SpringCloud 大型系列课程正在制作中,欢迎大家关注与提意见。
程序员每天的CV 与 板砖,也要知其所以然,本系列课程可以帮助初学者学习 SpringBooot 项目开发 与 SpringCloud 微服务系列项目开发
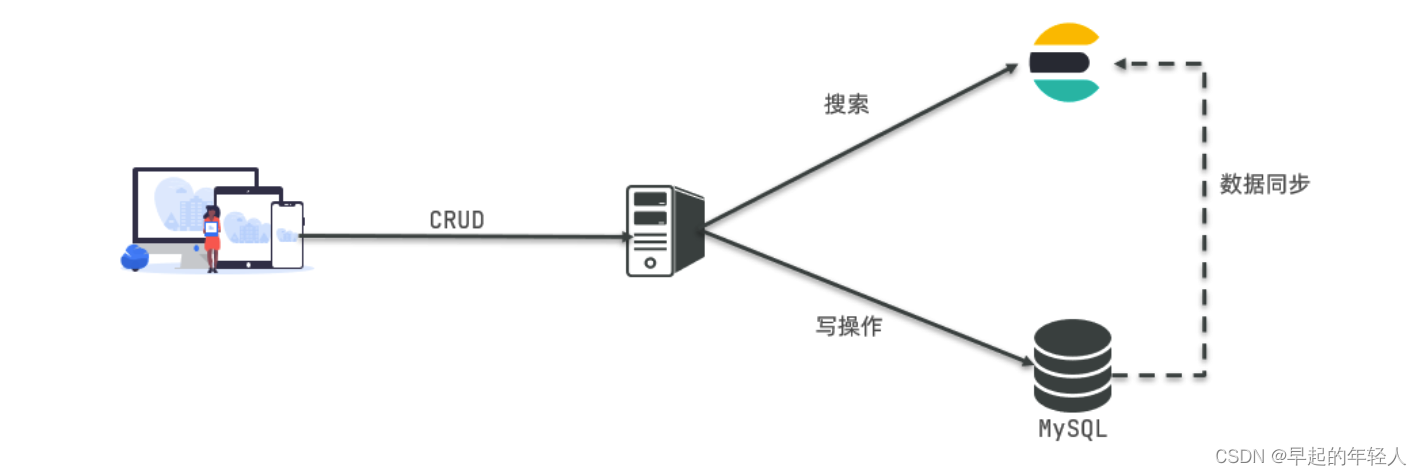
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容。
本项目数据库使用的是 MySql ,查询数据使用的是 ElasticSearch
SpringBoot RabbitMQ 延时队列取消订单【SpringBoot系列14】 本文章 基于这个项目来开发
本文章是系列文章 ,每节文章都有对应的代码,每节的源码都是在上一节的基础上配置而来,对应的视频讲解课程正在火速录制中。
首先是你的开发环境 以及服务器要安装es,我这里是使用 docker 来安装的 docker-compose安装elasticsearch及kibana
项目 pom.xm 中添加依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<!--测试使用-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
application.yml 中添加 es 的连接地址
elasticsearch:
host: 127.0.0.1
port: 9200
索引就像是数据库或者数据库中的表,我们平时是不会是通过java代码频繁的去创建修改删除数据库或者表的相关信息,我们只会针对数据做CRUD的操作。
kibana 提供了便捷的控制台开发工具
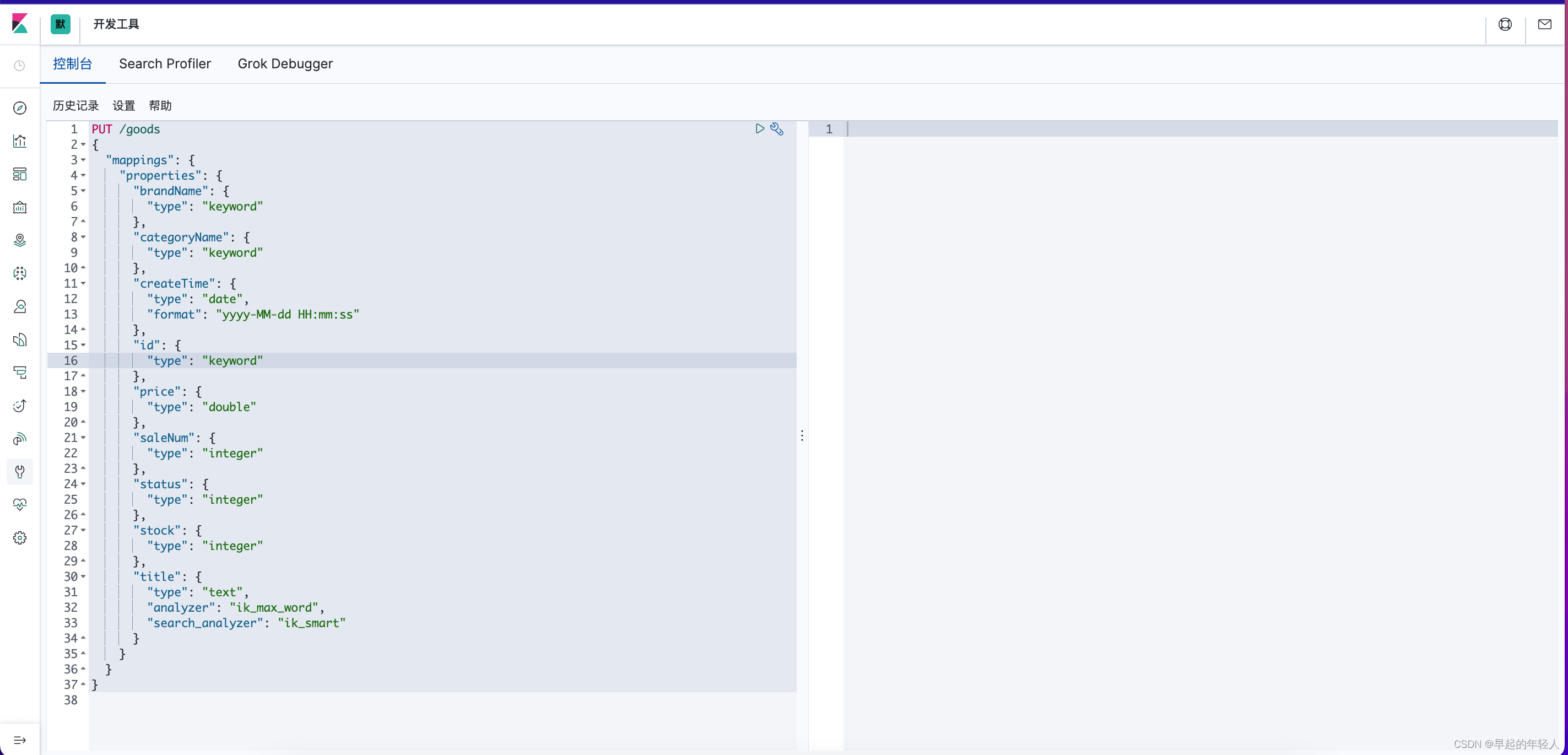
所以在使用 ElasticSearch 时,需要先使用 控制台来创建索引库,就好比你在操作数据库时,要先创建数据库与表 .
索引(Index),就是相同类型的文档的集合。
例如:


如本项目要将订单数据保存到ES中,所以这里要创建订单的索引库,创建索引库和映射的基本语法如下
PUT /order
{
"mappings": {
"properties": {
"id": {
"type": "long"
},
"userId": {
"type": "long"
},
"goodsId": {
"type": "long"
},
"deliveryAddrId": {
"type": "integer"
},
"sn": {
"type": "long"
},
"goodsName": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"goodsPrice": {
"type": "double"
},
"goodsCount": {
"type": "integer"
},
"orderChannel": {
"type": "integer"
},
"status": {
"type": "integer"
},
"payDate": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"createDate": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
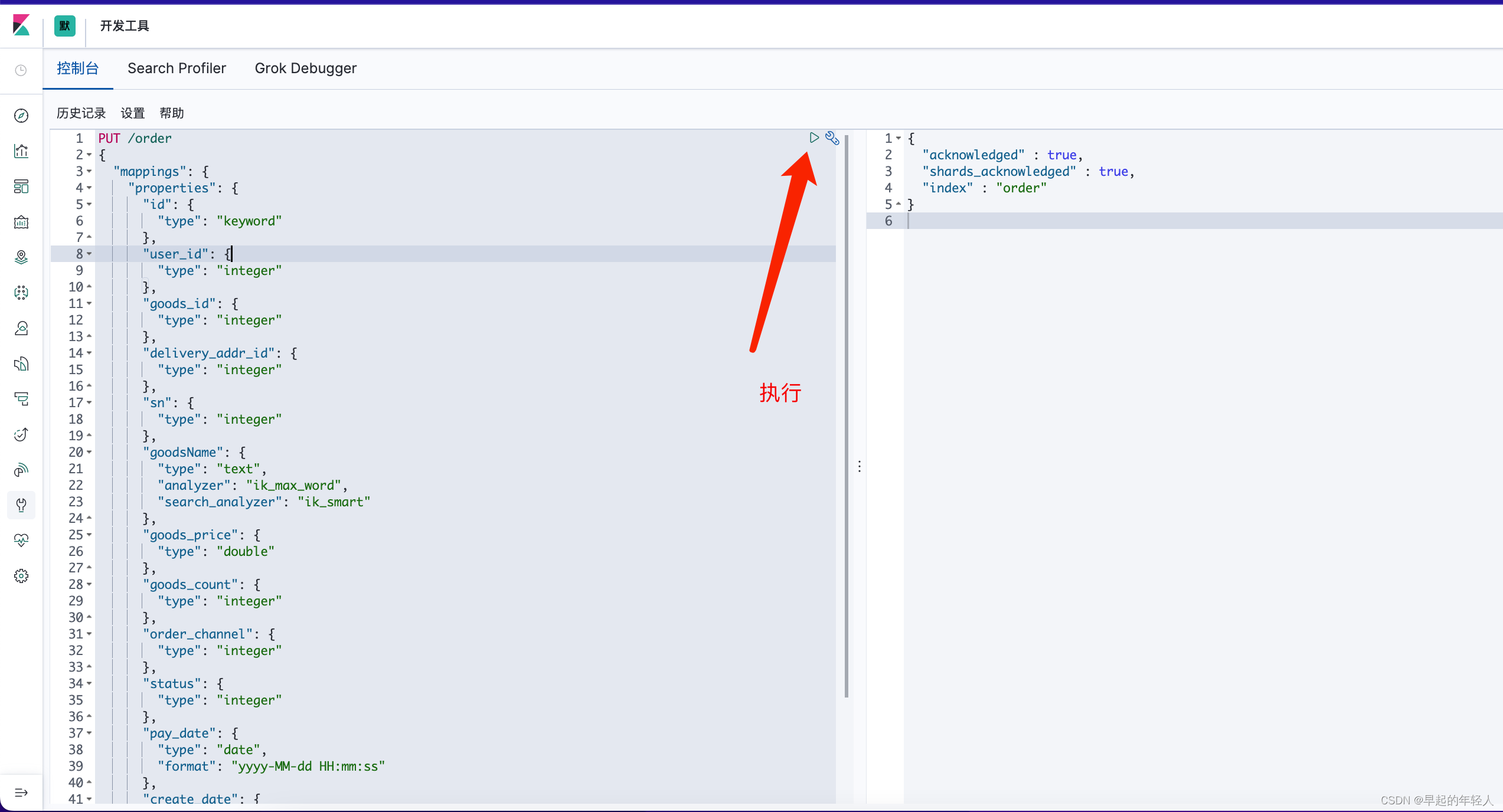
然后查询一下索引库
#查询
GET /order

删除索引库
#删除
DELETE /order

这是现在数据库中订单表的数据

import com.alibaba.fastjson.JSON;
import com.biglead.demo.pojo.Order;
import com.biglead.demo.service.OrderService;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
import java.io.IOException;
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESDocumentTests {
@Resource
RestHighLevelClient restHighLevelClient;
@Resource
OrderService orderService;
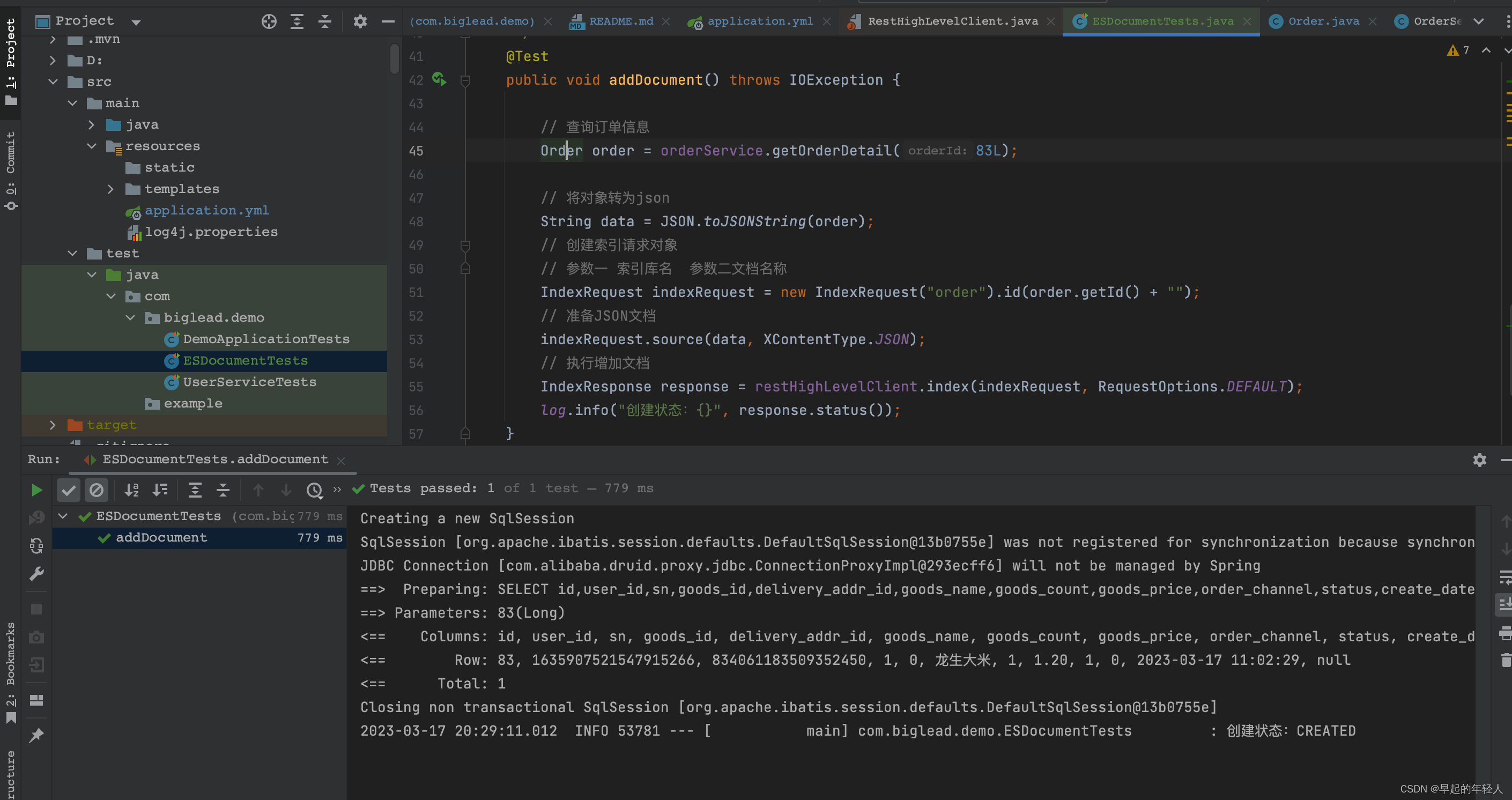
/**
* 增加文档信息
*/
@Test
public void addDocument() throws IOException {
// 查询订单信息
Order order = orderService.getOrderDetail(83L);
// 将对象转为json
String data = JSON.toJSONString(order);
// 创建索引请求对象
// 参数一 索引库名 参数二文档名称
IndexRequest indexRequest = new IndexRequest("order").id(order.getId() + "");
// 准备JSON文档
indexRequest.source(data, XContentType.JSON);
// 执行增加文档
IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
log.info("创建状态:{}", response.status());
}
}
我这里直接将 Order 实体的数据同步到了 ES中,这就要求对数据类型以及字段的完全匹配
@TableName("t_order")
@Data
public class Order implements Serializable {
private static final long serialVersionUID = 1L;
/** 订单ID **/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
/** 用户ID **/
private Long userId;
/** 商品订单号 **/
private Long sn;
/** 商品ID **/
private Long goodsId;
/** 收获地址ID **/
private Long deliveryAddrId;
/** 商品名字 **/
private String goodsName;
/** 商品数量 **/
private Integer goodsCount;
/** 商品价格 **/
private BigDecimal goodsPrice;
/** 1 pc,2 android, 3 ios **/
private Integer orderChannel;
/** 订单状态,0 新建未支付,1已支付,2已发货,3已收货,4已退货,5已完成 ,6已取消**/
private Integer status;
/** 订单创建时间 **/
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date createDate;
/** 支付时间 **/
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date payDate;
}
比如我这里的 Order 的 id 是 long 类型,如果ES 中对应的id 字段长度我定义为 integer 类型,同步时就会出错,因为长度不一样
/**
* 获取文档信息
*/
@Test
public void getDocument() throws IOException {
// 创建获取请求对象
GetRequest getRequest = new GetRequest("order", "83");
GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
}
/**
* 更新文档信息
*/
@Test
public void updateDocument() throws IOException {
// 设置商品更新信息
Order goods = new Order();
goods.setGoodsName("Apple iPhone 苹果手机");
goods.setGoodsPrice(new BigDecimal("345"));
// 将对象转为json
String data = JSON.toJSONString(goods);
// 创建索引请求对象
UpdateRequest updateRequest = new UpdateRequest("order", "83");
// 设置更新文档内容
updateRequest.doc(data, XContentType.JSON);
// 执行更新文档
UpdateResponse response = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("创建状态:{}", response.status());
}
/**
* 删除文档信息
*/
@Test
public void deleteDocument() throws IOException {
// 创建删除请求对象
DeleteRequest deleteRequest = new DeleteRequest("order", "1");
// 执行删除文档
DeleteResponse response = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info("删除状态:{}", response.status());
}
@Test
public void testBulkRequest() throws IOException {
// 批量查询订单数据
List<Order> orderList = orderService.alllist();
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备参数,添加多个新增的Request
for (Order order : orderList) {
// 创建新增文档的Request对象
request.add(new IndexRequest("order")
.id(order.getId().toString())
.source(JSON.toJSONString(order), XContentType.JSON));
}
// 3.发送请求
BulkResponse bulk = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
log.info("执行状态:{}", bulk.status());
}
项目源码在这里 :https://gitee.com/android.long/spring-boot-study/tree/master/biglead-api-12-es
有兴趣可以关注一下公众号:biglead
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我使用irb。下面是我写的代码。“斧头”..“bc”我期待"ax""ay""az""ba"bb""bc"但结果只是“斧头”..“bc”我该如何纠正?谢谢。 最佳答案 >puts("ax".."bc").to_aaxayazbabbbc 关于ruby-从结束值创建一系列字符串,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7617092/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
使用RubyonRails,我使用给定的增量(例如每30分钟)用时间填充“选择”。目前我正在YAML文件中写出所有的可能性,但我觉得有一种更巧妙的方法。我想我想提供一个开始时间、一个结束时间、一个增量,并且目前只提供一个名为“关闭”的选项(想想“business_hours”)。所以,我的选择可能会显示:'Closed'5:00am5:30am6:00am...[allthewayto]...11:30pm谁能想出更好的方法,或者只是将它们全部“拼写”出来的最佳方法? 最佳答案 此答案基于@emh的答案。defcreate_hour
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
如果您希望在Spring中启用定时任务功能,则需要在主类上添加 @EnableScheduling 注解。这样Spring才会扫描 @Scheduled 注解并执行定时任务。在大多数情况下,只需要在主类上添加 @EnableScheduling 注解即可,不需要在Service层或其他类中再次添加。以下是一个示例,演示如何在SpringBoot中启用定时任务功能:@SpringBootApplication@EnableSchedulingpublicclassApplication{publicstaticvoidmain(String[]args){SpringApplication.ru