加深学生对归结原理进行定理证明过程的理解,掌握基于谓词逻辑的归
结过程中子句变换过程、替换与合一算法即归结策略等重要环节,进一步了解实
现机器自动定理证明的步骤。
对于任意一阶谓词逻辑描述的定理,给出基于归结原理的证明过程。如输入:
A1 : (∀x)(P(x)→(Q(x) ∧R(x)))
A2 : (∀x)(P(x)∧S(x))
G : (∃x)(S(x)∧R(x))
要证明:G 是 A1 和 A2 的逻辑结果
归结原理是一种推理规则。从谓词公式转化为字句集的过程中看出,在子句
集中字句之间是合取关系,其中只要有一个字句不可满足,则字句集就不可满足。
若一个字句集中包含空字句,则这个字句集一定是不可满足的。归结原理就是基
于这一认识提出来的。
应用归结原理进行定理证明的过程:
设要被证明的定义表示为:
A1∧A2∧…∧An→B
(1)首先否定结论 B,并将否定后的公式¬B 与前提公式集组成如下形式的谓
词公式:G= A1∧A2∧…∧An∧¬B。
(2)求谓词公式 G 的字句集 S。
(3)应用归结原理,证明子句集 S 的不可满足性。
Visual Studio Code
步骤一 设计谓词公式的存储结构,即内部表示,注意对全称量词x 和存在
量词x 可采用其他符号代替。
原符号 替换符号
全称量词∀ @
存在量词∃ #
析取符号∨ |
合取符号∧ &
取反符号¬ ~
蕴含符号→ >
例 如 A1 : (∀x)(P(x)→(Q(x) ∧R(x))) , 输 入 的 时 候 要 替 换 为 A1 :
(@x)(P(x)>(Q(x)&R(x)))。
核心代码如下所示:
namespace FormulaNamepace {
// 公式符号定义
const char EQ = '#'; // 存在量词符号
const char UQ = '@';// 全称量词符号
const char IMPLICATION = '>'; // 蕴含符号
const char NEGATION = '~'; // 否定符号
const char CONJUNCTION = '&';// 合取符号
const char DISJUNCTION = '|'; // 析取符号
const char CONSTANT_ALPHA[] = { 'a', 'b', 'c', 'd', 'e',
'i', 'j', 'k'};
}
#endif // SUBSENTENCE_H
步骤二 变换子句集,可按以下过程变换,变换过程的核心代码如下所示:
1、消去蕴含连接词。
Formula& RemoveImplication(Formula& f)
{
FormulaIter iter;
while((iter = find(f.begin(), f.end(), IMPLICATION))
!= f.end()) {
*iter = DISJUNCTION; // 将蕴含符号替换为析取符号
FormulaRevIter revIter(iter);
revIter =
GetBeginOfFormula(revIter, f.rend()); // 查找蕴含前件
iter = revIter.base()-1;// 反向迭代器到正向迭代器转换需要减 1
f.insert(iter, NEGATION);// 在前件前面插入否定
}
return f;
}
2、将否定符号移到紧靠谓词的位置。
Formula& MoveNegation(Formula& f)
{
FormulaIter iter = find(f.begin(), f.end(), NEGATION);
while(iter != f.end()) {
if(*(iter+1) == '(') {// 否定不是直接修饰谓词公式,需要内移
// 否定符号修饰着带量词的谓词公式
if(*(iter+2) == EQ || *(iter+2) == UQ) {
// 量词取反
*(iter+2) == EQ ? *(iter+2) = UQ : *(iter+2) = EQ;
string leftDonePart(f.begin(), iter+5);
// 移除否定符号
leftDonePart.erase(find(leftDonePart.begin(),
leftDonePart.end(), NEGATION));
string rightPart(iter + 5, f.end());
// 否定内移
rightPart.insert(rightPart.begin(), NEGATION);
// 递归处理右部分
MoveNegation(rightPart);
string(leftDonePart + rightPart).swap(f);
return f;
}else { // 修饰着多个公式,形如~(P(x)|Q(x))
iter = f.insert(iter+2, NEGATION); // 内移否定符号
while(1) {
iter = FindFormula(iter, f.end());
assert(iter != f.end() && "No Predicate Formula!");
FormulaIter iter2 = FindPairChar(
iter, f.end(), '(', ')');
++iter2;
if(IsConnector(*iter2)) {
*iter2 == DISJUNCTION ? *iter2 = CONJUNCTION
: *iter2 = DISJUNCTION;
iter = f.insert(iter2+1, NEGATION);
}else
break;
}
f.erase(find(f.begin(), f.end(),
NEGATION));// 清除原否定符号
return MoveNegation(f);
}
}else if(*(iter+1) == NEGATION) {// 两个否定,直接相消
f.erase(iter, iter + 2);
return MoveNegation(f); // 重新处理
}else {
iter = find(iter + 1, f.end(), NEGATION);
} }
return f;
}
3、适当改名使量词间不含同名指导变元,对变元标准化。
Formula& StandardizeValues(Formula& f)
{
set<char> checkedAlpha;
FormulaIter iter = FindQuantifier(f.begin(), f.end());
while(iter != f.end()) {
char varName = *++iter;// 获取变量名
if(checkedAlpha.find(varName) == checkedAlpha.end()) {
checkedAlpha.insert(varName);
}else { // 变量名冲突了,需要改名
// 获取新名字
char newName = FindNewLowerAlpha(checkedAlpha);
// 查找替换右边界
FormulaIter rightBorder = FindPairChar(
iter + 2, f.end(), '(', ')');
// 将冲突变量名替换为新的名字
*iter = newName;
replace(iter, rightBorder, varName, newName);
iter = rightBorder; // 移动到新的开始
}
iter = FindQuantifier(iter, f.end());
}
return f;
}
4、化为前束范式。
Formula& TransformToPNF(Formula& f)
{
FormulaIter iter = FindQuantifier(f.begin(), f.end());
if(iter == f.end())
return f;
else if(iter-1 == f.begin()) { // 量词已经在最前面
iter += 3;
string leftPart(f.begin(), iter);
string rightPart(iter, f.end());
TransformToPNF(rightPart); // 递归处理右部分
(leftPart + rightPart).swap(f);
}else { // 量词在内部,需要提到前面
string quantf(iter-1, iter+3); // 保存量词
f.erase(iter-1, iter+3); // 移除量词
f.insert(f.begin(), quantf.begin(), quantf.end());
return TransformToPNF(f); // 继续处理
}
return f;
}
5、消去存在量词。
Formula& RemoveEQ(Formula& f)
{
set<char> checkedAlpha;
FormulaIter eqIter = find(f.begin(), f.end(), EQ);
if(eqIter == f.end()) return f;
FormulaRevIter uqIter = find(FormulaRevIter(eqIter), f.rend(), UQ);
if(uqIter == f.rend()) { // 该存在量词前没有任意量词
char varName = *(eqIter + 1);
char newName = GetNewConstantAlha(f);
auto rightBound = FindPairChar(eqIter + 3, f.end(), '(', ')');
assert(rightBound != f.end());
replace(eqIter + 3, rightBound, varName, newName); // 常量化
f.erase(eqIter - 1, eqIter + 3); // 移除存在量词
}else {
// 记录公式中已经存在的字母
copy_if(f.begin(), f.end(),
inserter(checkedAlpha, checkedAlpha.begin()),
ptr_fun<int, int>(isalpha));
const char oldName = *(eqIter+1);
// 准备任意量词的函数来替换该存在量词
const char funcName = FindNewLowerAlpha(checkedAlpha);
string funcFormula;
funcFormula = funcFormula + funcName
+ '(' + *(uqIter-1) + ')';
f.erase(eqIter - 1, eqIter + 3); // 移除存在量词
ReplaceAlphaWithString(f, oldName, funcFormula);
}
RemoveOuterBracket(f);
return RemoveEQ(f); // 递归处理
}
6、消去全称量词。
Formula& RemoveUQ(Formula& f)
{
FormulaIter uqIter = find(f.begin(), f.end(), UQ);
while(uqIter != f.end()) {
uqIter = f.erase(uqIter-1, uqIter+3); // 直接移除全称量词
uqIter = find(uqIter, f.end(), UQ); // 继续扫描
}
RemoveOuterBracket(f);
return f;
}
7、化为 Skolem 标准型。
Formula& TransformToSkolem(Formula& f)
{
RemoveEQ(f);
RemoveUQ(f);
return f;
}
8、消去合取词,以子句为元素组成一个集合 S。
void ExtractSubsentence(SubsentenceSet& subset,
const Formula& f)
{
auto leftIter = f.begin(),
middleIter = find(f.begin(), f.end(), CONJUNCTION);
while(middleIter != f.end()) {
subset.insert(string(leftIter, middleIter));
leftIter = middleIter + 1;
middleIter = find(middleIter + 1, f.end(), CONJUNCTION);
}
subset.insert(string(leftIter, middleIter));
}
需要考虑子句、子句集的存储结构的设计。
步骤三 选择并设计归结策略,常用的归结策略有:
删除策略、支持集策略、线性归结策略、输入归结策略、单元归结策略、锁
归结策略、祖先过滤型策略等。
步骤四实现归结算法,并在其中实现合一算法,使用归结原理进行定理证
明,要求采用归结反演过程,即:
1、先求出要证明的命题公式的否定式的子句集 S; 2、然后对子句集 S(一次或者多次)使用归结原理;
3、若在某一步推出了空子句,即推出了矛盾,则说明子句集 S 是不可满足
的,从而原否定式也是不可满足的,进而说明原公式是永真的。
合一算法及核心代码如下:
1、置 k=0,Sk=S, σk =ε;
2、若 Sk 只含有一个谓词公式,则算法停止, σk 就是最一般合一;
3、求 Sk 的差异集 Dk; 4、若中存在元素 xk 和 tk ,其中 xk 是变元, tk 是项且 xk 不在 tk 中出现,
则置 Sk +1=Sk{tk/ xk} σk =ε然后转 Step2; 5、算法停止,S 的最一般合一不存在。
Sustitutes MGU(const FormulaNamepace::Subsentence& subsent1,
const FormulaNamepace::Subsentence& subsent2)
{
pair<Subsentence, Subsentence> w = { subsent1, subsent2 };
Sustitutes mgu;
while(w.first != w.second) { // w 未合一
// 找不一致集
auto iter1 = FindPredicate(w.first.begin(), w.first.end());
auto iter2 = FindPredicate(w.second.begin(), w.second.end());
while(iter1 != w.first.end() && iter2 != w.second.end()) {
if(*iter1 != *iter2)
break;
iter1 = FindPredicate(iter1 + 1, w.first.end());
iter2 = FindPredicate(iter2 + 1, w.second.end());
}
// 找到不一致集合
if(iter1 != w.first.end() && iter2 != w.second.end()) {
string item1 = GetPredicate(iter1, w.first.end());
string item2 = GetPredicate(iter2, w.second.end());
// 不允许置换有嵌套关系
if(StrStr(item1, item2) != item1.end() ||
StrStr(item2, item1) != item2.end()) {
throw ResolutionException("cannot unifier");
}
// 只允许常量替换变量
if(!IsConstantAlpha(*iter1))
item1.swap(item2);
// 更新置换,然后置换子句集
Sustitutes sustiSet = { make_pair(item1, item2) };
mgu = ComposeSustitutes(mgu, sustiSet);
Substitution(w.first, mgu);
Substitution(w.second, mgu);
}
else { // 两子句不可合一
throw ResolutionException("cannot unifier");
} }
return mgu;
}
步骤五 编写代码,调试程序
实验结果图
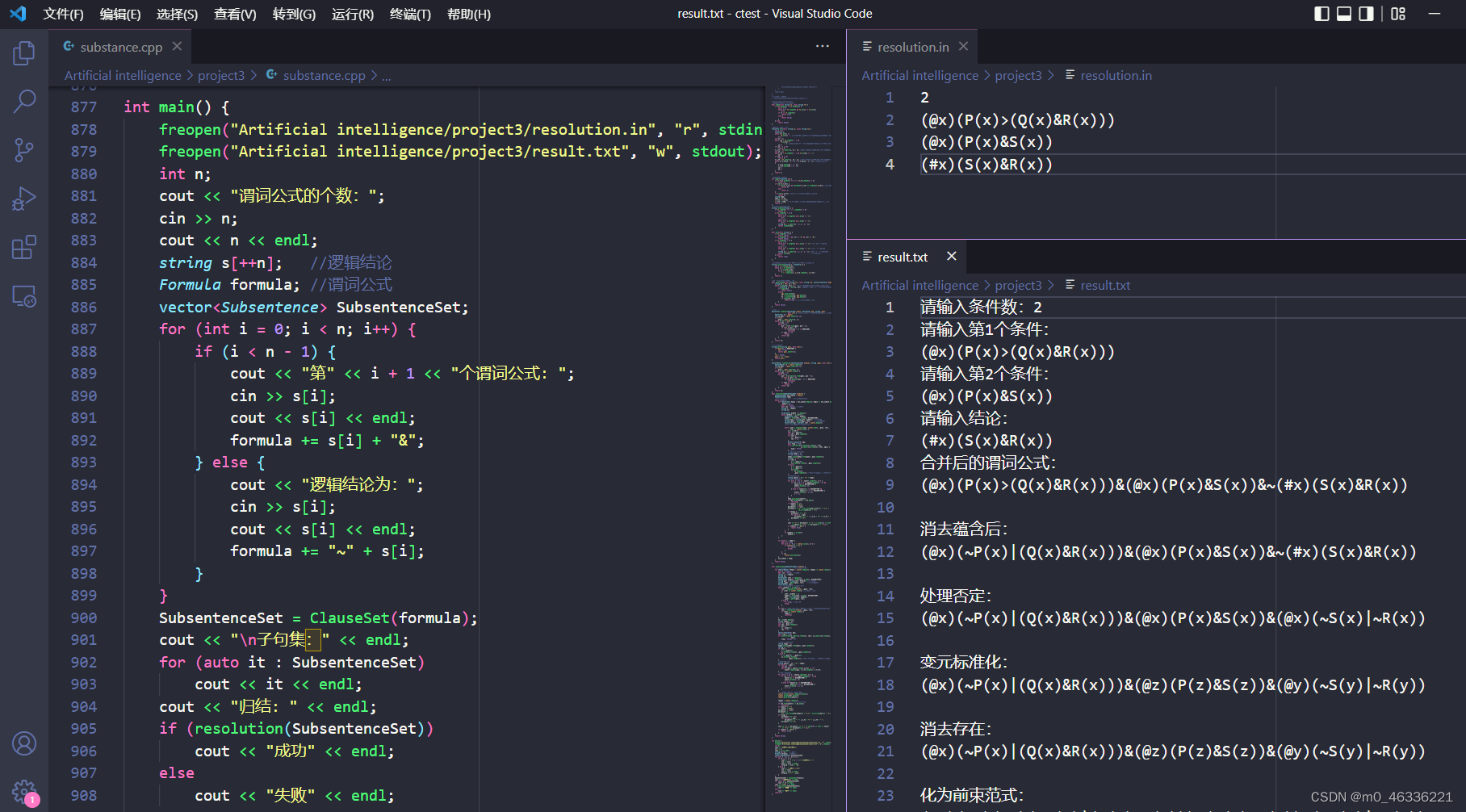
实验结果:
输入:
2
(@x)(P(x)>(Q(x)&R(x)))
(@x)(P(x)&S(x))
(#x)(S(x)&R(x))
输出:
谓词公式的个数:2
第1个谓词公式: (@x)(P(x)>(Q(x)&R(x)))
第2个谓词公式: (@x)(P(x)&S(x))
逻辑结论为:(#x)(S(x)&R(x))
合并后的谓词公式:
(@x)(P(x)>(Q(x)&R(x)))&(@x)(P(x)&S(x))&~(#x)(S(x)&R(x))
消去蕴含:
(@x)(~P(x)|(Q(x)&R(x)))&(@x)(P(x)&S(x))&~(#x)(S(x)&R(x))
处理否定:
(@x)(~P(x)|(Q(x)&R(x)))&(@x)(P(x)&S(x))&(@x)(~S(x)|~R(x))
变元标准化:
(@x)(~P(x)|(Q(x)&R(x)))&(@l)(P(l)&S(l))&(@r)(~S(r)|~R(r))
消去存在:
(@x)(~P(x)|(Q(x)&R(x)))&(@l)(P(l)&S(l))&(@r)(~S(r)|~R(r))
化为前束范式:
(@x)(@l)(@r)(~P(x)|(Q(x)&R(x)))&(P(l)&S(l))&(~S(r)|~R(r))
化为 Skolem 标准型:
(~P(x)|(Q(x)&R(x)))&(P(l)&S(l))&(~S(r)|~R(r))
化为合取范式:
(~P(x)|Q(x))&(~P(x)|R(x))&P(l)&S(l)&(~S(r)|~R(r))
子句集:
(1) ~P(x)|Q(x)
(2) ~P(x)|R(x)
(3) P(l)
(4) S(l)
(5) ~S(r)|~R(r)
归结:
归结策略1:
(6) ~R(r) [ (4),(5) { r/l } ]
(7) ~P(r) [ (2),(6) { r/x } ]
(8) Nil [ (3),(7) { r/l } ]
成功
归结策略2:
(6) Q(x) [ (3),(1) { x/l } ]
(7) R(x) [ (3),(2) { x/l } ]
(8) ~S(r)|~P(x) [ (5),(2) { x/r } ]
(9) ~R(r) [ (5),(4) { l/r } ]
(10) ~P(x)|~S(r) [ (2),(5) { r/x } ]
(11) ~S(r) [ (5),(7) { x/r } ]
(12) Nil [ (9),(7) { x/r } ]
成功
实验分析:归结采用水平归结,从尾部开始进行,即从结论出发开始遍历寻找相应结论的逆命题直至close表归结为Nill(空),此时结论证明成功。采用的是支持集策略。
利用归结反演方法来证明定理的具体步骤为:
步1否定目标公式G,得到¬G;
步2将¬G并入到公式集F1^F2^...^Fn中;
步3将公式集化子句集,得到子句集S;
步4对S进行归结,每次归结的结果并入到S中。如此反复,直到得到空子句为止。此时,就证明了在前提F1^F2^...^Fn为真时,结论G为真。
支持集策略
(1)每次归结时,两个亲本子句中至少要有一个是目标公式否定的子句或其后裔。
(2)目标公式否定的子句及其后裔即为支持集。
特点
(1)尽量避免在可满足的子句集中做归结,因为从中导不出空子句。而求证公式的前提通常是一致的,所以支持集策略要求归结时从目标公式否定的子句出发进行归结。支持集策略实际是一种目标制导的反向推理。
(2)支持集策略是完备的。
实验指导书
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
前面一篇关于智能合约翻译文讲到了,是一种计算机程序,既然是程序,那就可以使用程序语言去编写智能合约了。而若想玩区块链上的项目,大部分区块链项目都是开源的,能看得懂智能合约代码,或找出其中的漏洞,那么,学习Solidity这门高级的智能合约语言是有必要的,当然,这都得在公链``````以太坊上,毕竟国内的联盟链有些是不兼容Solidity。Solidity是一种面向对象的高级语言,用于实现智能合约。智能合约是管理以太坊状态下的账户行为的程序。Solidity是运行在以太坊(Ethereum)虚拟机(EVM)上,其语法受到了c++、python、javascript影响。Solidity是静态类型
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
一、RIPV2协议简介 RIP(RoutingInformationProtocol)路由协议是一种相对古老,在小型以及同介质网络中得到了广泛应用的一种路由协议。RIP采用距离向量算法,是一种距离向量协议。RIP-1是有类别路由协议(ClassfulRoutingProtocol),它只支持以广播方式发布协议报文。RIP-1的协议报文无法携带掩码信息,它只能识别A、B、C类这样的自然网段的路由,因此RIP-1不支持非连续子网(DiscontiguousSubnet)。RIP-2是一种无类别路由协议(ClasslessRoutingProtocol),支持路由标记,在路由策略中可根据路由标记对
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
我正在寻找一个用ruby或rails完成的报告生成器,它允许用户首先定义一个模板,然后将数据提取到模板中。我一直在浏览“TheRubyBox:报告部分”(https://www.ruby-toolbox.com/categories/reporting.html)有两个报告工具类似于我正在寻找的:ThinReports:这真的很好。您下载一个模板编辑器,然后定义您自己的报告模板,然后通过组合thinreportsgem,您可以从您的应用程序中获取SVG或PDF报告。ODFReport:它使用ODF文件作为模板,可以通过OpenOffice和MSWord2010进行编辑。然后你就可以
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动
目录1.1访问Cisco路由器的方法1.1.1通过Console口访问路由器1.1.2通过Telnet访问路由器1.1.3终端访问服务器1.2终端访问服务器配置命令汇总1.1访问Cisco路由器的方法 路由器没有键盘和鼠标,要初始化路由器需要把计算机的串口和路由器的Console口进行连接。访问Cisco路由器的方法还有Telnet、WebBrowser和网络管理软件(如CiscoWorks)等,本节讨论前2种。1.1.1通过Console口访问路由器 计算机的串口和路由器的Console口是通过反转线(Rollover)进行连接的,反转线的一端接在路由器的Console口上,另一
日前,全球著名咨询机构IDC最新MarketScape报告《中国DevOps平台市场厂商评估,2022》正式发布,此报告中对中国主流DevOps云厂商分别从现有能力和未来战略维度两个层面对厂商进行评估,IDC对具有代表性的8家提供商进行了深度研究,他们分别是(按照拼音字母顺序):AWS、阿里云、百度、博云、华为云、京东云、微软、腾讯云(CODING)。华为云、阿里云和腾讯云CODING均在战略和能力两大维度表现强势,成功入席领导者(Leaders)位置。IDC MarketScape:中国DevOps平台市场厂商评估,2022华为云软件开发生产线DevCloud在市场份额和发展战略两大维度均排
前言 Slowloris攻击是我在李华峰老师的书——《MetasploitWeb 渗透测试实战》里面看的,感觉既简单又使用,现在这种攻击是很容易被防护的啦。不过我也不敢真刀实战的去试,只是拿个靶机玩玩罢了。 废话还是写在结语里面吧。(划掉)结语可以不看(划掉)Slowloris攻击的原理 Slowloris是一种资源消耗类DoS攻击,它利用部分HTTP请求进行操作。也叫做慢速攻击,这里的慢速并不是说发动攻击慢,而是访问一条链接的速度慢。Slowloris攻击的功能是打开与目标Web服务器的连接,然后尽可能长时间的保持这些连接打开。如果由多台电脑同时发起Slo