最近看到了一篇MyBatis的分页实现原理,文章里描述到使用ThreadLocal,其实想主要想看看ThreadLocal的巧妙使用,并且看一下分页是如何实现的。
其实一个简单的分页如下面代码所示,使用PageHelp对象设置分页的参数,然后把查询到的List对象作为参数传入PageInfo对象中,就拿到了分页对象的结果。
@GetMapping("/page")
public Object page() {
//查询第三页,每页三条
PageHelper.startPage(3 , 3);
List<Temperature> temperatures = temperatureDao.selectByExample(null);
//得到分页的结果对象
PageInfo<Temperature> resPage = new PageInfo<>(temperatures);
return resPage;
}
一直跟下去会定位到PageMethod的startPage方法,方法内容为创建一个包含分页参数的page对象,然后放在ThreadLocal中。
/**
* 开始分页
*
* @param pageNum 页码
* @param pageSize 每页显示数量
* @param count 是否进行count查询
* @param reasonable 分页合理化,null时用默认配置
* @param pageSizeZero true且pageSize=0时返回全部结果,false时分页,null时用默认配置
*/
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) {
//构建一个包含分页参数的page对象
//构建一个包含分页参数的page对象
//构建一个包含分页参数的page对象
Page<E> page = new Page<E>(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
//当已经执行过orderBy的时候
Page<E> oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
//把page对象放在ThreadLocal中
//把page对象放在ThreadLocal中
//把page对象放在ThreadLocal中
setLocalPage(page);
return page;
}
即执行dao.select方法
List<Temperature> temperatures = temperatureDao.selectByExample(null);
下一步直接跳到PageInterceptor的intercept方法
@Override
public Object intercept(Invocation invocation) throws Throwable {
try {
//省略内容,省略内容,省略内容
List resultList;
//步骤1:调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
//步骤2:查询总条数
Long count = count(executor, ms, parameter, rowBounds, resultHandler, boundSql);
//处理查询总数,返回 true 时继续分页查询,false 时直接返回
//步骤3:保存总条数
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
//步骤4:执行分页查询
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
//步骤5:封装结果
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
if(dialect != null){
dialect.afterAll();
}
}
}
首先根据PageHelper的skip方法查看是否需要分页,判断条件是ThreadLocal中是否有page对象,因为PageHelper.startPage方法放入到ThreadLocal中放入page对象,因此此处会判断为分页
方法会定位到PageInterceptor的count方法的的代码
count = ExecutorUtil.executeAutoCount(dialect, executor, countMs, parameter, boundSql, rowBounds, resultHandler);
方法executeAutoCount方法如下,
1)首先根据查询语句拼接count语句(select * from table where a —> select count(“0”) from table where a)
2)然后执行SQL
3)拿到count结果
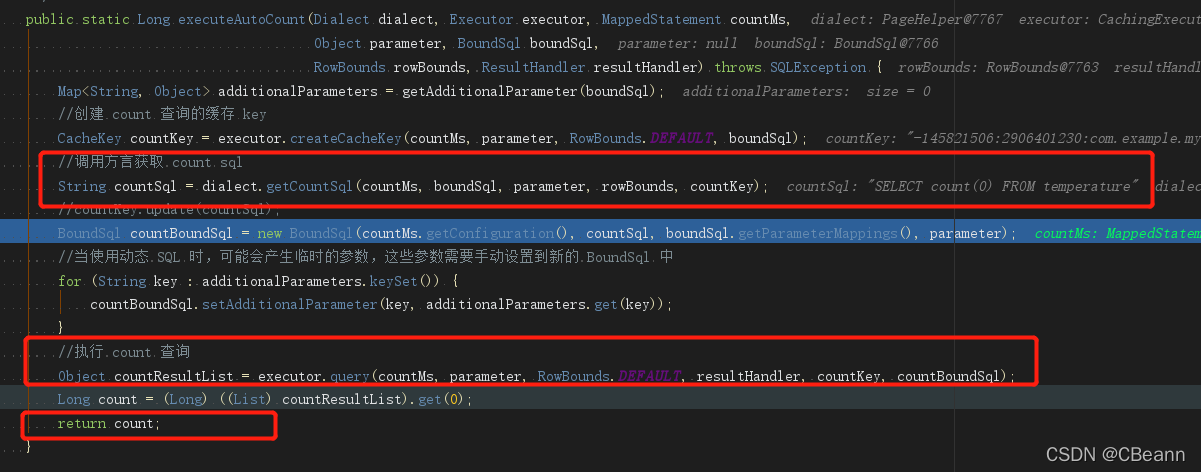
首先从ThreadLocal中获取page对象,然后把总条数count放在page对象中,然后根据总条数和分页条件判断是否有必要查询,比如一共10条记录,你每页10条,你查第2页,那么就没必要去查询,因此11-20条记录不存在。
public boolean afterCount(long count, Object parameterObject, RowBounds rowBounds) {
//获取ThreadLocal中的page对象
Page page = getLocalPage();
//保存count对象
page.setTotal(count);
if (rowBounds instanceof PageRowBounds) {
((PageRowBounds) rowBounds).setTotal(count);
}
//pageSize < 0 的时候,不执行分页查询
//pageSize = 0 的时候,还需要执行后续查询,但是不会分页
if (page.getPageSize() < 0) {
return false;
}
//根据总数量和你分页条件去判断是否有必要去做查询
return count > ((page.getPageNum() - 1) * page.getPageSize());
}
首先获取分页的SQL(slect * from tablle -> select * from table limit ,),然后执行获取到结果

怎么获取分页的SQL呢?简单到没朋友
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sqlBuilder.append(sql);
if (page.getStartRow() == 0) {
sqlBuilder.append(" LIMIT ? ");
} else {
sqlBuilder.append(" LIMIT ?, ? ");
}
return sqlBuilder.toString();
}
还是把查询到的结果放到TheadLocal中的page对象中,然后返回page对象,此时page对象带有查询对象集合、分页条数、第几页。
//AbstractHelperDialect###afterPage
public Object afterPage(List pageList, Object parameterObject, RowBounds rowBounds) {
Page page = getLocalPage();
if (page == null) {
return pageList;
}
page.addAll(pageList);
//省略
return page;
}
首先要明确的是下面代码中的temperatures对象是Page(Page extends ArrayList )类型的,Page集成了ArrayList对象。

下面看PageInfo的构造方法,真是一看吓一跳。首先list参数传入的是Page对象,可以从Page对象中拿到total、pageNum、pageSize和当前页的数据集合,可以进一步算出是否为首页、尾页等其他非必要的分页信息。
public PageInfo(List<T> list, int navigatePages) {
//把list对象强转为page对象,然后获取total总条数对象
super(list);
if (list instanceof Page) {
Page page = (Page) list;
//获取当前第几页
this.pageNum = page.getPageNum();
//获取每页大小
this.pageSize = page.getPageSize();
this.pages = page.getPages();
this.size = page.size();
//由于结果是>startRow的,所以实际的需要+1
if (this.size == 0) {
this.startRow = 0;
this.endRow = 0;
} else {
this.startRow = page.getStartRow() + 1;
//计算实际的endRow(最后一页的时候特殊)
this.endRow = this.startRow - 1 + this.size;
}
} else if (list instanceof Collection) {
this.pageNum = 1;
this.pageSize = list.size();
this.pages = this.pageSize > 0 ? 1 : 0;
this.size = list.size();
this.startRow = 0;
this.endRow = list.size() > 0 ? list.size() - 1 : 0;
}
if (list instanceof Collection) {
this.navigatePages = navigatePages;
//计算导航页
calcNavigatepageNums();
//计算前后页,第一页,最后一页
calcPage();
//判断页面边界
judgePageBoudary();
}
}
首先会把分页参数封装成Page对象放到ThreadLocal中
然后根据SQL进行拼接转换(select * from table where a) ->(select count(“0”)from table where a)和(select * from table where a limit ,)
有了total总条数、pageNum当前第几页、pageSize每页大小和当前页的数据,就可以算出分页的其他非必要信息(是否为首页,是否为尾页,总页数)
ThreadLocal的巧妙使用(big)
据我们所知,Jekyll默认分页仅支持index.html,我想创建blog.html并在那里包含分页。有什么解决办法吗? 最佳答案 如果您创建一个名为/blog的目录并在其中放置一个index.html文件,那么您可以向_config.yml表示paginate_path:"blog/page:num"。不是使用根文件夹中的默认index.html作为分页器模板,而是使用/blog/index.html。分页器将根据需要生成类似/blog/page2/和/blog/page3/的页面。这将使您到达yourwebsite.com/b
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
前言 Slowloris攻击是我在李华峰老师的书——《MetasploitWeb 渗透测试实战》里面看的,感觉既简单又使用,现在这种攻击是很容易被防护的啦。不过我也不敢真刀实战的去试,只是拿个靶机玩玩罢了。 废话还是写在结语里面吧。(划掉)结语可以不看(划掉)Slowloris攻击的原理 Slowloris是一种资源消耗类DoS攻击,它利用部分HTTP请求进行操作。也叫做慢速攻击,这里的慢速并不是说发动攻击慢,而是访问一条链接的速度慢。Slowloris攻击的功能是打开与目标Web服务器的连接,然后尽可能长时间的保持这些连接打开。如果由多台电脑同时发起Slo
目录一、原理部分1、什么是串行通信(1)并行通信与串行通信(2)串行通信的制式(3)串行通信的主要方式 2、配置串口(1)SCON和PCON:串行口1的控制寄存器(2)SBUF:串行口数据缓冲寄存器 (3)AUXR:辅助寄存器编辑(4)ES、PS:与串行口1中断相关的寄存器(5)波特率设置 3、串口框架编写二、程序案例一、原理部分1、什么是串行通信(1)并行通信与串行通信微控制器与外部设备的数据通信,根据连线结构和传送方式的不同,可以分为两种:并行通信和串行通信。并行通信:数据的各位同时发送与接收,每个数据位使用一条导线,这种方式传输快,但是需要多条导线进行信号传输。串行通信:数据一位一
我一整天都在想办法解决这个问题,这让我发疯了。我有两个Rails应用程序,ServerApp和ClientApp。ClientApp使用Hergem通过API从ServerApp获取数据。一切都很好,直到我需要分页信息。这是我用来获取订单的方法(使用kamainari进行分页,使用ransack进行搜索):#ServerAppdefsearch@search=Order.includes(:documents,:client).order('iddesc').search(params[:q])@orders=@search.result(distinct:true).page(par
例如,我一直看到称为String#split的方法,但从未见过String.split,这似乎更合乎逻辑。或者甚至可能是String::split,因为您可以认为#split位于String的命名空间中。当假定/隐含类(#split)时,我什至单独看到了该方法。我知道这是ri中识别方法的方式。哪个先出现?例如,这是为了区分方法和字段吗?我还听说这有助于区分实例方法和类方法。但这从哪里开始呢? 最佳答案 不同之处在于您如何访问这些方法。类方法使用::分隔符来表示消息可以发送到类/模块对象,而实例方法使用#分隔符表示消息可以发送到实例对
1、为什么压缩的原始数据一般采用YUV格式(1)利用人对图片感觉的生理特性,对于亮度信息比较敏感,对于色度信息不太敏感,所以视频编码是将Y分量和UV分量分开来编码,并且可以减少UV分量.2、视频压缩原理(1)空间冗余:图像相邻像素之间的相关性,比如一帧图片被划分成多个16x16的块之后,相邻的块之间有很多明显的相似性。(2)时间冗余:时间相差较近的两张图片变化较小。(3)视觉冗余:我们的眼睛对某些细节不太敏感,对图像中的高频信息的敏感度小于低频信息,可以去除一些高频信息。(4)编码冗余:一幅图片中不同像素出现的概率是不同的,对于出现次数较多的像素,用少的位数来编码,对于出现次数较少的像素,用多
Python程序运行原理Python是一种脚本语言,编辑完成的程序,也称源代码,可以直接运行。从计算机的角度看,Python程序的运行过程包含两个步骤:解释器将源代码翻译成字节码(即中间码),然后由虚拟机解释执行。Python程序文件的扩展名通常为.py。在执行时,首先由Python解释器将.py文件中的源代码翻译成中间码,这个中间码是一个扩展名为.pyc的文件,再由Python虚拟机(PythonVirtualMachine,PVM)逐条将中间码翻译成机器指令执行。需要说明的是,pyc文件保存在Python安装目录的pycache文件夹下,如果Python无法在用户的计算机上写人字节码,字节
有什么方法可以禁用或设置rubyNet-SSH连接的页面长度,这样我们就不必更改远程设备上的设置了吗?在Cisco路由器中,我们将使用参数“terminallength0”来完成此操作,但在其他服务器上,我们不能使用任何类似的命令。这可以通过Net-SSHlib设置吗? 最佳答案 假设远程端有一个shell,那么终端高度在LINES环境变量中设置。您可以尝试这样设置:Net::SSH.start('hostname','user')do|ssh|ssh.exec!('LINES=50your-command-here')end如
我有一个页面,用于通过使用提供的表格提交数据来搜索列表。表单参数通过ajax(post请求)提交,在搜索表中创建一条新记录,然后通过show显示列表(动态地,在提交表单的同一页面上)此记录的操作。结果有kaminari提供的分页链接,如下所示:{:controller=>'searches',#Ihavetospecifytheidbecausemysearchesarestoredinthedatabase:action=>'show',:id=>search.id},:remote=>true%>请注意,分页链接是动态包含在页面中的。因此,当我进行新搜索并获得新列表时,服务器会重新