 虽然业界有很多的争论,但是 LiDAR 在目前的 L3/L4 级自动驾驶系统中依然是不可或缺的传感器,因为它可以提供稠密的 3D 点云,非常精确的测量物体在 3D 空间中的位置和形状,而这是摄像头和毫米波雷达很难做到的。那么相应的,基于 LiDAR 点云的感知算法也就成为了近年来自动驾驶研发的重点之一。与图像的感知算法类似,LiDAR 点云的感知算法也分为物体检测(包括跟踪)和语义分割两大类。这篇文章主要关注基于 LiDAR 点云的物体检测算法,语义分割算法留待以后再做介绍。 很多综述性的文章把 LiDAR 点云的物体检测算法粗略分为四类:Multi-view 方法,Voxel 方法,Point 方法,以及 Point 和 Voxel 结合的方法。这种基于分类的综述更像是一个算法图书馆,读者可以根据关键字(或者说关键技术)进行索引,方便于查询和归档,可能更适合于该领域内的工作者。但是我想并不是所有的读者都对这个方向有比较深入的了解,直接讲方法分类和技术细节可能会从一开始就让读者迷失在算法的森林里。 所以,与一般的综述不同,在这篇文章里我以时间为线索,将 LiDAR 点云物体检测的发展历程粗略地划分为了四个时期:萌芽期,起步期,发展期和成落地期。我会从技术发展的角度,结合自己在研究中的一些体会来介绍各种算法。这篇综述的目的不在于包罗这个方向所有的文章,我只会选一些在技术发展的道路上具有重要意义的工作。当然本人水平有限,其中肯定会有疏漏。但是,如果大家读完以后能够对该方向的发展脉络有一个基本的认识,那我想我的目的就达到了。基本概念在进入具体的介绍之前,还是有必要简单说一下一些基本的概念。LiDAR 的输出数据是 3D 点云,每一个点除了包含 X,Y,Z 坐标,还包含一个反射强度 R,类似与毫米波雷达里的 RCS。3D 物体检测的目标是要根据点云数据来找到场景中所有感兴趣的物体,比如自动驾驶场景中的车辆,行人,静态障碍物等等。下图以车辆为例,来说明输出结果的格式。简单来说,检测算法输出多个 3D 矩形框(术语称为 3D BoundingBox,简称 3D BBox),每个框对应一个场景中的物体。3D BBox 可以有多种表示方法,一般最常用的就是用中心点 3D 坐标,长宽高,以及 3D 旋转角度来表示(简单一些的话可以只考虑平面内旋转,也就是下图中的 θ)。检测算法输出的 3D BBox 与人工标注的数据进行对比,一般采用 3D IoU (Intersection over Unoin)来衡量两个 BBox 重合的程度,高于设定的阈值就被认为是一个成功的检测,反之则认为物体没有被检测到(False Negative)。如果在没有物体的区域出现了 BBox 输出,则被认为是一个误检(False Positive)。评测算法会同时考虑这两个指标,给出一个综合的分数,比如 AP(Average Precision)以此为标准来评价算法的优劣。由于不是本文的重点,具体的细节这里就不做赘述了。
虽然业界有很多的争论,但是 LiDAR 在目前的 L3/L4 级自动驾驶系统中依然是不可或缺的传感器,因为它可以提供稠密的 3D 点云,非常精确的测量物体在 3D 空间中的位置和形状,而这是摄像头和毫米波雷达很难做到的。那么相应的,基于 LiDAR 点云的感知算法也就成为了近年来自动驾驶研发的重点之一。与图像的感知算法类似,LiDAR 点云的感知算法也分为物体检测(包括跟踪)和语义分割两大类。这篇文章主要关注基于 LiDAR 点云的物体检测算法,语义分割算法留待以后再做介绍。 很多综述性的文章把 LiDAR 点云的物体检测算法粗略分为四类:Multi-view 方法,Voxel 方法,Point 方法,以及 Point 和 Voxel 结合的方法。这种基于分类的综述更像是一个算法图书馆,读者可以根据关键字(或者说关键技术)进行索引,方便于查询和归档,可能更适合于该领域内的工作者。但是我想并不是所有的读者都对这个方向有比较深入的了解,直接讲方法分类和技术细节可能会从一开始就让读者迷失在算法的森林里。 所以,与一般的综述不同,在这篇文章里我以时间为线索,将 LiDAR 点云物体检测的发展历程粗略地划分为了四个时期:萌芽期,起步期,发展期和成落地期。我会从技术发展的角度,结合自己在研究中的一些体会来介绍各种算法。这篇综述的目的不在于包罗这个方向所有的文章,我只会选一些在技术发展的道路上具有重要意义的工作。当然本人水平有限,其中肯定会有疏漏。但是,如果大家读完以后能够对该方向的发展脉络有一个基本的认识,那我想我的目的就达到了。基本概念在进入具体的介绍之前,还是有必要简单说一下一些基本的概念。LiDAR 的输出数据是 3D 点云,每一个点除了包含 X,Y,Z 坐标,还包含一个反射强度 R,类似与毫米波雷达里的 RCS。3D 物体检测的目标是要根据点云数据来找到场景中所有感兴趣的物体,比如自动驾驶场景中的车辆,行人,静态障碍物等等。下图以车辆为例,来说明输出结果的格式。简单来说,检测算法输出多个 3D 矩形框(术语称为 3D BoundingBox,简称 3D BBox),每个框对应一个场景中的物体。3D BBox 可以有多种表示方法,一般最常用的就是用中心点 3D 坐标,长宽高,以及 3D 旋转角度来表示(简单一些的话可以只考虑平面内旋转,也就是下图中的 θ)。检测算法输出的 3D BBox 与人工标注的数据进行对比,一般采用 3D IoU (Intersection over Unoin)来衡量两个 BBox 重合的程度,高于设定的阈值就被认为是一个成功的检测,反之则认为物体没有被检测到(False Negative)。如果在没有物体的区域出现了 BBox 输出,则被认为是一个误检(False Positive)。评测算法会同时考虑这两个指标,给出一个综合的分数,比如 AP(Average Precision)以此为标准来评价算法的优劣。由于不是本文的重点,具体的细节这里就不做赘述了。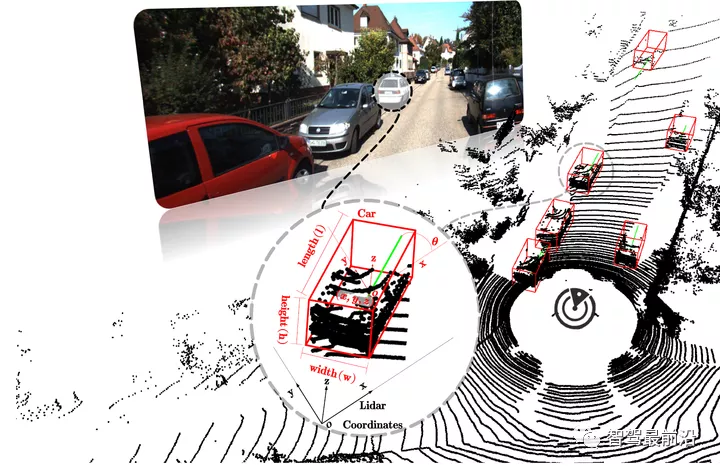 基于 LiDAR 点云的 3D 物体检测示意图萌芽期 (2017 年之前)有了前面的铺垫,下面我们的算法之旅正式开始了。话说物体检测算法的兴起主要来自于计算机视觉领域,自从 2012 年深度学习出现以来,图像和视频中的物体检测算法在性能上有了大幅度的提高,各种经典算法也是层数不穷,比如最早的 R-CNN,到后来的 Faster RCNN,再到 YOLO 以及最新的 CenterNet 等等,可以说已经研究的非常透彻了。那么,在做点云中的物体检测时,人们自然的就会想到要借鉴视觉领域的成功经验。VeloFCN 就是其中的代表性方法。它将 3D 点云转换到与图像相似的正视图(Front View),得到一个「点云伪图像」。这种数据在格式和性质上与图像非常类似,自然的也就可以照搬图像上的物体检测算法。但是这种表示的缺陷也很明显,首先多个点可能映射到图像坐标的同一个位置,这样会造成信息的丢失。更为重要的是,将 3D 的点映射到 2D 平面,丢掉了深度信息,而这个信息对 3D 物体检测来说是非常重要的。因此,人们又想到可以把 3D 点云映射到俯视图(也称作鸟瞰视图,Bird's Eye View, 简称 BEV)。这种映射是非常直观的,你可以简单的认为把 3D 点的高度坐标忽略(将其看作点的特征),从而得到 2D 平面上的数据表示。MV3D 就是将 3D 点云同时映射到正视图和俯视图,并与 2D 图像数据进行融合。以上说的都是数据构建和特征提取,至于后端的检测算法,一般来说这个时期都是采用基于 R-CNN 或者类似的方法。
基于 LiDAR 点云的 3D 物体检测示意图萌芽期 (2017 年之前)有了前面的铺垫,下面我们的算法之旅正式开始了。话说物体检测算法的兴起主要来自于计算机视觉领域,自从 2012 年深度学习出现以来,图像和视频中的物体检测算法在性能上有了大幅度的提高,各种经典算法也是层数不穷,比如最早的 R-CNN,到后来的 Faster RCNN,再到 YOLO 以及最新的 CenterNet 等等,可以说已经研究的非常透彻了。那么,在做点云中的物体检测时,人们自然的就会想到要借鉴视觉领域的成功经验。VeloFCN 就是其中的代表性方法。它将 3D 点云转换到与图像相似的正视图(Front View),得到一个「点云伪图像」。这种数据在格式和性质上与图像非常类似,自然的也就可以照搬图像上的物体检测算法。但是这种表示的缺陷也很明显,首先多个点可能映射到图像坐标的同一个位置,这样会造成信息的丢失。更为重要的是,将 3D 的点映射到 2D 平面,丢掉了深度信息,而这个信息对 3D 物体检测来说是非常重要的。因此,人们又想到可以把 3D 点云映射到俯视图(也称作鸟瞰视图,Bird's Eye View, 简称 BEV)。这种映射是非常直观的,你可以简单的认为把 3D 点的高度坐标忽略(将其看作点的特征),从而得到 2D 平面上的数据表示。MV3D 就是将 3D 点云同时映射到正视图和俯视图,并与 2D 图像数据进行融合。以上说的都是数据构建和特征提取,至于后端的检测算法,一般来说这个时期都是采用基于 R-CNN 或者类似的方法。 MV3D 的多种视图融合起步期(2017 年)时间进入 2017 年,在这个年份里出现了两个在点云物体检测领域堪称里程碑式的工作:VoxelNet 和 PointNet++。这两个工作代表了点云处理的两个基本方向,VoxelNet 将点云量化为网格数据,而 PointNet++ 直接处理非结构化的数据点。下面我会稍微详细的介绍一下这两个方法,因为之后点云物体检测领域几乎所有的方法都离不开这两个工作里的概念。VoxelNet 这个工作是 2017 年由苹果公司的两位研究人员提出的,并且发表在了 CVPR 2018 上(计算机视觉和模式识别领域的顶会)。其思路并不复杂,首先将点云量化到一个均匀的 3D 网格中(下图中的 grouping)。每个网格内部随机采样固定数量的点(不足的就重复),每个点用 7 维特征表示,包括该点的 X,Y,Z 坐标,反射强度 R,以及该点相对网格质心(网格内所有点位置的均值)的位置差 ΔX,ΔY 和 ΔZ。全连接层被用来提取点的特征,然后每个点的特征再与网格内所有点的特征均值进行拼接,得到新的点特征。这种特征的优点在于同时保留了单个点的特性和该点周围一个局部小区域(网格)的特性。这个点特征提取的过程可以重复多次,以增强特征的描述能力(下图中的 Stacked Voxel Feature Encoding)。最终网格内的所有点进行最大池化操作(Max Pooling),以得到一个固定长度的特征向量。以上这些步骤称为特征学习网络,其输出是一个 4D 的 Tensor(对应 X,Y,Z 坐标和特征)。这与一般的图像数据不同(图像是 3D Tensor,只有 X,Y 坐标和特征),因此还没法直接采用图像物体检测的方法。VoxelNet 中采用 3D 卷积对Z维度进行压缩(比如 stride=2)。假设 4D Tensor 的维度为 HxWxDxC,经过若干次 3D 卷积后,Z 维度的大小被压缩为 2(也就是 HxWx2xC'),然后直接将 Z 维度与特征维度合并,生成一个 3D 的 Tensor(HxWx2C')。这就和标准的图像数据格式相似了,因此可以接上图像物体检测网络(比如 Region Proposal Network,RPN)来生成物体检测框,只不过这里生成的是 3D 的检测框。从上面的介绍可以看出,VoxelNet 的框架非常简洁,也是第一个可以真正进行端对端的学习的点云物体检测网络。实验结果表明,这种端对端的方式可以自动地从点云中学习到可用的信息,比手工设计特征的方式更为高效。
MV3D 的多种视图融合起步期(2017 年)时间进入 2017 年,在这个年份里出现了两个在点云物体检测领域堪称里程碑式的工作:VoxelNet 和 PointNet++。这两个工作代表了点云处理的两个基本方向,VoxelNet 将点云量化为网格数据,而 PointNet++ 直接处理非结构化的数据点。下面我会稍微详细的介绍一下这两个方法,因为之后点云物体检测领域几乎所有的方法都离不开这两个工作里的概念。VoxelNet 这个工作是 2017 年由苹果公司的两位研究人员提出的,并且发表在了 CVPR 2018 上(计算机视觉和模式识别领域的顶会)。其思路并不复杂,首先将点云量化到一个均匀的 3D 网格中(下图中的 grouping)。每个网格内部随机采样固定数量的点(不足的就重复),每个点用 7 维特征表示,包括该点的 X,Y,Z 坐标,反射强度 R,以及该点相对网格质心(网格内所有点位置的均值)的位置差 ΔX,ΔY 和 ΔZ。全连接层被用来提取点的特征,然后每个点的特征再与网格内所有点的特征均值进行拼接,得到新的点特征。这种特征的优点在于同时保留了单个点的特性和该点周围一个局部小区域(网格)的特性。这个点特征提取的过程可以重复多次,以增强特征的描述能力(下图中的 Stacked Voxel Feature Encoding)。最终网格内的所有点进行最大池化操作(Max Pooling),以得到一个固定长度的特征向量。以上这些步骤称为特征学习网络,其输出是一个 4D 的 Tensor(对应 X,Y,Z 坐标和特征)。这与一般的图像数据不同(图像是 3D Tensor,只有 X,Y 坐标和特征),因此还没法直接采用图像物体检测的方法。VoxelNet 中采用 3D 卷积对Z维度进行压缩(比如 stride=2)。假设 4D Tensor 的维度为 HxWxDxC,经过若干次 3D 卷积后,Z 维度的大小被压缩为 2(也就是 HxWx2xC'),然后直接将 Z 维度与特征维度合并,生成一个 3D 的 Tensor(HxWx2C')。这就和标准的图像数据格式相似了,因此可以接上图像物体检测网络(比如 Region Proposal Network,RPN)来生成物体检测框,只不过这里生成的是 3D 的检测框。从上面的介绍可以看出,VoxelNet 的框架非常简洁,也是第一个可以真正进行端对端的学习的点云物体检测网络。实验结果表明,这种端对端的方式可以自动地从点云中学习到可用的信息,比手工设计特征的方式更为高效。 VoxelNet 网络结构PointNet++ 该方法的前身是 PointNet,由斯坦福大学的研究者在 2017 年发表,这也是点云处理领域的开创性工作之一。PointNet 处理的是点云分类任务,其主要思路是直接处理原始的点云。除了一些几何变换之外,PointNet 主要有两个操作:MLP(多个全连接层)提取点特征,MaxPooling 得到全局特征。物体分类网络采用全局特征作为输入,而分割网络则同时采用全局特征和点特征。简单来说,你可以把 PointNet 分类网络看做一个分类器,比如可以理解为传统方法中的 SVM。但是要进行物体检测的话,就还需要一个类似于 Sliding Window 的机制,也就是说在场景内的各个位置应用 PointNet 来区分物体和背景,以达到物体检测的效果。当然对于相对稀疏的点云数据来说,这种做法是非常低效的。因此,PointNet 的作者同年就提出了升级版本,也就是 PointNet++。其主要思路是用聚类的方式来产生多个候选区域(每个区域是一个点集),在每个候选区域内采用 PointNet 来提取点的特征。这个过程以一种层级化的方式重复多次,每一次聚类算法输出的多个点集都被当做抽象后的点云再进行下一次处理(Set Abstraction,SA)。这样得到的点特征具有较大的感受野,包含了局部邻域内丰富的上下文信息。最后,在多层 SA 输出的点集上进行PointNet分类,以区分物体和背景。同样的,这个方法也可以做点云分割。
VoxelNet 网络结构PointNet++ 该方法的前身是 PointNet,由斯坦福大学的研究者在 2017 年发表,这也是点云处理领域的开创性工作之一。PointNet 处理的是点云分类任务,其主要思路是直接处理原始的点云。除了一些几何变换之外,PointNet 主要有两个操作:MLP(多个全连接层)提取点特征,MaxPooling 得到全局特征。物体分类网络采用全局特征作为输入,而分割网络则同时采用全局特征和点特征。简单来说,你可以把 PointNet 分类网络看做一个分类器,比如可以理解为传统方法中的 SVM。但是要进行物体检测的话,就还需要一个类似于 Sliding Window 的机制,也就是说在场景内的各个位置应用 PointNet 来区分物体和背景,以达到物体检测的效果。当然对于相对稀疏的点云数据来说,这种做法是非常低效的。因此,PointNet 的作者同年就提出了升级版本,也就是 PointNet++。其主要思路是用聚类的方式来产生多个候选区域(每个区域是一个点集),在每个候选区域内采用 PointNet 来提取点的特征。这个过程以一种层级化的方式重复多次,每一次聚类算法输出的多个点集都被当做抽象后的点云再进行下一次处理(Set Abstraction,SA)。这样得到的点特征具有较大的感受野,包含了局部邻域内丰富的上下文信息。最后,在多层 SA 输出的点集上进行PointNet分类,以区分物体和背景。同样的,这个方法也可以做点云分割。 PointNet 网络结构
PointNet 网络结构 PointNet++ 网络结构与 VoxelNet 相比,PointNet++ 的优点在于:1,没有量化带来的信息损失,也无需调节量化超参数;2,忽略空白区域,避免了无效的计算。但是缺点也显而易见:1,无法利用成熟的基于空间卷积的2D物体检测算法;2,虽然避免了无效计算,但是GPU对于点云的处理效率远低于网格数据,因此实际的运行速度甚至更慢。发展期(2018 年 - 2020 年)在 VoxelNet 和 PointNet++ 相继提出后,3D 物体检测领域迎来了一个快速发展期,很多算法被提出,用来改进这两个工作中的不足。对 Voxel 方法的改进VoxelNet 的主要问题在于数据表示比较低效,中间层的 3D 卷积计算量太大,导致其运行速度只有大约 2FPS(Frame Per Second),远低于实时性的要求,因此后续很多工作针对其运行效率的问题进行了改进。SECOND 采用稀疏卷积策略,避免了空白区域的无效计算,将运行速度提升到了 26 FPS,同时也降低了显存的使用量。PIXOR 提出通过手工设计的方式,将 3D 的 Voxel 压缩到 2D 的 Pixel。这样做避免了 3D 卷积,但是损失了高度方向上的信息,导致检测准确度下降很多。PointPillar 的思路也是 3D 转 2D,也就是将点 3D 云量化到 2D 的 XY 平面网格。但是与 PIXOR 手工设计特征的方式不同,PointPillar 把落到每个网格内的点直接叠放在一起,形象的称其为柱子(Pillar),然后利用与 PointNet 相似的方式来学习特征,最后再把学到的特征向量映射回网格坐标上,得到与图像类似的数据。这样做一来避免了 VoxelNet 中的 3D 卷积和空白区域的无效计算(运行速度达到 62 FPS),二来避免了手工设计特征导致信息丢失和网络适应性不强的问题,可以说是很巧妙的思路。不好的方面是,点特征的学习被限制在网格内,无法有效的提取邻域的上下文信息。
PointNet++ 网络结构与 VoxelNet 相比,PointNet++ 的优点在于:1,没有量化带来的信息损失,也无需调节量化超参数;2,忽略空白区域,避免了无效的计算。但是缺点也显而易见:1,无法利用成熟的基于空间卷积的2D物体检测算法;2,虽然避免了无效计算,但是GPU对于点云的处理效率远低于网格数据,因此实际的运行速度甚至更慢。发展期(2018 年 - 2020 年)在 VoxelNet 和 PointNet++ 相继提出后,3D 物体检测领域迎来了一个快速发展期,很多算法被提出,用来改进这两个工作中的不足。对 Voxel 方法的改进VoxelNet 的主要问题在于数据表示比较低效,中间层的 3D 卷积计算量太大,导致其运行速度只有大约 2FPS(Frame Per Second),远低于实时性的要求,因此后续很多工作针对其运行效率的问题进行了改进。SECOND 采用稀疏卷积策略,避免了空白区域的无效计算,将运行速度提升到了 26 FPS,同时也降低了显存的使用量。PIXOR 提出通过手工设计的方式,将 3D 的 Voxel 压缩到 2D 的 Pixel。这样做避免了 3D 卷积,但是损失了高度方向上的信息,导致检测准确度下降很多。PointPillar 的思路也是 3D 转 2D,也就是将点 3D 云量化到 2D 的 XY 平面网格。但是与 PIXOR 手工设计特征的方式不同,PointPillar 把落到每个网格内的点直接叠放在一起,形象的称其为柱子(Pillar),然后利用与 PointNet 相似的方式来学习特征,最后再把学到的特征向量映射回网格坐标上,得到与图像类似的数据。这样做一来避免了 VoxelNet 中的 3D 卷积和空白区域的无效计算(运行速度达到 62 FPS),二来避免了手工设计特征导致信息丢失和网络适应性不强的问题,可以说是很巧妙的思路。不好的方面是,点特征的学习被限制在网格内,无法有效的提取邻域的上下文信息。 PointPillar 网络结构对 Point 方法的改进PointNet++ 采用基于聚类的方法来层级化的提取邻域特征以及获得物体候选,这种做法效率比较低,而且也很难做并行加速。而这恰巧是传统的 2D 卷积网络的强项,因此后续的工作逐渐将 2D 物体检测算法中的一些思路拿过来,用来解决 PointNet++ 中的问题。Point-RCNN 首先在这个方向了进行了探索,可以称得上 3D 物体检测领域的又一个里程碑式的工作。从名字上就能看出,这个方法将点云处理和 2D 物体检测领域的开山之作 Faster RCNN 结合了起来。首先,PointNet++ 被用来提取点特征。点特征被用来进行前景分割,以区分物体上的点和背景点。同时,每个前景点也会输出一个 3D 候选 BBox。接下来就是将候选 BBox 内的点再做进一步的特征提取,输出 BBox 所属的物体类别,并且对其位置,大小进行细化。看到这里,熟悉 2D 物体检测的朋友肯定会说,这不就是一个典型的两阶段检测模型嘛。没错,但不同的是,Point-RCNN 只在前景点上生成候选,这样避免了 3D 空间中生成稠密候选框所带来的巨大计算量。尽管如此,作为一个两阶段的检测器,加上 PointNet++ 本身较大的计算量,Point-RCNN的运行效率依然不高,只有大约13FPS 。Point-RCNN后来被扩展为Part-A2[11],速度和准确度都有一定的提升。
PointPillar 网络结构对 Point 方法的改进PointNet++ 采用基于聚类的方法来层级化的提取邻域特征以及获得物体候选,这种做法效率比较低,而且也很难做并行加速。而这恰巧是传统的 2D 卷积网络的强项,因此后续的工作逐渐将 2D 物体检测算法中的一些思路拿过来,用来解决 PointNet++ 中的问题。Point-RCNN 首先在这个方向了进行了探索,可以称得上 3D 物体检测领域的又一个里程碑式的工作。从名字上就能看出,这个方法将点云处理和 2D 物体检测领域的开山之作 Faster RCNN 结合了起来。首先,PointNet++ 被用来提取点特征。点特征被用来进行前景分割,以区分物体上的点和背景点。同时,每个前景点也会输出一个 3D 候选 BBox。接下来就是将候选 BBox 内的点再做进一步的特征提取,输出 BBox 所属的物体类别,并且对其位置,大小进行细化。看到这里,熟悉 2D 物体检测的朋友肯定会说,这不就是一个典型的两阶段检测模型嘛。没错,但不同的是,Point-RCNN 只在前景点上生成候选,这样避免了 3D 空间中生成稠密候选框所带来的巨大计算量。尽管如此,作为一个两阶段的检测器,加上 PointNet++ 本身较大的计算量,Point-RCNN的运行效率依然不高,只有大约13FPS 。Point-RCNN后来被扩展为Part-A2[11],速度和准确度都有一定的提升。 Point-RCNN 网络结构3D-SSD 通过对之前 Point-based 方法的各个模块进行分析,得出结论:FP(Feature Propagation)层和细化层(Refinement)是系统运行速度的瓶颈。FP 层的作用是将 SA 层抽象后的点特征再映射回原始的点云,可以理解为上图中 Point-RCNN 的 Point Cloud Decoder。这一步非常必要,因为 SA 输出的抽象点并不能很好的覆盖所有的物体,会导致很大的信息丢失。3D-SSD 提出了一种新的聚类方法,同时考虑点与点之间在几何空间和特征空间的相似度。通过这种改进的聚类方法,SA 层的输出可以直接用来生成物体 Proposal,避免了 FP 层带来的大计算量。同时,为了避免 Refinement 阶段的 Region Pooling,3D-SSD 直接采用 SA 输出的代表点,利用前面提到了改进聚类算法找到其邻域点,用一个简单的 MLP 来预测类别和物体框 3D BBox。3D-SSD 可以认为是一个 Anchor-Free 的单阶段检测器,这也符合整个物体检测领域的发展趋势。通过以上改进,3D-SSD 的运行速度可以达到 25FPS。
Point-RCNN 网络结构3D-SSD 通过对之前 Point-based 方法的各个模块进行分析,得出结论:FP(Feature Propagation)层和细化层(Refinement)是系统运行速度的瓶颈。FP 层的作用是将 SA 层抽象后的点特征再映射回原始的点云,可以理解为上图中 Point-RCNN 的 Point Cloud Decoder。这一步非常必要,因为 SA 输出的抽象点并不能很好的覆盖所有的物体,会导致很大的信息丢失。3D-SSD 提出了一种新的聚类方法,同时考虑点与点之间在几何空间和特征空间的相似度。通过这种改进的聚类方法,SA 层的输出可以直接用来生成物体 Proposal,避免了 FP 层带来的大计算量。同时,为了避免 Refinement 阶段的 Region Pooling,3D-SSD 直接采用 SA 输出的代表点,利用前面提到了改进聚类算法找到其邻域点,用一个简单的 MLP 来预测类别和物体框 3D BBox。3D-SSD 可以认为是一个 Anchor-Free 的单阶段检测器,这也符合整个物体检测领域的发展趋势。通过以上改进,3D-SSD 的运行速度可以达到 25FPS。 3D-SSD 网络结构对于非结构化的点云数据,用图模型来表示也是一种很自然的想法。但是图神经网络相对比较复杂,虽然近些年发展也很快,但是在 3D 物体检测上的工作并不多。PointGNN 是其中一个比较典型的工作。其流程主要分为三步:首先根据一个预设的距离阈值来建立图模型;然后更新每个顶点以获取邻域点的信息,用来检测物体类别和位置,最后融合多个顶点输出的 3D 物体框,作为最终的检测结果。这种基于图模型的方法在思路上非常新颖,但是训练和推理过程的计算量太大。论文中指出完成一次训练需要花费将近一周的时间,这大大降低了该类方法的实用性。
3D-SSD 网络结构对于非结构化的点云数据,用图模型来表示也是一种很自然的想法。但是图神经网络相对比较复杂,虽然近些年发展也很快,但是在 3D 物体检测上的工作并不多。PointGNN 是其中一个比较典型的工作。其流程主要分为三步:首先根据一个预设的距离阈值来建立图模型;然后更新每个顶点以获取邻域点的信息,用来检测物体类别和位置,最后融合多个顶点输出的 3D 物体框,作为最终的检测结果。这种基于图模型的方法在思路上非常新颖,但是训练和推理过程的计算量太大。论文中指出完成一次训练需要花费将近一周的时间,这大大降低了该类方法的实用性。 PointGNN 网络结构Voxel 和 Point 方法的融合以上回顾了 Voxel-based 和 Point-based 两个主要方向上的改进。其实,在这个阶段,研究者已经有意无意的将两种策略进行融合,以取长补短。PointPillar 就是一个例子,虽然点云被按照类似 Voxel 的方式进行量化,但是点特征的学习是采用类似 PointNet 的方式。虽然说算法的性能并不是最好的,但是其思路还是非常值得思考的。沿着这个方向,后续又出现了很多不错的工作。在介绍更多的工作之前,有必要来总结一下之前的代表性方法,看看它们在检测率和速度上的对比如何。这里我们采用行业内最流行的 KITTI 数据库来作为评测的基准。至于更大规模和更针对自动驾驶应用的 nuScenes 和 Waymo 数据库,我们留在后面再讨论。KITTI 采用 Velodyne 激光雷达,在城市道路环境下采集数据,其 3D 物体识别任务的类别包括车辆,行人和骑车的人。因为早期一些算法只提供了车辆检测的正确率,因此这里我们就只对比车辆这个类别。这里算法的准确度采用中等难度测试集上的 AP 作为指标,而速度则采用 FPS 来衡量,这两个指标都是越高越好。
PointGNN 网络结构Voxel 和 Point 方法的融合以上回顾了 Voxel-based 和 Point-based 两个主要方向上的改进。其实,在这个阶段,研究者已经有意无意的将两种策略进行融合,以取长补短。PointPillar 就是一个例子,虽然点云被按照类似 Voxel 的方式进行量化,但是点特征的学习是采用类似 PointNet 的方式。虽然说算法的性能并不是最好的,但是其思路还是非常值得思考的。沿着这个方向,后续又出现了很多不错的工作。在介绍更多的工作之前,有必要来总结一下之前的代表性方法,看看它们在检测率和速度上的对比如何。这里我们采用行业内最流行的 KITTI 数据库来作为评测的基准。至于更大规模和更针对自动驾驶应用的 nuScenes 和 Waymo 数据库,我们留在后面再讨论。KITTI 采用 Velodyne 激光雷达,在城市道路环境下采集数据,其 3D 物体识别任务的类别包括车辆,行人和骑车的人。因为早期一些算法只提供了车辆检测的正确率,因此这里我们就只对比车辆这个类别。这里算法的准确度采用中等难度测试集上的 AP 作为指标,而速度则采用 FPS 来衡量,这两个指标都是越高越好。| VoxelNet | SECOND | PointPillar | PointRCNN | 3D-SSD | |
| 准确度(AP) | 64.17% | 75.96% | 74.31% | 75.64% | 79.57% |
| 速度(FPS) | 2.0 | 26.3 | 62.0 | 10.0 | 25.0 |
 PV-CNN 网络结构类似的,PV-RCNN 的一个分支将点云量化到不同分辨率的 Voxel,以提取上下文特征和生成 3D 物体候选。另外一条分支上采用类似于 PointNet++ 中 Set Abstraction 的操作来提取点特征。这里比较特别的是,每个点的领域点并不是原始点云中的点,而是 Voxel 中的点。由于 Voxel 中的点具有多分辨率的上下文信息,点特征提取也就同时兼顾了单个点以及邻域信息,这与 PV-CNN 中的思路是类似的。值得一提的是,PV-RCNN 和 Fast Point RCNN 都属于两阶段的检测方法,有一个 ROI Pooling 的步骤,因此运行速度会收到影响(PV-RCNN 只有 12.5 FPS,Fast Point R-CNN 也只有 16.7 FPS)。
PV-CNN 网络结构类似的,PV-RCNN 的一个分支将点云量化到不同分辨率的 Voxel,以提取上下文特征和生成 3D 物体候选。另外一条分支上采用类似于 PointNet++ 中 Set Abstraction 的操作来提取点特征。这里比较特别的是,每个点的领域点并不是原始点云中的点,而是 Voxel 中的点。由于 Voxel 中的点具有多分辨率的上下文信息,点特征提取也就同时兼顾了单个点以及邻域信息,这与 PV-CNN 中的思路是类似的。值得一提的是,PV-RCNN 和 Fast Point RCNN 都属于两阶段的检测方法,有一个 ROI Pooling 的步骤,因此运行速度会收到影响(PV-RCNN 只有 12.5 FPS,Fast Point R-CNN 也只有 16.7 FPS)。 PV-RCNN 网络结构SA-SSD 通过附加的前景分割和物体中心点估计任务引导 Voxel 分支去更好的学习点特征和利用点之间的空间关系,同时也避免了 3D 物体候选框和 ROI Pooling 步骤。作为一个单阶段的检测器,SA-SSD 可以达到 25 FPS,准确度也仅比 PV-RCNN 略低(79.79% vs. 81.43%)。
PV-RCNN 网络结构SA-SSD 通过附加的前景分割和物体中心点估计任务引导 Voxel 分支去更好的学习点特征和利用点之间的空间关系,同时也避免了 3D 物体候选框和 ROI Pooling 步骤。作为一个单阶段的检测器,SA-SSD 可以达到 25 FPS,准确度也仅比 PV-RCNN 略低(79.79% vs. 81.43%)。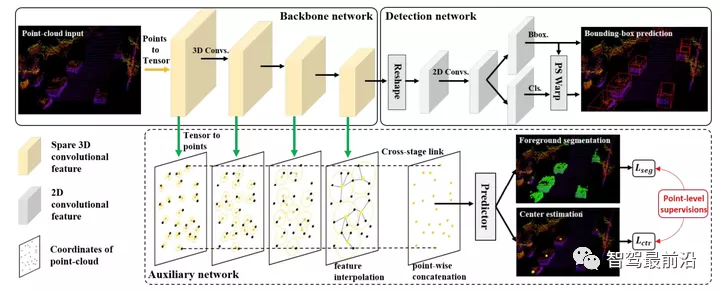 SA-SSD 网络结构落地期(2020 年至今)在之前的快速发展期中,3D 物体检测的各种策略都被充分的研究和实验,人们也获得了很多宝贵的经验。那么,下一步很自然就是需要确定最优的策略,以及如何将算法与实际的应用相结合。因此,在这一阶段,研究的重心开始往算法的实用性上和可落地性上转移。针对自动驾驶应用来说,基于激光雷达的 3D 物体检测一方面是重要的感知信号来源,是自动驾驶系统的核心之一,因此我们需要充分的考虑实时性和准确性的平衡。另一方面,激光雷达在很多时候会作为辅助的传感器来辅助离线的数据标注。比如,毫米波雷达的点云非常稀疏,底层数据又无法直观的理解,因此很难在其上进行精确的物体标注。这个时候激光雷达或者摄像头的辅助就变得非常重要。一般来说,自动的物体检测算法会和人工标注进行结合,以提高标注效率。在这种应用中,最关注的是检测算法的准确度而不是速度。因此,个人认为现阶段 3D 物体检测的发展有两个趋势:一个是追求速度和准确度的平衡,另一个是在保证一定速度的前提下最大化准确度。前者一般会采用 Voxel 加单阶段检测器,后者一般会融合 Voxel 和 Point,甚至采用两阶段的检测器,以获得更为精细的物体框。下面结合几个 2021 年最新的工作,来做进一步的分析。SIENet 是一个基于 Voxel 和 Point 融合的两阶段检测方法,其融合策略与 PV-RCNN 相似。为了解决远处物体点云相对稀疏的问题,SIENet 采用了一个附加分支,将 Voxel 的网格看做额外的点,以此来对远处物体进行补全。SIENet 在 KITTI 车辆检测上的 AP 为 81.71%,但是速度只有 12.5 FPS,基本上与 PV-RCNN 相当。
SA-SSD 网络结构落地期(2020 年至今)在之前的快速发展期中,3D 物体检测的各种策略都被充分的研究和实验,人们也获得了很多宝贵的经验。那么,下一步很自然就是需要确定最优的策略,以及如何将算法与实际的应用相结合。因此,在这一阶段,研究的重心开始往算法的实用性上和可落地性上转移。针对自动驾驶应用来说,基于激光雷达的 3D 物体检测一方面是重要的感知信号来源,是自动驾驶系统的核心之一,因此我们需要充分的考虑实时性和准确性的平衡。另一方面,激光雷达在很多时候会作为辅助的传感器来辅助离线的数据标注。比如,毫米波雷达的点云非常稀疏,底层数据又无法直观的理解,因此很难在其上进行精确的物体标注。这个时候激光雷达或者摄像头的辅助就变得非常重要。一般来说,自动的物体检测算法会和人工标注进行结合,以提高标注效率。在这种应用中,最关注的是检测算法的准确度而不是速度。因此,个人认为现阶段 3D 物体检测的发展有两个趋势:一个是追求速度和准确度的平衡,另一个是在保证一定速度的前提下最大化准确度。前者一般会采用 Voxel 加单阶段检测器,后者一般会融合 Voxel 和 Point,甚至采用两阶段的检测器,以获得更为精细的物体框。下面结合几个 2021 年最新的工作,来做进一步的分析。SIENet 是一个基于 Voxel 和 Point 融合的两阶段检测方法,其融合策略与 PV-RCNN 相似。为了解决远处物体点云相对稀疏的问题,SIENet 采用了一个附加分支,将 Voxel 的网格看做额外的点,以此来对远处物体进行补全。SIENet 在 KITTI 车辆检测上的 AP 为 81.71%,但是速度只有 12.5 FPS,基本上与 PV-RCNN 相当。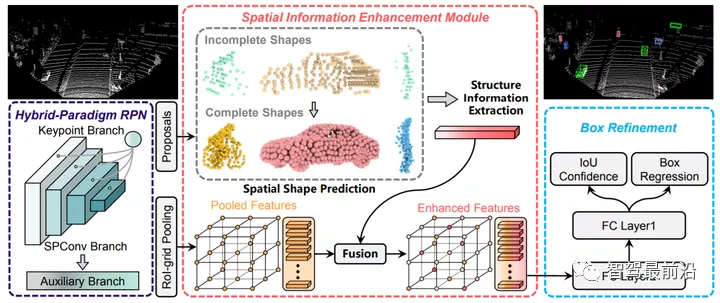 SIENet 网络结构Voxel R-CNN 也是一个两阶段检测器,但是只采用了 Voxel 来做特征提取,其结构更加简洁。通过一个特别设计的 Voxel ROI Pooling 模块,该方法可以进一步提高物体检测的精确度。其余的部分与一般的基于 Voxel 方法非常相似,这里就不详细描述了。Voxel RCNN 在 KITTI 车辆检测上的 AP 为81.62%,与 SIENet 相当,但是速度提升了一倍,达到 25.2 FPS。
SIENet 网络结构Voxel R-CNN 也是一个两阶段检测器,但是只采用了 Voxel 来做特征提取,其结构更加简洁。通过一个特别设计的 Voxel ROI Pooling 模块,该方法可以进一步提高物体检测的精确度。其余的部分与一般的基于 Voxel 方法非常相似,这里就不详细描述了。Voxel RCNN 在 KITTI 车辆检测上的 AP 为81.62%,与 SIENet 相当,但是速度提升了一倍,达到 25.2 FPS。 Voxel R-CNN 网络结构 CIA-SSD 是一个基于 Voxel 的单阶段检测方法。其特征提取阶段与 SECOND 类似,都是采用稀疏 3D 卷积。不同的是 CIA-SSD 将网格内点的均值作为起始特征(没有采用 VoxelNet 中的多阶段 MLP),而且通过不断降低空间分辨率来进一步减少计算量,最后将Z方向的特征拼接以得到 2D 特征图(类似 VoxelNet 中的做法)。作为一个单阶段的检测器,CIA-SSD 借鉴了图像物体检测领域的一些技巧。比如,为了更好的提取空间和语义特征,CIA-SSD 采用了一种类似于 Feature Pyramid Network (FPN)的结构,当然这里的细节设计稍微复杂一些。此外,为了解决单阶段检测器分类置信度和定位准确度之间的差异问题,CIA- SSD 采用了 IoU 预测分支,以修正分类的置信度和辅助 NMS。结合以上这些策略,CIA-SSD 在 KITTI 车辆检测的 AP 达到 80.28%,速度为 33 FPS。CIA-SSD 之后被扩展为 SE-SSD,速度不变,AP 提升到 82.54%,这其实已经超越了基于 Voxel 和 Point 融合的两阶段检测器。
Voxel R-CNN 网络结构 CIA-SSD 是一个基于 Voxel 的单阶段检测方法。其特征提取阶段与 SECOND 类似,都是采用稀疏 3D 卷积。不同的是 CIA-SSD 将网格内点的均值作为起始特征(没有采用 VoxelNet 中的多阶段 MLP),而且通过不断降低空间分辨率来进一步减少计算量,最后将Z方向的特征拼接以得到 2D 特征图(类似 VoxelNet 中的做法)。作为一个单阶段的检测器,CIA-SSD 借鉴了图像物体检测领域的一些技巧。比如,为了更好的提取空间和语义特征,CIA-SSD 采用了一种类似于 Feature Pyramid Network (FPN)的结构,当然这里的细节设计稍微复杂一些。此外,为了解决单阶段检测器分类置信度和定位准确度之间的差异问题,CIA- SSD 采用了 IoU 预测分支,以修正分类的置信度和辅助 NMS。结合以上这些策略,CIA-SSD 在 KITTI 车辆检测的 AP 达到 80.28%,速度为 33 FPS。CIA-SSD 之后被扩展为 SE-SSD,速度不变,AP 提升到 82.54%,这其实已经超越了基于 Voxel 和 Point 融合的两阶段检测器。 CIA-SSD 网络结构新的数据库和基准评测以上关于检测准确度和速度的分析都是基于 KITTI 数据库。近两年来,为了更好的评测 3D 物体检测算法,并且更加贴近自动驾驶场景,工业界构建了两个更大规模的数据库:Waymo Open Dataset 和 NuScenes,其数据量比 KITTI高出两个量级。这两个数据库上都组织了 3D 物体识别竞赛,使得业界的研究和工程人员可以清楚的了解当前最实用的技术。尤其是 2021 年的 Waymo 3D 物体识别竞赛,还特别增加了对运行时间的要求,进一步的强调了算法的可落地性。从近两届比赛获胜的算法来看,基于 Voxel 的单阶段方法成为主流,这也与图像物体检测领域的发展趋势相契合。前文介绍的很多技巧,比如轻量级的 Voxel 特征提取,稀疏 3D 卷积,FPN,IoU 预测分支等等,都在获胜的算法中有所体现。这从另一个侧面说明了当前技术的最高水平,也为 3D 物体检测领域的进一步发展提供了方向。
CIA-SSD 网络结构新的数据库和基准评测以上关于检测准确度和速度的分析都是基于 KITTI 数据库。近两年来,为了更好的评测 3D 物体检测算法,并且更加贴近自动驾驶场景,工业界构建了两个更大规模的数据库:Waymo Open Dataset 和 NuScenes,其数据量比 KITTI高出两个量级。这两个数据库上都组织了 3D 物体识别竞赛,使得业界的研究和工程人员可以清楚的了解当前最实用的技术。尤其是 2021 年的 Waymo 3D 物体识别竞赛,还特别增加了对运行时间的要求,进一步的强调了算法的可落地性。从近两届比赛获胜的算法来看,基于 Voxel 的单阶段方法成为主流,这也与图像物体检测领域的发展趋势相契合。前文介绍的很多技巧,比如轻量级的 Voxel 特征提取,稀疏 3D 卷积,FPN,IoU 预测分支等等,都在获胜的算法中有所体现。这从另一个侧面说明了当前技术的最高水平,也为 3D 物体检测领域的进一步发展提供了方向。 我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我想知道我的代码是否在rspec下运行。这可能吗?原因是我正在加载一些错误记录器,这些记录器在测试期间会被故意错误(expect{x}.toraise_error)弄得乱七八糟。我查看了我的ENV变量,没有(明显的)测试环境变量的迹象。 最佳答案 在spec_helper.rb的开头添加:ENV['RACK_ENV']='test'现在您可以在代码中检查RACK_ENV是否经过测试。 关于ruby-检测由RSpec、Ruby运行的代码,我们在StackOverflow上找到一个类似的问题