
GenericAPIView继承自 APIView,也就是在 APIView基础上再做了一层封装
queryset = None
serializer_class = None
lookup_field = ‘pk’
lookup_url_kwarg = None
filter_backends = api_settings.DEFAULT_FILTER_BACKENDS
pagination_class = api_settings.DEFAULT_PAGINATION_CLASS
queryset是用来控制视图返回给前端的数据。如果没什么逻辑,可以直接写在视图的类属性中,如果逻辑比较复杂,也可以重写get_queryset方法用来返回一个queryset对象。如果重写了get_queryset,那么以后获取queryset的时候就需要通过调用get_queryset方法。因为queryset` 这个属性只会调用一次,以后所有的请求都是使用他的缓存。
serializer_class用来验证和序列化、反序列化数据的。也是可以通过直接设置这个属性,也可以通过重写get_serializer_class来实现。
在检索的时候,根据什么参数进行检索。默认是pk,也就是主键。
在检索的url中的参数名称。默认没有设置,跟lookup_field保持一致。
用于过滤查询集的过滤器后端类的列表。默认值与DEFAULT_FILTER_BACKENDS 设置的值相同。
当分页列出结果时应使用的分页类。默认值与 DEFAULT_PAGINATION_CLASS 设置的值相同,即 ‘rest_framework.pagination.PageNumberPagination’。
get_object()
get_queryset()
get_serializer()
get_serializer_class()
get_serializer_context()
paginate_queryset()
filter_queryset()
get_queryset默认是返回数据库全部数据,如果想返回其他数据,需要自定义
def get_queryset(self):
"""
Get the list of items for this view.
This must be an iterable, and may be a queryset.
Defaults to using `self.queryset`.
This method should always be used rather than accessing `self.queryset`
directly, as `self.queryset` gets evaluated only once, and those results
are cached for all subsequent requests.
You may want to override this if you need to provide different
querysets depending on the incoming request.
(Eg. return a list of items that is specific to the user)
"""
assert self.queryset is not None, (
"'%s' should either include a `queryset` attribute, "
"or override the `get_queryset()` method."
% self.__class__.__name__
)
queryset = self.queryset
if isinstance(queryset, QuerySet):
# Ensure queryset is re-evaluated on each request.
queryset = queryset.all()
return queryset
该方法是用于在数据检索(通过pk查找)的时候,返回一条数据的。
不需要重写get_object(),直接调用
def get_object(self):
"""
Returns the object the view is displaying.
You may want to override this if you need to provide non-standard
queryset lookups. Eg if objects are referenced using multiple
keyword arguments in the url conf.
"""
queryset = self.filter_queryset(self.get_queryset())
# Perform the lookup filtering.
lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field
assert lookup_url_kwarg in self.kwargs, (
'Expected view %s to be called with a URL keyword argument '
'named "%s". Fix your URL conf, or set the `.lookup_field` '
'attribute on the view correctly.' %
(self.__class__.__name__, lookup_url_kwarg)
)
filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]}
obj = get_object_or_404(queryset, **filter_kwargs)
# May raise a permission denied
self.check_object_permissions(self.request, obj)
return obj
返回应该用于验证和反序列化输入以及序列化输出的序列化器实例
不需要重写get_serializer()方法,直接调用即可
def get_serializer(self, *args, **kwargs):
"""
Return the serializer instance that should be used for validating and
deserializing input, and for serializing output.
"""
serializer_class = self.get_serializer_class()
kwargs.setdefault('context', self.get_serializer_context())
return serializer_class(*args, **kwargs)
返回用于序列化的类。默认使用 self.serializer_class。如果您需要根据传入请求提供不同的序列化,您可能需要重写它。
def get_serializer_class(self):
"""
Return the class to use for the serializer.
Defaults to using `self.serializer_class`.
You may want to override this if you need to provide different
serializations depending on the incoming request.
(Eg. admins get full serialization, others get basic serialization)
"""
assert self.serializer_class is not None, (
"'%s' should either include a `serializer_class` attribute, "
"or override the `get_serializer_class()` method."
% self.__class__.__name__
)
return self.serializer_class
默认不需要过滤,如果需要过滤需要重写filter_queryset()方法
def filter_queryset(self, queryset):
"""
Given a queryset, filter it with whichever filter backend is in use.
You are unlikely to want to override this method, although you may need
to call it either from a list view, or from a custom `get_object`
method if you want to apply the configured filtering backend to the
default queryset.
"""
for backend in list(self.filter_backends):
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
a、paginator()方法让装饰器@property进行修饰,表示将方法暴露出去变成了属性
b、判断类属性中是否包含pagination_class方法,如果存在pagination_class,则变为pagination_class()方法并且赋值给self._paginator,返回self._paginator
@property
def paginator(self):
"""
The paginator instance associated with the view, or `None`.
"""
if not hasattr(self, '_paginator'):
if self.pagination_class is None:
self._paginator = None
else:
self._paginator = self.pagination_class()
return self._paginator
a、默认不需要分页,如果需要分页需要重写paginate_queryset()方法
b、如果self.paginator 为 None,不需要进行过滤,否则需要通过self.paginator.paginate_queryset()方法进行过滤
def paginate_queryset(self, queryset):
"""
Return a single page of results, or `None` if pagination is disabled.
"""
if self.paginator is None:
return None
return self.paginator.paginate_queryset(queryset, self.request, view=self)
from rest_framework.generics import GenericAPIView
from rest_framework.response import Response
from app2.models import NewsChannel
from app2.serializers1 import NewsChannelSerializer,NewsChannel1Serializer
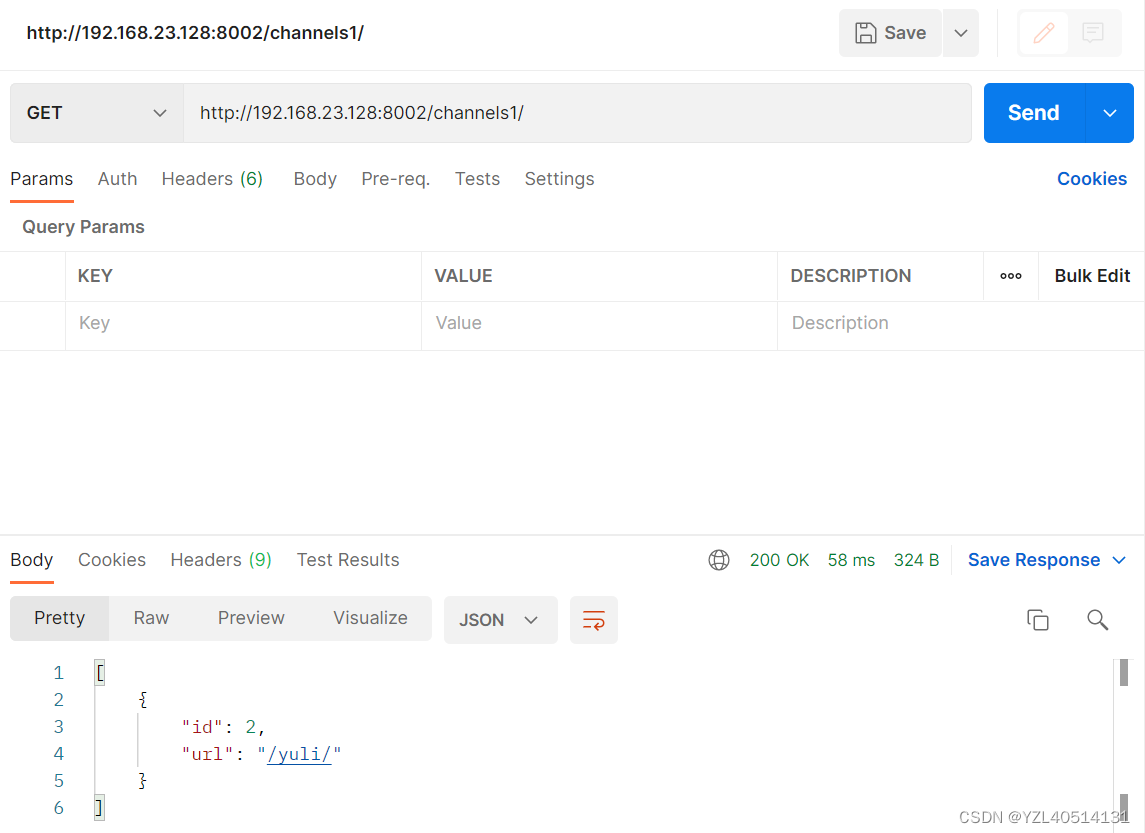
class ChannelsAPIView(GenericAPIView):
queryset = NewsChannel.objects.all()
serializer_class = NewsChannelSerializer
def get_queryset(self):
return NewsChannel.objects.filter(id__exact=2)
def get_serializer_class(self):
return NewsChannel1Serializer
def get(self, request,*args,**kwargs):
queryset=self.get_queryset()
serializer=self.get_serializer(instance=queryset,many=True)
return Response(serializer.data)
def post(self,request):
serializer=self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(serializer.data)


我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我想开始使用“Sinatra”框架进行编码,但我找不到该框架的“MVC”模式。是“MVC-Sinatra”模式或框架吗? 最佳答案 您可能想查看Padrino这是一个围绕Sinatra构建的框架,可为您的项目提供更“类似Rails”的感觉,但没有那么多隐藏的魔法。这是使用Sinatra可以做什么的一个很好的例子。虽然如果您需要开始使用这很好,但我个人建议您将它用作学习工具,以对您来说最有意义的方式使用Sinatra构建您自己的应用程序。写一些测试/期望,写一些代码,通过测试-重复:)至于ORM,你还应该结帐Sequel其中(imho