 Apache HBase是一个提供 NoSQL 数据存储的 Apache 开源项目。HBase 通常与 HDFS 一起使用,在世界范围内被广泛使用。知名用户包括 Facebook、Twitter、Yahoo 等。从开发人员的角度来看,HBase 是一个“分布式、版本化、非关系型数据库,仿照 Google 的 Bigtable,一个用于结构化数据的分布式存储系统”。HBase 可以通过纵向扩展(即部署在更大的服务器上)或横向扩展(即部署在更多服务器上)轻松处理非常高的吞吐量。 从用户的角度来看,每个查询的延迟非常重要。当我们与用户一起测试、调整和优化 HBase 工作负载时,我们现在遇到了很多真正想要 99% 操作延迟的人。这意味着从客户端请求到返回客户端的响应的往返行程,全部在 100 毫秒内完成。 有几个因素会导致延迟的变化。最具破坏性和不可预测的延迟入侵者之一是 Java 虚拟机 (JVM) 的“stop the world”垃圾收集(内存清理)暂停。 为了解决这个问题,我们使用 Oracle jdk7u21 和 jdk7u60 G1 (Garbage 1st) 收集器尝试了一些实验。我们使用的服务器系统基于具有超线程(40 个逻辑处理器)的 Intel Xeon Ivy-bridge EP 处理器。它有 256GB DDR3-1600 RAM 和三个 400GB SSD 作为本地存储。这个小型设置包含一个主站和一个从站,配置在一个节点上,负载适当缩放。我们使用 HBase 版本 0.98.1 和本地文件系统来存储 HFile。HBase测试表配置为4亿行,大小为580GB。我们使用默认的 HBase 堆策略:40% 用于 blockcache,40% 用于 memstore。YCSB 用于驱动 600 个工作线程向 HBase 服务器发送请求 以下图表显示 jdk7u21 使用. 我们指定了要使用的垃圾收集器、堆大小和所需的垃圾收集 (GC)“停止世界”暂停时间。-XX:+UseG1GC -Xms100g -Xmx100g -XX:MaxGCPauseMillis=100
Apache HBase是一个提供 NoSQL 数据存储的 Apache 开源项目。HBase 通常与 HDFS 一起使用,在世界范围内被广泛使用。知名用户包括 Facebook、Twitter、Yahoo 等。从开发人员的角度来看,HBase 是一个“分布式、版本化、非关系型数据库,仿照 Google 的 Bigtable,一个用于结构化数据的分布式存储系统”。HBase 可以通过纵向扩展(即部署在更大的服务器上)或横向扩展(即部署在更多服务器上)轻松处理非常高的吞吐量。 从用户的角度来看,每个查询的延迟非常重要。当我们与用户一起测试、调整和优化 HBase 工作负载时,我们现在遇到了很多真正想要 99% 操作延迟的人。这意味着从客户端请求到返回客户端的响应的往返行程,全部在 100 毫秒内完成。 有几个因素会导致延迟的变化。最具破坏性和不可预测的延迟入侵者之一是 Java 虚拟机 (JVM) 的“stop the world”垃圾收集(内存清理)暂停。 为了解决这个问题,我们使用 Oracle jdk7u21 和 jdk7u60 G1 (Garbage 1st) 收集器尝试了一些实验。我们使用的服务器系统基于具有超线程(40 个逻辑处理器)的 Intel Xeon Ivy-bridge EP 处理器。它有 256GB DDR3-1600 RAM 和三个 400GB SSD 作为本地存储。这个小型设置包含一个主站和一个从站,配置在一个节点上,负载适当缩放。我们使用 HBase 版本 0.98.1 和本地文件系统来存储 HFile。HBase测试表配置为4亿行,大小为580GB。我们使用默认的 HBase 堆策略:40% 用于 blockcache,40% 用于 memstore。YCSB 用于驱动 600 个工作线程向 HBase 服务器发送请求 以下图表显示 jdk7u21 使用. 我们指定了要使用的垃圾收集器、堆大小和所需的垃圾收集 (GC)“停止世界”暂停时间。-XX:+UseG1GC -Xms100g -Xmx100g -XX:MaxGCPauseMillis=100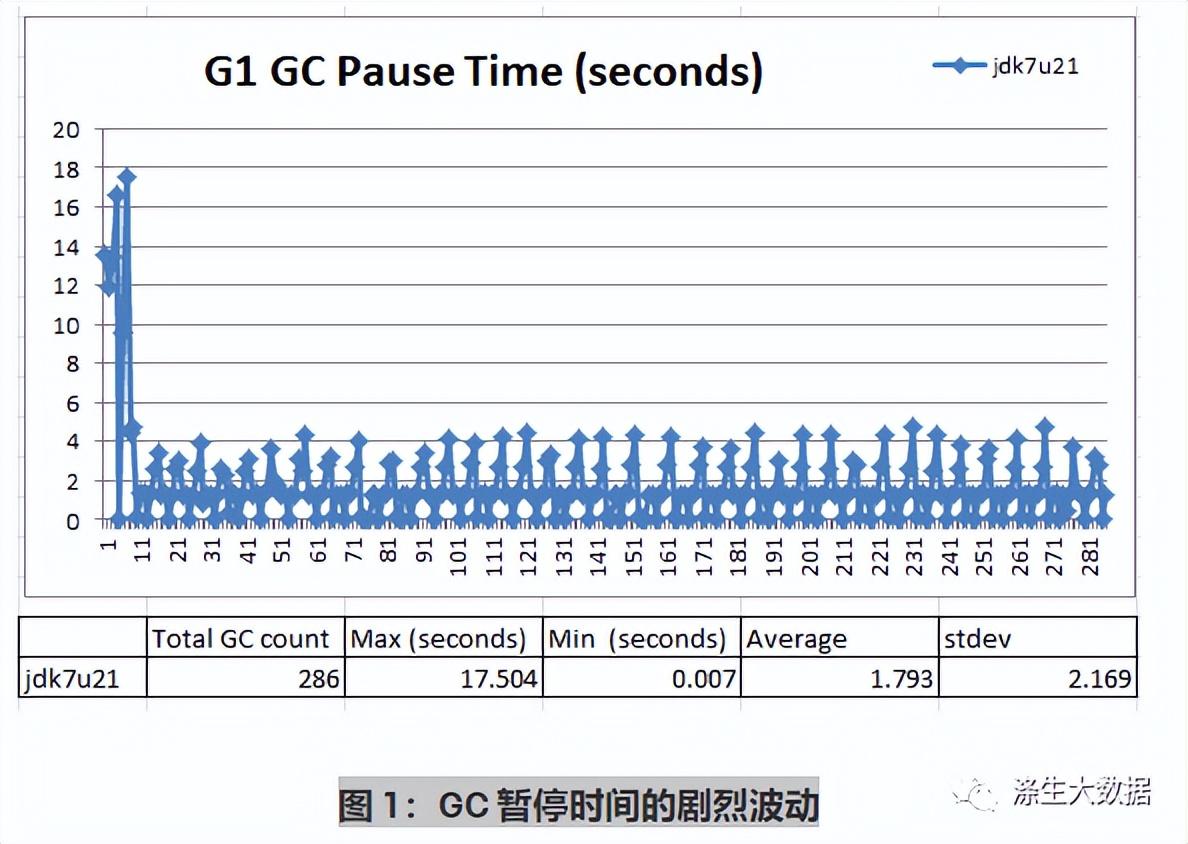 在这种情况下,我们遇到了剧烈波动的 GC 暂停。在初始峰值达到 17.5 秒后,GC 暂停的范围从 7 毫秒到 5 整秒。下图显示了稳态期间的更多详细信息:
在这种情况下,我们遇到了剧烈波动的 GC 暂停。在初始峰值达到 17.5 秒后,GC 暂停的范围从 7 毫秒到 5 整秒。下图显示了稳态期间的更多详细信息: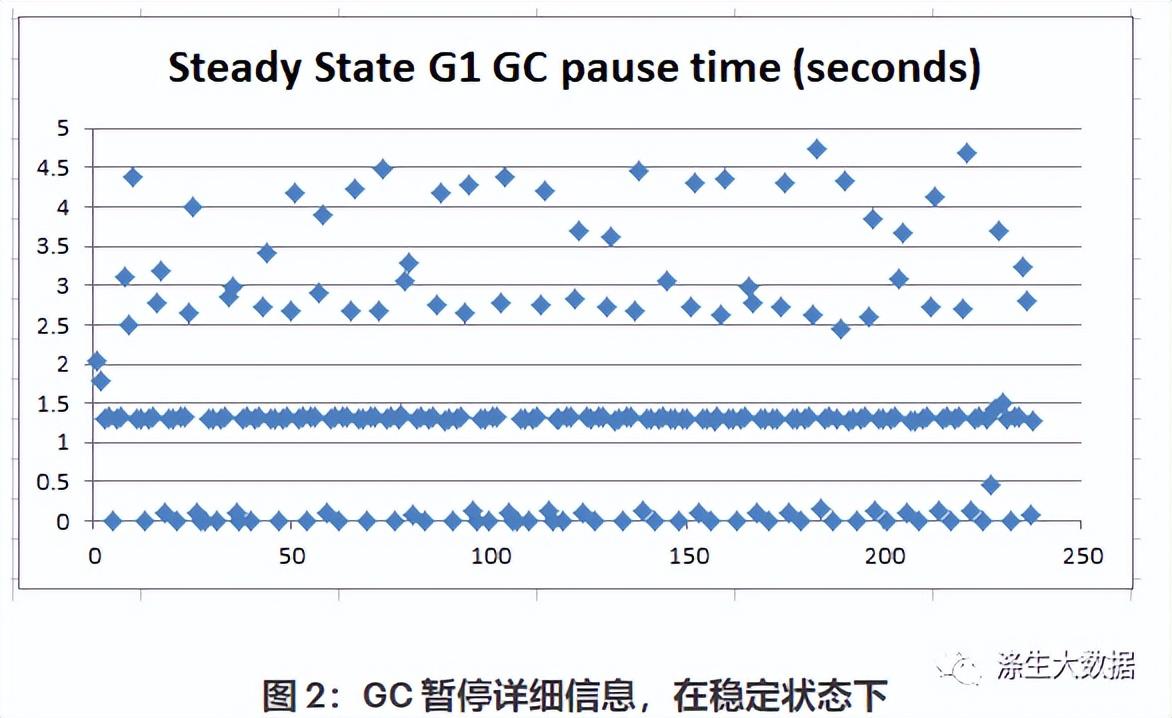 图 2 告诉我们 GC 暂停实际上分为三个不同的组:(1) 在 1 到 1.5 秒之间;(1) 在 1 到 1.5 秒之间;(2) 0.007秒至0.5秒之间;(3) 尖峰在 1.5 秒到 5 秒之间。这很奇怪,所以我们测试了最近发布的jdk7u60,看看数据是否有任何不同: 我们使用完全相同的 JVM 参数运行相同的 100% 读取测试:.-XX:+UseG1GC -Xms100g -Xmx100g -XX:MaxGCPauseMillis=100
图 2 告诉我们 GC 暂停实际上分为三个不同的组:(1) 在 1 到 1.5 秒之间;(1) 在 1 到 1.5 秒之间;(2) 0.007秒至0.5秒之间;(3) 尖峰在 1.5 秒到 5 秒之间。这很奇怪,所以我们测试了最近发布的jdk7u60,看看数据是否有任何不同: 我们使用完全相同的 JVM 参数运行相同的 100% 读取测试:.-XX:+UseG1GC -Xms100g -Xmx100g -XX:MaxGCPauseMillis=100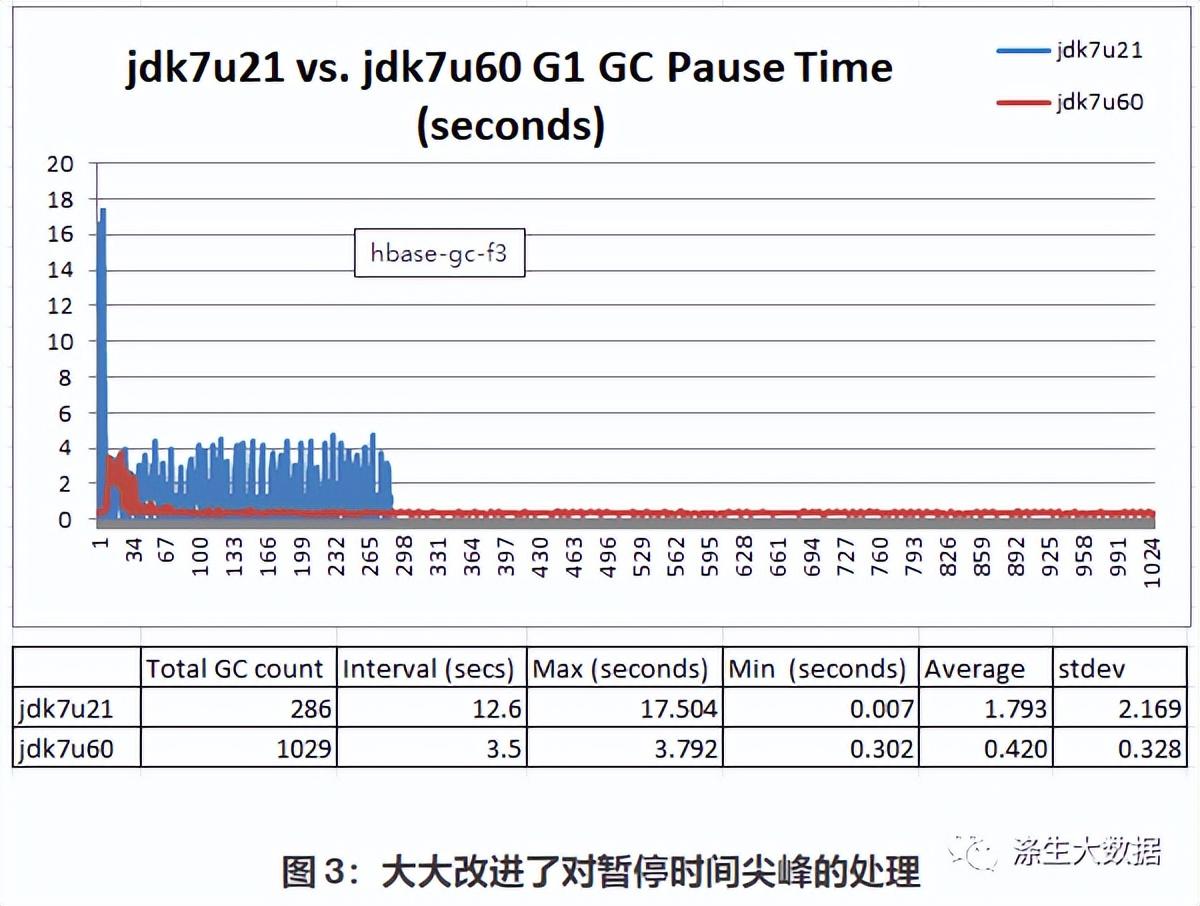 Jdk7u60 大大提高了 G1 在稳定阶段处理初始尖峰后的暂停时间尖峰的能力。Jdk7u60 在一小时的运行中产生了 1029 次年轻的和混合的 GC。GC 大约每 3.5 秒发生一次。Jdk7u21 进行了 286 次 GC,每次 GC 大约每 12.6 秒发生一次。Jdk7u60 能够将暂停时间控制在 0.302 到 1 秒之间,而没有出现大的峰值。 下面的图 4 让我们更仔细地观察了稳定状态下 150 次 GC 暂停:
Jdk7u60 大大提高了 G1 在稳定阶段处理初始尖峰后的暂停时间尖峰的能力。Jdk7u60 在一小时的运行中产生了 1029 次年轻的和混合的 GC。GC 大约每 3.5 秒发生一次。Jdk7u21 进行了 286 次 GC,每次 GC 大约每 12.6 秒发生一次。Jdk7u60 能够将暂停时间控制在 0.302 到 1 秒之间,而没有出现大的峰值。 下面的图 4 让我们更仔细地观察了稳定状态下 150 次 GC 暂停: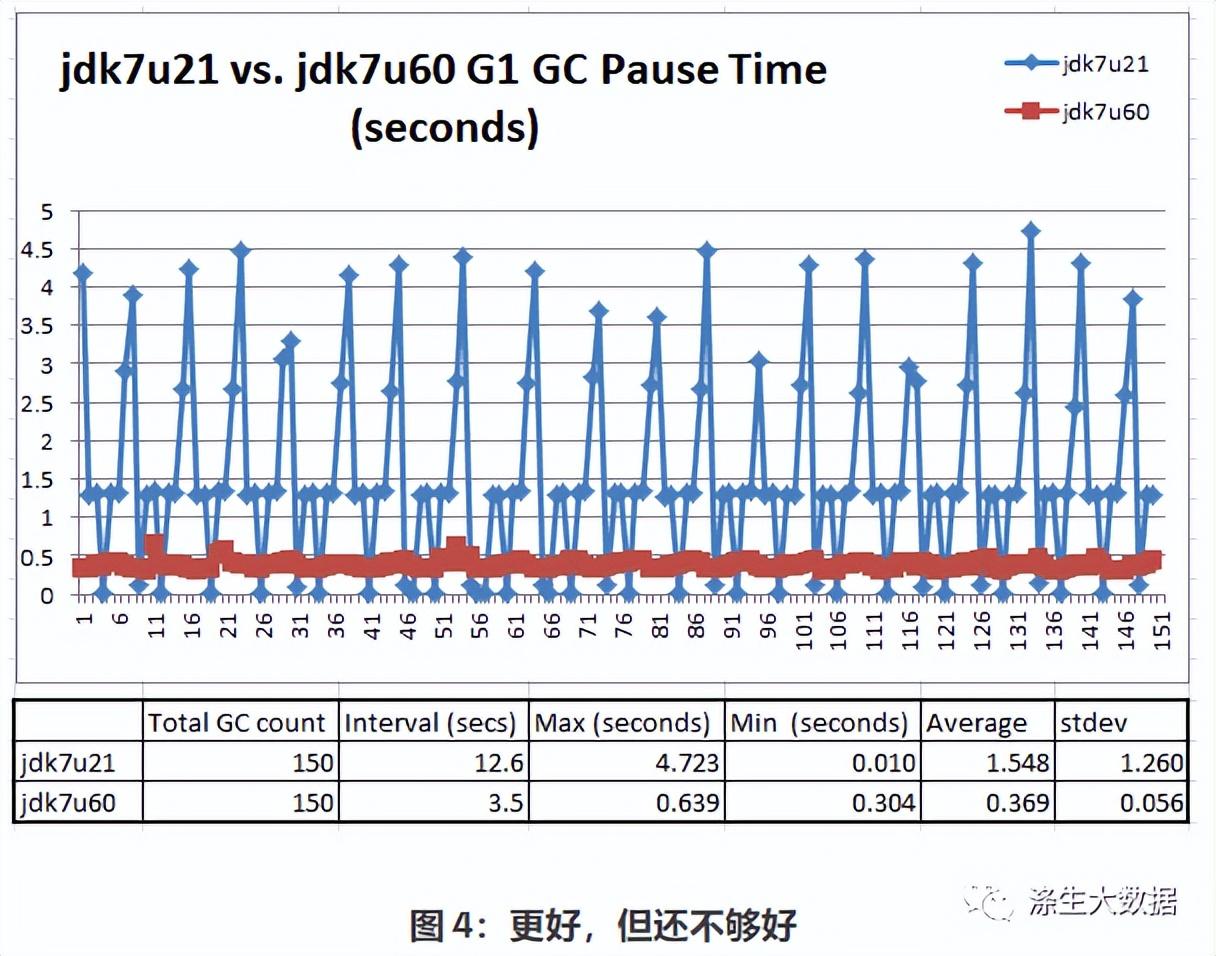 在稳定状态下,jdk7u60 能够将平均暂停时间保持在 369 毫秒左右。比jdk7u21好很多,但是还是达不到我们给的100毫秒的要求。–Xx:MaxGCPauseMillis=100 为了确定我们还能做些什么来获得 1 亿秒的暂停时间,我们需要更多地了解 JVM 的内存管理和 G1(垃圾优先)垃圾收集器的行为。下图显示了 G1 如何进行 Young Gen 收集。
在稳定状态下,jdk7u60 能够将平均暂停时间保持在 369 毫秒左右。比jdk7u21好很多,但是还是达不到我们给的100毫秒的要求。–Xx:MaxGCPauseMillis=100 为了确定我们还能做些什么来获得 1 亿秒的暂停时间,我们需要更多地了解 JVM 的内存管理和 G1(垃圾优先)垃圾收集器的行为。下图显示了 G1 如何进行 Young Gen 收集。 当 JVM 启动时,根据 JVM 启动参数,它要求操作系统分配一个大的连续内存块来托管 JVM 的堆。该内存块由 JVM 划分为多个区域。
当 JVM 启动时,根据 JVM 启动参数,它要求操作系统分配一个大的连续内存块来托管 JVM 的堆。该内存块由 JVM 划分为多个区域。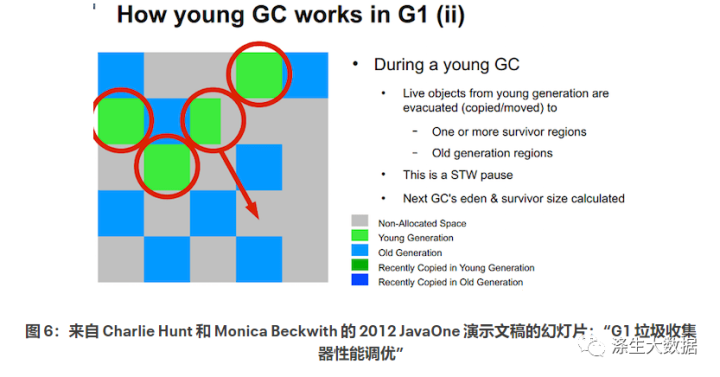 如图 6 所示,Java 程序使用 Java API 分配的每个对象首先进入左侧年轻代的 Eden 空间。一段时间后,Eden 变满,触发了 Young generation GC。仍然被引用(即“活着”)的对象被复制到 Survivor 空间。当对象在年轻代中存活了几次 GC 后,它们就会被提升到老年代空间。当 Young GC 发生时,Java 应用程序的线程会停止,以便安全地标记和复制活动对象。这些停止是臭名昭著的“停止世界”GC 暂停,这使得应用程序在暂停结束之前没有响应。
如图 6 所示,Java 程序使用 Java API 分配的每个对象首先进入左侧年轻代的 Eden 空间。一段时间后,Eden 变满,触发了 Young generation GC。仍然被引用(即“活着”)的对象被复制到 Survivor 空间。当对象在年轻代中存活了几次 GC 后,它们就会被提升到老年代空间。当 Young GC 发生时,Java 应用程序的线程会停止,以便安全地标记和复制活动对象。这些停止是臭名昭著的“停止世界”GC 暂停,这使得应用程序在暂停结束之前没有响应。 老一代也会变得拥挤。在某个级别(由默认为总堆的 45% 控制)会触发混合 GC。它收集年轻一代和老一代。混合 GC 暂停由年轻代在混合 GC 发生时清理所需的时间控制。-XX:InitiatingHeapOccupancyPercent=? 所以我们可以在 G1 中看到,“停止世界”GC 暂停主要取决于 G1 标记和复制活动对象到 Eden 空间之外的速度。考虑到这一点,我们将分析 HBase 内存分配模式将如何帮助我们调整 G1 GC 以获得我们期望的 100 毫秒暂停。 在 HBase 中,有两个内存结构消耗了它的大部分堆:用于BlockCache读取操作的缓存 HBase 文件块,以及缓存最新更新的 Memstore。
老一代也会变得拥挤。在某个级别(由默认为总堆的 45% 控制)会触发混合 GC。它收集年轻一代和老一代。混合 GC 暂停由年轻代在混合 GC 发生时清理所需的时间控制。-XX:InitiatingHeapOccupancyPercent=? 所以我们可以在 G1 中看到,“停止世界”GC 暂停主要取决于 G1 标记和复制活动对象到 Eden 空间之外的速度。考虑到这一点,我们将分析 HBase 内存分配模式将如何帮助我们调整 G1 GC 以获得我们期望的 100 毫秒暂停。 在 HBase 中,有两个内存结构消耗了它的大部分堆:用于BlockCache读取操作的缓存 HBase 文件块,以及缓存最新更新的 Memstore。 新对象形成LruBlockCache,Memstore首先进入Young generation的Eden空间。如果它们存活的时间足够长(即,如果它们没有被逐出LruBlockCache或从 Memstore 中清除),那么在几次 GC 之后,它们就会进入 Java 堆的老年代。当 Old generation 的可用空间小于给定threshOld(InitiatingHeapOccupancyPercent开始)时,混合 GC 开始并清除 Old generation 中的一些死对象,从 Young gen 复制活动对象,并重新计算 Young gen 的 Eden 和 Old gen 的HeapOccupancyPercent. 最终,当HeapOccupancyPercent达到一定水平时,FULL GC会发生一个巨大的“停止世界” GC 暂停以清理 Old gen 中的所有死亡对象。 在研究了“”生成的 GC 日志之后,我们注意到在 HBase 100% 读取期间,它从未增长到足以引发完整 GC 的程度。我们看到的 GC 暂停主要由年轻一代“停止世界”暂停和随时间增加的引用处理所主导。-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicyHeapOccupancyPercent完成该分析后,我们对默认的 G1 GC 设置进行了三组更改:
新对象形成LruBlockCache,Memstore首先进入Young generation的Eden空间。如果它们存活的时间足够长(即,如果它们没有被逐出LruBlockCache或从 Memstore 中清除),那么在几次 GC 之后,它们就会进入 Java 堆的老年代。当 Old generation 的可用空间小于给定threshOld(InitiatingHeapOccupancyPercent开始)时,混合 GC 开始并清除 Old generation 中的一些死对象,从 Young gen 复制活动对象,并重新计算 Young gen 的 Eden 和 Old gen 的HeapOccupancyPercent. 最终,当HeapOccupancyPercent达到一定水平时,FULL GC会发生一个巨大的“停止世界” GC 暂停以清理 Old gen 中的所有死亡对象。 在研究了“”生成的 GC 日志之后,我们注意到在 HBase 100% 读取期间,它从未增长到足以引发完整 GC 的程度。我们看到的 GC 暂停主要由年轻一代“停止世界”暂停和随时间增加的引用处理所主导。-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicyHeapOccupancyPercent完成该分析后,我们对默认的 G1 GC 设置进行了三组更改: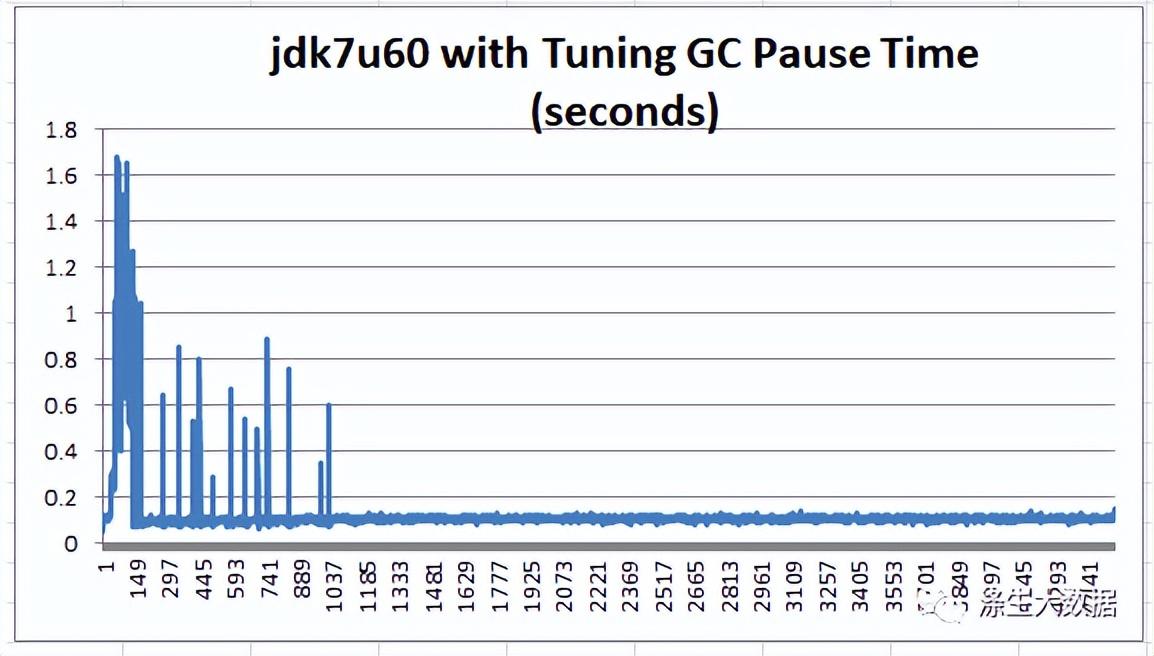 在此图表中,即使是最高的初始稳定峰值也从 3.792 秒减少到 1.684 秒。最开始的峰值不到 1 秒。结算后,GC 能够将暂停时间保持在 100 毫秒左右。下图比较了 jdk7u60 在稳定状态下使用和不使用调优的运行情况:
在此图表中,即使是最高的初始稳定峰值也从 3.792 秒减少到 1.684 秒。最开始的峰值不到 1 秒。结算后,GC 能够将暂停时间保持在 100 毫秒左右。下图比较了 jdk7u60 在稳定状态下使用和不使用调优的运行情况: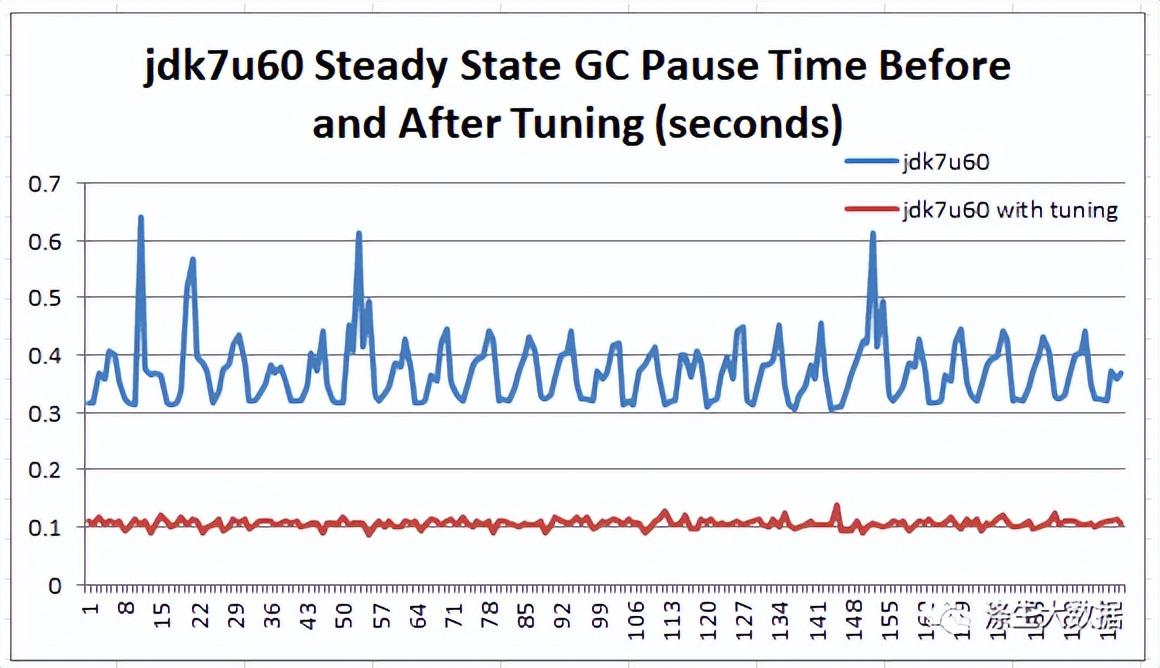 我们上面描述的简单 GC 调整给出了理想的 GC 暂停时间,大约 100 毫秒,平均 106 毫秒和 7 毫秒标准偏差。经验总结:HBase 是一个响应时间关键的应用程序,它要求 GC 暂停时间是可预测和可管理的。使用 Oracle jdk7u60,根据报告的 GC 信息,我们能够将 GC 暂停时间调低到我们想要的 100 毫秒。-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy
我们上面描述的简单 GC 调整给出了理想的 GC 暂停时间,大约 100 毫秒,平均 106 毫秒和 7 毫秒标准偏差。经验总结:HBase 是一个响应时间关键的应用程序,它要求 GC 暂停时间是可预测和可管理的。使用 Oracle jdk7u60,根据报告的 GC 信息,我们能够将 GC 暂停时间调低到我们想要的 100 毫秒。-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy-server -XX:+UseG1GC
-XX:+UnlockExperimentalVMOptions
-XX:G1NewSizePercent=5
-XX:+ParallelRefProcEnabled
-XX:ConcGCThreads=8
-XX:ParallelGCThreads=16
-XX:G1HeapRegionSize=32m
-XX:G1MixedGCCountTarget=32
-XX:G1OldCSetRegionThresholdPercent=5
-XX:SurvivorRatio=4
-XX:InitiatingHeapOccupancyPercent=70
-XX:G1ReservePercent=15
-XX:G1HeapWastePercent=5
-XX:MaxGCPauseMillis=50
-XX:GCPauseIntervalMillis=100我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.