对于某项指标,可以用熵值来判断某个指标的离散程度,其 信息熵值越小,指标的离散程度越大(表明指标值得变异程度越大,提供的信息量越多),该指标对综合评价的影响(即 权重)就 越大,如果某项指标的值全部相等,则该指标在综合评价中不起作用。因此,可 利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据。
指标的值变化会直接影响因素的变化,变化量越大,说明指标对于 因素的变化作用也应该是 越明显的。
可用于任何评价问题中的确定指标权重;
可用于剔除指标体系中对评价结果贡献不大的指标
注意:确定权重前需要确定指标对目标得分的影响方向,对非线性的指标要进行预处理或者剔除。
能深刻反映出指标的区分能力,进而确定权重
是―种 客观赋权法,相对主观赋权具有较高的可信度和精确度算法简单
不够智能,没有考虑指标与指标之间的影响,如:相关性、层级关系等若无业务经验指导,权重可能失真
对样本的依赖性较大,随着建模样本不断变化,权重会发生一定波动
研究:评价类问题
依据:利用信息熵计算各个指标的权重
目的:为多指标综合评价提供依据。
指标值越大,则评价就越好。与此相对的是负向指标。
举例:场均得分----越大越好----正向指标, 场均失误----越小越好----负向指标。
计算公式:I(x)=-ln(p(x))
公式推导:
<越有可能发生的事情包含的信息量越小>
将信息量用字母I表示,概率用p表示,那么我们可以将它们建立一个函数关系:
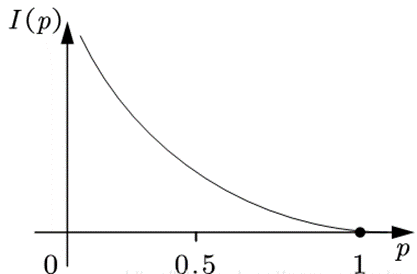
假设 x 表示事件 X 可能发生的某种情况,p(x)表示该事件发生的概率,那么I(p)=−ln(p(x)) ,因为 0⩽p(x)⩽1 ,所以I(x)⩾0 。
说明:此处的I(p)=−ln(p(x)),其中的对数是以e为下标的,也可将2作为下标,对此,目前没有统一要求。
事件X的信息熵H(X)如下:
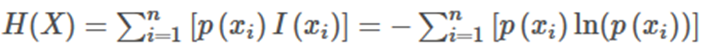
从公式可以看出,信息熵本质上就是对信息量的期望,且式中唯一的未知数是事件x的概率。

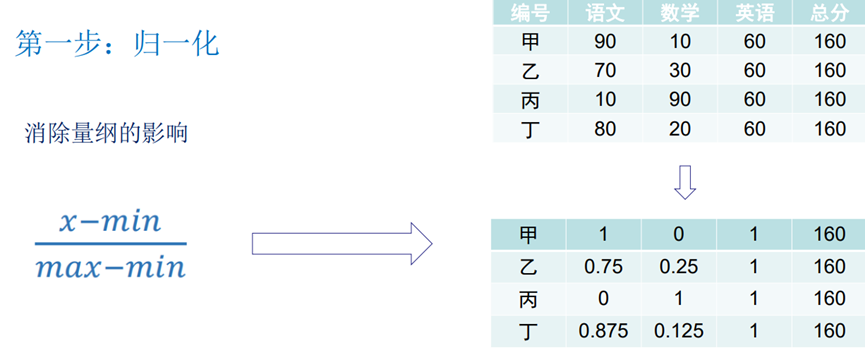
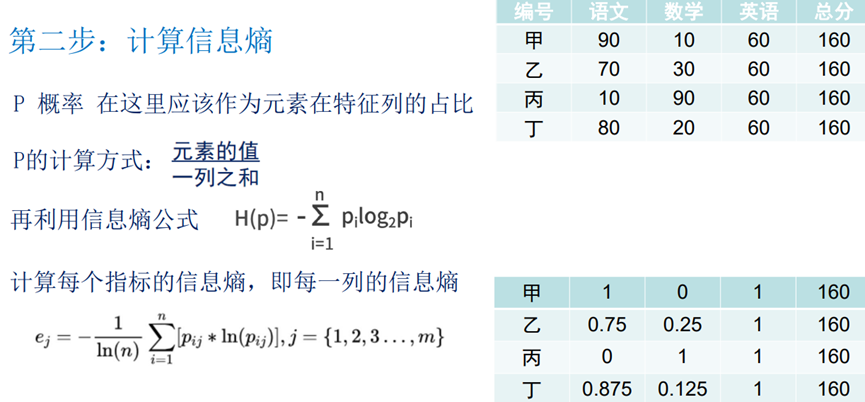
编号 | 语文 | 数学 | 英语 | 总分 |
甲 | 90 | 10 | 60 | 160 |
乙 | 70 | 30 | 60 | 160 |
丙 | 10 | 90 | 60 | 160 |
订 | 80 | 20 | 60 | 160 |
这四个同学谁的综合成绩最好?
SPSSPRO操作:

熵权法 | |||
项 | 信息熵值e | 信息效用值d | 权重(%) |
语文_min-max标准化 | 0.788 | 0.212 | 31.97 |
数学_min-max标准化 | 0.549 | 0.451 | 68.03 |

综合得分表
行索引 | 综合评价 | 排名 |
1 | 0.31973321396603943 | 4 |
2 | 0.4098666069830197 | 2 |
3 | 0.6802667860339606 | 1 |
4 | 0.36479991047452953 | 3 |
disp('输入矩阵A');
A=input('A=');
%%D=max(A);
%%归一化%%
[n,m] = size(A);
minguiyi=repmat(min(A),n,1);
maxguiyi=repmat(max(A),n,1);
B=(A-minguiyi) ./ (maxguiyi-minguiyi);
% disp('归一化结果为 B= ');
% disp(B);
%%计算信息熵%%
C=B./repmat(sum(B),n,1);
% disp(' P的矩阵为 P= ');
% disp(C);%%C是概率矩阵
for i = 1:n
for j =1:m
ifC(i,j) == 0
D(i,j)=0;
else
D(i,j) = C(i,j)*log(C(i,j));
end
end
end
E=-sum(D)/log(n);%%每一列的信息熵
%%计算每个指标的信息效用值%%
F=1-E;
%%权重的计算;
sq=F/sum(F,2);
%%加上权重比较%%
A_=sum(A.*repmat(sq,n,1),2);
disp('加权结果为:');
disp(A_);
参考资料
【数学建模基础课程】熵权法_哔哩哔哩_bilibili
数学建模系列---熵权法_cm959的博客-CSDN博客_熵权法计算公式
数学建模算法1—熵权法(EWM) - 百度文库 (baidu.com)
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
matlab打开matlab,用最简单的imread方法读取一个图像clcclearimg_h=imread('hua.jpg');返回一个数组(矩阵),往往是a*b*cunit8类型解释一下这个三维数组的意思,行数、数和层数,unit8:指数据类型,无符号八位整形,可理解为0~2^8的数三个层数分别代表RGB三个通道图像rgb最常用的是24-位实现方法,即RGB每个通道有256色阶(2^8)。基于这样的24-位RGB模型的色彩空间可以表现256×256×256≈1670万色当imshow传入了一个二维数组,它将以灰度方式绘制;可以把图像拆分为rgb三层,可以以灰度的方式观察它figure(1
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
ruby中有这样的东西吗?send(+,1,2)我想让这段代码看起来不那么冗余ifop=="+"returnarg1+arg2elsifop=="-"returnarg1-arg2elsifop=="*"returnarg1*arg2elsifop=="/"returnarg1/arg2 最佳答案 是的,只需像这样使用send(或者更好的是public_send):arg1.public_send(op,arg2)这是可行的,因为Ruby中的大多数运算符(包括+、-、*、/、andmore)只需调用方法。所以1+2与1.+(2)相同
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
情况:我正在编写一个程序来求解素数。我需要解决4x^2+y^2=n的问题,其中n是一个已知变量。是的,必须是Ruby。我愿意在这个项目上花费大量时间。我最好自己编写方程式的求解算法,并将其作为该项目的一部分。我真正喜欢的是:如果任何人都可以向我提供指南、网站的链接,或者关于与求解代数方程特别相关的形式算法的构造的歧义消除,或者向我提供似乎你是读者它会帮助我完成任务。请不要建议我使用其他语言。如果您在回答之前接受我真的非常想这样做,我将不胜感激。该项目没有范围或时间限制,也不以营利为目的。这是为了我自己的教育。注意:我并不直接反对为Ruby实现和使用现存的数学库/模块/其他东西,但我更喜
我发现许多Rails应用程序主要针对企业、社交网络类型的Web应用程序。我看到有人将Ruby与一些出色的OOPS语言(如Java和C#)进行了比较,但我确实发现很难获得一些数学密集型应用程序。非常感谢任何知识渊博的输入(指向示例程序的链接等),其中轻松显示了语言的用法,就像快速启动或显示该语言如何用于各种数学问题一样。 最佳答案 不幸的是,Ruby并没有在数学和科学计算领域涉足太多。目前,有一个名为SciRuby的pre-alpha库它试图为Ruby带来更多面向数学的功能。他们正试图构建一个NumPy/SciPy等价物。SciRub
link有两个组件:componenta_id和componentb_id。为此,在Link模型文件中我有:belongs_to:componenta,class_name:"Component"belongs_to:componentb,class_name:"Component"validates:componenta_id,presence:truevalidates:componentb_id,presence:truevalidates:componenta_id,uniqueness:{scope::componentb_id}validates:componentb_id
“架设一个亿级高并发系统,是多数程序员、架构师的工作目标。许多的技术从业人员甚至有时会降薪去寻找这样的机会。但并不是所有人都有机会主导,甚至参与这样一个系统。今天我们用12306火车票购票这样一个业务场景来做DDD领域建模。”开篇要实现软件设计、软件开发在一个统一的思想、统一的节奏下进行,就应该有一个轻量级的框架对开发过程与代码编写做一定的约束。虽然DDD是一个软件开发的方法,而不是具体的技术或框架,但拥有一个轻量级的框架仍然是必要的,为了开发一个支持DDD的框架,首先需要理解DDD的基本概念和核心的组件。一.什么是领域驱动设计(DDD)首先要知道DDD是一种开发理念,核心是维护一个反应领域概