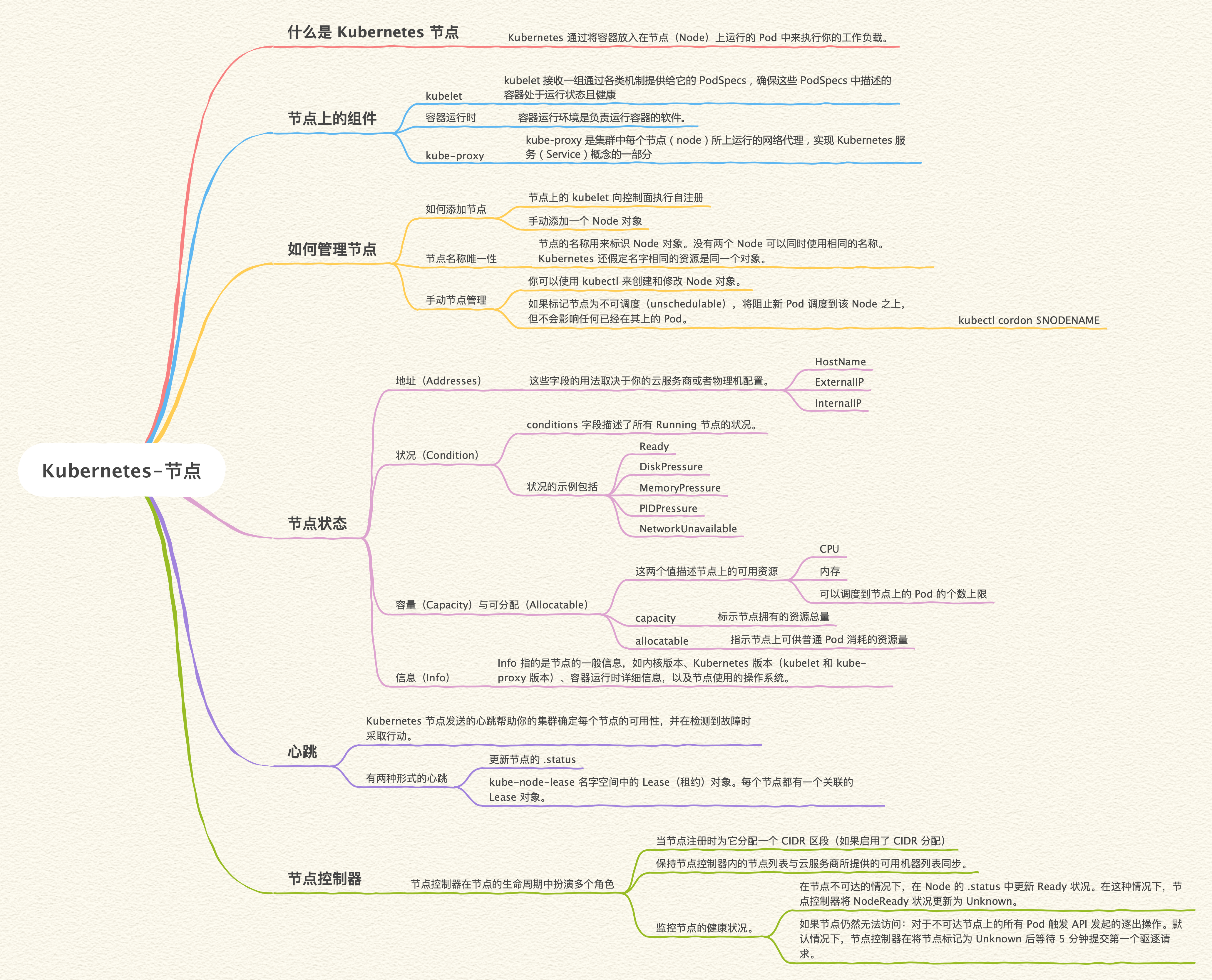
Kubernetes 通过将容器放入在节点(Node)上运行的 Pod 中来执行你的工作负载。
节点上的组件包括:
向 API 服务器添加节点的方式主要有两种:
节点的名称用来标识 Node 对象。没有两个 Node 可以同时使用相同的名称。Kubernetes 还假定名字相同的资源是同一个对象。
你可以使用 kubectl 来创建和修改 Node 对象。
如果标记节点为不可调度(unschedulable),将阻止新 Pod 调度到该 Node 之上,但不会影响任何已经在其上的 Pod。这是重启节点或者执行其他维护操作之前的一个有用的准备步骤。
要标记一个 Node 为不可调度,执行以下命令:
kubectl cordon $NODENAME
一个节点的状态包含以下信息:
这些字段的用法取决于你的云服务商或者物理机配置。
conditions 字段描述了所有 Running 节点的状况。状况的示例包括:
| 节点状况 | 描述 |
|---|---|
| Ready | 如节点是健康的并已经准备好接收 Pod 则为 True;False 表示节点不健康而且不能接收 Pod;Unknown 表示节点控制器在最近 node-monitor-grace-period 期间(默认 40 秒)没有收到节点的消息 |
| DiskPressure | True 表示节点存在磁盘空间压力,即磁盘可用量低, 否则为 False |
| MemoryPressure | True 表示节点存在内存压力,即节点内存可用量低,否则为 False |
| PIDPressure | True 表示节点存在进程压力,即节点上进程过多;否则为 False |
| NetworkUnavailable | True 表示节点网络配置不正确;否则为 False |
如果 Ready 状况的 status 处于 Unknown 或者 False 状态的时间超过了 pod-eviction-timeout 值(一个传递给 kube-controller-manager 的参数),节点控制器会对节点上的所有 Pod 触发 API 发起的驱逐。默认的逐出超时时长为 5 分钟。
当节点上出现问题时,Kubernetes 控制面会自动创建与影响节点的状况对应的污点。调度器在将 Pod 指派到某 Node 时会考虑 Node 上的污点设置。Pod 也可以设置容忍度,以便能够在设置了特定污点的 Node 上运行。
这两个值描述节点上的可用资源:
capacity 块中的字段标示节点拥有的资源总量。allocatable 块指示节点上可供普通 Pod 消耗的资源量。
Info 指的是节点的一般信息,如内核版本、Kubernetes 版本(kubelet 和 kube-proxy 版本)、容器运行时详细信息,以及节点使用的操作系统。kubelet 从节点收集这些信息并将其发布到 Kubernetes API。
Kubernetes 节点发送的心跳帮助你的集群确定每个节点的可用性,并在检测到故障时采取行动。
对于节点,有两种形式的心跳:
与 Node 的 .status 更新相比,Lease 是一种轻量级资源。使用 Lease 来表达心跳在大型集群中可以减少这些更新对性能的影响。
kubelet 负责创建和更新节点的 .status,以及更新它们对应的 Lease。
节点控制器在节点的生命周期中扮演多个角色:


文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
基本上我想选择一个节点(div),其中它的子节点(h1,b,h3)包含指定的文本。Childtext1Childtext2...Childtext3我期待的是/html/div/而不是/html/div/h1我在下面有这个,但不幸的是返回了child,而不是div的xpath。expression="//div[contains(text(),'Childtext1')]"doc.xpath(expression)我期待的是/html/div/而不是/html/div/h1那么有没有一种方法可以简单地使用xpath语法来做到这一点? 最佳答案
这个问题在这里已经有了答案:Nokogiri:SelectcontentbetweenelementAandB(3个答案)关闭2年前。我正在从url中抓取文本的div,并想删除具有backtotop类的段落下方的所有内容。我在stackoverflow上看到了一段遍历代码片段,看起来很有希望,但我不知道如何将它合并,所以@el只包含第一个p.backtotop之前的所有内容分区我的代码:@doc=Nokogiri::HTML(open(url))@el=@doc.css("div")[0]end遍历片段:doc=Nokogiri::HTML(code)stop_node=doc.css
我正在尝试为ChefRecipe编写一个库,以简化一些常见的搜索。例如,我希望能够在cookbook/libraries/library.rb中执行类似的操作,然后从同一Recipe中的Recipe中使用它:moduleExampledefself.search_attribute(attribute_name)returnsearch(:nodes,node[attribute_name])endend问题是,在Chef库文件中,node对象或search函数都不可用。似乎可以使用Chef::Search::Query.new().search(...)进行搜索,但我找不到任何可以访
我正在尝试使用Nokogiri来解析带有一些相当古怪的标记的HTML文件。具体来说,我正在尝试获取同时定义了id、多个类和样式的div。标记看起来像这样:titleListofstuff我正在尝试获取里面的问题.我可以毫无问题地获得具有单个id属性的div,但我想不出一种方法让Nokogiri获取具有和两个id类的div。所以这些工作正常:content=@doc.xpath("//div[id='foo']")content=@doc.css('div#foo')但是这些不返回任何东西:content=@doc.xpath("//div[id='bar']")content=@doc
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
文章目录Kubernetes(k8s)工作负载一、Workloads二、Pod三、Deployment四、RC、RS、DaemonSet、StatefulSet五、Job、CronJob1、Job2、CronJob六、GCKubernetes(k8s)工作负载一、Workloads什么是工作负载(Workloads)工作负载是运行在Kubernetes上的一个应用程序。一个应用很复杂,可能由单个组件或者多个组件共同完成。无论怎样我们可以用一组Pod来表示一个应用,也就是一个工作负载Pod又是一组容器(Containers)所以关系又像是这样工作负载(Workloads)控制一组PodPod控制
我有这样的代码:@doc=Nokogiri::HTML(open(url)@doc.xpath(query).eachdo|html|putshtml#howgetcontentofanodeend我如何获取节点的内容而不是像这样: 最佳答案 这是READMEfile中的概要示例为Nokogiri展示了一种使用CSS、XPath或混合的方法:require'nokogiri'require'open-uri'#GetaNokogiri::HTML:Documentforthepagewe’reinterestedin...doc=N
有没有什么干净的方法可以用Nokogiri获取文本节点的内容?现在我正在使用some_node.at_xpath("//whatever").first.content这对于获取文本来说似乎真的很冗长。 最佳答案 您只想要文本?doc.search('//text()').map(&:text)也许您不想要所有的空白和噪音。如果您只想要包含单词字符的文本节点,doc.search('//text()').map(&:text).delete_if{|x|x!~/\w/}编辑:看来您只想要单个节点的文本内容:some_node.at_