通过Java API来操作HDFS,完成的操作有:文件上传、文件下载、新建文件夹、查看文件、删除文件。
1.Windows下安装好jdk1.8
2.Windows下安装好maven,这里使用Maven3.6.3
3.Windows下安装好IDEA,这里使用IDEA2021
4.Linux下安装好hadoop2,这里使用hadoop2.7.3
打开IDEA-->File-->New-->Project
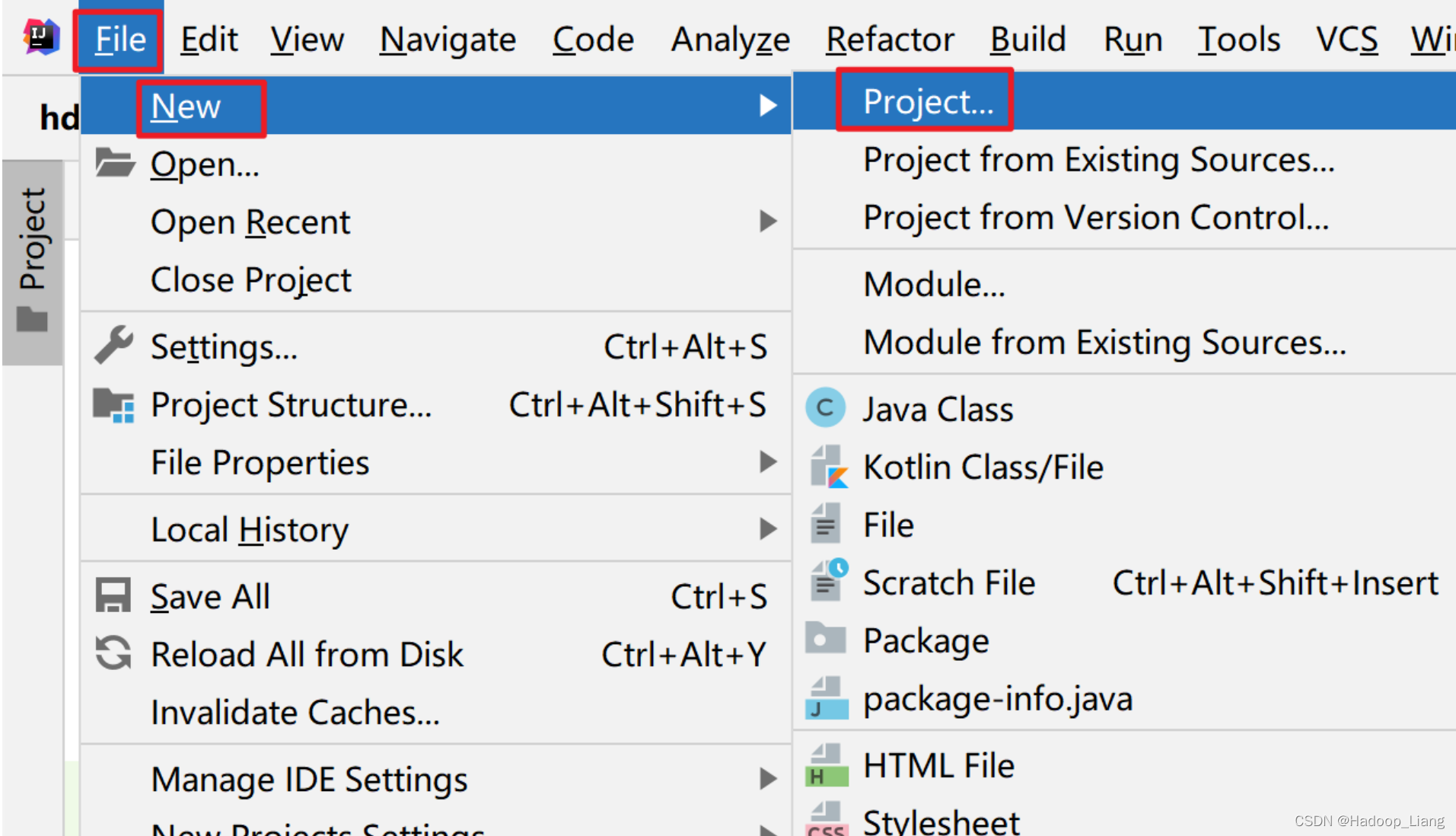
选择Maven-->点击Next
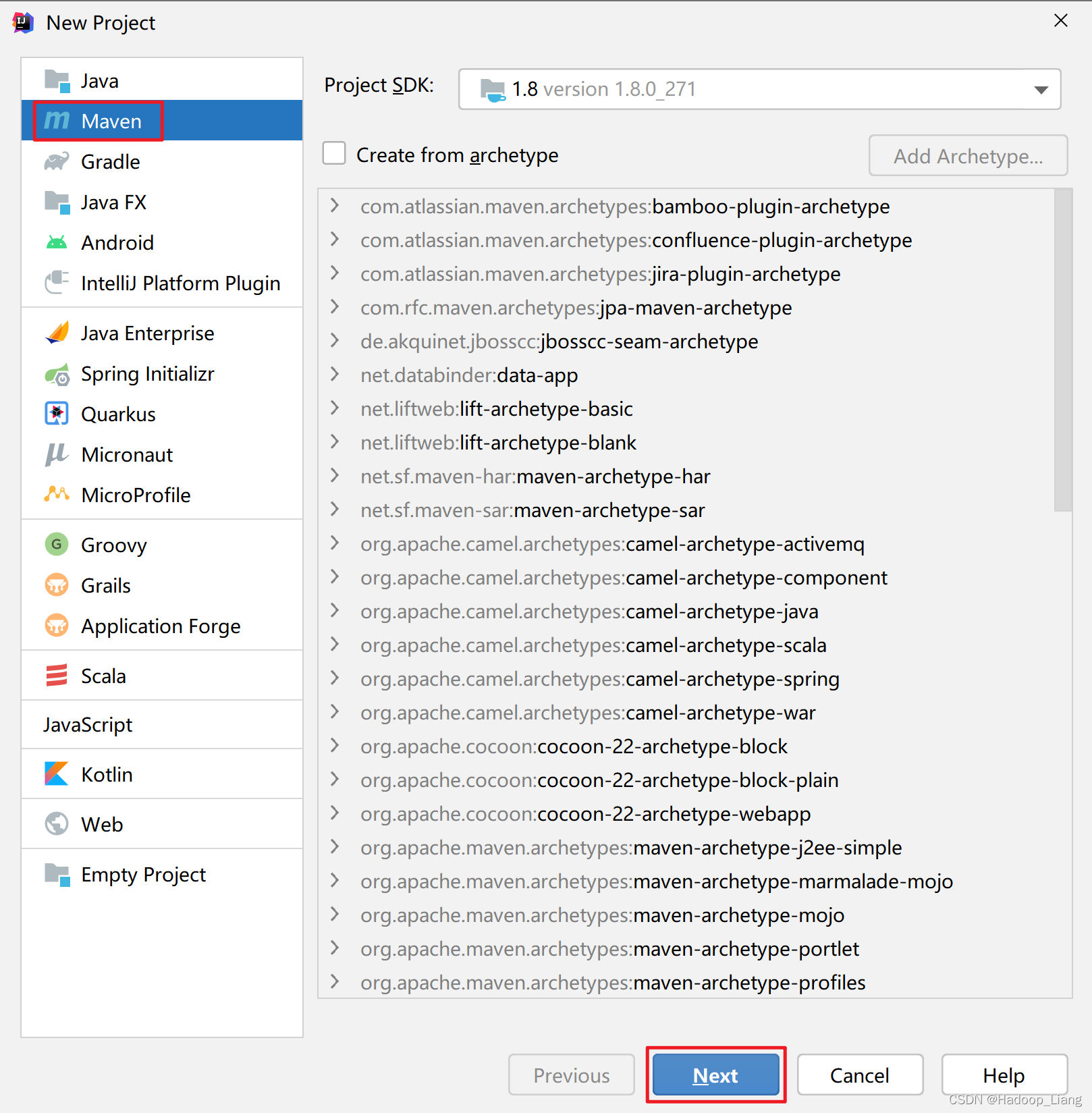
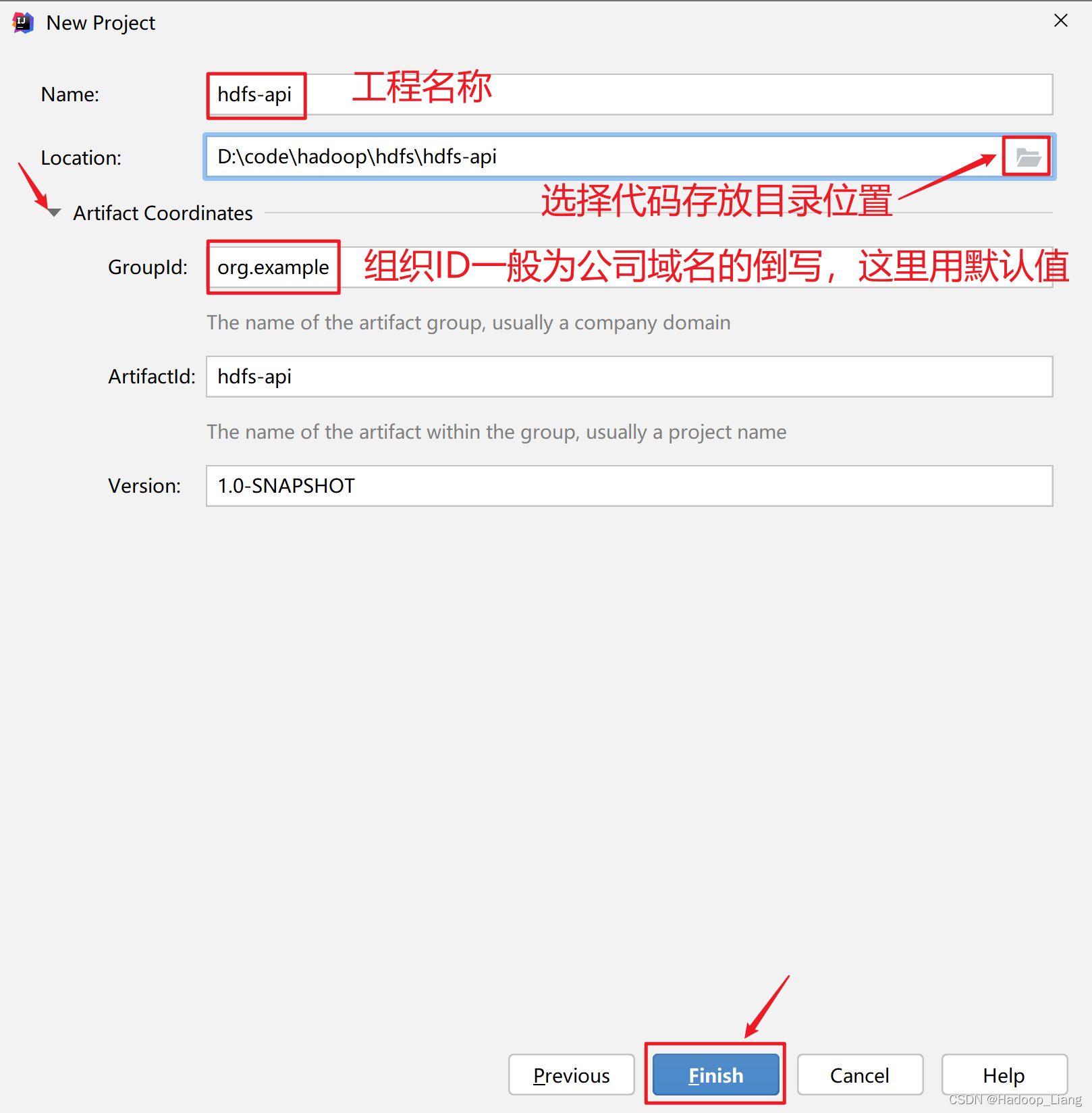
选择工程代码存放目录,这个目录需要为一个空目录,目录名称就是工程名称,可以点击Artifact Coordinates左侧的三角形展开内容后,可以修改组织ID,组织ID一般为公司域名的倒写,例如:域名为baidu.com,组织ID填写com.baidu。这里使用默认值。然后点击Finish按钮完成Maven工程的创建。
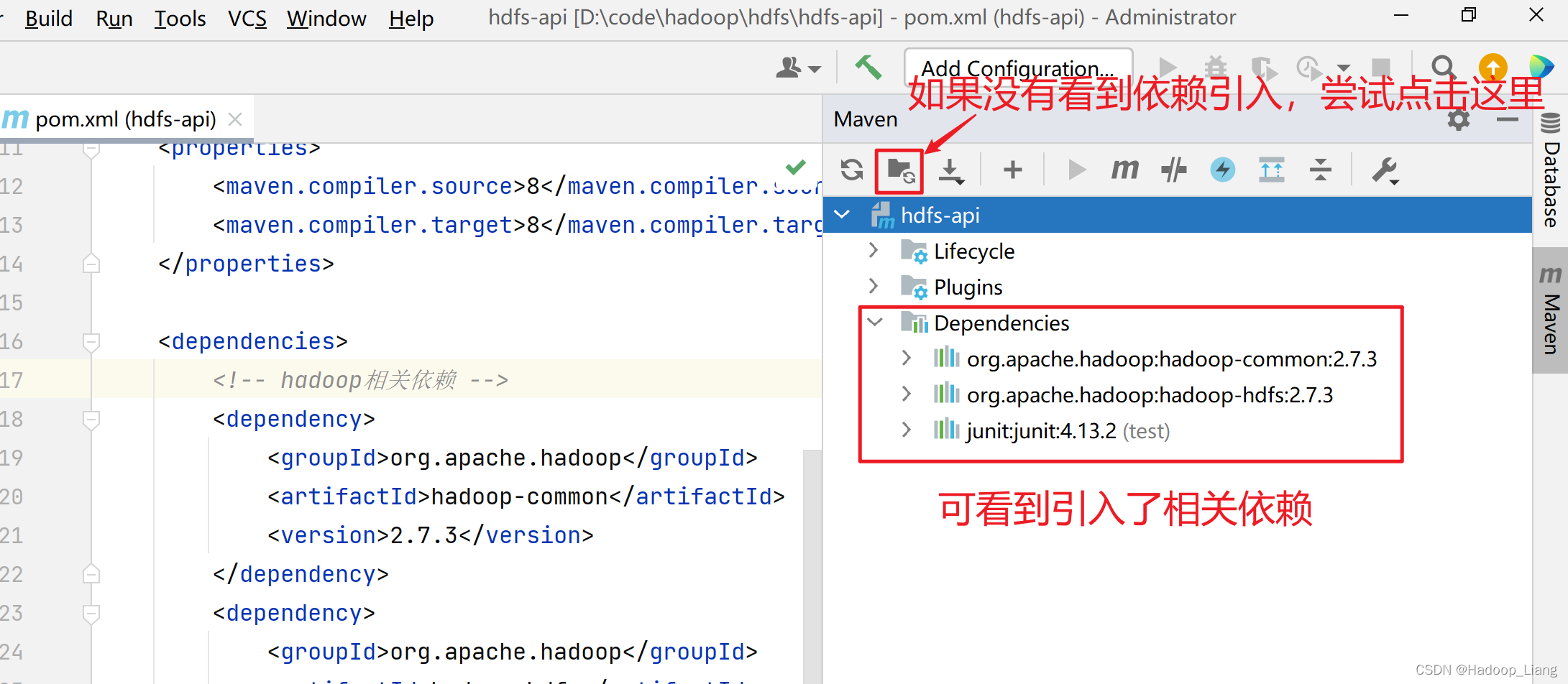
在pom.xml的</project>上一行添加如下依赖:
<dependencies>
<!-- hadoop相关依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<!-- 单元测试依赖 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<!-- log4j依赖 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.17.2</version>
</dependency>
</dependencies>加载依赖
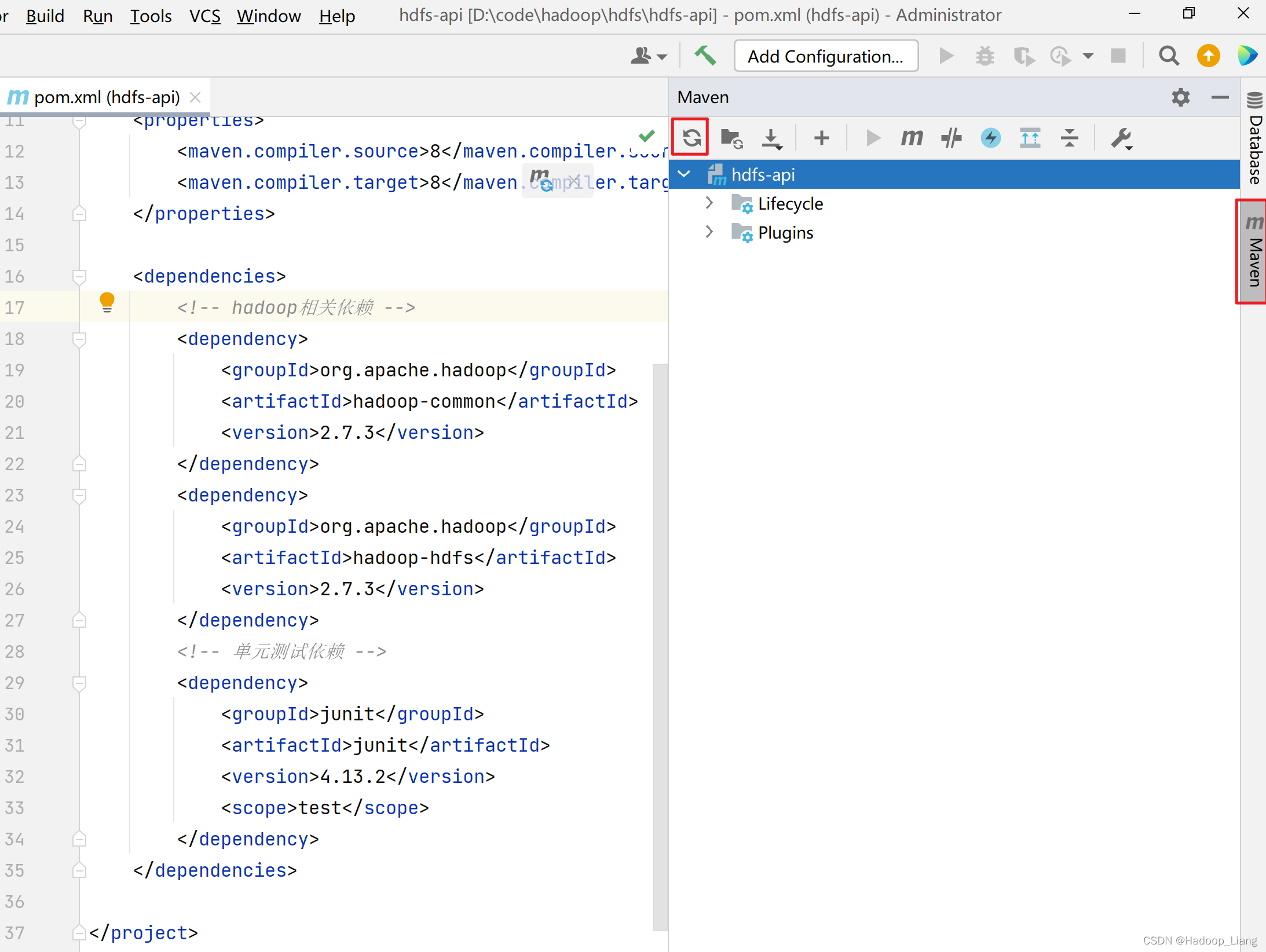
可以看到
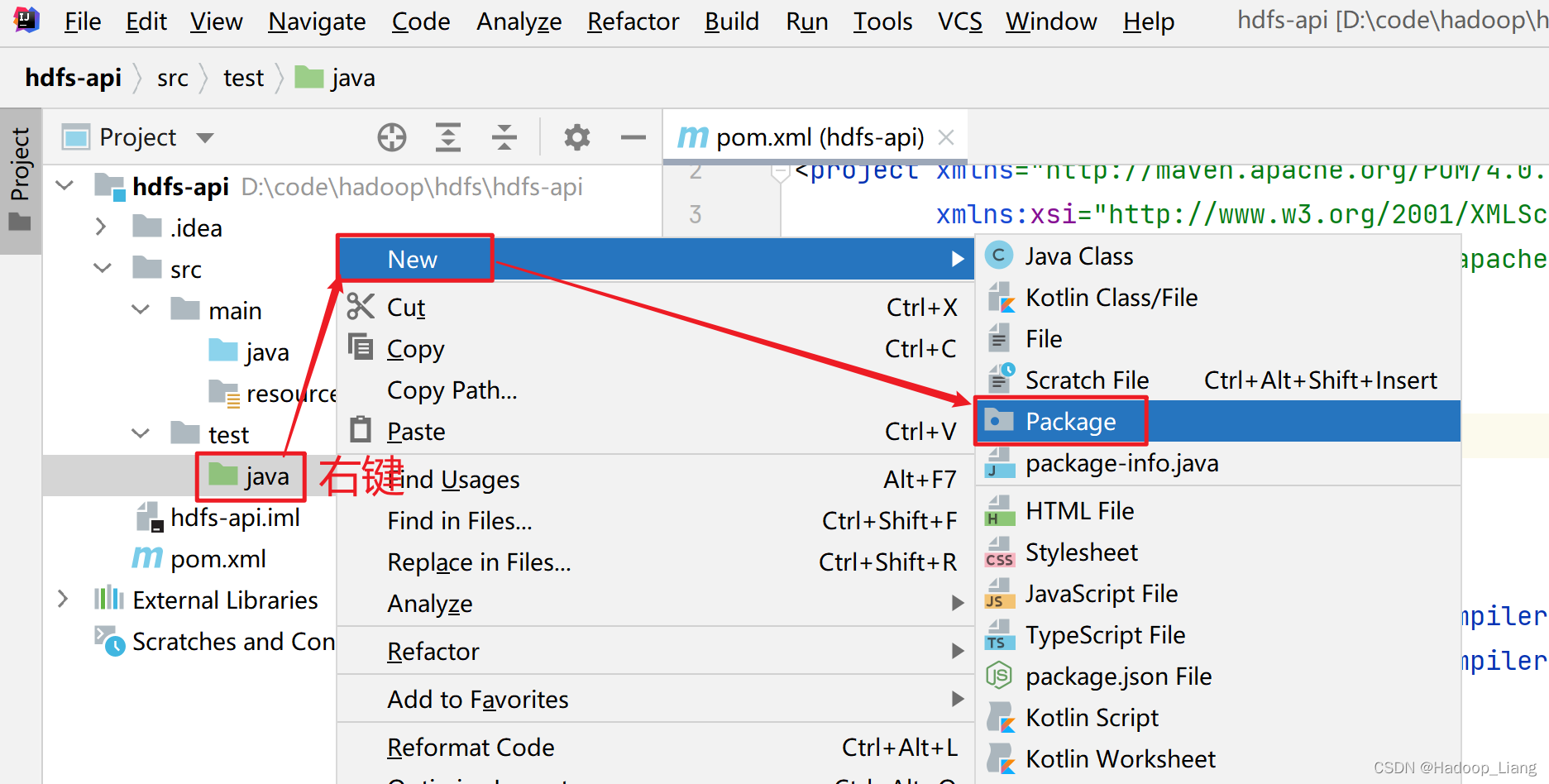
新建包
在src\test\java目录下新建package,包名为GroupID的值:org.example
新建HdfsTest类
新建出的包名处,右键-->New-->Java Class 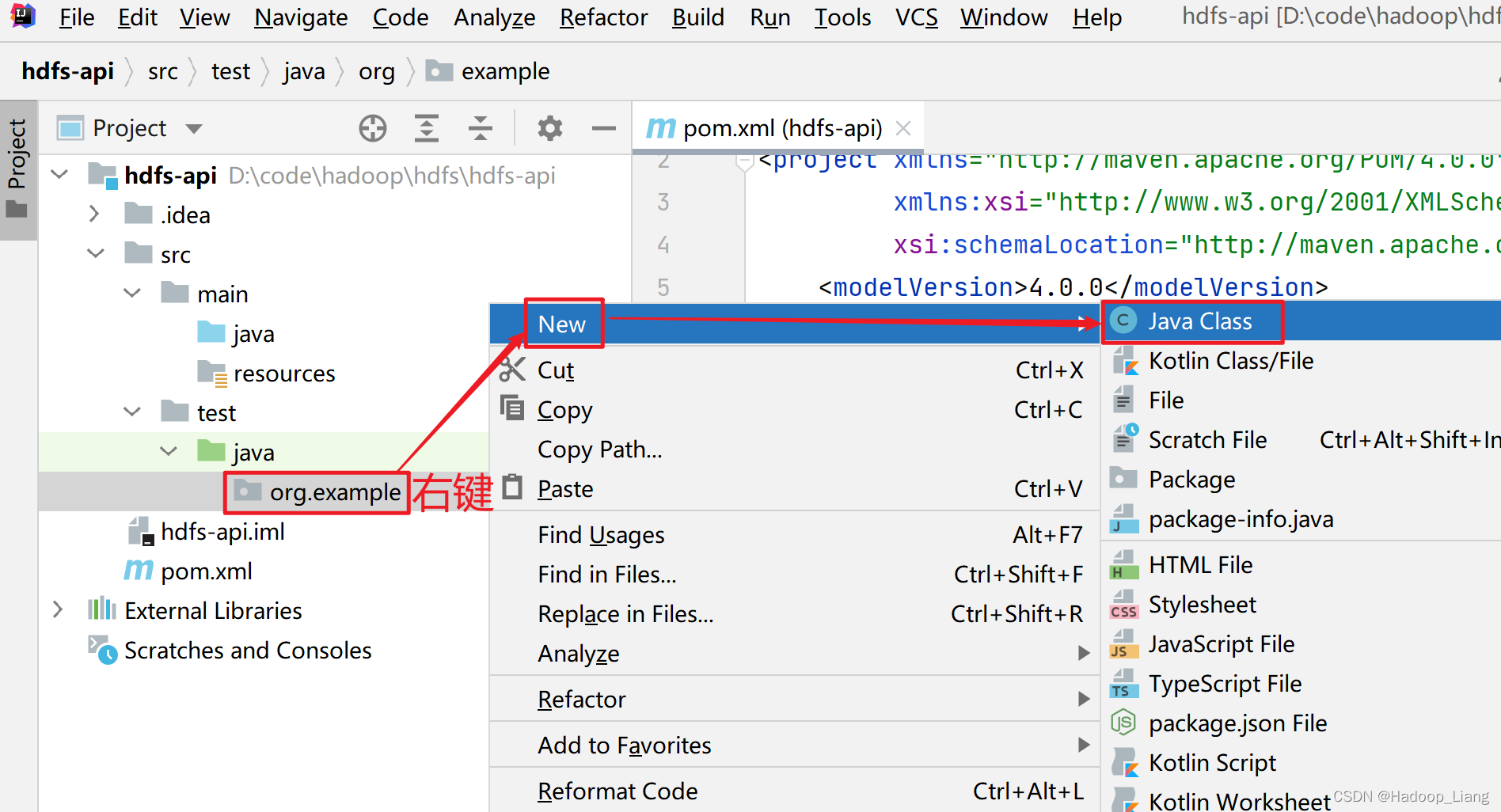
填写类名:HdfsTest
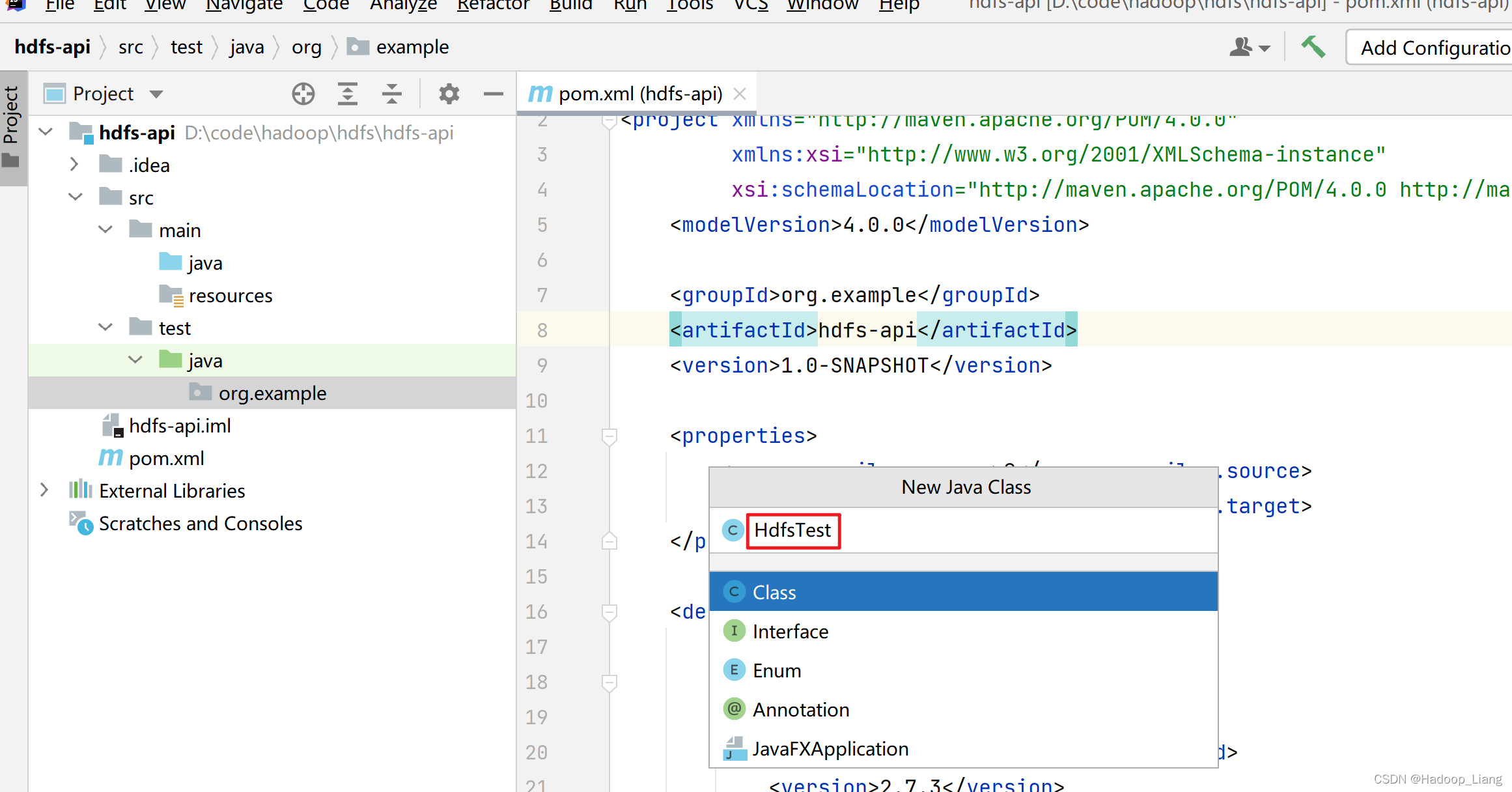
文件上传
将本地D:\test\input\1.txt上传到HDFS的/目录下
在HdfsTest类编写代码,实现文件上传的代码如下:
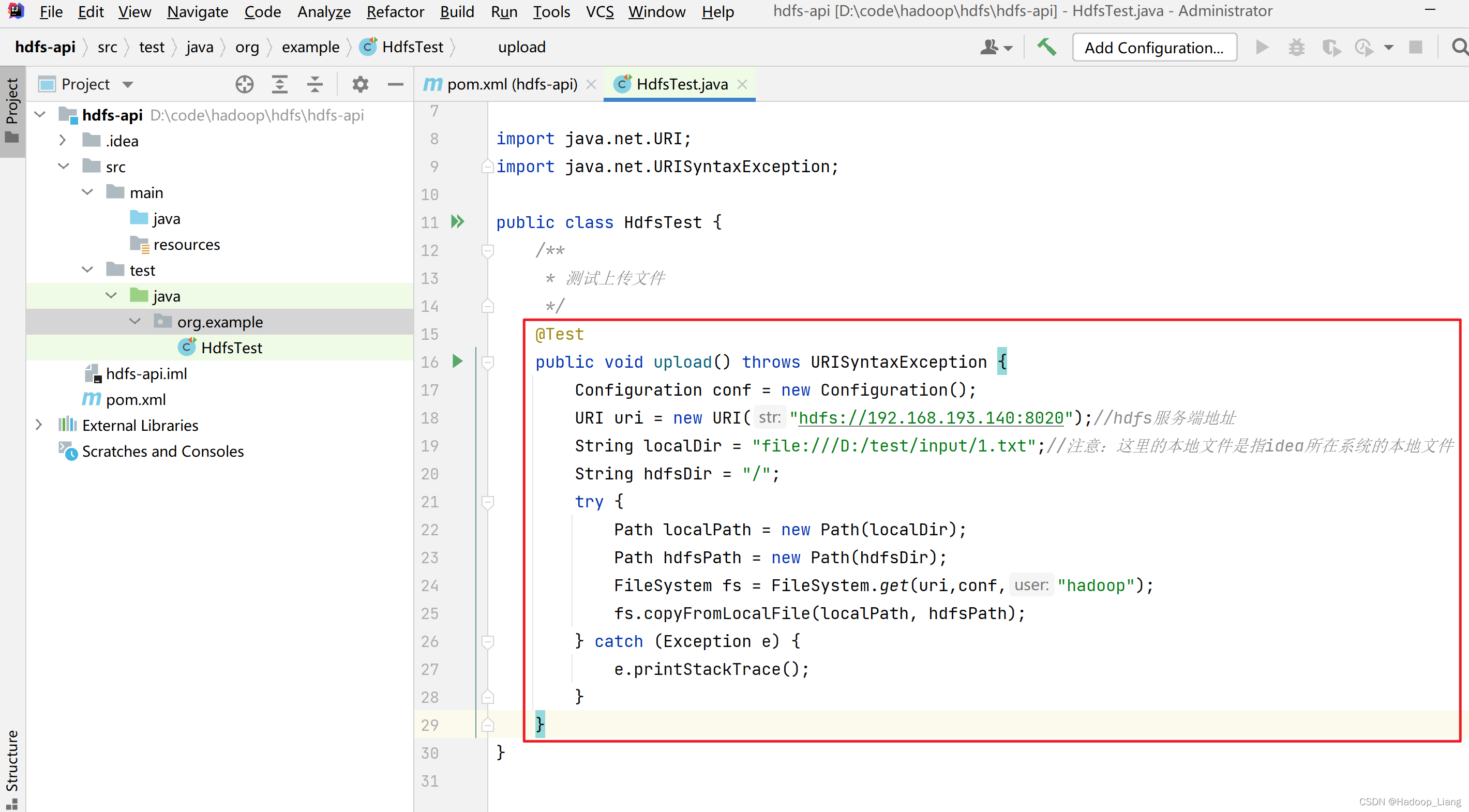
/**
* 测试上传文件
*/
@Test
public void upload() throws URISyntaxException {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://192.168.193.140:8020");//hdfs服务端地址
String localDir = "file:///D:/test/input/1.txt";//注意:这里的本地文件是指idea所在系统的本地文件
String hdfsDir = "/";
try {
Path localPath = new Path(localDir);
Path hdfsPath = new Path(hdfsDir);
FileSystem fs = FileSystem.get(uri,conf,"hadoop");
fs.copyFromLocalFile(localPath, hdfsPath);
} catch (Exception e) {
e.printStackTrace();
}
}
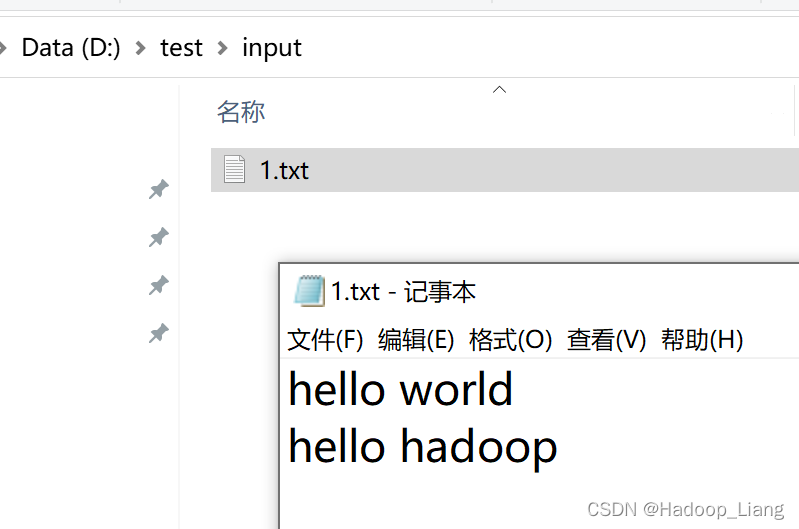
测试前数据准备,在WindowsD:\test\input目录下新建一个1.txt文件,1.txt内容为
hello world hello hadoop
启动hdfs服务
start-dfs.sh
查看HDFS的/目录,没有1.txt文件
[hadoop@node1 ~]$ hdfs dfs -ls / Found 10 items -rw-r--r-- 1 hadoop supergroup 26 2022-03-14 10:48 /2.txt -rw-r--r-- 1 hadoop supergroup 1028 2022-03-15 16:22 /core-site.xml drwxr-xr-x - hadoop supergroup 0 2022-03-14 10:39 /input -rw-r--r-- 3 hadoop supergroup 27 2022-03-16 09:19 /newfile.txt drwxr-xr-x - hadoop supergroup 0 2022-03-14 21:40 /out1 drwxr-xr-x - hadoop supergroup 0 2022-03-18 15:08 /out318 drwxr-xr-x - hadoop supergroup 0 2022-03-18 15:45 /out318-2 drwxr-xr-x - hadoop supergroup 0 2022-03-15 11:05 /output drwxr-xr-x - hadoop supergroup 0 2022-03-14 10:32 /test drwx------ - hadoop supergroup 0 2022-03-18 15:45 /tmp
运行测试,点击upload方法左侧的三角形,然后点击Run 'upload()'运行upload方法
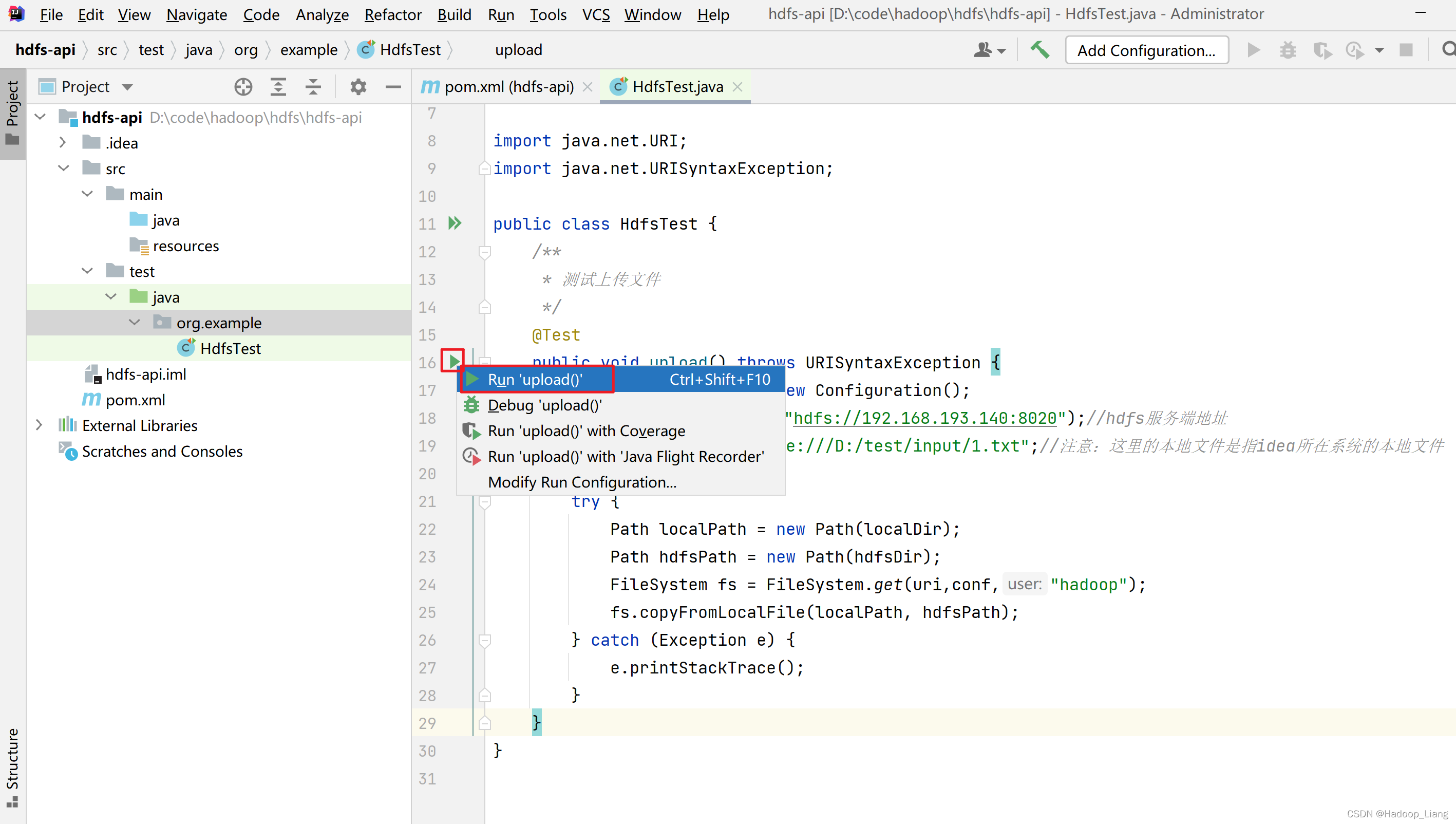
看到Tests passed 或者 Exit code 0 说明运行成功。

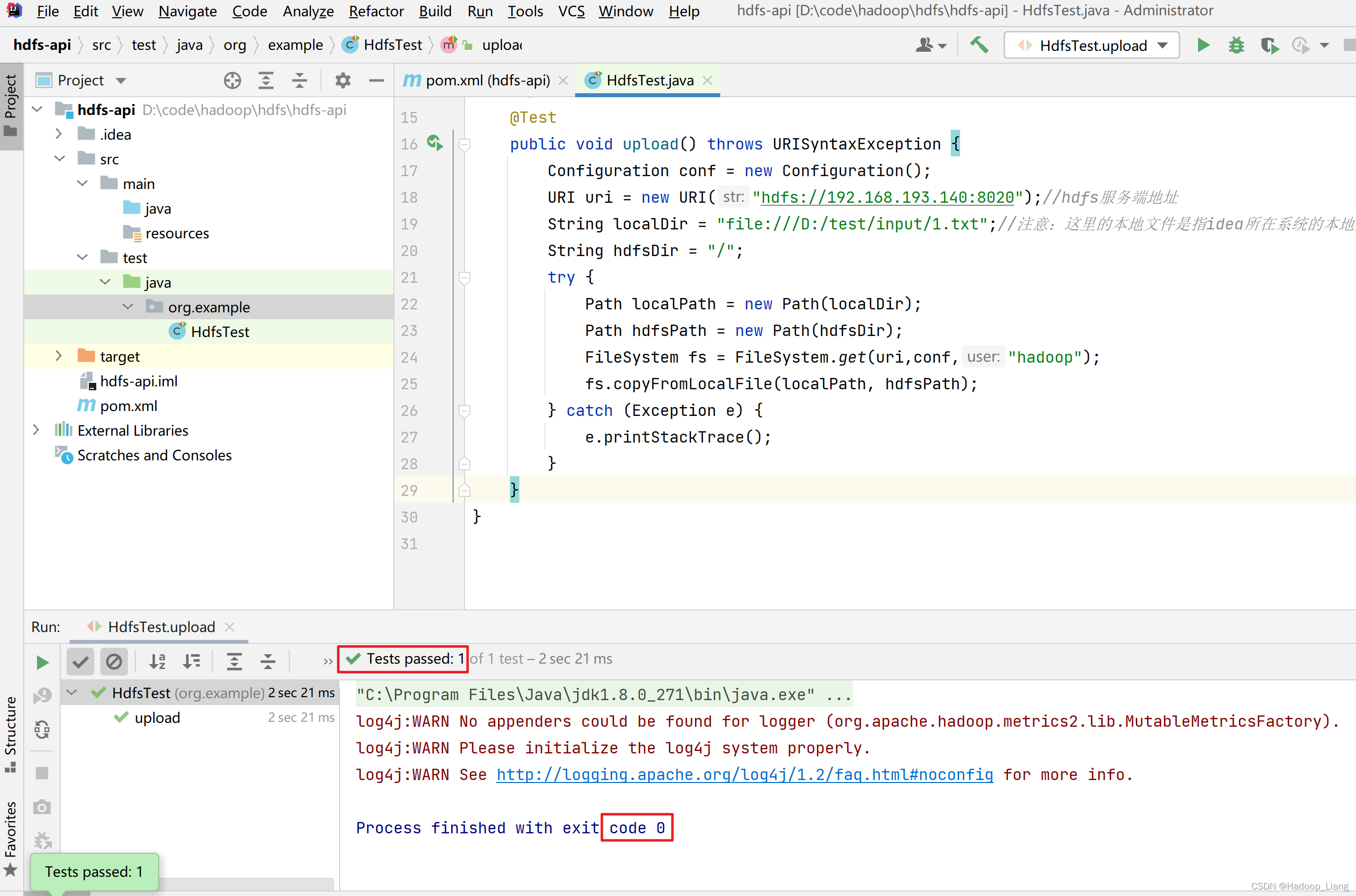
查看HDFS的/目录,发现有1.txt文件
[hadoop@node1 ~]$ hdfs dfs -ls / Found 11 items -rw-r--r-- 3 hadoop supergroup 25 2022-03-21 23:26 /1.txt -rw-r--r-- 1 hadoop supergroup 26 2022-03-14 10:48 /2.txt -rw-r--r-- 1 hadoop supergroup 1028 2022-03-15 16:22 /core-site.xml drwxr-xr-x - hadoop supergroup 0 2022-03-14 10:39 /input -rw-r--r-- 3 hadoop supergroup 27 2022-03-16 09:19 /newfile.txt drwxr-xr-x - hadoop supergroup 0 2022-03-14 21:40 /out1 drwxr-xr-x - hadoop supergroup 0 2022-03-18 15:08 /out318 drwxr-xr-x - hadoop supergroup 0 2022-03-18 15:45 /out318-2 drwxr-xr-x - hadoop supergroup 0 2022-03-15 11:05 /output drwxr-xr-x - hadoop supergroup 0 2022-03-14 10:32 /test drwx------ - hadoop supergroup 0 2022-03-18 15:45 /tmp
查看1.txt文件内容
[hadoop@node1 ~]$ hdfs dfs -cat /1.txt hello world hello hadoop
至此,说明从文件上传成功了。
思考:程序是如何实现文件上传的,核心代码是什么?如果不使用api是否可以自定义实现上传功能的代码?
文件下载
将HDFS /1.txt下载到本地D:\test目录下
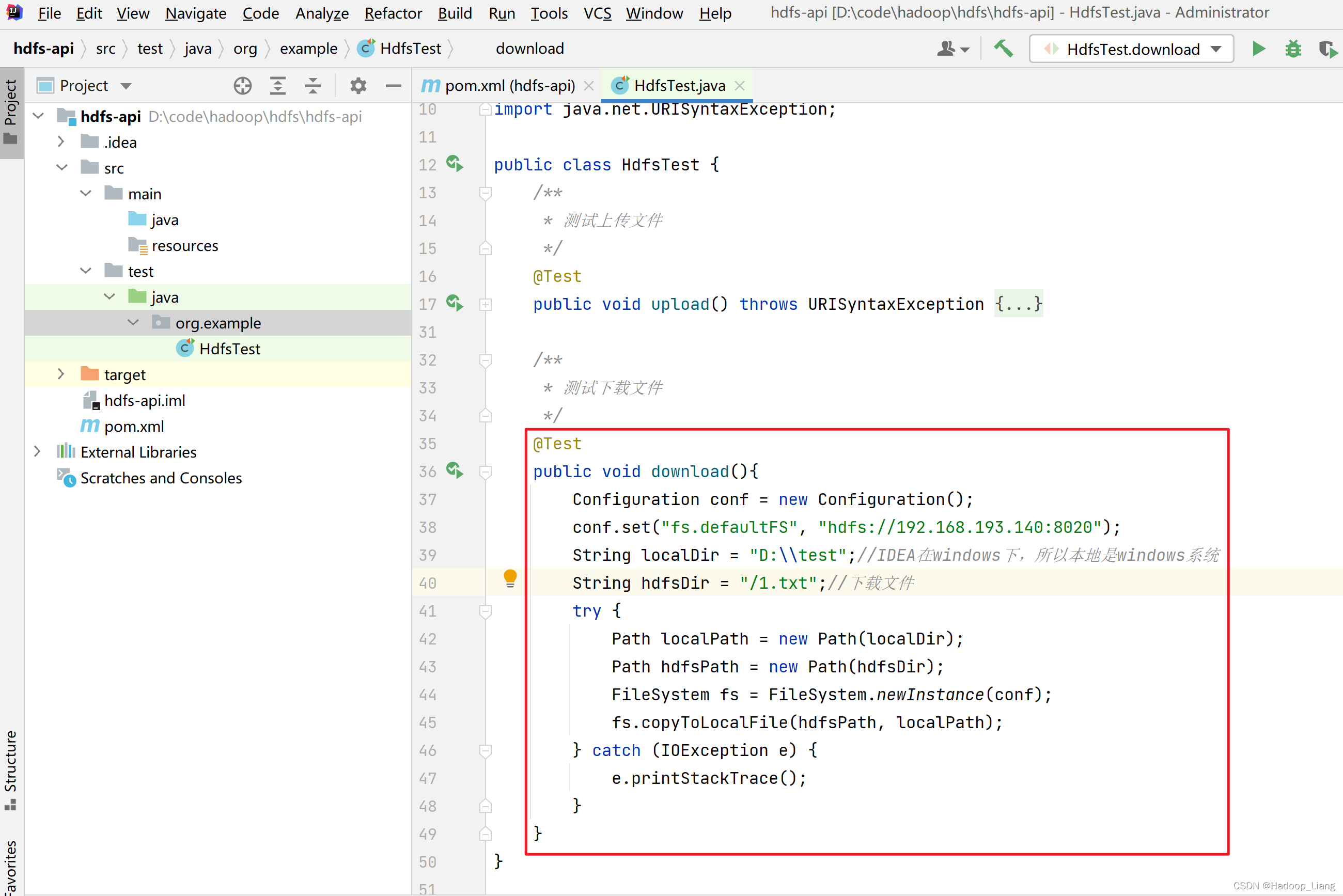
/**
* 测试下载文件
*/
@Test
public void download(){
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.193.140:8020");
String localDir = "D:\\test\\download";//IDEA在windows下,所以本地是windows系统
String hdfsDir = "/1.txt";//下载文件
try {
Path localPath = new Path(localDir);
Path hdfsPath = new Path(hdfsDir);
FileSystem fs = FileSystem.newInstance(conf);
fs.copyToLocalFile(hdfsPath, localPath);
} catch (IOException e) {
e.printStackTrace();
}
}运行测试
查看本地是否成功下载了1.txt文件
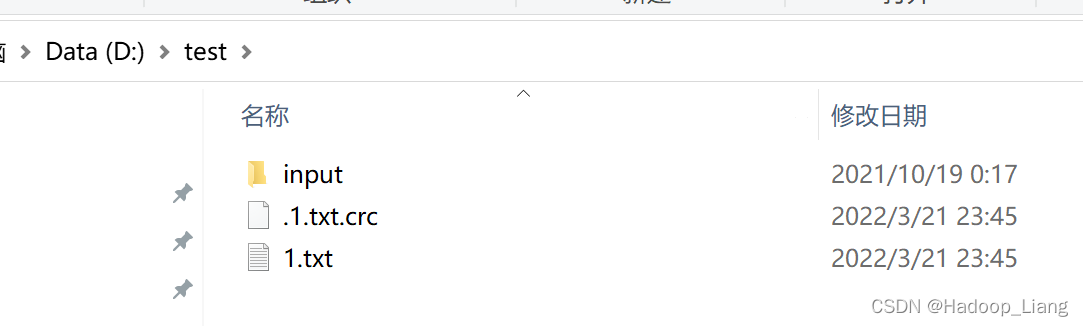
新建文件夹
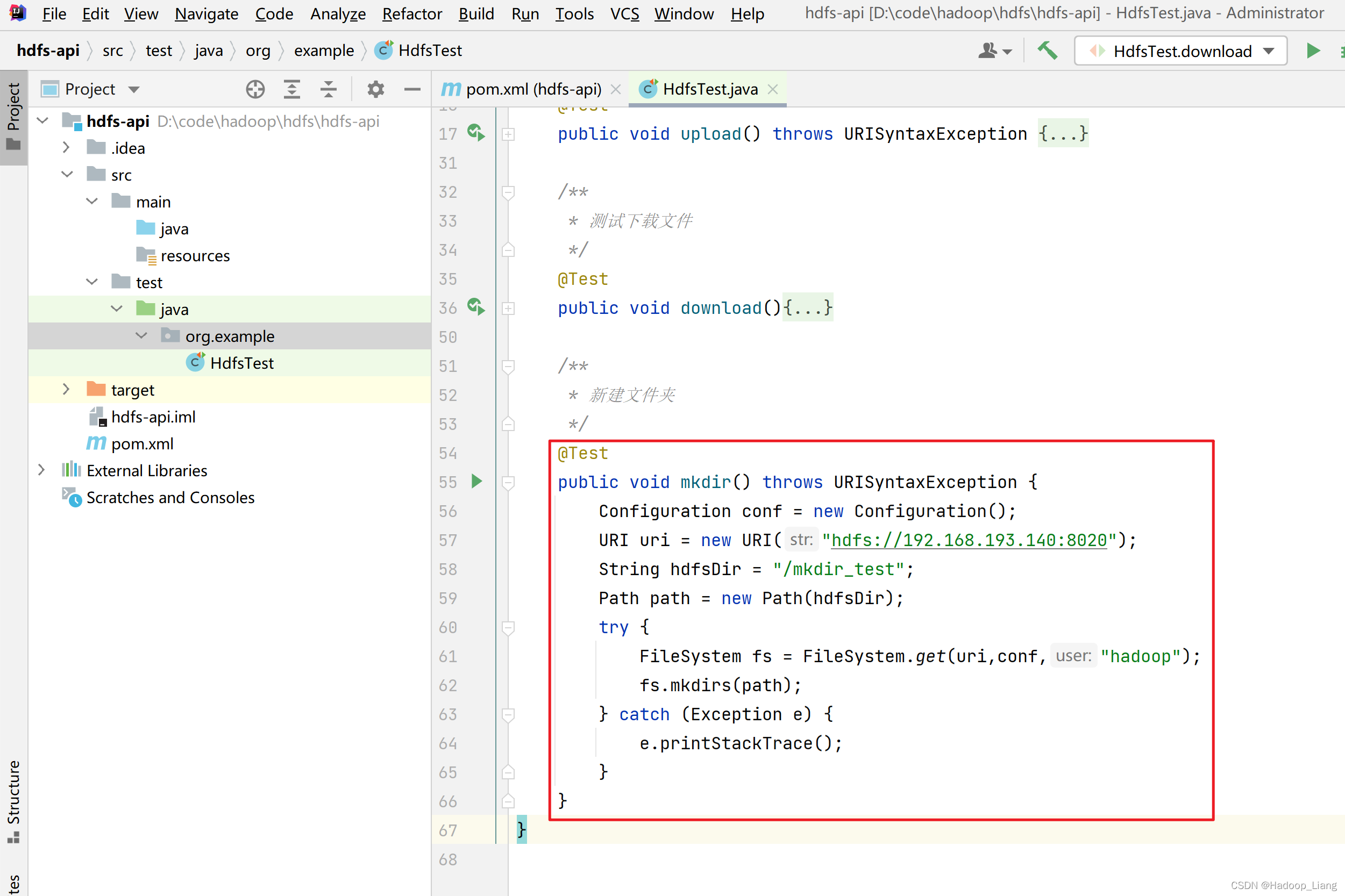
/**
* 新建文件夹
*/
@Test
public void mkdir() throws URISyntaxException {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://192.168.193.140:8020");
String hdfsDir = "/mkdir_test";
Path path = new Path(hdfsDir);
try {
FileSystem fs = FileSystem.get(uri,conf,"hadoop");
fs.mkdirs(path);
} catch (Exception e) {
e.printStackTrace();
}
}运行测试
查看HDFS 是否创建了/mkdir_test
[hadoop@node1 ~]$ hdfs dfs -ls /
Found 12 items
-rw-r--r-- 3 hadoop supergroup 25 2022-03-21 23:26 /1.txt
-rw-r--r-- 1 hadoop supergroup 26 2022-03-14 10:48 /2.txt
-rw-r--r-- 1 hadoop supergroup 1028 2022-03-15 16:22 /core-site.xml
drwxr-xr-x - hadoop supergroup 0 2022-03-14 10:39 /input
drwxr-xr-x - hadoop supergroup 0 2022-03-21 23:51 /mkdir_test
-rw-r--r-- 3 hadoop supergroup 27 2022-03-16 09:19 /newfile.txt
drwxr-xr-x - hadoop supergroup 0 2022-03-14 21:40 /out1
drwxr-xr-x - hadoop supergroup 0 2022-03-18 15:08 /out318
drwxr-xr-x - hadoop supergroup 0 2022-03-18 15:45 /out318-2
drwxr-xr-x - hadoop supergroup 0 2022-03-15 11:05 /output
drwxr-xr-x - hadoop supergroup 0 2022-03-14 10:32 /test
drwx------ - hadoop supergroup 0 2022-03-18 15:45 /tmp
思考:程序是如何实现文件下载的,核心代码是什么?如果不使用api是否可以自定义实现下载功能的代码?
查看文件状态
查看HDFS已存在的目录下的文件和目录,本案例查看的是/user,如果没有/user目录需要自行创建
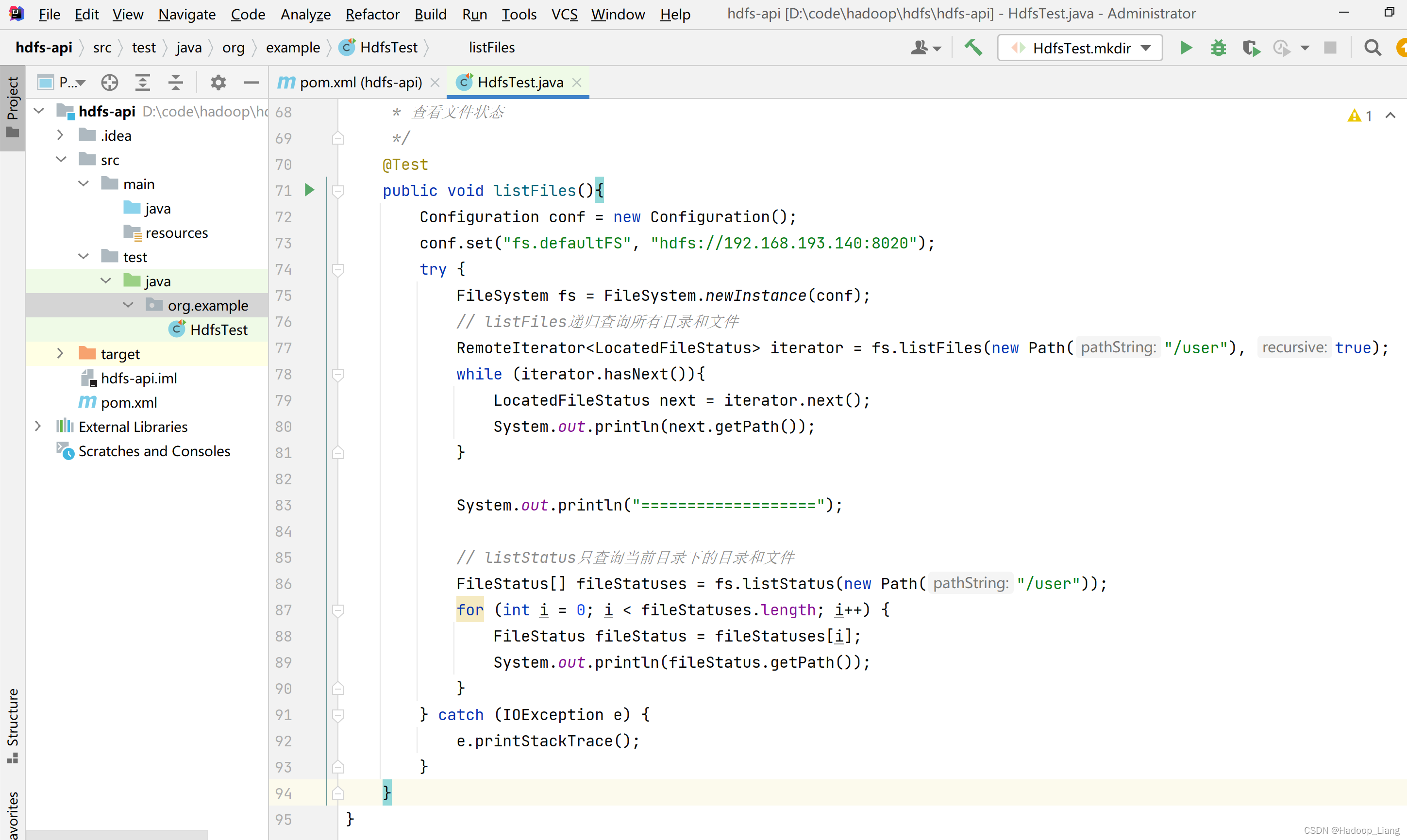
/**
* 查看文件状态
*/
@Test
public void listFiles(){
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.193.140:8020");
try {
FileSystem fs = FileSystem.newInstance(conf);
// listFiles递归查询所有目录和文件
RemoteIterator<LocatedFileStatus> iterator = fs.listFiles(new Path("/user"), true);
while (iterator.hasNext()){
LocatedFileStatus next = iterator.next();
System.out.println(next.getPath());
}
System.out.println("===================");
// listStatus只查询当前目录下的目录和文件
FileStatus[] fileStatuses = fs.listStatus(new Path("/user"));
for (int i = 0; i < fileStatuses.length; i++) {
FileStatus fileStatus = fileStatuses[i];
System.out.println(fileStatus.getPath());
}
} catch (IOException e) {
e.printStackTrace();
}
}思考:这个程序能否运行成功,如果不能运行成功,原因是什么?请自行修改代码并运行成功。
删除文件
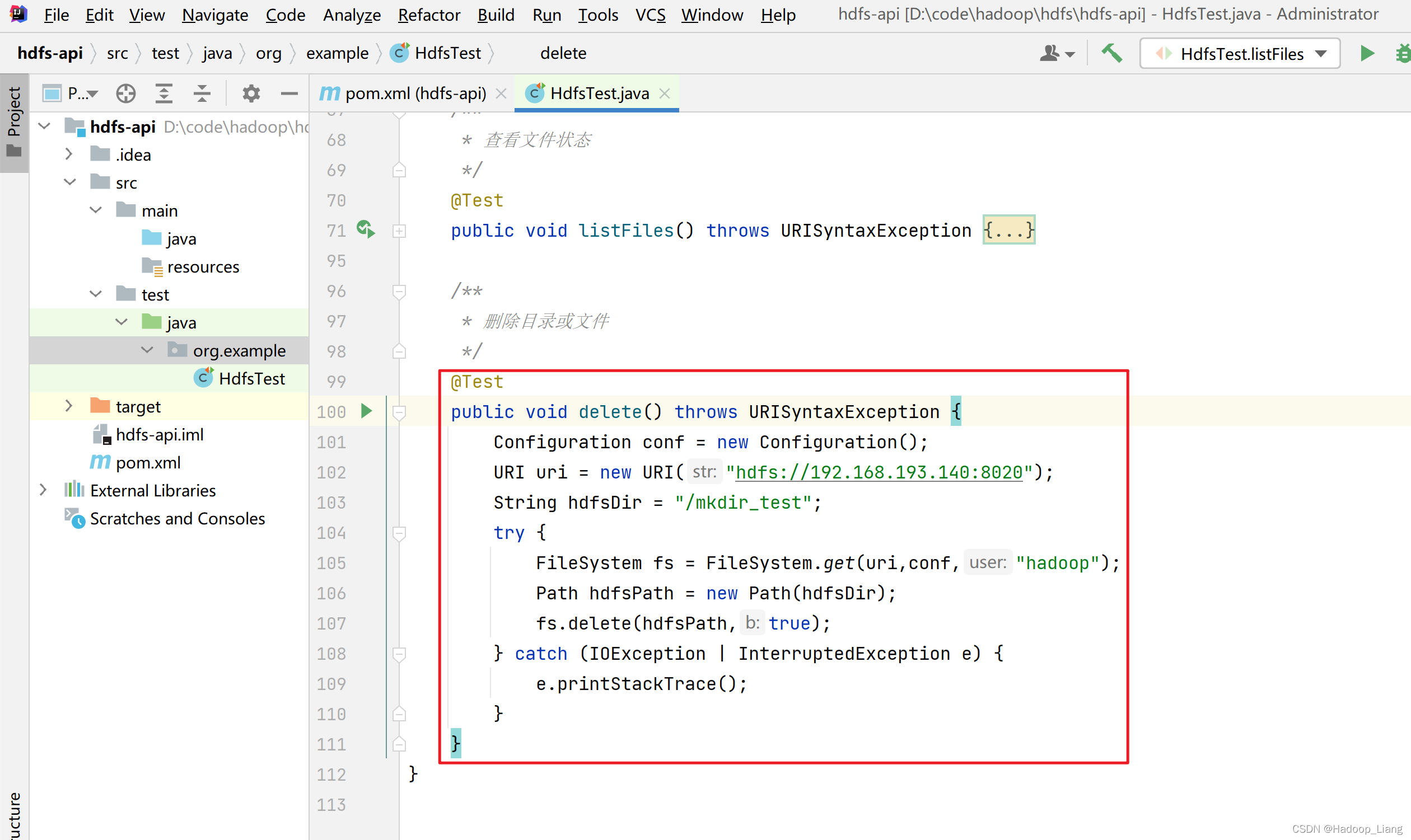
/**
* 删除目录或文件
*/
@Test
public void delete() throws URISyntaxException {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://192.168.193.140:8020");
String hdfsDir = "/mkdir_test";
try {
FileSystem fs = FileSystem.get(uri,conf,"hadoop");
Path hdfsPath = new Path(hdfsDir);
fs.delete(hdfsPath,true);
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
扩展
使用流拷贝方式实现上传和下载
// 采用流拷贝的方式实现上传、下载
/**
* 上传
*/
@Test
public void uploadByIOStream() throws URISyntaxException {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://192.168.193.140:8020");
try {
FileSystem fs = FileSystem.get(uri, conf, "hadoop");
FileInputStream is = new FileInputStream("d:\\test\\data.txt");
FSDataOutputStream os = fs.create(new Path("/input2/data.txt"));//创建一个路径
// 流拷贝
IOUtils.copyBytes(is, os, 1024);
// 关闭资源
is.close();
os.close();
fs.close();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 下载
*/
@Test
public void downloadByIOStream() throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://192.168.193.140:8020");
FileSystem fs = FileSystem.get(uri, conf, "hadoop");
FSDataInputStream is = fs.open(new Path("/input2/1.txt"));//输入流
FileOutputStream os = new FileOutputStream("d:\\test\\1downbyio.txt");
IOUtils.copyBytes(is,os,1024);
is.close();
os.close();
fs.close();
}
完成!enjoy it!
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我有一个非常简单的Controller来管理我的Rails应用程序中的静态页面:classPagesController我怎样才能让View模板返回它自己的名字,这样我就可以做这样的事情:#pricing.html.erb#-->"Pricing"感谢您的帮助。 最佳答案 4.3RoutingParametersTheparamshashwillalwayscontainthe:controllerand:actionkeys,butyoushouldusethemethodscontroller_nameandaction_nam
前言我们习惯用idea编写、调试代码,在LeetCode上刷题时,如果能够在IDEA编写代码,并且做好代码管理,是一件事半功倍的事情。对于后续复习题目,做笔记也会非常便利。本文目的在于介绍LeetCodeEditor的使用,以及配置工具类,最终目录结构如下:note:放置笔记src:放置代码leetcode.editor.cn:插件LeetCodeEditor自动生成utils:自定义的工具包,可用于自动化输入测试用例,定义题目需要的类(结构体)out:运行测试时自动生成LeetCodeEditorGitHub:https://github.com/shuzijun/leetcode-edit
1、接口请求基本操作1.1例子tips在view的选项可以zoomin调整窗口字帖大小。1、创建一个测试的workspace,并命名为test2、test后面新增一个addrequest3、选择发送GET,URL为一个开源的https://api.apiopen.top/api/sentences获取每日一句4、点击send查看内容Tips:如果提示出现Error:tunnelingsocketcouldnotbeestablished,statusCode=407错误,参照以下解决办法)关于tunnelingsocketcouldnotbeestablished,cause=getaddri
Linux操作系统——网络配置与SSH远程安装完VMware与系统后,需要进行网络配置。第一个目标为进行SSH连接,可以从本机到VMware进行文件传送,首先需要进行网络配置。1.下载远程软件首先需要先下载安装一款远程软件:FinalShell或者xhell7FinalShellxhell7FinalShell下载:Windows下载http://www.hostbuf.com/downloads/finalshell_install.exemacOS下载http://www.hostbuf.com/downloads/finalshell_install.pkg2.配置CentOS网络安装好
Ruby语言是否可以用于创建全新的移动操作系统或桌面操作系统,即是否可以用于系统编程? 最佳答案 嗯,现在有一些操作系统使用比C更高级的语言。基本上,ruby解释器本身需要用一些低级的东西来编写,并且需要一些引导加载代码将功能齐全的ruby解释器作为独立内核加载到内存中。一旦ruby解释器被引导并以内核模式(或innerrings之一)运行,就没有什么可以阻止您在其上构建整个操作系统。不幸的是,它可能会很慢。每个操作系统功能的垃圾收集可能会相当引人注目。ruby解释器将负责任务调度和网络堆栈等基本事情,使用垃圾收集框架会大大
假设我们有以下描述一个人的JSON对象:{"firstName":"John","lastName":"Smith","age":25,"address":{"streetAddress":"212ndStreet","city":"NewYork","state":"NY","postalCode":"10021"},"phoneNumber":[{"type":"home","number":"212555-1234"},{"type":"fax","number":"646555-4567"}]有人可以建议在Rails3中操作前一个对象的最优雅和最有效的方法吗?我希望能够:添加另