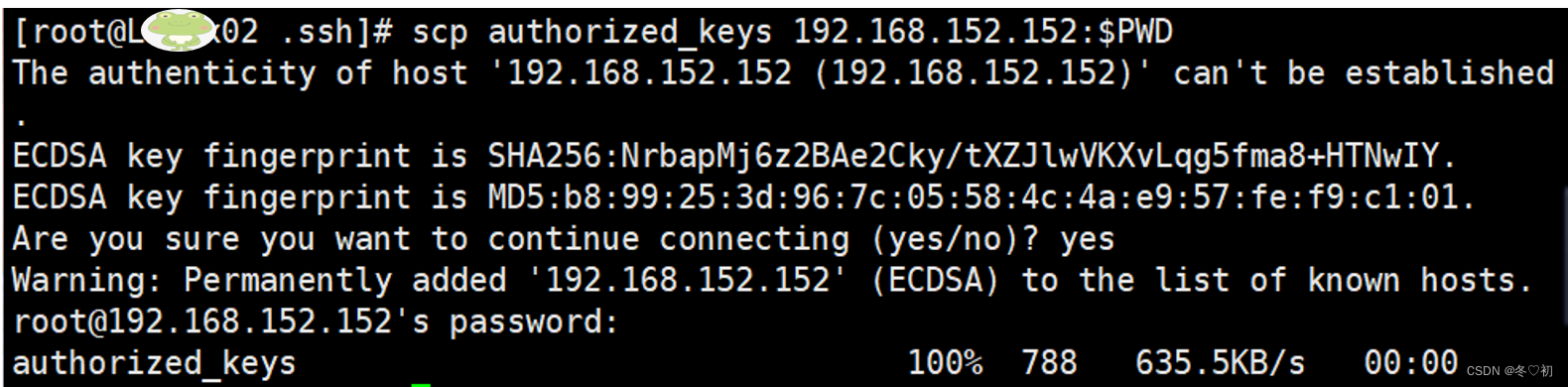
11.切换到Linux03机器上,进入~/.ssh目录中,输入命令:cd ~/.ssh。

12.将Linux03上.ssh目录中id_rsa.pub文件内容拷贝到authorized_keys文件中,输入命令:cat id_rsa.pub >> authorized_keys,然后查看authorized_keys文件中的内容,输入命令:cat authorized_keys。
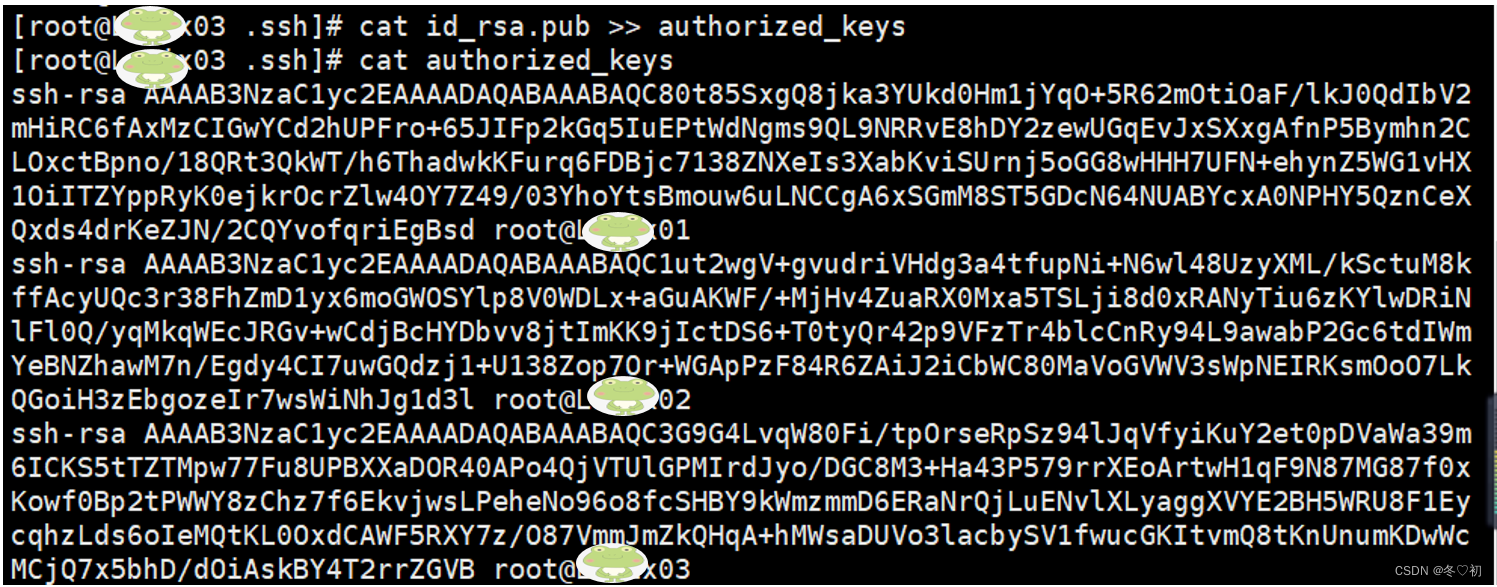
13.将Linux03上.ssh目录中authorized_keys文件回传给Linux02和Linux01。
(1)回传给Linux02输入命令:scp authorized_keys 192.168.152.151:$PWD。

(2)回传给Linux01,输入命令:scp authorized_keys 192.168.152.150:$PWD。

14.在Linux01上进行验证,输入命令:ssh 192.168.152.151。

1.在Linux01上打开/etc/hosts文件,输入命令:vim /etc/hosts。

然后在文件中添加:
192.168.152.150 Linux01
192.168.152.151 Linux02
192.168.152.152 Linux03
然后按ESC键,输入 :wq! 保存退出。

2.将Linux01上/etc/hosts文件分别分发到Linuxx02,Linux03上。
(1)输入命令scp /etc/hosts 192.168.152.151:/etc/
 (2)输入命令scp /etc/hosts 192.168.152.152:/etc/。
(2)输入命令scp /etc/hosts 192.168.152.152:/etc/。

3.在Linux01上分别验证Linux02和Linux03。
(1)输入命令:ping Linux02。
 (2)输入命令:ping Linux03。
(2)输入命令:ping Linux03。

1.首先检查系统中是否自带JDK,输入命令:rpm -qa | grep jdk。

通过输入命令后的结果可以知道,系统没有自带JDK,可以直接进行接下来的操作。
2.用xftp软件将jdk上传到linux 的用户家目录下。
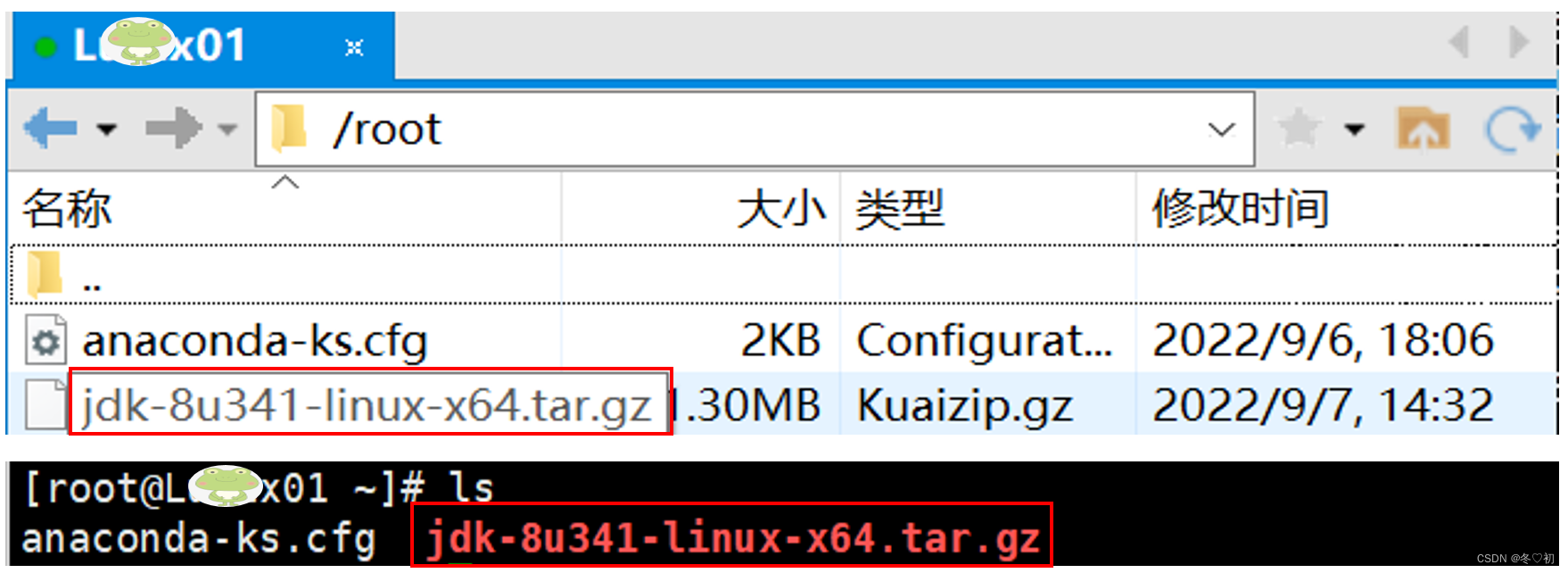
3.在根目录下建服务器软件服务目录,输入命令:mkdir -p /exports/servers。

4.将家目录下jdk解压到/exports/servers目录下,输入命令:tar -zxvf jdk-8u341-linux-x64.tar.gz -C /exports/servers。

5.查看/exports/servers目录下是否有解压后的文件。

6.在Linux02和Linux02上重复步骤1~5。
1.首先将JDK的根目录复制下来,将目录切换到JDK的根目录下。输入命令:
cd /exports/servers/jdk1.8.0_341/,然后输入命令pwd复制出现的路径。

2.打开环境变量配置文件,输入命令:vim /etc/profile。

3.在文件末尾添加:
export JAVA_HOME=/exports/servers/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
然后按ESC键输入冒号wq!保存并退出。

4.重启配置文件,输入命令:source /etc/profile。

5.验证环境变量是否配置成功,输入命令:java -version。

6.将Linux01上的/exports目录的内容分别传输到Linux02和Linux03。
(1)输入命令:scp -r /exports Linux02:/。
 (2)输入命令:scp -r /exports Linux03:/。
(2)输入命令:scp -r /exports Linux03:/。

7.将Linux01上的/etc/profile环境变量配置文件分别发送到Linux0102和Linux0103上
(1)输入命令:scp /etc/profile Linux02:/etc/。
 (2)输入命令:scp /etc/profile Linux03:/etc/。
(2)输入命令:scp /etc/profile Linux03:/etc/。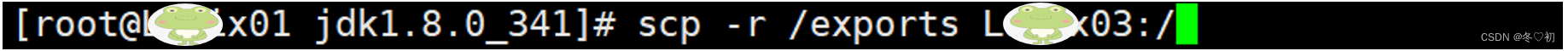 8. 在Linux02和Linux02上执行命令source /etc/profile 命令。
8. 在Linux02和Linux02上执行命令source /etc/profile 命令。
 9.在Linux02和Linux02上分别验证环境变量是否配置成功。
9.在Linux02和Linux02上分别验证环境变量是否配置成功。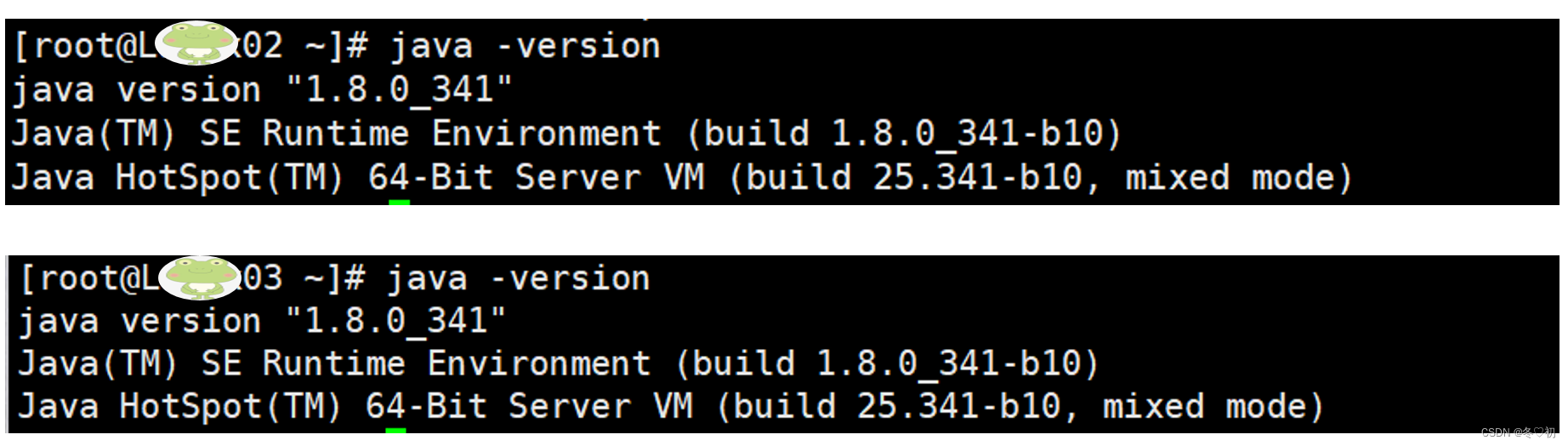
1.通过传输软件将hadoop-2.10.2.tar.gz上传到Linux01的root的家目录下。
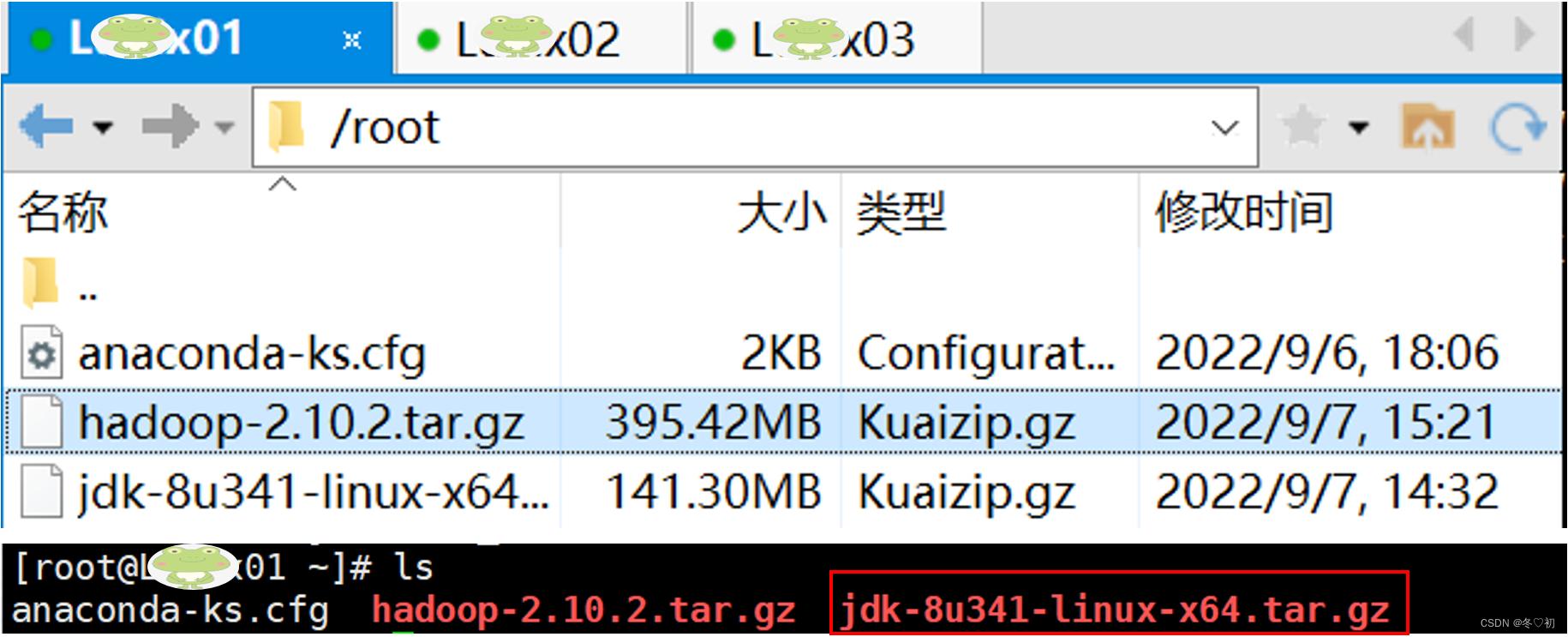 2.将hadoop-2.10.2.tar.gz解压到/exports/servers目录下,输入命令:tar -zxvf hadoop-2.10.2.tar.gz -C /exports/servers。
2.将hadoop-2.10.2.tar.gz解压到/exports/servers目录下,输入命令:tar -zxvf hadoop-2.10.2.tar.gz -C /exports/servers。 3.切换到/exports/servers/hadoop-2.10.2.tar.gz目录下,输入命令:cd /exports/servers/hadoop-2.10.2。
3.切换到/exports/servers/hadoop-2.10.2.tar.gz目录下,输入命令:cd /exports/servers/hadoop-2.10.2。
 4.在Hadoop的根目录下新建datas目录,输入命令:mkdir datas。
4.在Hadoop的根目录下新建datas目录,输入命令:mkdir datas。

1.进入etc/hadoop目录下,输入命令:cd /exports/servers/hadoop-2.10.2 /etc/hadoop/。

2.修改hadoop-env.sh文件,输入命令:vim hadoop-env.sh。
 在“# The java implementation to use”下面添上:
在“# The java implementation to use”下面添上:
export JAVA_HOME=/exports/servers/jdk1.8.0_341
然后ESC键冒号wq!保存并退出。

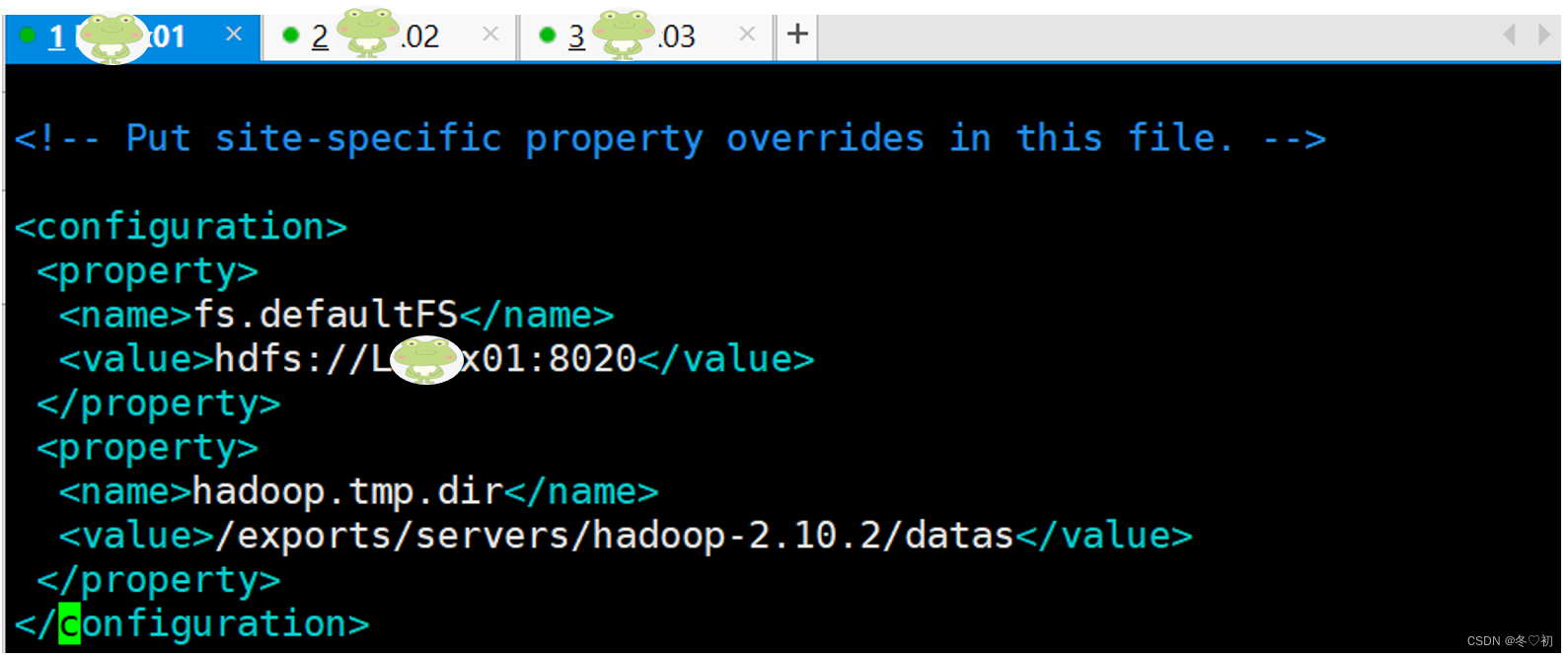
3.修改core-site.xml,输入命令:vim core-site.xml,在标签中加入子标签内容。

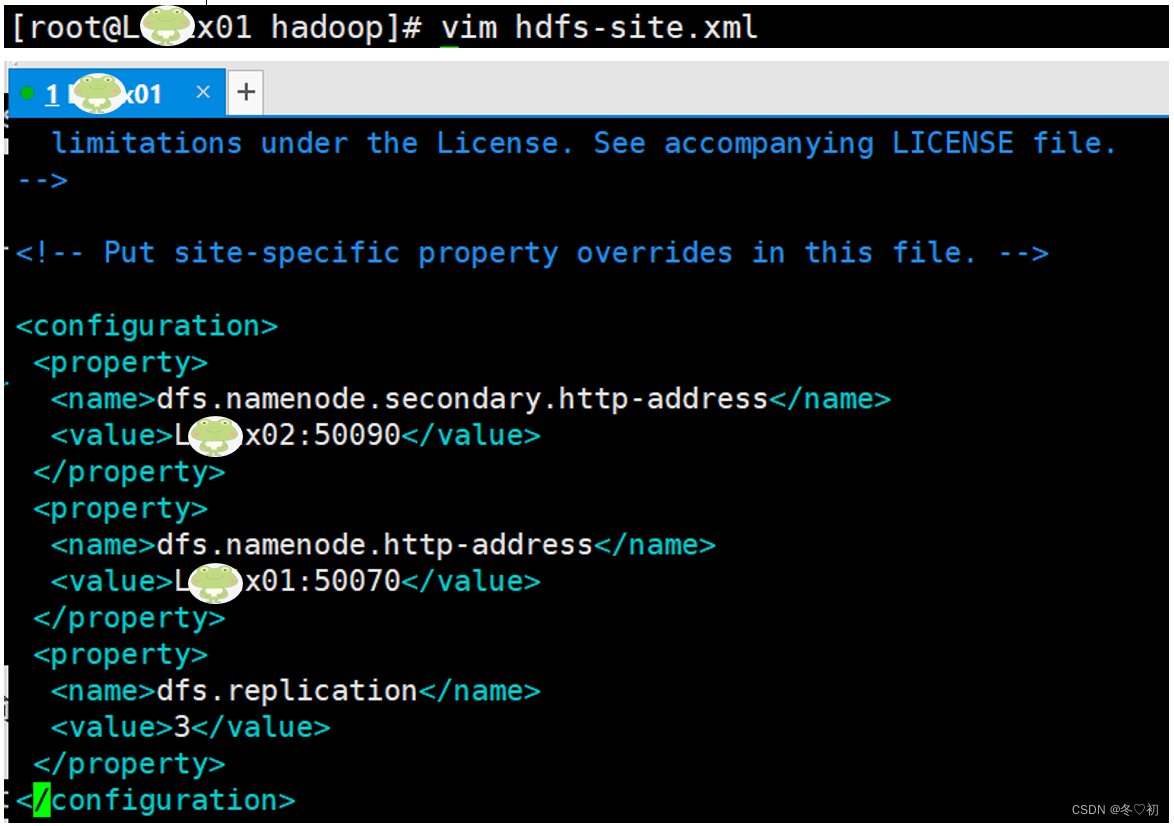
4.修改hdfs-site.xml,输入命令:vim hdfs-site.xml,在标签中加入子标签内容。
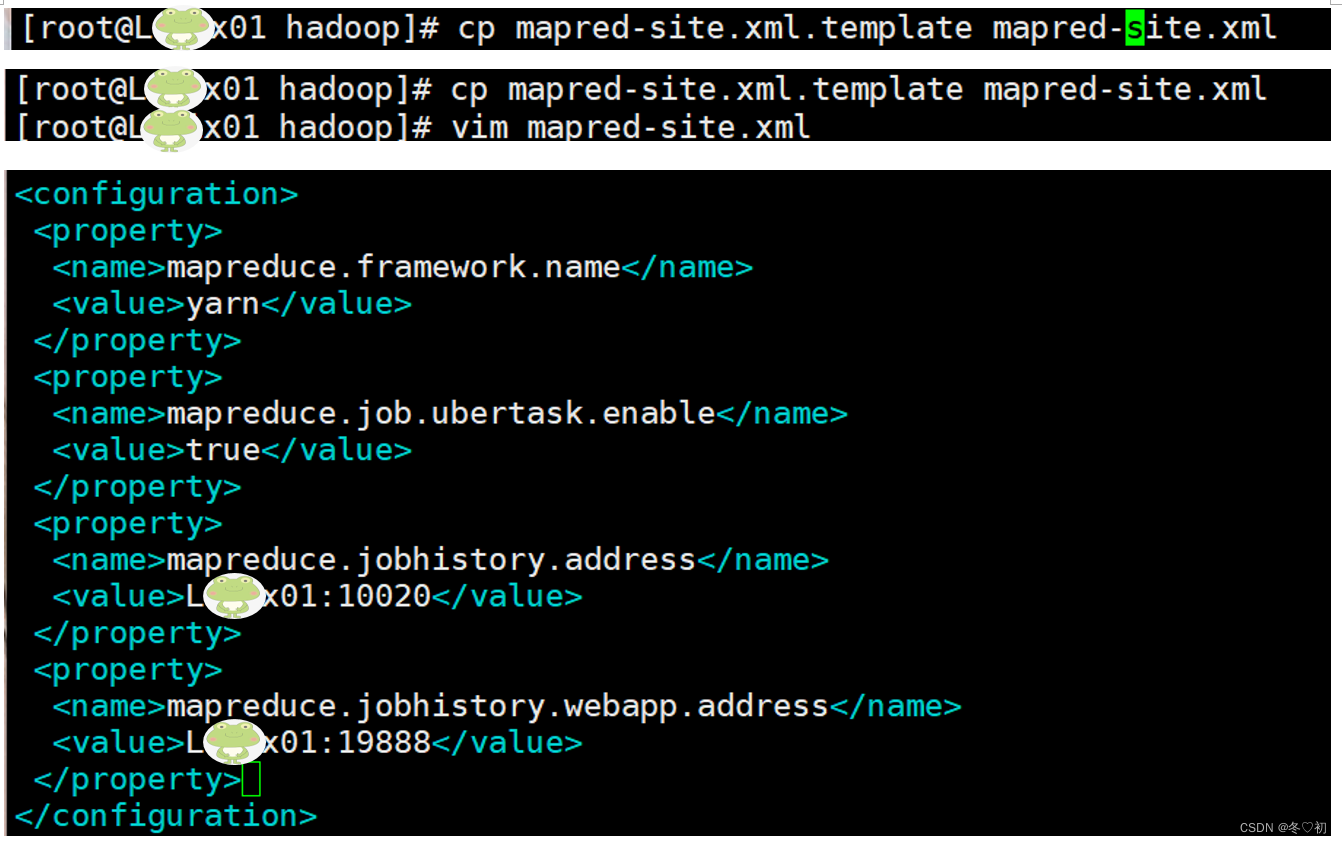
5.修改mapred-site.xml文件,输入命令:vim mapred-site.xml,在标签中加入子标签内容。
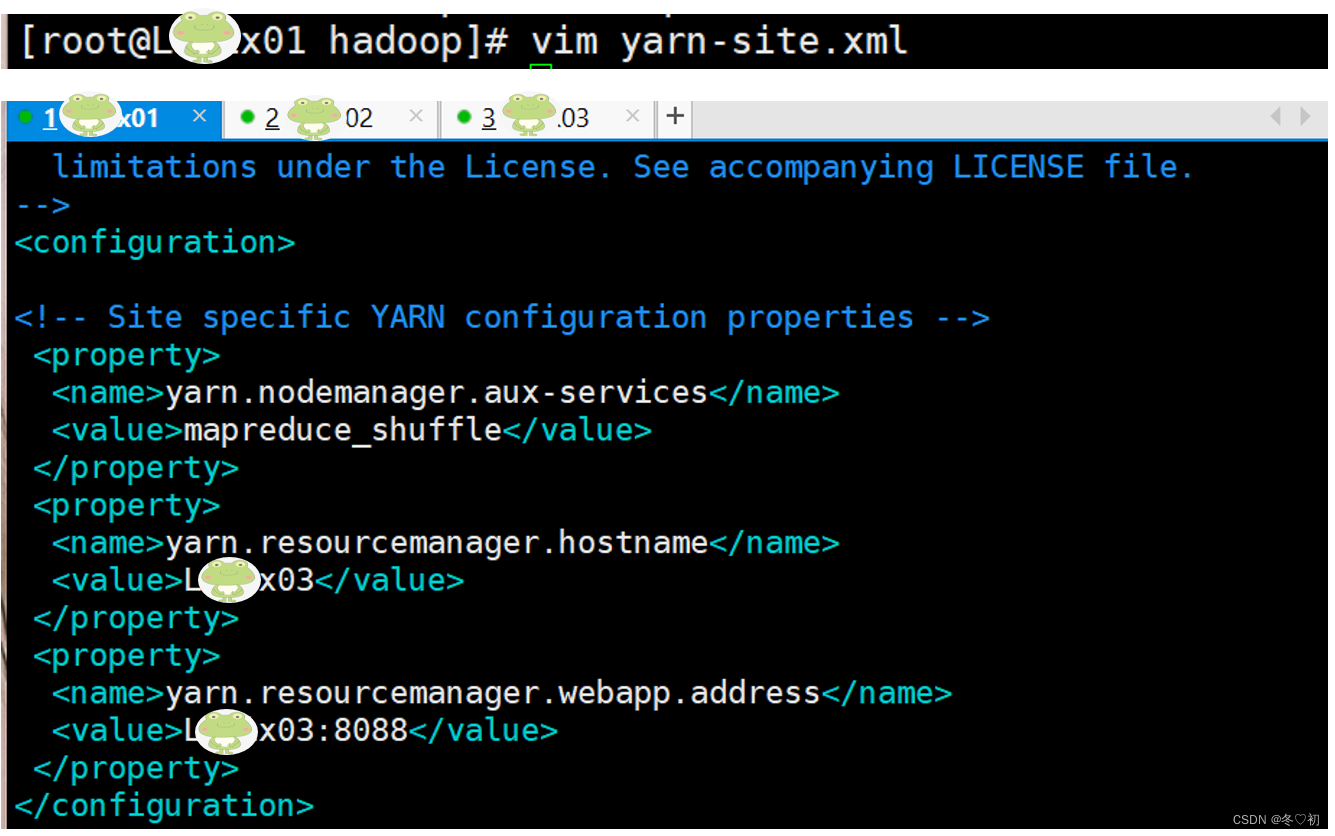
6.修改yarn-site.xml,输入命令:vim yarn-site.xml,在标签中加入子标签内容。
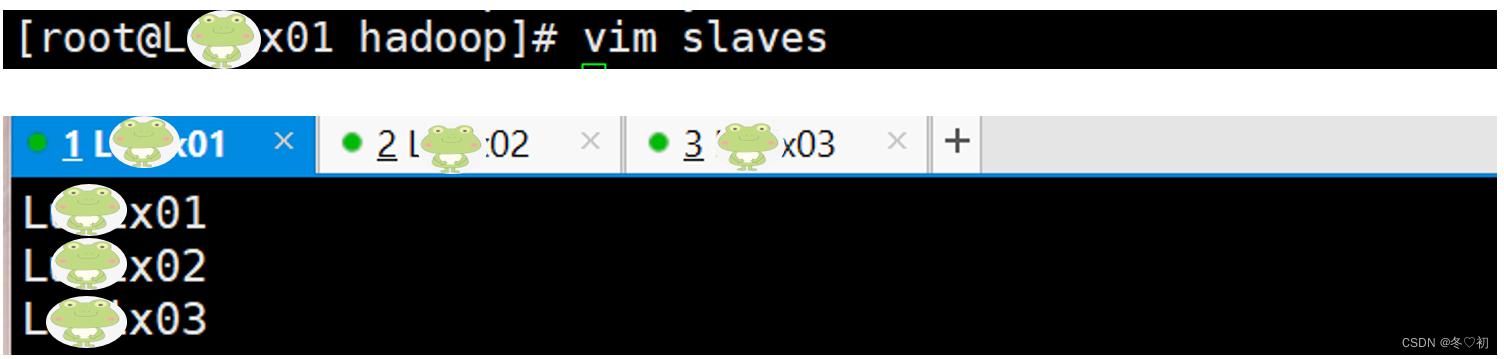
7.配置workers文件,输入命令:vim workers,删除localhost,在文件中加入CentOne,CentTwo,CentThree。
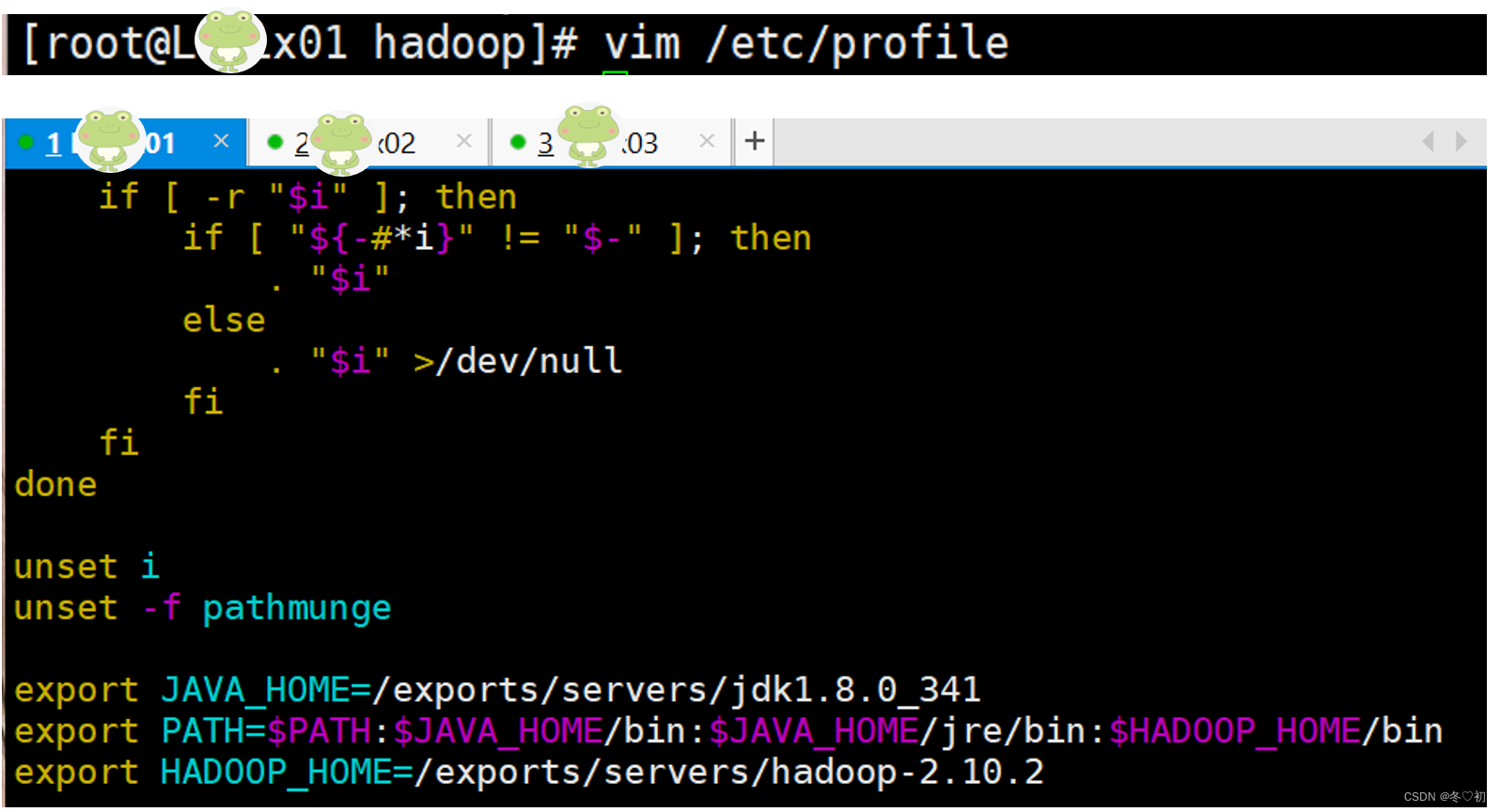
8.将hadoop根目录下的bin中命令加入系统PATH中,输入命令:vim /etc/profile,然后加入:
export HADOOP_HOME=/exports/servers/hadoop-2.10.2
export PATH=$PATH:$HADOOP_HOME/bin。
9.让配置立即生效,执行命令:source /etc/profile。

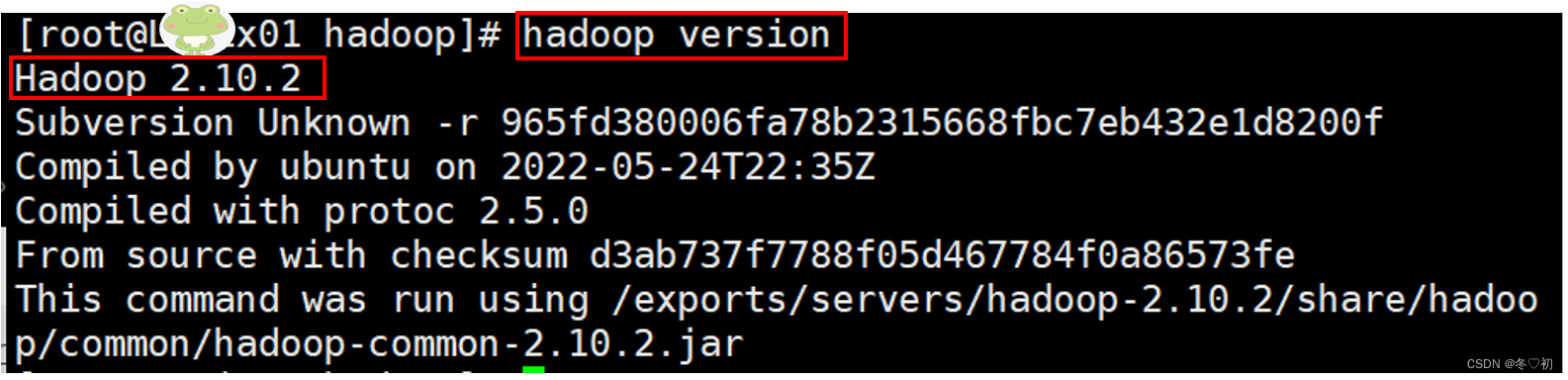
1.输入命令:hadoop version,出现如下界面,证明hadoop命令的环境变量配置成功。
2.将/exports/servers下的hadoop-2.10.2目录中的内容复制到Linux02和Linux03上。
(1)输入命令:scp -r /exports/servers/hadoop-2.10.2/ Lunix02:/exports/servers/。

(2)输入命令:scp -r /exports/servers/hadoop-2.10.2/ Linux03:/exports/servers/。

3.将Linux01上的/etc/profile文件复制到Linux02和Linux03中。输入命令:scp /etc/profile Linux03:/etc/和scp /etc/profileLinux03:/etc/。

4.在Linux02和Linux03上分别执行:source /etc/profile ,让环境变量立即生效。
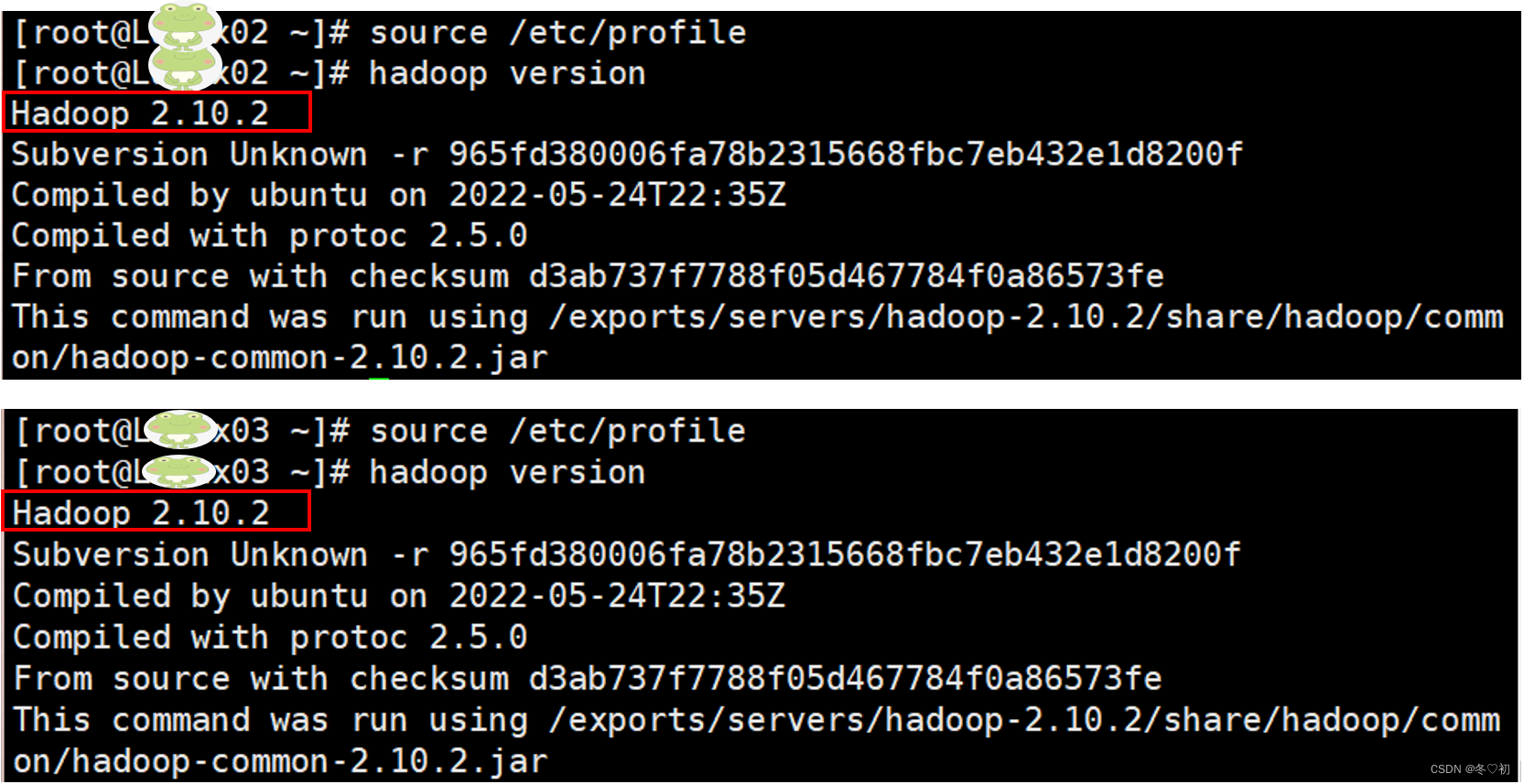
5.启动和验证hadoop集群,在Linux01上输入命令:hadoop namenode -format,出现如下图所示情况,证明hadoop集群格式化成功。如果格式化失败,可以到$HADOOP_HOME/logs目录下查看日志记录,查看具体的异常信息。

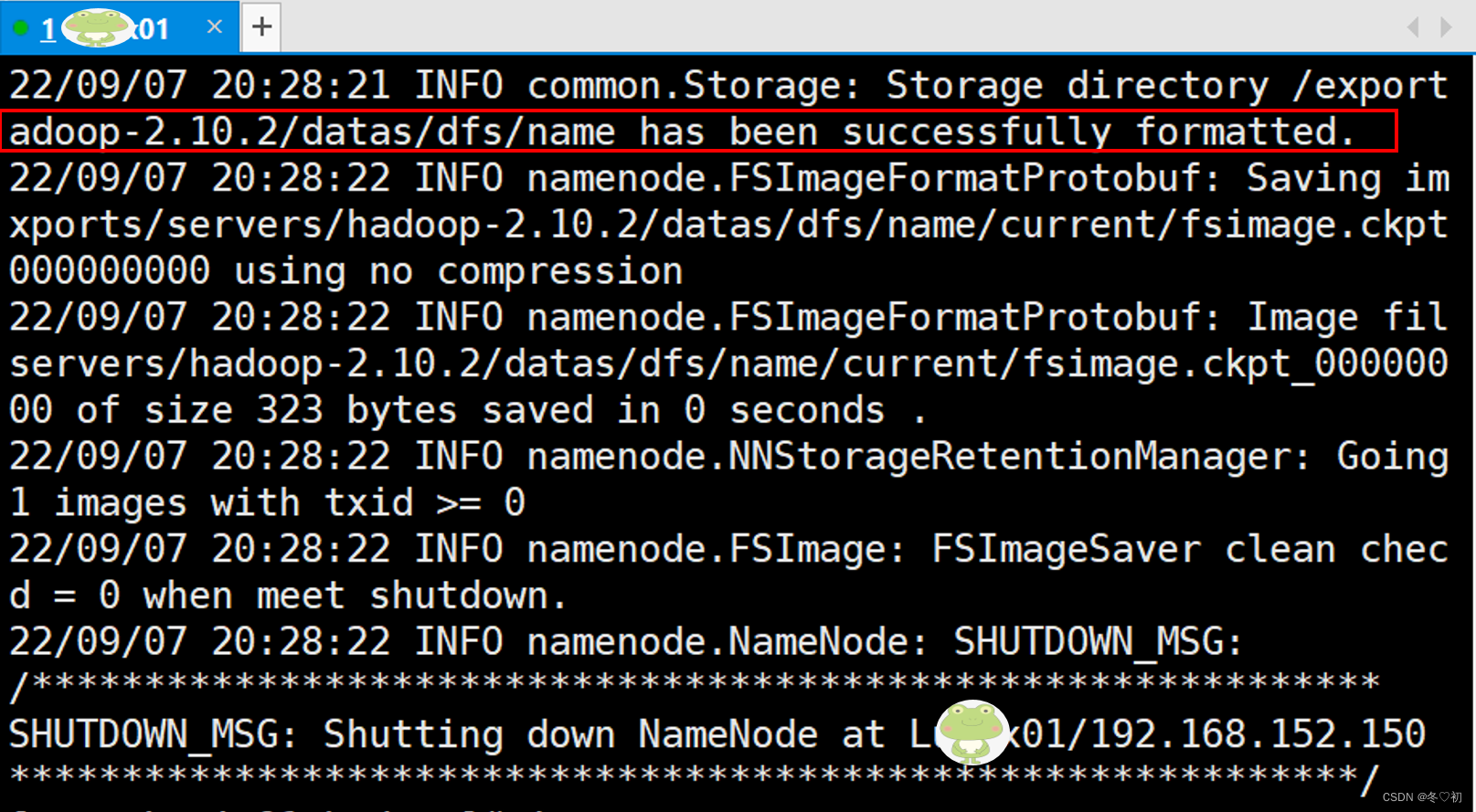
6.在Linux01上启动集群,将目录切换到hadoop的sbin目录下,输入命令:cd /exports/servers/hadoop-2.10.2/sbin/,然后再执行命令:./start-dfs.sh。
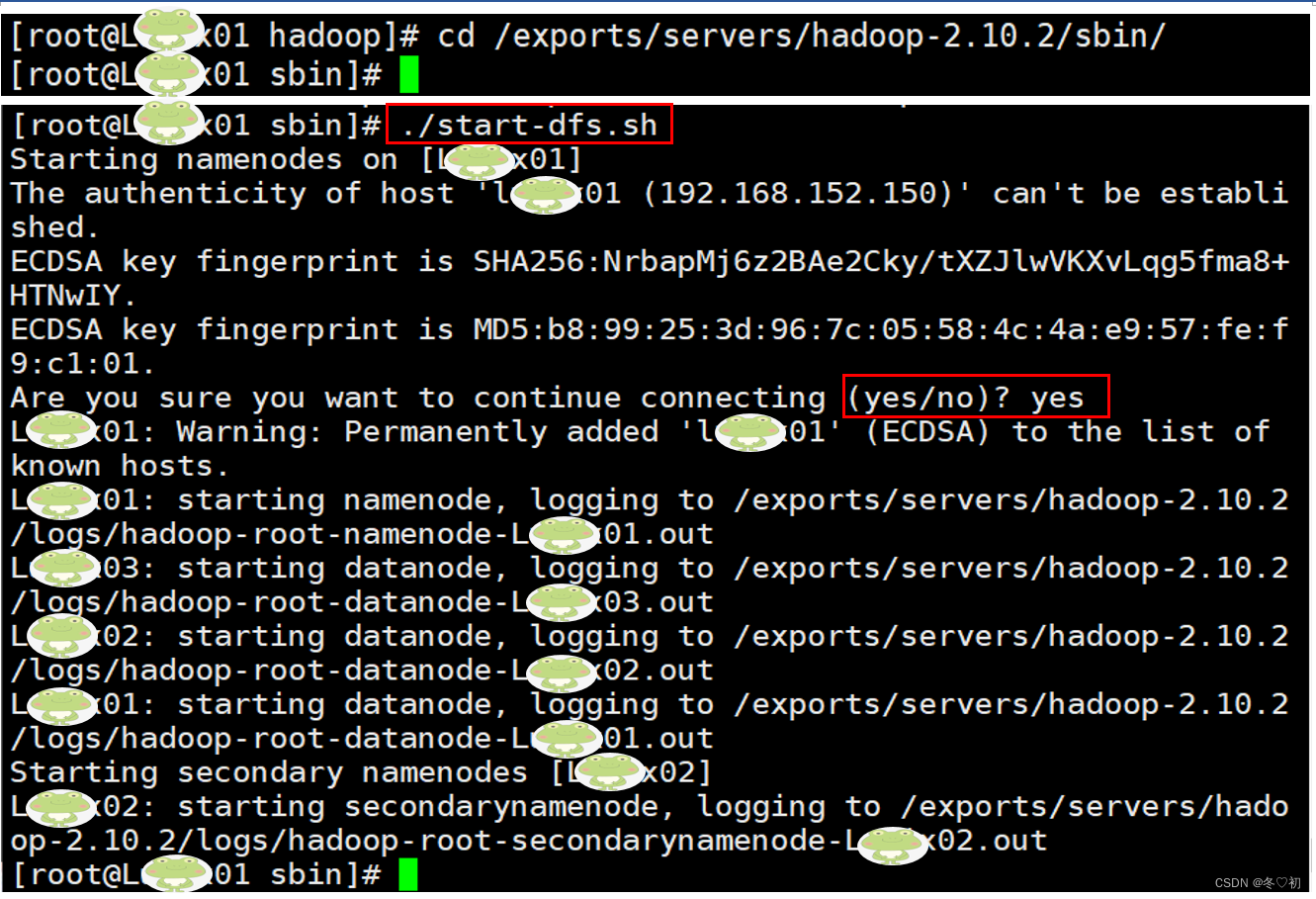
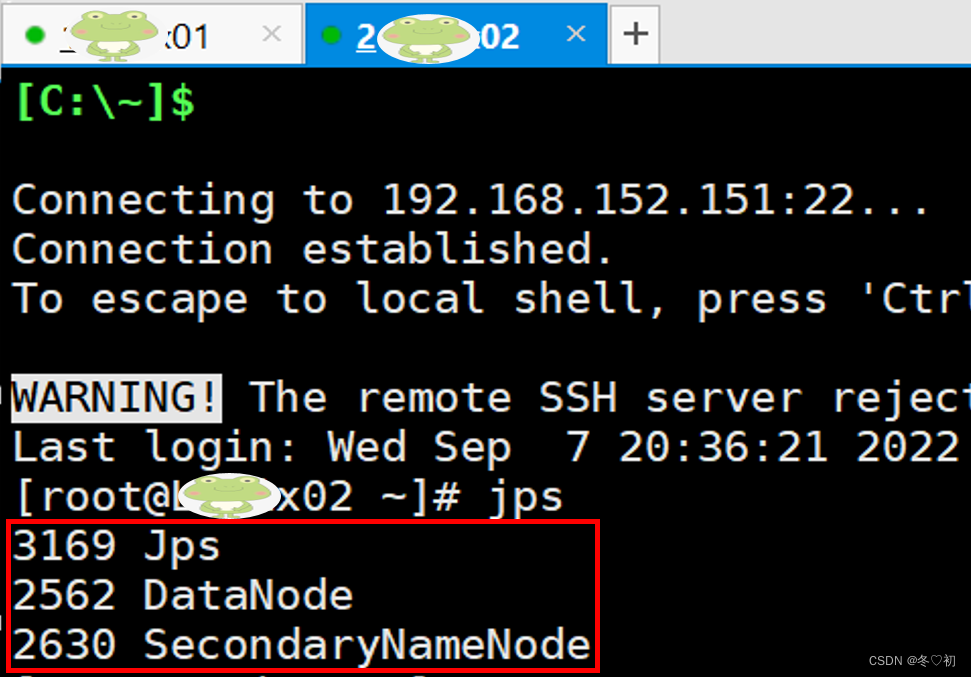
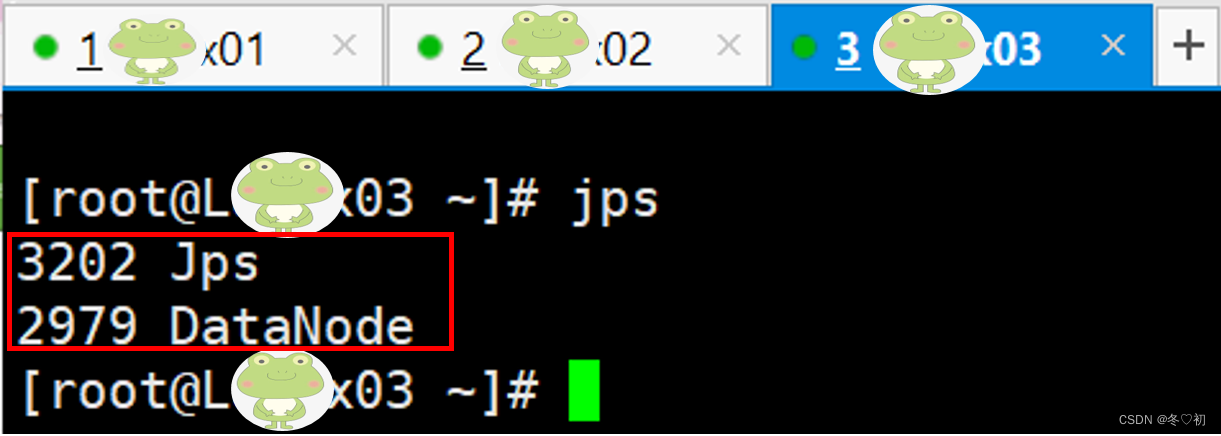
7.分别在三台机器上执行命令:jps,验证集群是否启动成功,启动成功如下图所示。
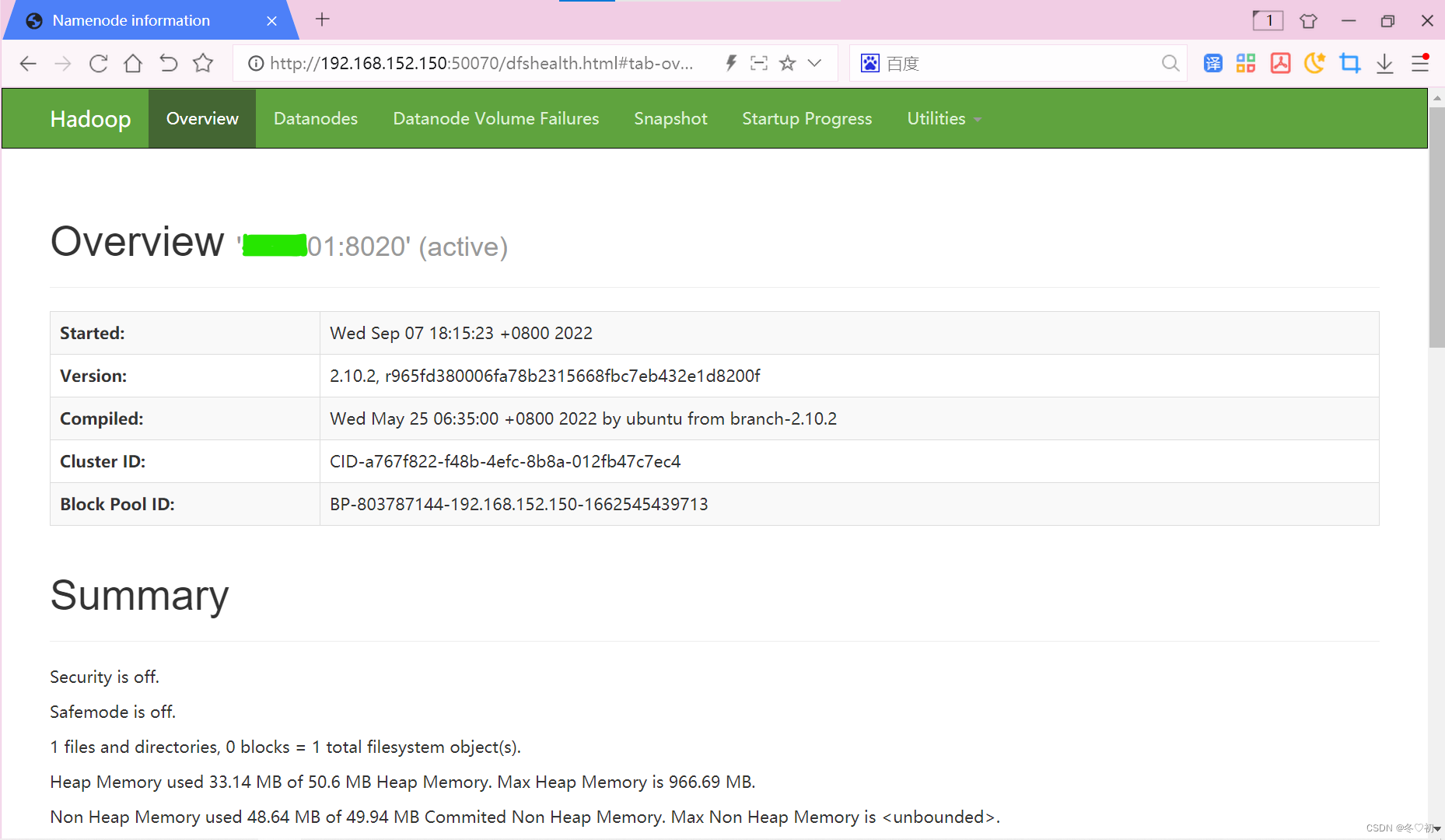
8.打开浏览器,在浏览器中输入http://192.168.152.150:50070/,出现如下图所示界面,也说明hadoop集群启动成功。
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
(二十二)-框架主入口main.py设计&log日志调用和生成1测试目的2测试需求3需求分析4详细设计4.1新建存放日志目录log4.1.1配置config.py中写入log的目录4.2`baseInfo.py`中加入日志4.3`test_gedit.py`中加入日志4.4主函数入口main.py中调用日志5调用日志主函数main.py源码6`baseInfo.py`源码7`test_gedit.py`源码8运行效果9目前框架结构1测试目的组织运行所有的测试用例,并调用日志模块,便于问题定位。
(1)为什么写这个话题(Why)读万卷书不如行千里路。这次搭建MQTT服务,遇到了一些误解,特此记录备忘。主要包括:(1)服务(Broker)的账户管理与网页管理平台的账户(2)与web应用的集成(Spring系)(2)ActiveMQ版本选择因为JAVA环境是JDK8,所以按兼容性考虑选择了ActiveMQ5.15的最后版本5.15.15。如果你是JDK11则可考虑ActiveMQ的最新版本5.17或5.18。ActiveMQ支持MQTTv3.1.1andv3.1。(3)ActiveMQ与web应用的集成主要介绍与Spring系的webapp集成(SpringBoot和SpringMVC)。
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
这篇文章,主要介绍如何使用SpringCloud微服务组件从0到1搭建一个微服务工程。目录一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件(2)微服务依赖1.2、搭建注册中心(1)引入依赖(2)配置文件(3)启动类1.3、搭建配置中心(1)引入依赖(2)配置文件(3)启动类1.4、搭建API网关(1)引入依赖(2)配置文件(3)启动类1.5、搭建服务提供者(1)引入依赖(2)配置文件(3)启动类1.6、搭建服务消费者(1)引入依赖(2)配置文件(3)启动类1.7、运行测试一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件这里主要是使用的SpringCloudNetflix
云计算实验中要求我们在Linux系统安装Hadoop,故来做一个简单的记录。· 注:我的操作系统环境是Ubuntu-20.04.3,安装的JDK版本为jdk1.8.0_301,安装的Hadoop版本为hadoop2.7.1。(不确定其他版本是否会出现版本兼容问题)Hadoop安装步骤如下: 一、更新apt和安装vim编辑器 二、配置本机无密码登录SSH 三、安装JAVA环境 四、下载安装Hadoop 五、伪分布式搭建一、更新apt和安装vim编辑器1、更新aptsudoapt-getupdate2、安装vim