在线体验:Seata实验室
相信 youlai-mall 的实验室大家有曾在项目中见到过,但应该都还处于陌生的阶段,毕竟在此之前实验室多是以概念般的形式存在,所以我想借着此次的机会,对其进行一个详细的说明。
实验室模块的建立初衷和开源项目的成立一致的,都是为了提升开发成员的技术能力,只不过开源项目是从技术栈广度上(全栈),而实验室则是从技术栈深度方面切入,更重要的它是一种更深刻而又高效的学习方式。为什么能够这么说?因为实验室是结合真实的业务场景把Seata分布式事务能力可视化,通过现象去看本质(原理和源码),不再是被动式输入的短期记忆学习。
实验室未来计划是将工作和面试常见的中间件(Spring、MyBatis、Redis、Seata、MQ、MySQL、ES等)做进来,本篇就以 Seata 为例正式为有来实验室拉开一个序幕。
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
| 术语 | |
|---|---|
| TC (Transaction Coordinator) - 事务协调者 | 维护全局和分支事务的状态,驱动全局事务提交或回滚。 |
| TM (Transaction Manager) - 事务管理器 | 定义全局事务的范围:开始全局事务、提交或回滚全局事务。 |
| RM (Resource Manager) - 资源管理器 | 管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。 |
| 中间件 | 版本 | 服务器IP | 端口 |
|---|---|---|---|
| Seata | 1.5.2 | 192.168.10.100 | 8091、7091 |
| Nacos | 2.0.3 | 192.168.10.99 | 8848 |
| MySQL | 8.0.27 | 192.168.10.98 | 3306 |
Seata 表结构MySQL脚本在线地址: https://github.com/seata/seata/blob/1.5.2/script/server/db/mysql.sql
执行以下脚本完成 Seata 数据库创建和表的初始化:
-- 1. 执行语句创建名为 seata 的数据库
CREATE DATABASE seata DEFAULT CHARACTER SET utf8mb4 DEFAULT COLLATE utf8mb4_general_ci;
-- 2.执行脚本完成 Seata 表结构的创建
use seata;
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`status` TINYINT NOT NULL,
`application_id` VARCHAR(32),
`transaction_service_group` VARCHAR(32),
`transaction_name` VARCHAR(128),
`timeout` INT,
`begin_time` BIGINT,
`application_data` VARCHAR(2000),
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`xid`),
KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(
`branch_id` BIGINT NOT NULL,
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`resource_group_id` VARCHAR(32),
`resource_id` VARCHAR(256),
`branch_type` VARCHAR(8),
`status` TINYINT,
`client_id` VARCHAR(64),
`application_data` VARCHAR(2000),
`gmt_create` DATETIME(6),
`gmt_modified` DATETIME(6),
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(
`row_key` VARCHAR(128) NOT NULL,
`xid` VARCHAR(128),
`transaction_id` BIGINT,
`branch_id` BIGINT NOT NULL,
`resource_id` VARCHAR(256),
`table_name` VARCHAR(32),
`pk` VARCHAR(36),
`status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`row_key`),
KEY `idx_status` (`status`),
KEY `idx_branch_id` (`branch_id`),
KEY `idx_xid_and_branch_id` (`xid` , `branch_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE IF NOT EXISTS `distributed_lock`
(
`lock_key` CHAR(20) NOT NULL,
`lock_value` VARCHAR(20) NOT NULL,
`expire` BIGINT,
primary key (`lock_key`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('AsyncCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryRollbacking', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('TxTimeoutCheck', ' ', 0);
这里采用 Nacos 作为配置中心的方式,所以需要把 Seata 的外置配置放置在Nacos上
Seata 外置配置在线地址:https://github.com/seata/seata/blob/1.5.2/script/config-center/config.txt
完整配置如下:
#For details about configuration items, see https://seata.io/zh-cn/docs/user/configurations.html
#Transport configuration, for client and server
transport.type=TCP
transport.server=NIO
transport.heartbeat=true
transport.enableTmClientBatchSendRequest=false
transport.enableRmClientBatchSendRequest=true
transport.enableTcServerBatchSendResponse=false
transport.rpcRmRequestTimeout=30000
transport.rpcTmRequestTimeout=30000
transport.rpcTcRequestTimeout=30000
transport.threadFactory.bossThreadPrefix=NettyBoss
transport.threadFactory.workerThreadPrefix=NettyServerNIOWorker
transport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandler
transport.threadFactory.shareBossWorker=false
transport.threadFactory.clientSelectorThreadPrefix=NettyClientSelector
transport.threadFactory.clientSelectorThreadSize=1
transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThread
transport.threadFactory.bossThreadSize=1
transport.threadFactory.workerThreadSize=default
transport.shutdown.wait=3
transport.serialization=seata
transport.compressor=none
#Transaction routing rules configuration, only for the client
service.vgroupMapping.default_tx_group=default
#If you use a registry, you can ignore it
service.default.grouplist=127.0.0.1:8091
service.enableDegrade=false
service.disableGlobalTransaction=false
#Transaction rule configuration, only for the client
client.rm.asyncCommitBufferLimit=10000
client.rm.lock.retryInterval=10
client.rm.lock.retryTimes=30
client.rm.lock.retryPolicyBranchRollbackOnConflict=true
client.rm.reportRetryCount=5
client.rm.tableMetaCheckEnable=true
client.rm.tableMetaCheckerInterval=60000
client.rm.sqlParserType=druid
client.rm.reportSuccessEnable=false
client.rm.sagaBranchRegisterEnable=false
client.rm.sagaJsonParser=fastjson
client.rm.tccActionInterceptorOrder=-2147482648
client.tm.commitRetryCount=5
client.tm.rollbackRetryCount=5
client.tm.defaultGlobalTransactionTimeout=60000
client.tm.degradeCheck=false
client.tm.degradeCheckAllowTimes=10
client.tm.degradeCheckPeriod=2000
client.tm.interceptorOrder=-2147482648
client.undo.dataValidation=true
client.undo.logSerialization=jackson
client.undo.onlyCareUpdateColumns=true
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
client.undo.logTable=undo_log
client.undo.compress.enable=true
client.undo.compress.type=zip
client.undo.compress.threshold=64k
#For TCC transaction mode
tcc.fence.logTableName=tcc_fence_log
tcc.fence.cleanPeriod=1h
#Log rule configuration, for client and server
log.exceptionRate=100
#Transaction storage configuration, only for the server. The file, DB, and redis configuration values are optional.
store.mode=file
store.lock.mode=file
store.session.mode=file
#Used for password encryption
store.publicKey=
#If `store.mode,store.lock.mode,store.session.mode` are not equal to `file`, you can remove the configuration block.
store.file.dir=file_store/data
store.file.maxBranchSessionSize=16384
store.file.maxGlobalSessionSize=512
store.file.fileWriteBufferCacheSize=16384
store.file.flushDiskMode=async
store.file.sessionReloadReadSize=100
#These configurations are required if the `store mode` is `db`. If `store.mode,store.lock.mode,store.session.mode` are not equal to `db`, you can remove the configuration block.
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=username
store.db.password=password
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.distributedLockTable=distributed_lock
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
#These configurations are required if the `store mode` is `redis`. If `store.mode,store.lock.mode,store.session.mode` are not equal to `redis`, you can remove the configuration block.
store.redis.mode=single
store.redis.single.host=127.0.0.1
store.redis.single.port=6379
store.redis.sentinel.masterName=
store.redis.sentinel.sentinelHosts=
store.redis.maxConn=10
store.redis.minConn=1
store.redis.maxTotal=100
store.redis.database=0
store.redis.password=
store.redis.queryLimit=100
#Transaction rule configuration, only for the server
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.distributedLockExpireTime=10000
server.xaerNotaRetryTimeout=60000
server.session.branchAsyncQueueSize=5000
server.session.enableBranchAsyncRemove=false
server.enableParallelRequestHandle=false
#Metrics configuration, only for the server
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898
在 Nacos 管控台默认的 public 命名空间下 ,新建配置 Data ID 为 seataServer.properties ,Group 为 SEATA_GROUP 的配置,并将Seata外置配置config.txt 内容复制进来
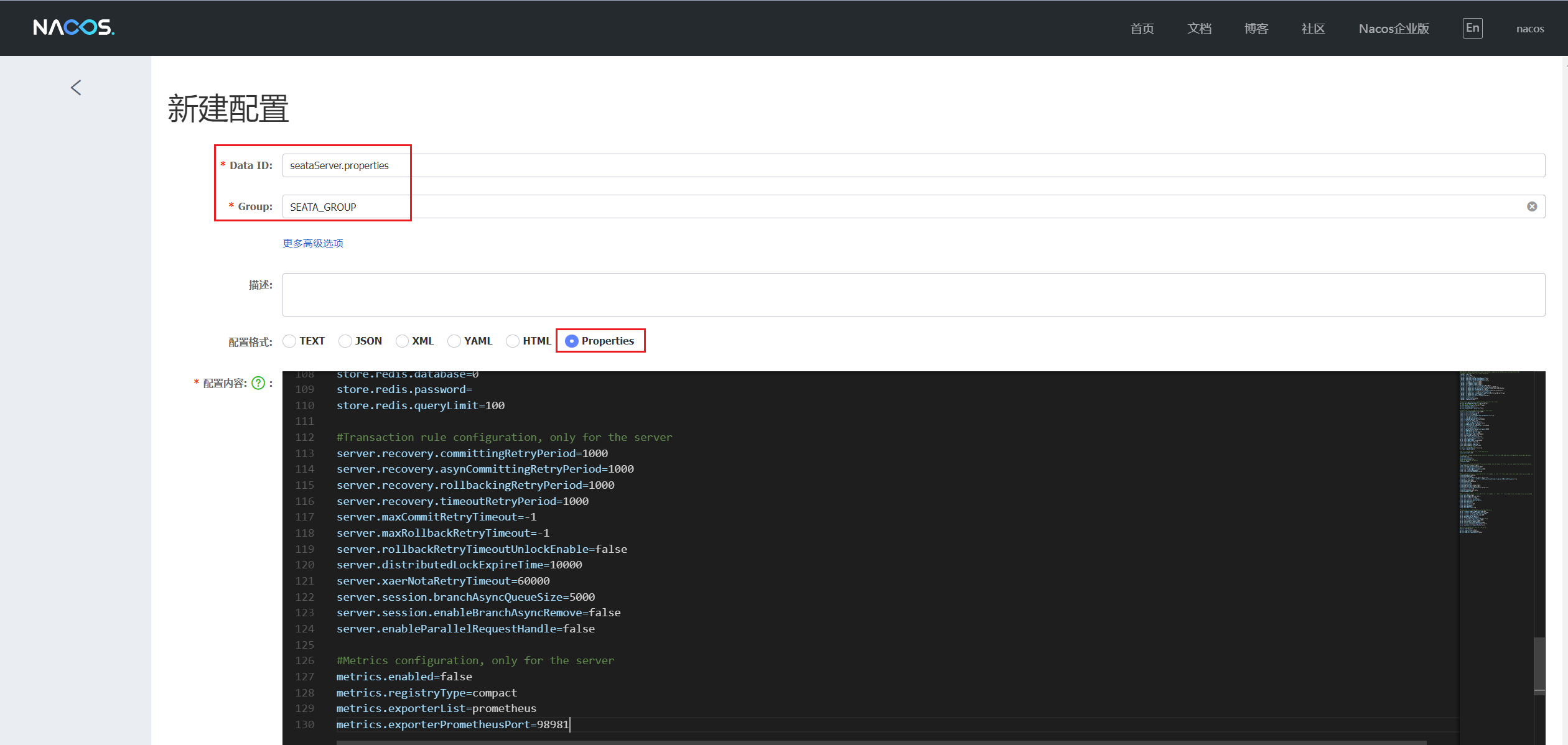
仅需修存储模式为db以及对应的db连接配置
# 修改store.mode为db,配置数据库连接
store.mode=db
store.db.dbType=mysql
store.db.driverClassName=com.mysql.cj.jdbc.Driver
store.db.url=jdbc:mysql://192.168.10.98:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=123456
Seata 官方部署文档:https://seata.io/zh-cn/docs/ops/deploy-by-docker.html
按照官方文档描述使用自定义配置文件的部署方式,需要先创建临时容器把配置copy到宿主机
创建临时容器
docker run -d --name seata-server -p 8091:8091 -p 7091:7091 seataio/seata-server:1.5.2
创建挂载目录
mkdir -p /mnt/seata/config
复制容器配置至宿主机
docker cp seata-server:/seata-server/resources/. /mnt/seata/config
注意复制到宿主机的目录,下文启动容器需要做宿主机和容器的目录挂载

过河拆桥,删除临时容器
docker rm -f seata-server
在获取到 seata-server 的应用配置之后,因为这里采用 Nacos 作为 seata 的配置中心和注册中心,所以需要修改 application.yml 里的配置中心和注册中心地址,详细配置我们可以从 application.example.yml 拿到。
application.yml 原配置
vi /mnt/seata/config/application.yml
修改后的配置(参考 application.example.yml 示例文件),以下是需要调整的部分,其他配置默认即可
seata:
config:
type: nacos
nacos:
server-addr: 192.168.10.99:8848
namespace:
group: SEATA_GROUP
data-id: seataServer.properties
registry:
type: nacos
preferred-networks: 30.240.*
nacos:
application: seata-server
server-addr: 192.168.10.99:8848
namespace:
group: SEATA_GROUP
cluster: default
# 存储模式在外置配置(Nacos)中,Nacos 配置加载优先级大于application.yml,会被application.yml覆盖,所以此处注释
#store:
#mode: file
docker run -d --name seata-server --restart=always \
-p 8091:8091 \
-p 7091:7091 \
-e SEATA_IP=192.168.10.100 \
-v /mnt/seata/config:/seata-server/resources \
seataio/seata-server:1.5.2
/mnt/seata/config Seata应用配置挂载在宿主机的目录
192.168.10.100 Seata 宿主机IP地址
在 nacos 控制台 的 public 命名空间下服务列表里有 seata-server 说明部署启动成功

如果启动失败或者未注册到 nacos , 基本是粗心的结果,请仔细检查下自己 application.yml 的注册中心配置或查看日志
docker logs -f --tail=100 seata-server
以上就完成对 Seata 服务端的部署和配置,接下来就是 SpringBoot 与 Seata 客户端的整合。
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<!-- 默认seata客户端版本比较低,排除后重新引入指定版本-->
<exclusions>
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.5.2</version>
</dependency>
undo_log表脚本: https://github.com/seata/seata/blob/1.5.2/script/client/at/db/mysql.sql
-- for AT mode you must to init this sql for you business database. the seata server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';
AT模式两阶段提交协议的演变:
Seata的AT模式下之所以在第一阶段直接提交事务,依赖的是需要在每个RM创建一张undo_log表,记录业务执行前后的数据快照。
如果二阶段需要回滚,直接根据undo_log表回滚,如果执行成功,则在第二阶段删除对应的快照数据。
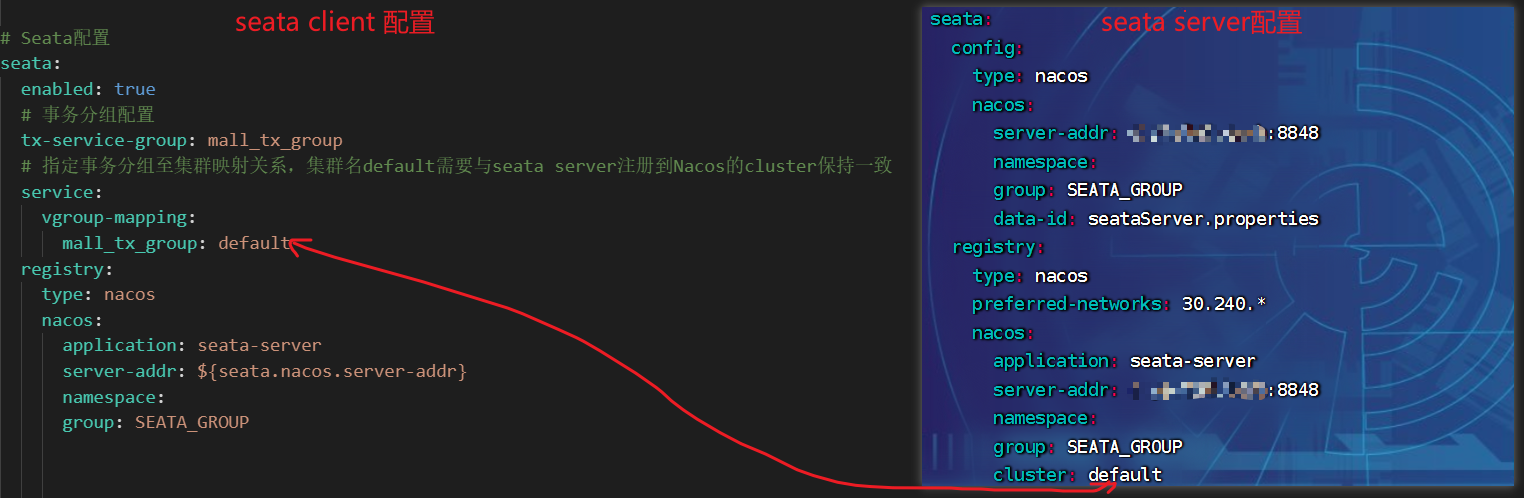
# Seata配置
seata:
enabled: true
# 指定事务分组至集群映射关系,集群名default需要与seata-server注册到Nacos的cluster保持一致
service:
vgroup-mapping:
mall_tx_group: default
# 事务分组配置
tx-service-group: mall_tx_group
registry:
type: nacos
nacos:
application: seata-server
# nacos 服务地址
server-addr: 192.168.10.99:8848
namespace:
group: SEATA_GROUP
以上3点就是 Seata 客户端需要做的事项,下面就 Seata 如何实战应用进行展开详细说明。
Seata 官网示例: http://seata.io/zh-cn/docs/user/quickstart.html
用户购买商品订单支付的业务逻辑。整个业务逻辑由3个微服务提供支持:
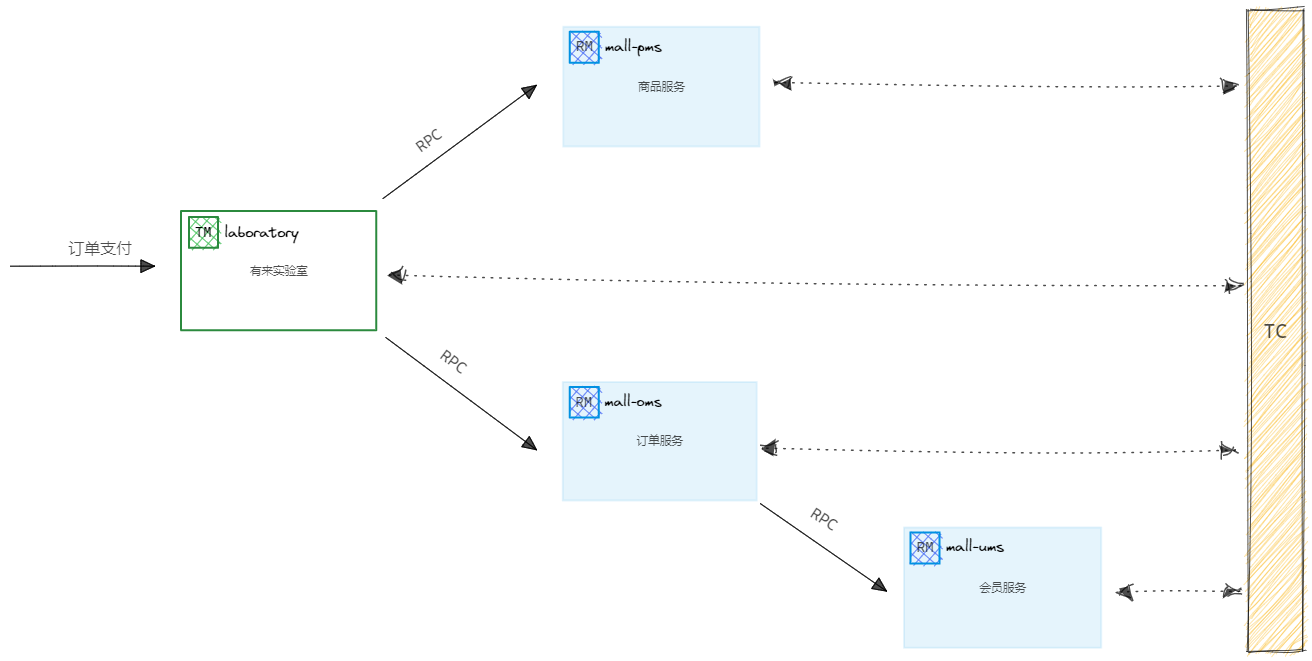
实验室在“订单支付”案例中扮演的是【事务管理器】的角色,其工作内容是开始全局事务、提交或回滚全局事务。
按照 【第三节-Seata客户端搭建 】 在 laboratory 模块添加 Maven 依赖和客户端的配置。
订单支付关键代码片段(SeataServiceImpl#payOrderWithGlobalTx),通过注解 GlobalTransactional 开启全局事务,通过对商品 Feign 客户端和订单 Feign 客户端的调用完成订单支付的流程,这是全局事务开始的地方。
/**
* 订单支付(全局事务)
*/
@GlobalTransactional
public boolean payOrderWithGlobalTx(SeataForm seataForm) {
log.info("========扣减商品库存========");
skuFeignClient.deductStock(skuId, 1);
log.info("========订单支付========");
orderFeignClient.payOrder(orderId, ...);
return true;
}
按照 【第三节-Seata客户端搭建 】 在 mall-pms 模块添加 Maven 依赖和客户端的配置,在 mall-pms 数据库创建 undo_log 表。
扣减库存关键代码:
/**
* 「实验室」扣减商品库存
*/
public boolean deductStock(Long skuId, Integer num) {
boolean result = this.update(new LambdaUpdateWrapper<PmsSku>()
.setSql("stock_num = stock_num - " + num)
.eq(PmsSku::getId, skuId)
);
return result;
}
按照 【第三节-Seata客户端搭建 】 在 mall-oms 模块添加 Maven 依赖和客户端的配置,在 mall-oms 数据库创建 undo_log 表。
订单支付关键代码:
/**
* 「实验室」订单支付
*/
public Boolean payOrder(Long orderId, SeataOrderDTO orderDTO) {
Long memberId = orderDTO.getMemberId();
Long amount = orderDTO.getAmount();
// 扣减账户余额
memberFeignClient.deductBalance(memberId, amount);
// 【关键】如果开启异常,全局事务将会回滚
Boolean openEx = orderDTO.getOpenEx();
if (openEx) {
int i = 1 / 0;
}
// 修改订单【已支付】
boolean result = this.update(new LambdaUpdateWrapper<OmsOrder>()
.eq(OmsOrder::getId, orderId)
.set(OmsOrder::getStatus, OrderStatusEnum.WAIT_SHIPPING.getValue())
);
return result;
}
按照 【第三节-Seata客户端搭建 】 在 mall-ums 模块添加 Maven 依赖和客户端的配置,在 mall-ums 数据库创建 undo_log 表。
扣减余额关键代码:
@ApiOperation(value = "「实验室」扣减会员余额")
@PutMapping("/{memberId}/balances/_deduct")
public Result deductBalance(@PathVariable Long memberId, @RequestParam Long amount) {
boolean result = memberService.update(new LambdaUpdateWrapper<UmsMember>()
.setSql("balance = balance - " + amount)
.eq(UmsMember::getId, memberId));
return Result.judge(result);
}
以上就基于 youlai-mall 商城订单支付的业务简单实现的 Seata 实验室,接下来通过测试来看看 Seata 分布式事务的能力。
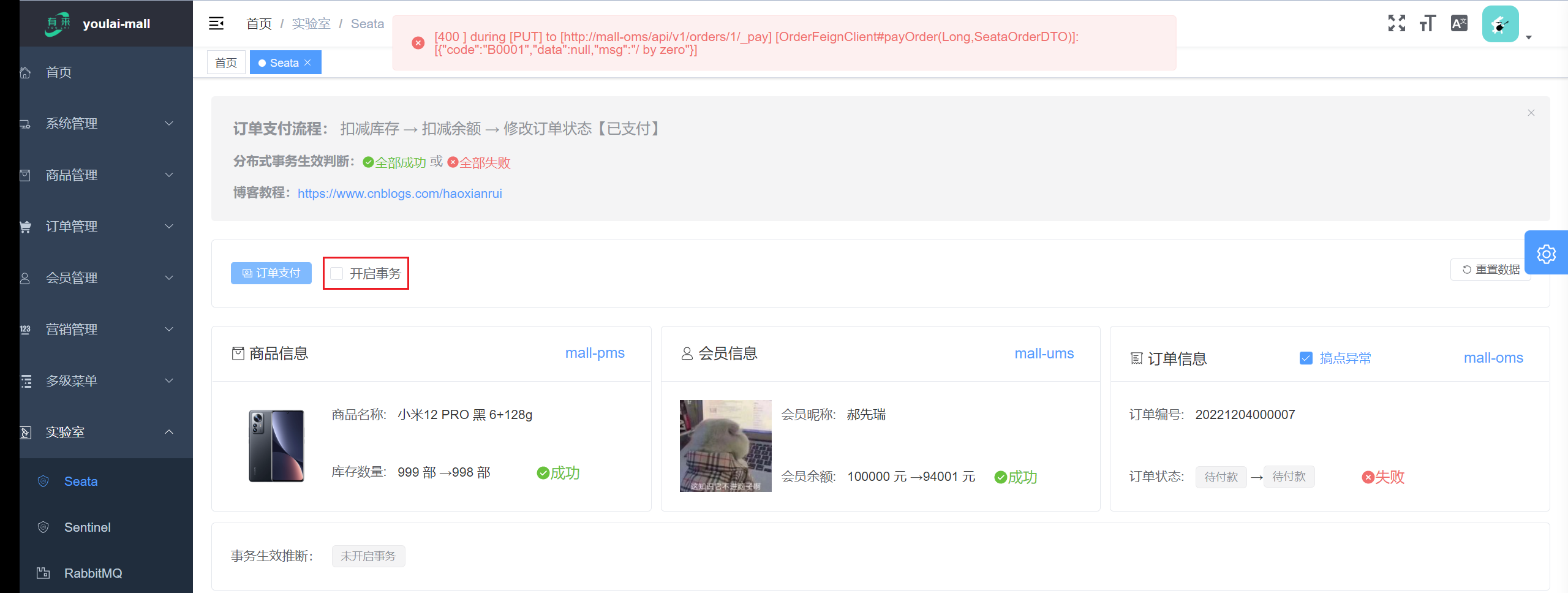
未开启事务前提: 订单状态因为异常修改失败,但这并未影响到商品库存扣减和余额扣减成功的结果,明显这不是希望的结果。
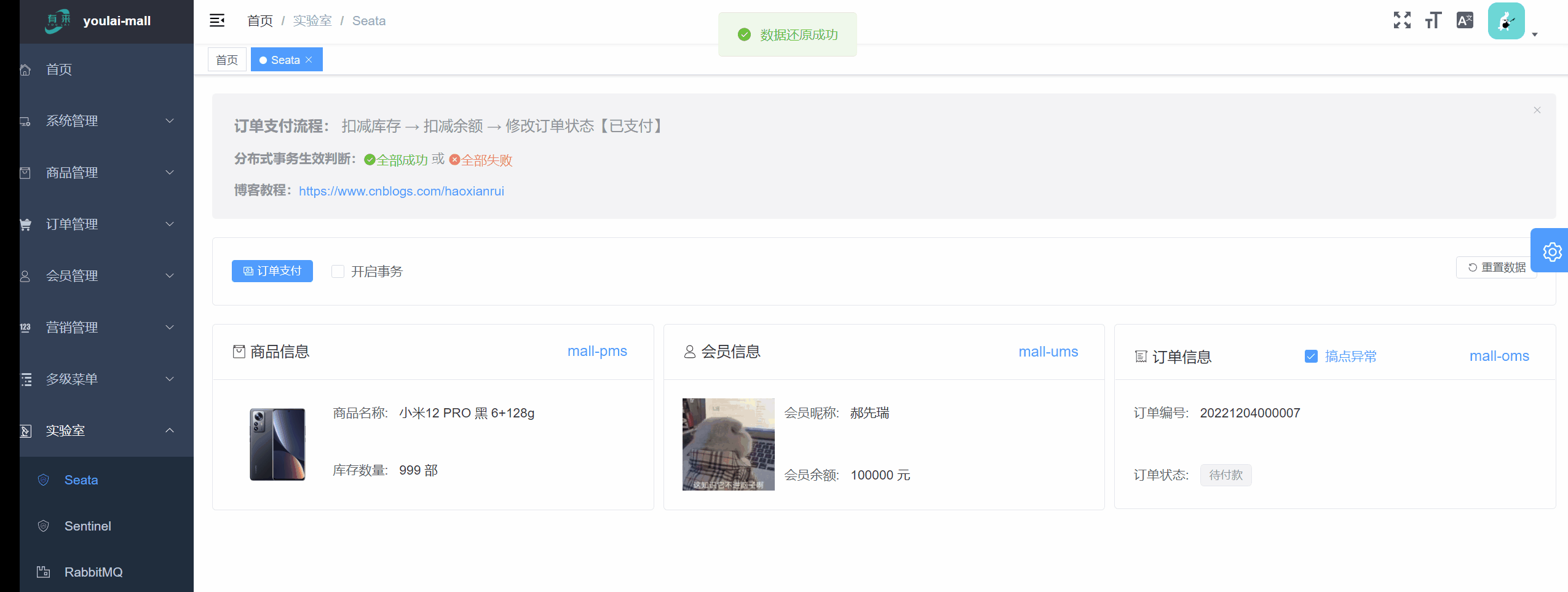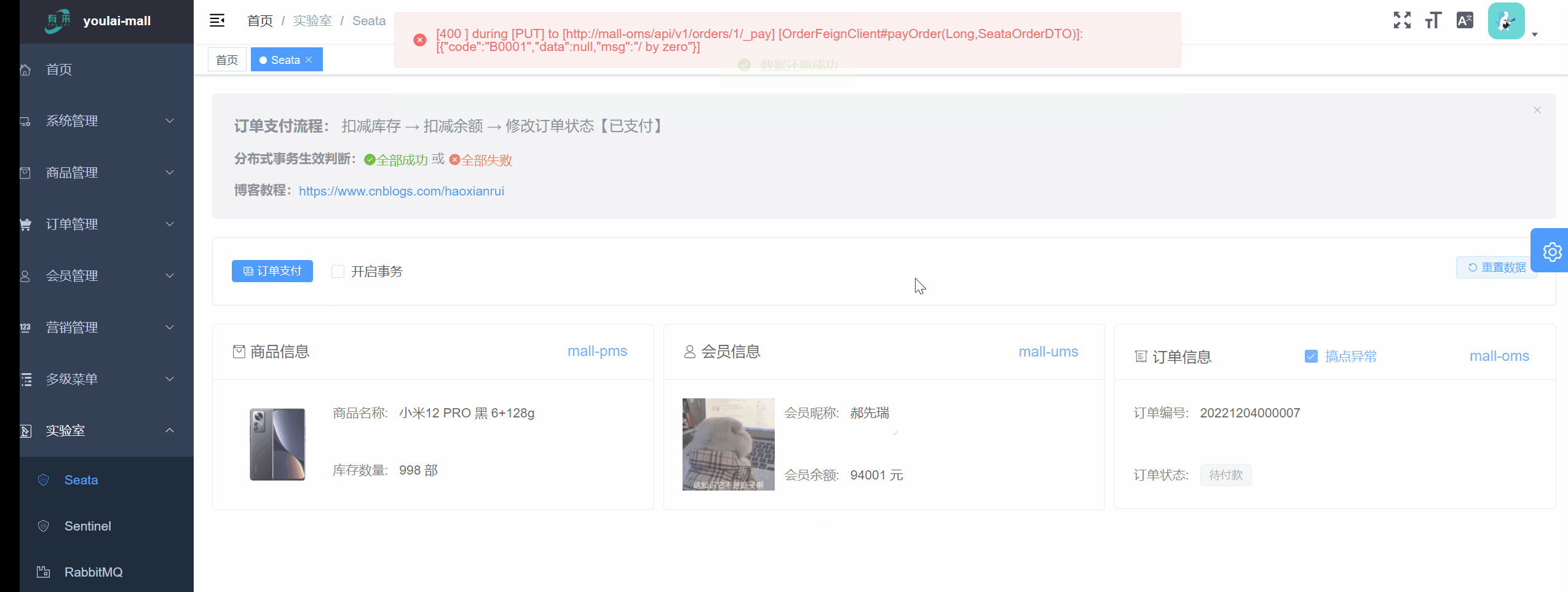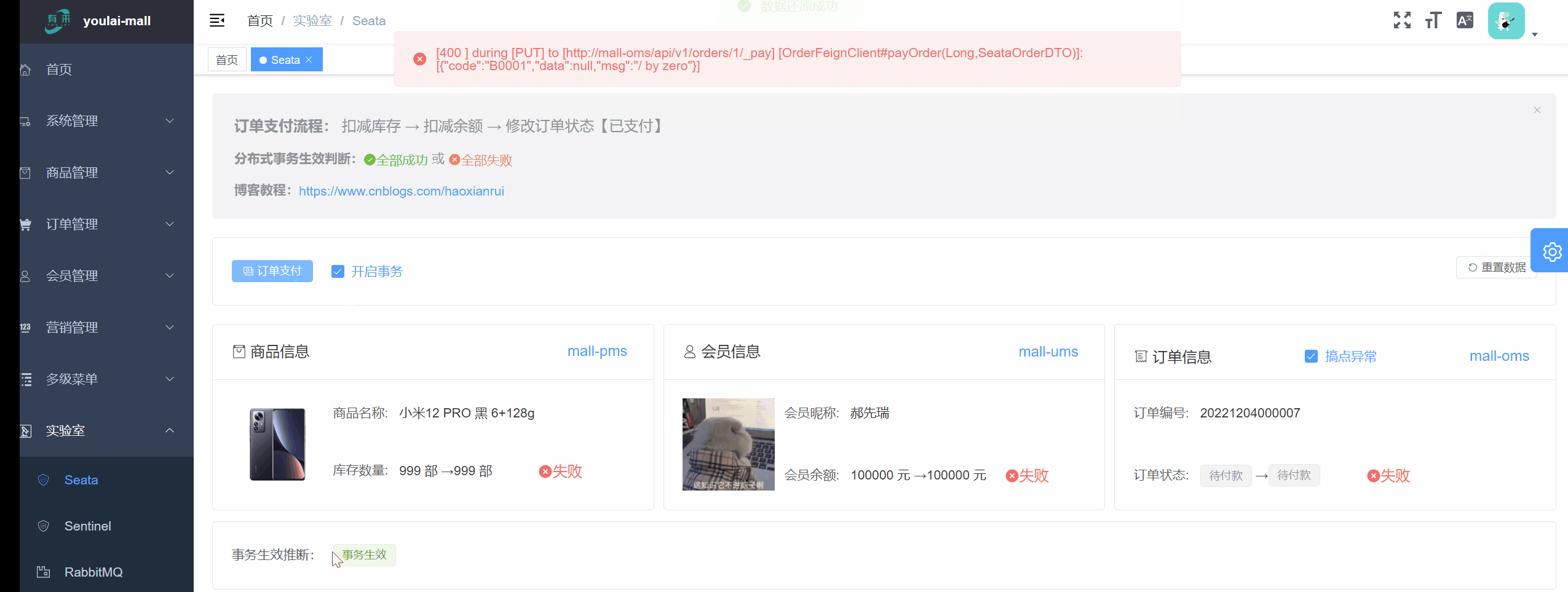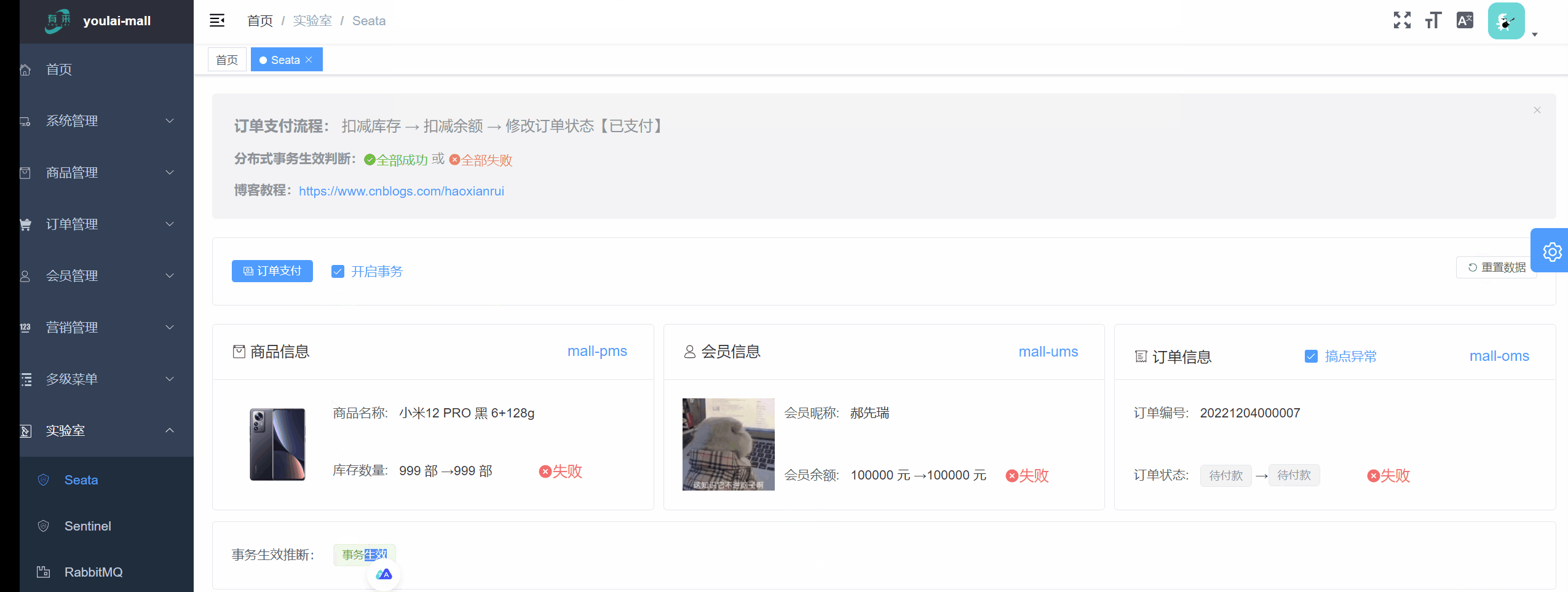
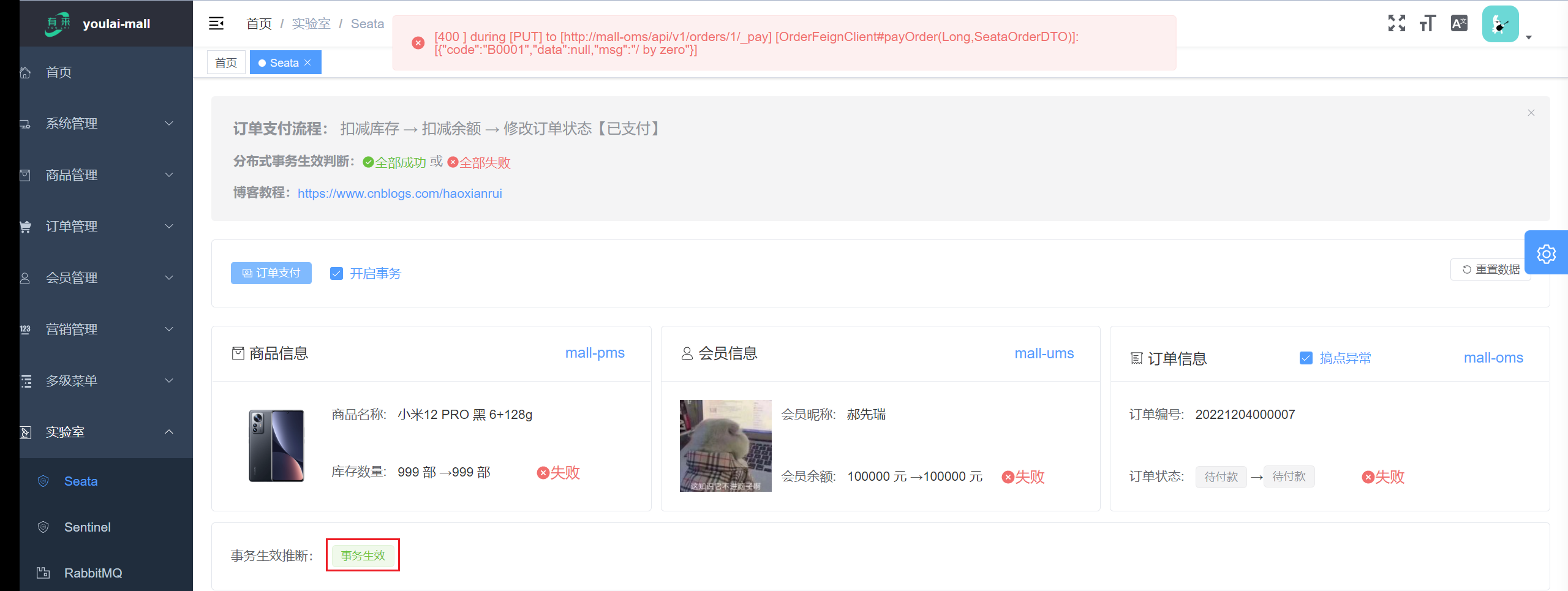
开启事务前提:订单状态修改发生异常,同时也回滚了扣减库存、扣减余额的行为,可见 Seata 分布式事务生效。
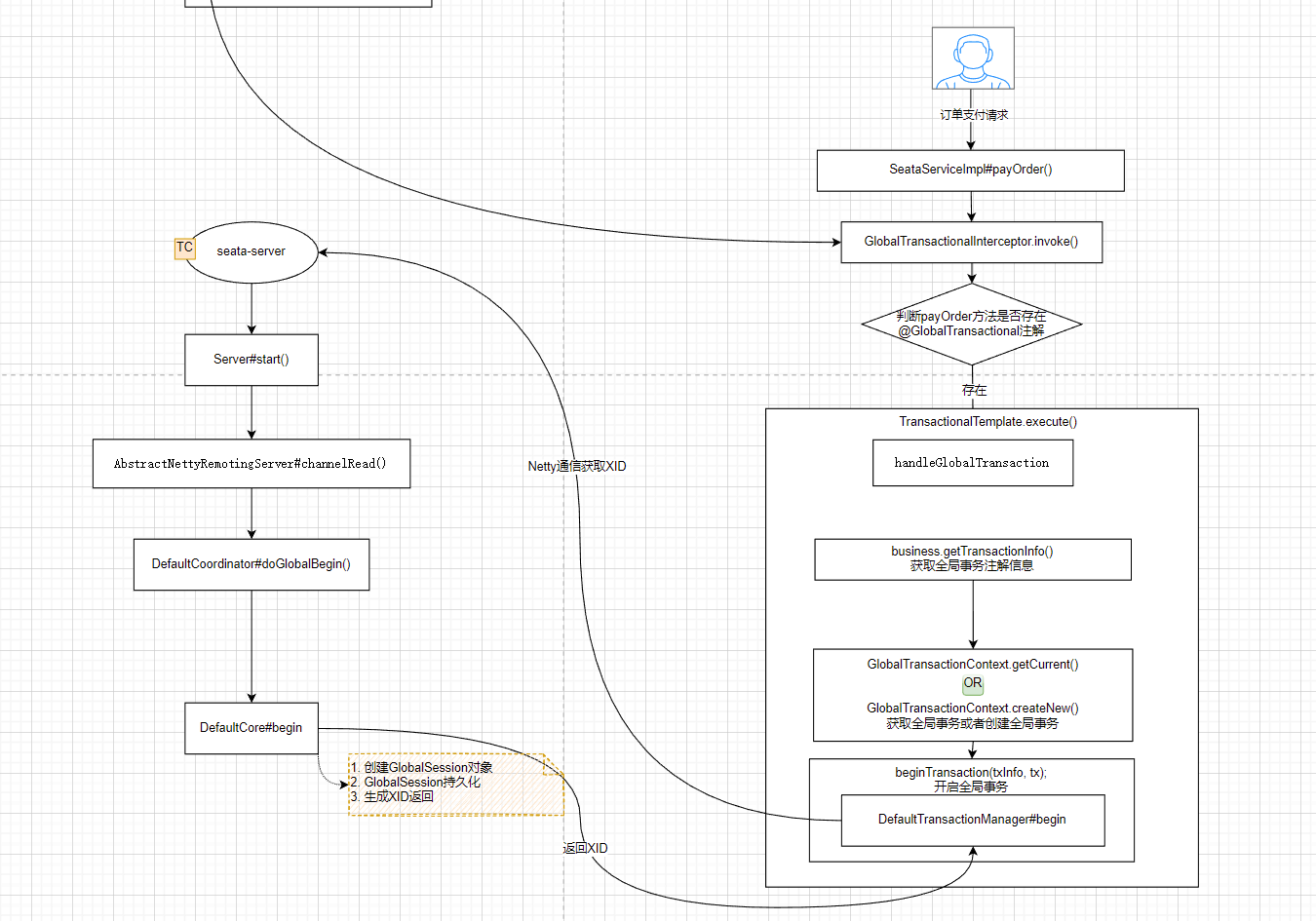
因为 Seata 源码牵涉角色比较多,需要在本地搭建 seata-server 然后和 Seata 客户端交互调试,后面整理出来会单独拿一篇文章进行进行具体分析。
本篇通过 Seata 1.5.2 版本部署到实战讲述了 Seata 分布式事务AT模式在商城订单支付业务场景的应用,相信大家对 Seata 和有来实验室有个初步的认知,但这里还只是一个开始,后续会有更多的热门中间件登上实验室舞台。当然,可见这个舞台很大,所以也希望有兴趣或者有想法同学加入有来实验室的开发。
本文源码已推送至gitee和github仓库
| gitee | github | |
|---|---|---|
| 后端工程 | https://gitee.com/youlaitech/youlai-mall | https://github.com/youlaitech/youlai-mall |
| 前端工程 | https://gitee.com/youlaiorg/mall-admin | https://github.com/youlaitech/mall-admin |
我有一个PORO(普通旧Ruby对象)来处理一些业务逻辑。它接收一个ActiveRecord对象并对其进行分类。为了简单起见,以下面为例:classClassificatorSTATES={1=>"Positive",2=>"Neutral",3=>"Negative"}definitializer(item)@item=itemenddefnameSTATES.fetch(state_id)endprivatedefstate_idreturn1if@item.value>0return2if@item.value==0return3if@item.value但是,我还想根据这些st
一、RIPV2协议简介 RIP(RoutingInformationProtocol)路由协议是一种相对古老,在小型以及同介质网络中得到了广泛应用的一种路由协议。RIP采用距离向量算法,是一种距离向量协议。RIP-1是有类别路由协议(ClassfulRoutingProtocol),它只支持以广播方式发布协议报文。RIP-1的协议报文无法携带掩码信息,它只能识别A、B、C类这样的自然网段的路由,因此RIP-1不支持非连续子网(DiscontiguousSubnet)。RIP-2是一种无类别路由协议(ClasslessRoutingProtocol),支持路由标记,在路由策略中可根据路由标记对
目录1.1访问Cisco路由器的方法1.1.1通过Console口访问路由器1.1.2通过Telnet访问路由器1.1.3终端访问服务器1.2终端访问服务器配置命令汇总1.1访问Cisco路由器的方法 路由器没有键盘和鼠标,要初始化路由器需要把计算机的串口和路由器的Console口进行连接。访问Cisco路由器的方法还有Telnet、WebBrowser和网络管理软件(如CiscoWorks)等,本节讨论前2种。1.1.1通过Console口访问路由器 计算机的串口和路由器的Console口是通过反转线(Rollover)进行连接的,反转线的一端接在路由器的Console口上,另一
文章目录一、用户二、用户分类1、普通用户2、超级用户3、系统用户三、用户相关文件1、/etc/passwd文件2、/etc/shadow文件四、用户管理命令1、useradd2、adduser3、passwd4、usermod5、userdel一、用户Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户都必须先向系统管理员申请一个账号,然后以这个账号的身份进入系统。在Linux系统中,任何文件都属于某一特定用户,而任何用户都隶属于至少一个用户组。用户名(username):每个用户账号都拥有一个惟一的用户名和各自的口令。用户在登录时键入正确的用户名和口令后,就能够进入系
文章目录实验要求实验思路IP地址规划路由实验配置R1上配置R2上配置R3上配置R4上配置R5上配置R6上配置R7上配置R8上配置R9上配置R10上配置R11上配置R12上配置实验测试R10pingR4的环回R10pingR12的环回R10pingR1实验要求R4为ISP,其只能配置IP地址;R4与其他所有直连设备间均使用公有IP;R3-R5/6/7为MGRE环境,R3为中心站点;整个OSPF环境IP基于172.16.0.0/16划分;所有设备均可访问R4的环回;减少LSA的更新量,加快收敛,保障更新安全;全网可达实验思路IP地址规划公网IP随便配置,这里我R3-R4的网段为34.1.1.0/2
我刚刚从5.1升级到5.2,我对这种“更好”的secret存储方法感到很困惑...也许我不明白,但现在开发和生产似乎已经“合并”到一个单一的SECRET_KEY_BASE以及master.key中......这是正确的吗?如果没有,我如何在开发中使用单独的主key和SECRET_KEY_BASE?如果我有开发人员帮助我并且我不想让他们知道我在生产中使用的主key(或secret)怎么办? 最佳答案 Rails5.2对此做了很大的改变。对于开发和测试环境,secret_key_base是自动生成的,因此您可以将其从secrets.ym
首先我们得有一个数据库,数据库里有表职工表: 部门表:接下来的操作都是针对以上的表其次我们来建立登录用户createlogin王明withpassword='123456'--创建登录用户,登录名为王明,密码为123456.创建登录名之后,登录用户还不能对数据库进行操作,还要对登录用户创建数据库用户createuserU1forlogin王明--创建数据库用户关联登录用户这时候登录王明的账户,数据库会自动映射到数据库用户U1,由U1来进行对数据库的操作。不过,只创建了用户,而用户还没有获得对数据库的操作权力,我们就要对数据库用户进行权力分配有时间的小伙伴可以额外花点时间点击链接了解详细1)设置
Ruby社区最近出现了大量关于使用更好的OO设计的好处的博客文章、推文和评论,特别是将业务逻辑与持久性逻辑分开。特别是对于较大的应用程序,我认为这是很好的建议。http://solnic.eu/2011/08/01/making-activerecord-models-thin.htmlhttp://blog.steveklabnik.com/2011/09/06/the-secret-to-rails-oo-design.htmlhttp://avdi.org/devblog/2011/11/15/early-access-beta-of-objects-on-rails-now-a
C#面向对象程序设计课程实验五:实验名称:C#面向对象技术实验内容:C#面向对象技术一、实验目的及要求二、实验环境三、实验内容与步骤3.1、实验内容:测试类,实现多态3.2、实验步骤3.2.1、实验程序3.2.2、实验运行结果3.3、实验内容:创建一个Vehicle类,并将它声明为抽象类3.4、实验步骤3.4.1、实验程序3.4.2、实验运行结果四、实验总结实验内容:C#面向对象技术一、实验目的及要求(1)掌握类的继承特性;(2)学会使用C#实现类的继承性;(3)理解类的多态特性;(4)学会使用C#的方法重写;二、实验环境MicrosoftVisualStudio2008三、实验内容与步骤3.
实验题目bomblab实验目的使用gdb工具反汇编出汇编代码,结合c语言文件找到每个关卡的入口函数。然后分析汇编代码,分析得到每一关的通关密码。进一步加深对linux指令的理解,对gdb调试的一些基本操作以及高级操作有所了解。熟悉汇编程序,懂得如何利用汇编程序写出C语言程序伪代码,熟悉并掌握函数调用过程中的栈帧结构的变化,熟悉汇编程序及其调试方法。实验环境个人PC、Linux32位操作系统、Ubuntu16.04实验内容准备阶段将实验压缩包解压并找到本人所用到的实验文件夹bomb7,复制到linux系统中,打开文件夹得到bomb、bomb.c、README文件;阅读README等实验相关材料,