1.已经确定研究的基因,但是想探索他潜在的功能,可以通过跟这个基因表达最相关的基因来反推他的功能,这种方法在英语中称为guilt of association,协同犯罪。
2.我们的注释方法依赖于TCGA大样本,既然他可以注释基因,那么任何跟肿瘤相关的基因都可以被注释,包括长链非编码RNA
下面操作开始:
load(file = "exprSet_arrange.Rdata")
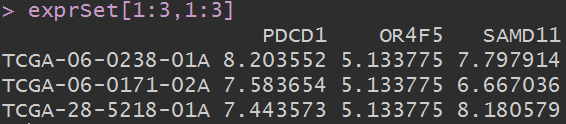
exprSet[1:3,1:3]
这个数据依然是行是样本,列是基因。
将第一行目的基因跟其他行的编码基因批量做相关性分析,得到相关性系数以及p值 需要大概30s左右的时间。
y <- as.numeric(exprSet[,"PDCD1"])
colnames <- colnames(exprSet)
cor_data_df <- data.frame(colnames)
for (i in 1:length(colnames)){
test <- cor.test(as.numeric(exprSet[,i]),y,type="spearman")
cor_data_df[i,2] <- test$estimate
cor_data_df[i,3] <- test$p.value
}
names(cor_data_df) <- c("symbol","correlation","pvalue")
查看这个数据结构
head(cor_data_df)
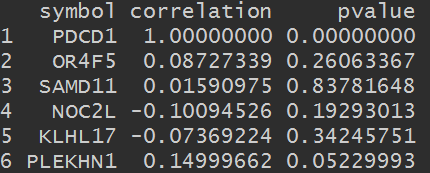
筛选p值小于0.05,按照相关性系数绝对值选前500个的基因, 数量可以自己定
library(dplyr)
library(tidyr)
cor_data_sig <- cor_data_df %>%
filter(pvalue < 0.05) %>%
arrange(desc(abs(correlation)))%>%
dplyr::slice(1:500)
用到的方法在以前的图有毒系列里面 图有毒系列之二
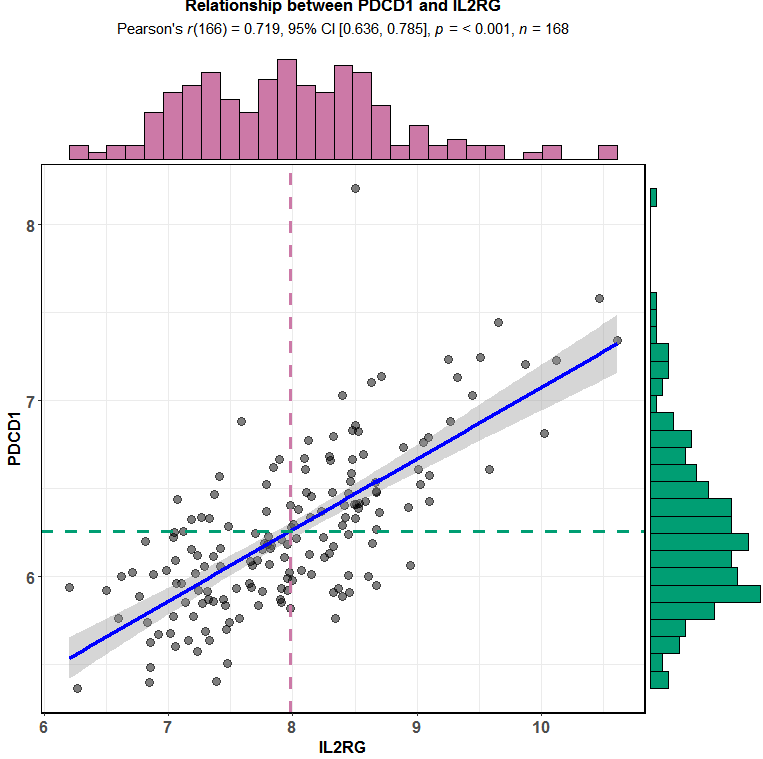
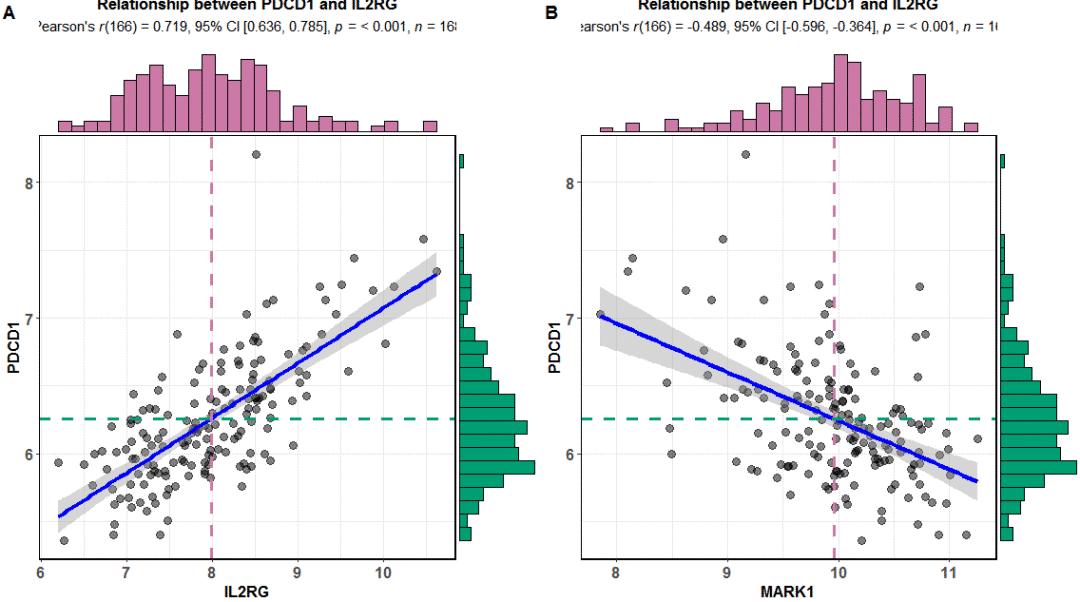
正相关的选取IL2RG
library(ggstatsplot)
ggscatterstats(data = exprSet,
y = PDCD1,
x = IL2RG,
centrality.para = "mean",
margins = "both",
xfill = "#CC79A7",
yfill = "#009E73",
marginal.type = "histogram",
title = "Relationship between PDCD1 and IL2RG")
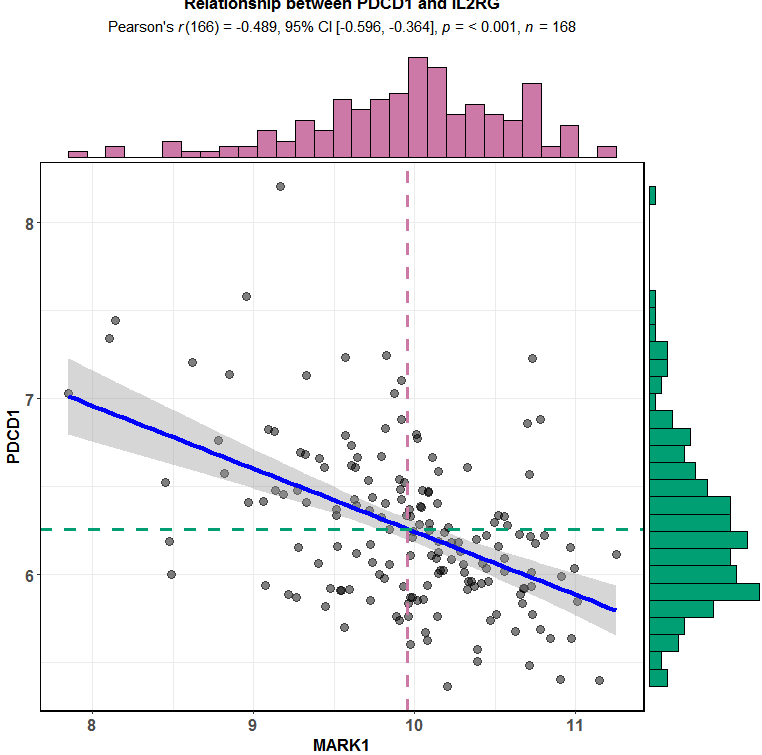
负相关的选取MARK1
library(ggstatsplot)
ggscatterstats(data = exprSet,
y = PDCD1,
x = MARK1,
centrality.para = "mean",
margins = "both",
xfill = "#CC79A7",
yfill = "#009E73",
marginal.type = "histogram",
title = "Relationship between PDCD1 and IL2RG")
我们还可以用cowplot拼图
library(cowplot)
p1 <- ggscatterstats(data = exprSet,
y = PDCD1,
x = IL2RG,
centrality.para = "mean",
margins = "both",
xfill = "#CC79A7",
yfill = "#009E73",
marginal.type = "histogram",
title = "Relationship between PDCD1 and IL2RG")
p2 <- ggscatterstats(data = exprSet,
y = PDCD1,
x = MARK1,
centrality.para = "mean",
margins = "both",
xfill = "#CC79A7",
yfill = "#009E73",
marginal.type = "histogram",
title = "Relationship between PDCD1 and IL2RG")
plot_grid(p1,p2,nrow = 1,labels = LETTERS[1:2])
setwd("/home/data/t040413/ipf/gse135893_20_PF_10_control_scRNAseq")
getwd()
#install.packages("ggside") #.libPaths(c("/home/data/t040413/R/yll/usr/local/lib/R/site-library", "/home/data/t040413/R/x86_64-pc-linux-gnu-library/4.2", "/usr/local/lib/R/library"))
.libPaths(c("/home/data/t040413/R/yll/usr/local/lib/R/site-library", "/home/data/t040413/R/x86_64-pc-linux-gnu-library/4.2", "/usr/local/lib/R/library"))
library(ggstatsplot)
load("/home/data/t040413/ipf/gse135893_20_PF_10_control_scRNAseq/mydata_for_gpx3_ecm_association.rds")
head(mydata)
ggscatterstats(data =mydata,
y = ECM_Score,
x = GPX3,
centrality.para = "mean",
margins = "both",
xfill = "#CC79A7",
yfill = "#009E73",
marginal.type = "histogram",
title = "Relationship between GPX3 and ECM_Score from fibroblasts in GSE135895")
.libPaths(c("/home/data/refdir/Rlib",
"/home/data/t040413/R/x86_64-pc-linux-gnu-library/4.2",
"/usr/local/lib/R/library"))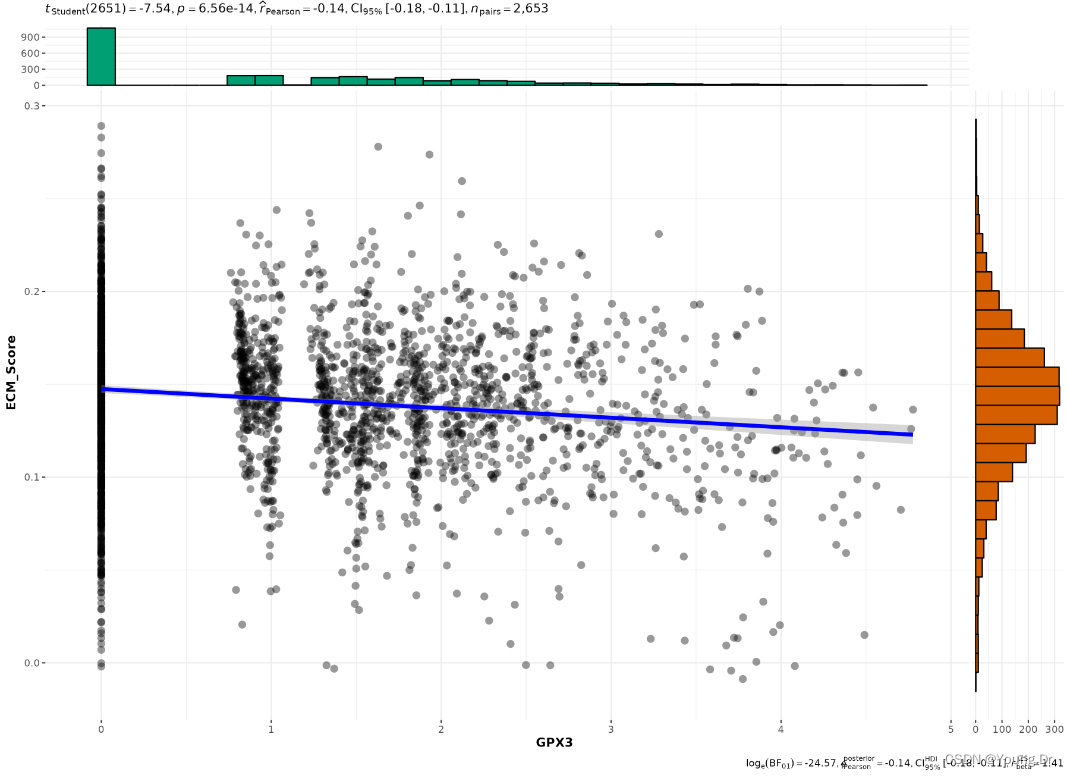
既然确定了相关性是正确的,那么我们用我们筛选的基因进行富集分析就可以反推这个基因的功能
library(clusterProfiler)
#获得基因列表
library(stringr)
gene <- str_trim(cor_data_sig$symbol,'both')
#基因名称转换,返回的是数据框
gene = bitr(gene, fromType="SYMBOL", toType="ENTREZID", OrgDb="org.Hs.eg.db")
go <- enrichGO(gene = gene$ENTREZID, OrgDb = "org.Hs.eg.db", ont="all")
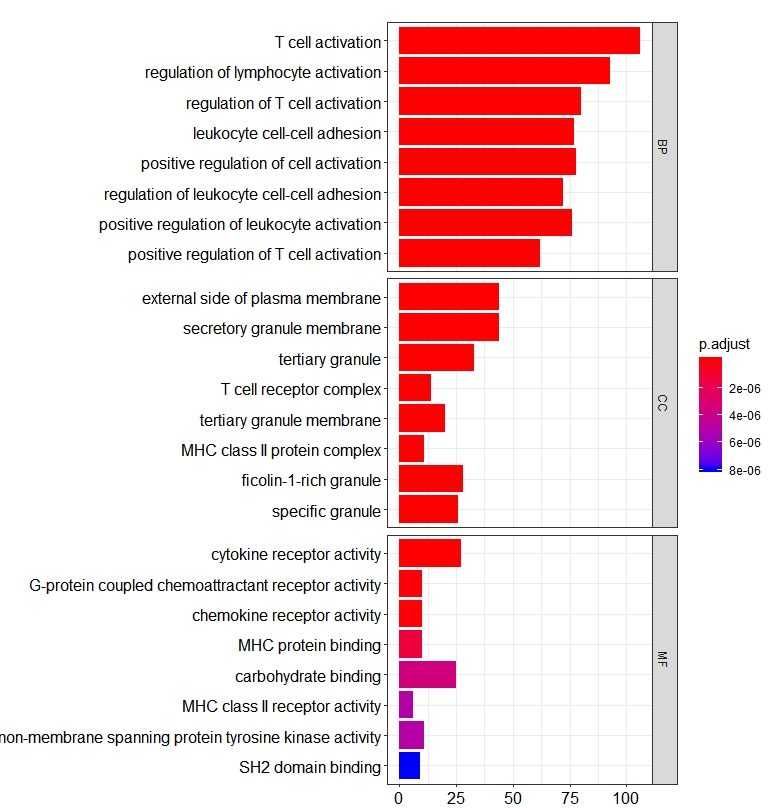
这里因为是计算的所有GO分析的三个分类,所以可以合并作图
这是条形图
barplot(go, split="ONTOLOGY")+ facet_grid(ONTOLOGY~., scale="free")
这是气泡图
dotplot(go, split="ONTOLOGY")+ facet_grid(ONTOLOGY~., scale="free")
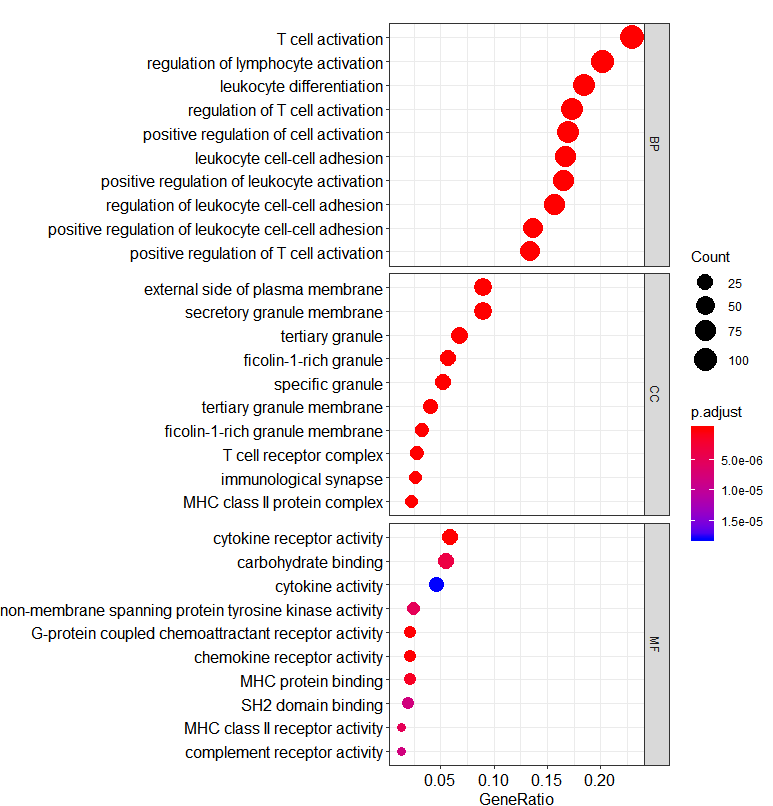
这时候,我们能推断PDCD1这个基因主要参与T细胞激活,细胞因子受体活性调剂等功能,大致跟她本身的功能是一致的。
这种方法,即使是非编码基因也可以注释出来,想到长链非编码基因的数量,真是钱途无量。

欢迎关注微信:生信小博士
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
点向量坐标矩阵的几何意义介绍旋转矩阵的几何含义之前,先介绍一下点向量坐标矩阵的几何含义点:在一维空间下就是一个标量,如同一条直线上,以任意某一个位置为0点,以一定的尺度间隔为1,2,3...,相反方向为-1,-2,-3...;如此就形成了一维坐标系,这时候任何一个点都可以用一个数值表示,如点p1=5,即即从原点出发沿着x轴正方向移动5个尺度;点p2=-3,负方向移动3个尺度; 在一维坐标系上过原点做垂直于一维坐标系的直线,则形成了二维坐标系,此时描述一个点需要两个数值来表示点p3=(3,2),即从原点出发沿着x轴正方向移动3个尺度,在此基础上沿着y轴正方向移动两个尺度的位置就是点p3。
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
假设您有一个可执行文件foo.rb,其库bar.rb的布局如下:/bin/foo.rb/lib/bar.rb在foo.rb的header中放置以下要求以在bar.rb中引入功能:requireFile.dirname(__FILE__)+"../lib/bar.rb"只要对foo.rb的所有调用都是直接的,这就可以正常工作。如果你把$HOME/project和符号链接(symboliclink)foo.rb放入$HOME/usr/bin,然后__FILE__解析为$HOME/usr/bin/foo.rb,因此无法找到bar.rb关于foo.rb的目录名.我意识到像rubygems这
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
术语中文解释Ability原子化服务帮助用户完成任务的原子化服务,和用户的意图进行关联。Fulfillment服务履行通过图标,卡片,语音等形式呈现用户意图。开发者通过接口的方式,处理用户意图,返回内容。Intent意图用于表达用户想要达成的目标或完成的任务。HUAWEIAssistant智能助手“无微不智”的个人助手,通过不断的学习用户的使用习惯,不断的为用户提供贴心的精准的便捷的个性化服务。AISearch全局搜索用户可快速搜索关键词,与之匹配的原子化服务则会出现在搜索结果中。SmartService智慧服务用户订阅原子化服务,在到达特定触发条件(时间、地点、事件)后,卡片推送至用户智能助
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
目录一.大致如下常见问题:(1)找不到程序所依赖的Qt库version`Qt_5'notfound(requiredby(2)CouldnotLoadtheQtplatformplugin"xcb"in""eventhoughitwasfound(3)打包到在不同的linux系统下,或者打包到高版本的相同系统下,运行程序时,直接提示段错误即segmentationfault,或者Illegalinstruction(coredumped)非法指令(4)ldd应用程序或者库,查看运行所依赖的库时,直接报段错误二.问题逐个分析,得出解决方法:(1)找不到程序所依赖的Qt库version`Qt_5'