文章目录
介绍
最近也是准备复现VTNFP,那么首先需要将VTNFP论文读懂才行。
VTNFP是基于VITON和CP-VTON的改进。
VITON是2D虚拟试穿的开山鼻祖,之后的CP-VTON在上面进行了两个改进,VITON我没有复现成功,CP-VTON也是复现成功了。
论文笔记
随着网络购物的兴起,虚拟换衣可以极大的增加用户的体验感。
虚拟换衣技术基本分为基于3D模型和2D模型的。基于3D的换衣技术在硬件部署和计算效率上成本很高,在网上实现不方便,大量的计算量以及需要其他信息极大的限制了3D的实现。人们的注意力开始转移到基于2D图像的虚拟换装技术。
最近的RGB图像方法近似是生成图像类似的,如果有效的话就会使用更少的资源等等。
2D方法会遇到很多挑战,因为需要满足如下标准:1:姿势和身体形状应该被保留,身体部分应该很好的渲染;2:服装细节不应该被替代,比如裤子就应该被保留;3:目标服装应该比较好的适应身体部分;4:文本和嵌入的细节应该就可能的保留。
然后介绍了VITON和CP-VTON,后者在扭曲服装图像上面做的较好,但是在身体部分和服装保留有缺点。
将三个方法进行了比较:

前两个都没有保留好裤子,并且前两个在服装和身体的交界处也是模糊的。可能有两个原因:前两个使用的CA展现没有保留足够的身体部分细节;如手臂和裤子等重要部分在最后合成的时候没有充分的展现。
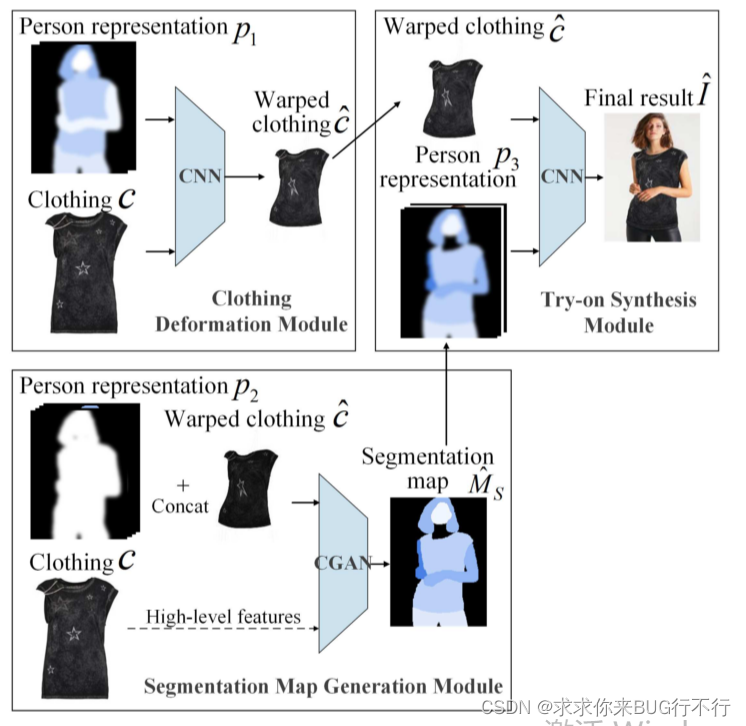
为了解决上述问题,我们提出了VTNFP,主要分为三步。
1:Clothing Deformation Module 将目标服装与人的身体姿势进行匹配。与CP-VTON不同,我们采用了自注意力机制使其相关匹配组件更有力。
2:Segmentation Map Generation Module 生成分割图 生成人穿着目标衣物的分割图,这是一个重要贡献。
3:Try-on synthesis Module 融合阶段 将扭曲的服装以及生成的分割图和其他信息进行合成。
我们做的最主要的贡献:
我们提供了一个新的生成分割图的方法,去预测身体部分穿着衣服。这个阶段可以被训练并且对服装合成有重要意义;
我们使用了一个新的将扭曲的服装以及生成的分割图和其他信息进行合成的网络,可以保留服装和身体部分的细节;
我们的方法定性的定量的比现在最好的方法都表现更好。
介绍了GAN等方法,再就是人的分析与理解,虚拟试穿的不同方法,我们方法和VITON CP-VTON最相近。
我们的训练数据应该是三元组:reference image I,clothing c, ˆI 但是这样的数据比较难获得,因此我们的数据是I,c。为了训练我们的模型,我们创造与衣服无关的人物表达I,然后训练一个模型去生成基于CA和c的合成图像ˆI 。
VTNFP由三个模型组成,上面也是说到了。
在第一个模型里面:a: ˆc = M1(p1, c),通过P1和服装生成符合身体形状的扭曲之后的服装; b:Mˆs = M2(p2, ˆc),通过P2和ˆc 和c生成一个新的身体部分分割图,并且是被目标衣物覆盖的; c:图像合成阶段:ˆI = M3(p3, ˆc),生成最后的图像。关键点是三个人物表示,p1,p2是从I得到的,p3是从I和 ˆc得到的,p3包含了分割图的身体部分和目标衣物,这对于保留服装细节和身体部分很重要。
为了保留人身体和服装的细节,我们使用了hybrid clothing-agnostic person representation (HCPR)去得到三个阶段的人体表示。
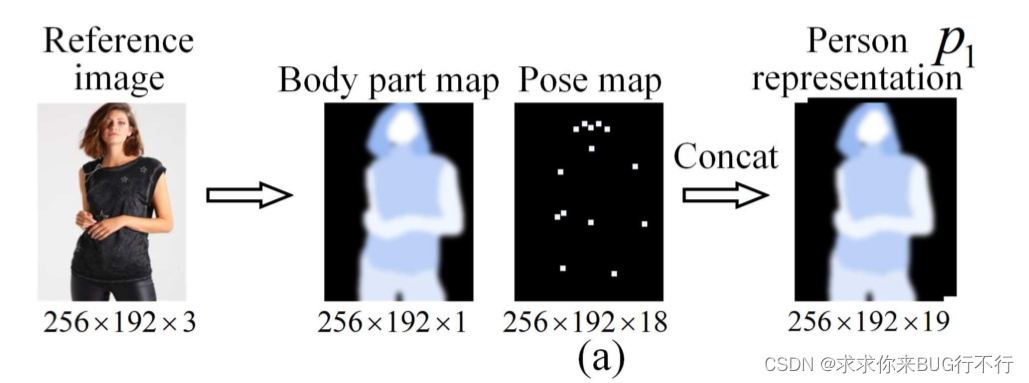
p1由两部分组成:单通道的身体部分图和18通道的姿势热图。身体部分图是从I得到的,表现了人的身体的六个部位。姿势热图这部分主要是提取图像中人体的姿态信息(pose)(使用openpose),人体的姿态信息是使用 18 个关键点进行表示的。然后将每个关键点都转换成热图的形式。先将 18 个关键点分开,对特征图中的每个关键点,将它 11 × 11 范围内的邻居点填充为1,其余地方填充为 0。最后,将这些关键点的热图结果合并到一起,就得到了一个18通道的人体姿态热图(pose map)。然后concat就行。

p2由四部分组成:单通道的身体形状图;单通道的手臂图;但通道的脸和头发图,再就是18通道的姿势图。姿势图和p1里面的一样,其他三个部分是通过结合p1中身体部分图和其他的通过8方法得到的语义零件标签生成的。

p3由四部分组成:单通道身体分割图;单通道手臂形状图;三通道的脸部和头发图;18通道的姿势图。从p2和ˆc得到的身体分割图包含了13个语义分割区域并且是人穿着目标衣物的图,包含了上下衣物,眼镜等细节。手臂形状图是从身体分割图得到的,表示了暴露在衣服外面的手臂(与p2里面的手臂图不一样);脸部和头发是RGB图像,姿势图和之前的一样。
p 1 2 3 表示不同的信息,p1和p2表示了从I得到的与服装无关的人物表示,p1用来生成扭曲的衣服,p2用来预测身体分割图。p3提供了从p2和ˆc得到的目标图像蓝图。
这个模型是将目标衣物与I中人的姿势和身体形状(p1)进行匹配与扭曲,和CP-VTON一样,也使用了一个端到端的GMM,并且还是用了NL去提升特征学习与匹配。
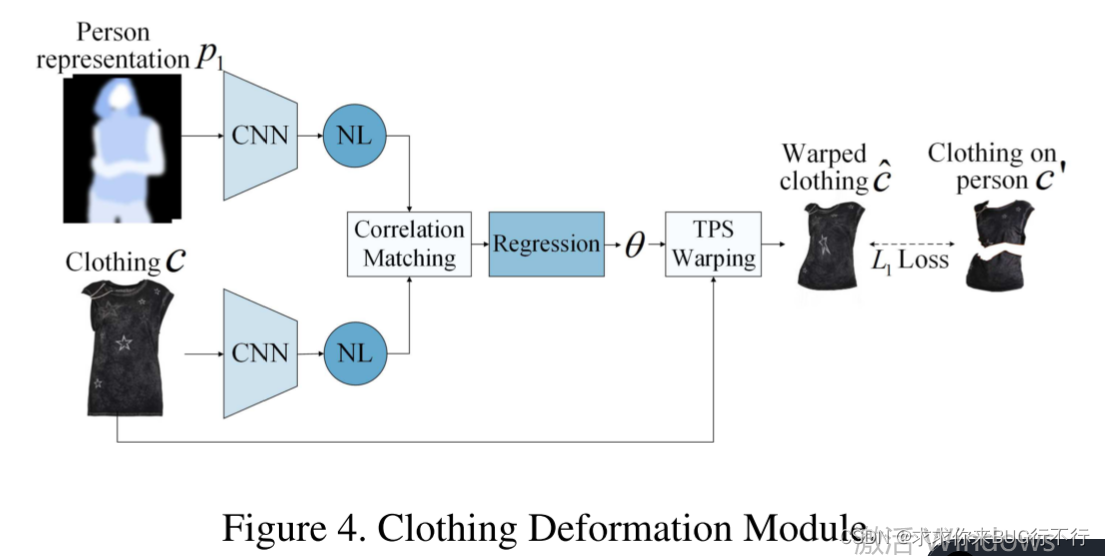
分别使用卷积神经网络提取p1和c的特征,然后使用NL,之后将他两进行关联,最终这个关联图送入到一个回归网络去预测参数theta,然后将c通过theta进行扭曲为ˆc,损失函数是使用的L1损失,ground truth 是从I里面分割出来的。这里我想的是与I中的衣服分割图进行损失求值,不仅为了将衣服与人的姿势适应,还为了将手臂遮挡的地方也去掉。
注意: 我们使用的数据集是:I, c。原始图像人穿的衣服和我们的目标衣物是一样的,所以我们最终扭曲的c就是为了和人身上穿的c尽量符合!!!
M2是为了得到人穿着目标衣物的语义分割图,而从I里面只能得到穿着原始衣服的语义分割图。这一阶段的语义分割图是基于p2和^c的。
下图展示了这一阶段的结构
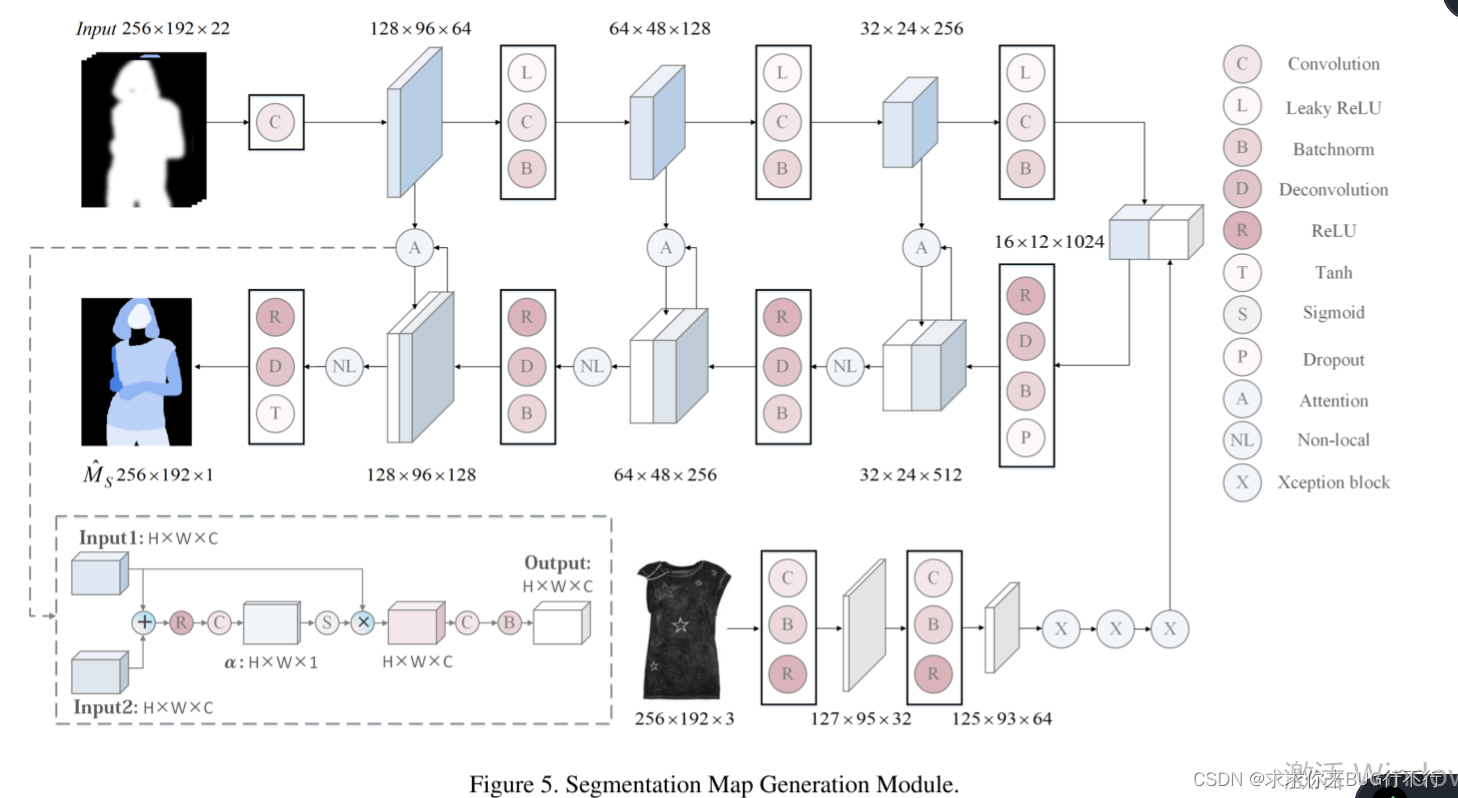
我们将p2和^c进行编码,然后用解码器去生成Mˆs。我们采用了自注意力机制来门控从编码器到解码器的横向信息流,NL操作用来捕获长期依赖。尽管 ^c是编码器解码器的输入,但是可能丢掉目标服装文本以及嵌入的细节,所以我们添加了一个分支去提取服装特征,最后将它连接到编码器层。
注意:上层除了p2之后还添加了wrapped clothing
我们训练这个模型使用c,I。首先从I得到p2,然后将Mˆs与ground truth进行比较,后者是直接从I得到的。这个模型也可以看作一个CGAN模型。最终的损失函数由在像素级别的中心损失和CGAN的损失函数占不同权重组成。i和k分别代表像素索引和语义身体部位。
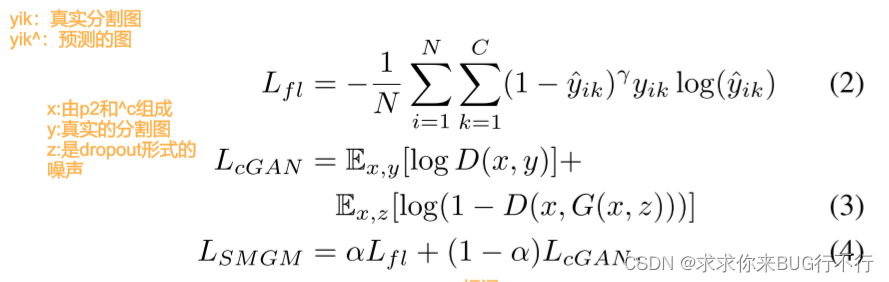
最终目的是基于前两个模型的输出计算出最终的目标图像。总的来说,我们使用了三个来源:^c,p3,从I得到的手臂和裤子的信息。
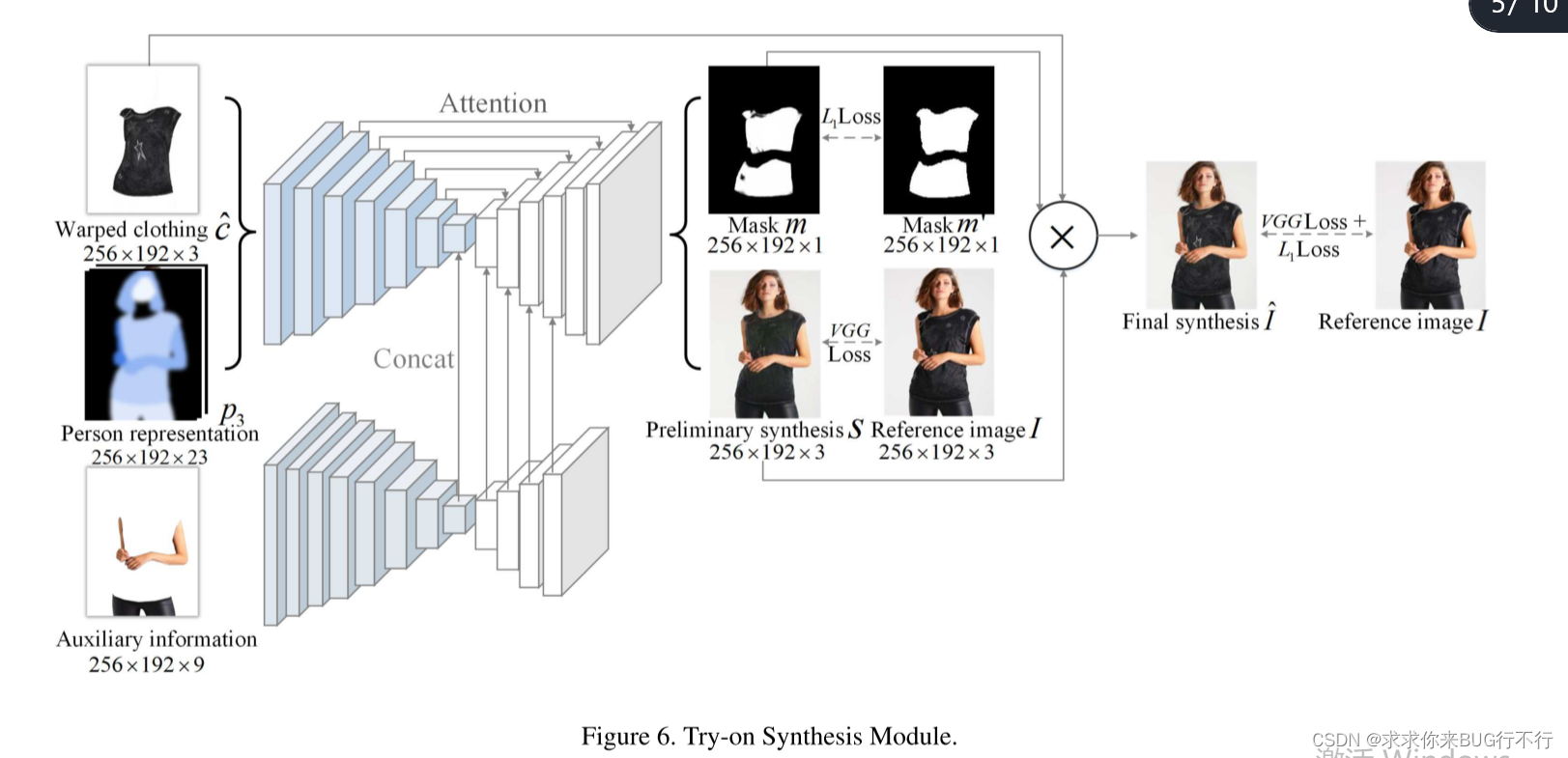
上面分支使用了门控网络(U-NET型)去提取p3和^c的信息;下面分支由七个编码层并且基于Xception,接着就是四个解码器提取辅助信息的信息,之后直接连接到上分支得到的特征即可。下分支最主要的任务是为了提供手臂和裤子的信息。
这个模型会生成一个掩码,决定了目标图像的衣物区域,还生成了一个初步的合成图像s。最终的图像为前两个输出的混合体:Iˆ= m⊙ ˆc+ (1 −m) ⊙ s 注:⊙ 代表逐元素矩阵乘法。
损失函数
M3的损失函数由如下构成:

等式6是使用的L1损失。ground truth mask是通过去掉扭曲的衣服^c的手臂部分得到的。这个损失是为了使网络保留更多的目标服装细节。(7)是合成的图像与最终真实的目标图像的L1损失,除了使用像素强度差距 ,我们还通过VGG19提取特征使用了感知损失。S和I之间使用了感知损失,提取特征的每层权重也不同。最终的损失函数通过四个不同的权重与他们相乘组成。感知损失就是为了使生成的图像更加真实。
数据集:与VITON和CP-VTON的一样,14006训练,2002测试。在训练的时候,目标衣物与模型穿的衣物一样,在测试的时候是不同的。所有的评估和可视化都是在测试阶段完成的。
所有输入和输出都是256x192。
1.等式4里面的α = 0.5。
2.训练15epoch batch size = 5;
3.生成器包含四个编码层和四个解码层,过滤器大小4x4并且步长为2。
4.编码器过滤器数量分别是64,128,256,512。解码器的通道分别是512,256,128,1 。NL层加在连接层后面。、
5.提取高维特征的卷积层的过滤器是3x3的,还有三个Xception,过滤器的数量分别是32,64,128,256,512 .鉴别器和参考文献【12】一样。
1.等式(10)的λ都是1,次数,优化器,学习率和Clothing Deformation Module的一样。
2.所有的上分支编码层过滤器大小是4x4,步长为2,数量分别是64,128,256,512,512,512.
3.如参考文献39,24 我们使用最近邻插值层和单步长的卷积层代替两步长的逆卷积层。
4.所以所有的解码层都由factor为2的上采样层以及单步长的过滤器3x3的卷积层组成。数量分别是512,512,256,128,64,4。
5.在编码层使用了leakrelu,解码层使用了relu,每个卷积层之后都跟了一个instance normalization层。
6.下分支与上分支不同。在编码层的过滤器分别是32,64,128,256,512,512,512.前两个卷积层的过滤器为3x3,步长分别为2和1 。后五个卷积层是Xception 块。
7.解码层我们使用与上分支的前四层相同的结构。

如果没有提取高维特征和使用NL层,产生的分割图的效果不好。

如果没有下分支的话,手臂裤子等细节不好。
接下来就是各个模型的比较

各有优缺点。只有VTNFP能够同时很好的保留姿势和服装细节。VITON忽略了边缘服装的细节,CP-VTON为了改善,但是在身体方面又有所下降。VTNFP生成一个穿着目标衣物的人的分割图,以此为基础而不是单独依靠姿势图,ground truth的mask是扭曲的衣物的分割图去除掉手臂部分得到的,所以能够很好的保留姿势和服装细节。
我们选了一些志愿者,让他们选心仪的生成的图像,大都倾向于VTNFP。
我们的模型是分为三步的,第一步生成扭曲的衣物,然后生成穿着目标衣物的身体分割图,最终就是合成图像。我们模型目前比其他的方法效果都好。
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
我这个模型:classBunny每当我提交一个表单来创建这个模型时,我都会收到以下错误:#的未定义方法“number_before_type_cast” 最佳答案 我通过将此方法添加到我的Bunny模型中解决了这个问题:defnumber_before_type_castnumberend我不喜欢它,但我想在有人发布更好的解决方案之前它会起作用。 关于ruby-on-rails-Rails验证虚拟属性,我们在StackOverflow上找到一个类似的问题: h
【适用平台】私有云 说明:完成私有云部分是需要两台虚拟机的,分别为controller、compute两个节点,但我们只需配置一台,然后克隆就方便多啦!需要用到的映射文件:关于vm的安装我就不介绍的,毕竟挺简单的,下面让我们看看基于私有云模块中,虚拟机的搭建吧。1、创建新的虚拟机,这里一般我会选择自定义,毕竟后面的配置都要根据私有云相关来进行搭建,会比较复杂。(如果是基础的可以选择典型,典型的满足一般虚拟机的配置) 2、选择稍后安装操作系统会比较方便后续的选择,这里你也可以自己选择自己的映像文件(但不建议) 3、我们是基于Linux下操作的,所以选择Linux客户机操作系统,版本选择自己
TCP是面向连接的协议,连接的建立和释放是每一次面向连接的通信中必不可少的过程。TCP连接的管理就是使连接的建立和释放都能正常地进行。三次握手TCP连接的建立—三次握手建立TCP连接①若主机A中运行了一个客户进程,当它需要主机B的服务时,就发起TCP连接请求,并在所发送的分段中用SYN=1表示连接请求,并产生一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x。主机B收到A的连接请求报文,就完成了第一次握手。客户端发送SYN=1表示连接请求客户端发送一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x②主机B如果同意建立连接,则向主机A发送确认报
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
VXLAN简介定义RFC定义了VLAN扩展方案VXLAN(VirtualeXtensibleLocalAreaNetwork,虚拟扩展局域网)。VXLAN采用MACinUDP(UserDatagramProtocol)封装方式,是NVO3(NetworkVirtualizationoverLayer3)中的一种网络虚拟化技术。目的随着网络技术的发展,云计算凭借其在系统利用率高、人力/管理成本低、灵活性/可扩展性强等方面表现出的优势,已经成为目前企业IT建设的新趋势。而服务器虚拟化作为云计算的核心技术之一,得到了越来越多的应用。服务器虚拟化技术的广泛部署,极大地增加了数据中心的计算密度;同时,为