首先要知道Hive和HBase两者的区别,我们必须要知道两者的作用和在大数据中扮演的角色
1.Hive是hadoop数据仓库管理工具,严格来说,不是数据库,本身是不存储数据和处理数据的,其依赖于HDFS存储数据,依赖于MapReducer进行数据处理。
2.Hive的优点是学习成本低,可以通过类SQL语句(HSQL)快速实现简单的MR任务,不必开发专门的MR程序。
3.由于Hive是依赖于MapReducer处理数据的,因此有很高的延迟性,不适用于实时数据处理(数据查询,数据插入,数据分析),适用于离线数据的批处理。
1.HBase是一种分布式、可扩展、支持海量数据存储的NOSQL数据库
2.HBase主要适用于海量数据的实时数据处理(随机读写)
3.由于HDFS不支持随机读写,而HBase正是为此而诞生的,弥补了HDFS的不可随机读写。
共同点
hbase与hive都是架构在hadoop之上的。都是用HDFS作为底层存储。
区别
1.Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。总的来说,hive是适用于离线数据的批处理,hbase是适用于实时数据的处理。
2.Hive本身不存储和计算数据,它完全依赖于HDFS存储数据和MapReduce处理数据,Hive中的表纯逻辑。
3.hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
4.由于HDFS的不可随机读写,hive是不支持随机写操作,而hbase支持随机写入操作。
5.HBase只支持简单的键查询,不支持复杂的条件查询
关系
在大数据架构中,Hive和HBase是协作关系,这里就举例一种常用的协作关系,具体流程如下图:
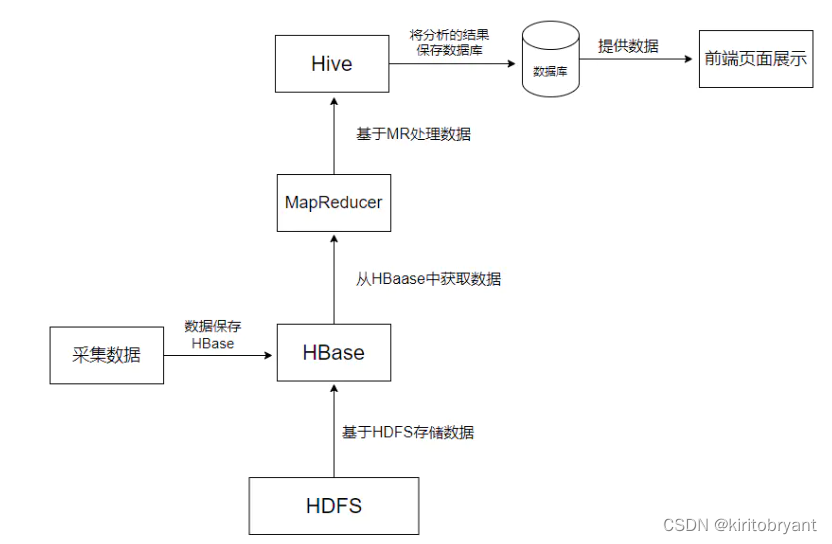
做一个总结,Hive和HBase都是Hadoop集群下的工具,Hive是对MapReduce的优化,而HBase则是HDFS数据存储的大管家。那么,这两者各适用于哪些场景呢?
1.Hive中的表为纯逻辑表,仅仅对表的元数据进行定义。Hive没有物理存储的功能,它完全依赖HDFS和MapReduce。尚学堂陈老师指出这样就可以将结构化的数据文件映射为为一张数据库表,并提供完整的SQL查询功能,并将SQL语句最终转换为MapReduce任务进行运行。HBase表则是物理表,适合存放非结构化的数据。
2.Hive是在MapReduce的基础上对数据进行处理,而MapReduce的数据处理依照行模式;而HBase为列模式,这样使得对海量数据的随机访问变得可行。
3.HBase的存储表存储密度小,因而用户可以对行定义成不同的列;而Hive是逻辑表,属于稠密型,即定义列数,每一行对列数都有固定的数据。
4.Hive使用Hadoop来分析处理数据,而Hadoop系统是批处理系统,所以数据处理存在延时的问题;而HBase是准实时系统,可以实现数据的实时查询。
5.Hive没有row-level的更新,它适用于大量append-only数据集(如日志)的批任务处理。而基于HBase的查询,支持和row-level的更新。
6.Hive全面支持SQL,一般可以用来进行基于历史数据的挖掘、分析。而HBase不适用于有join,多级索引,表关系复杂的应用场景。
两者使用场景的区别:
HBase的应用场景通常是采集网页数据的存储,因为它是key-value型数据库,从而可以到各种key-value应用场景,例如存储日志信息,对于内容信息不需要完全结构化出来的类CMS应用等。注意hbase针对的仍然是OLTP应用为主。
hive主要针对的是OLAP应用,其底层是hdfs分布式文件系统,重点是基于一个统一的查询分析层,支撑OLAP应用中的各种关联,分组,聚合类SQL语句。hive一般只用于查询分析统计,而不能是常见的CUD操作,要知道HIVE是需要从已有的数据库或日志进行同步最终入到hdfs文件系统中,当前要做到增量实时同步都相当困难。
以上就是关于Hive和HBase有哪些区别与联系及适用场景的论述,希望对学大数据分析的同学有所帮助。
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我正在检查一个Rails项目。在ERubyHTML模板页面上,我看到了这样几行:我不明白为什么不这样写:在这种情况下,||=和ifnil?有什么区别? 最佳答案 在这种特殊情况下没有区别,但可能是出于习惯。每当我看到nil?被使用时,它几乎总是使用不当。在Ruby中,很少有东西在逻辑上是假的,只有文字false和nil是。这意味着像if(!x.nil?)这样的代码几乎总是更好地表示为if(x)除非期望x可能是文字false。我会将其切换为||=false,因为它具有相同的结果,但这在很大程度上取决于偏好。唯一的缺点是赋值会在每次运行
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
打印1:defsum(i)i=i+[2]end$x=[1]sum($x)print$x打印12:defsum(i)i.push(2)end$x=[1]sum($x)print$x后者是修改全局变量$x。为什么它在第二个例子中被修改而不是在第一个例子中?类Array的任何方法(不仅是push)都会发生这种情况吗? 最佳答案 变量范围在这里无关紧要。在第一段代码中,您仅使用赋值运算符=为变量i赋值,而在第二段代码中,您正在修改$x(也称为i)使用破坏性方法push。赋值从不修改任何对象。它只是提供一个名称来引用一个对象。方法要么是破坏性
Ruby中的Fixnum方法.next和.succ有什么区别?看起来它的工作原理是一样的:1.next=>21.succ=>2如果有什么不同,为什么有两种方法做同样的事情? 最佳答案 它们是等价的。Fixnum#succ只是Fixnum#next的同义词。他们甚至在thereferencemanual中共享同一block. 关于ruby-Ruby中.next和.succ的区别,我们在StackOverflow上找到一个类似的问题: https://stacko
我明白了defa(&block)block.call(self)end和defa()yieldselfend导致相同的结果,如果我假设有这样一个blocka{}。我的问题是-因为我偶然发现了一些这样的代码,它是否有任何区别或者是否有任何优势(如果我不使用变量/引用block):defa(&block)yieldselfend这是一个我不理解&block用法的具体案例:defrule(code,name,&block)@rules=[]if@rules.nil?@rules 最佳答案 我能想到的唯一优点就是自省(introspecti
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A