摘要:对于池化层和步长为2的卷积层来说,个人的理解是这样的,池化层是一种先验的下采样方式,即人为的确定好下采样的规则;而对于步长为2的卷积层来说,其参数是通过学习得到的,采样的规则是不确定的。
本文分享自华为云社区《对于池化层和步长为2的卷积层的一些思考》,作者: 李长安。
对于池化层和步长为2的卷积层的思考源于前一段时间对于2.0文档API的评估。自从ResNet开始,大家逐渐使用步长为2的卷积层替代Size为2的池化层,二者都是对特征图进行下采样的操作。池化层的主要意义(目前的主流看法,但是有相关论文反驳这个观点)在于invariance(不变性),这个不变性包括平移不变性、尺度不变性、旋转不变形。其过程如下图所示。
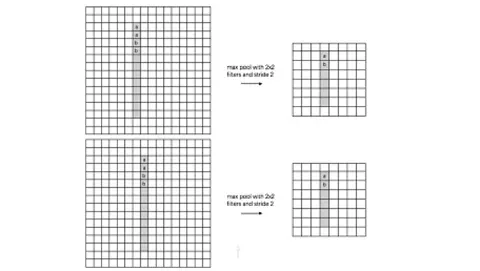
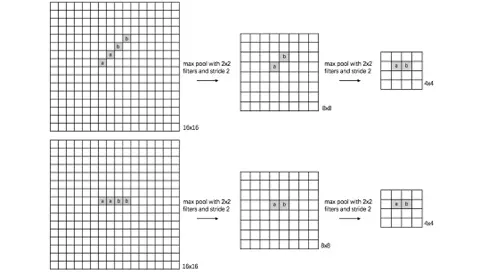
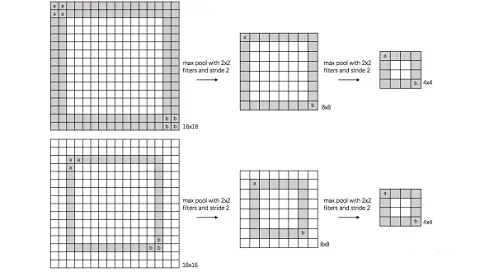
对于池化层和步长为2的卷积层来说,个人的理解是这样的,池化层是一种先验的下采样方式,即人为的确定好下采样的规则;而对于步长为2的卷积层来说,其参数是通过学习得到的,采样的规则是不确定的。下面对两种下采样方式进行一组对比实验,实验设计的可能不够严谨,欢迎大家在评论区讨论。
本次对比实验采用LeNet进行对比,目的在于简单的说明池化层与步长为2的卷积层之前的区别。采用MNIST数据集。
import paddle
print(paddle.__version__)
2.0.0-rc0train_dataset = paddle.vision.datasets.MNIST(mode='train')
test_dataset = paddle.vision.datasets.MNIST(mode='test')%matplotlib notebook
import numpy as np
import matplotlib.pyplot as plt
train_data0, train_label_0 = train_dataset[0][0],train_dataset[0][1]
train_data0 = train_data0.reshape([28,28])
plt.figure(figsize=(2,2))
plt.imshow(train_data0, cmap=plt.cm.binary)
print('train_data0 label is: ' + str(train_label_0))import paddle.nn.functional as F
class LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)
self.max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.linear1 = paddle.nn.Linear(in_features=16*5*5, out_features=120)
self.linear2 = paddle.nn.Linear(in_features=120, out_features=84)
self.linear3 = paddle.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.max_pool2(x)
# print(x.shape)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
x = self.linear3(x)
return xfrom paddle.metric import Accuracy
model2 = paddle.Model(LeNet()) # 用Model封装模型
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model2.parameters())
# 配置模型
model2.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy(topk=(1, 2))
)# 训练模型
model2.fit(train_dataset,
epochs=10,
batch_size=64,
verbose=1
)model2.evaluate(test_dataset, batch_size=64, verbose=1)
Eval begin...
step 157/157 [==============================] - loss: 1.4789e-05 - acc_top1: 0.9810 - acc_top2: 0.9932 - 3ms/step
Eval samples: 10000
{'loss': [1.4788801e-05], 'acc_top1': 0.981, 'acc_top2': 0.9932}import paddle.nn.functional as F
class LeNet_nopool(paddle.nn.Layer):
def __init__(self):
super(LeNet_nopool, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)
# self.max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1)
self.conv4 = paddle.nn.Conv2D(in_channels=16, out_channels=16, kernel_size=3, stride=2)
# self.max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.linear1 = paddle.nn.Linear(in_features=16*5*5, out_features=120)
self.linear2 = paddle.nn.Linear(in_features=120, out_features=84)
self.linear3 = paddle.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.conv1(x)
# print(x.shape)
x = F.relu(x)
x = self.conv2(x)
# print(x.shape)
x = F.relu(x)
x = self.conv3(x)
# print(x.shape)
x = F.relu(x)
x = self.conv4(x)
# print(x.shape)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
x = self.linear3(x)
return xfrom paddle.metric import Accuracy
model3 = paddle.Model(LeNet_nopool()) # 用Model封装模型
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model3.parameters())
# 配置模型
model3.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy(topk=(1, 2))
)
# 训练模型
model3.fit(train_dataset,
epochs=10,
batch_size=64,
verbose=1
)model3.evaluate(test_dataset, batch_size=64, verbose=1)
Eval begin...
step 157/157 [==============================] - loss: 1.7807e-06 - acc_top1: 0.9837 - acc_top2: 0.9964 - 3ms/step
Eval samples: 10000
{'loss': [1.7806786e-06], 'acc_top1': 0.9837, 'acc_top2': 0.9964}从两者在MNIST测试集上的结果来看,使用步长为2的卷积层替代池化层,其模型的表现略高于原始的LeNet5。表明使用卷积层代替池化层是对模型表现有较好的提升。但是改进之后的LeNet5在参数量上是高于原始的LeNet5的,
#改进的LeNet5
print('# model3 parameters:', sum(param.numel() for param in model3.parameters()))
# model3 parameters: Tensor(shape=[1], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[66346])
#原始的LeNet5
, dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[66346])
```python
#原始的LeNet5
print('# model2 parameters:', sum(param.numel() for param in model.parameters()))
# model2 parameters: Tensor(shape=[1], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[61706])(1)从图像成像角度来看,图像在成像过程中接收模拟信号变成电信号再存储的阵列都不是同时的。即图片上每一点都是有时序的。结合图像的时域信息进行多模态训练可能会有突破。
(2)在图像中应用香农定理,下采样越多,信息丢失越多,对于CNN中池化层的讨论,大家可以参考:CNN真的需要下采样(上采样)吗?
(3)对于池化层不一样的看法,证伪:CNN中的图片平移不变性
(4)实际上已经有众多大佬对这个进行过论证,但是对于大家来说,自己动手永远比听别人讲来得更好,希望能和大家一起成长。
文章目录背景一、最初的疑惑二、简单聊聊原理三、组织内实践案例四、实践带来的反思五、最后聊几句问题背景这个概念由来已久,但是在国内兴起,是最近几年;低代码即Low-Code;指提供可视化开发环境,可以用来创建和管理软件应用;简单的说就是可以通过各种组件的拖拽,实现页面的创建,交互流程和逻辑,以及数据层面的管理,更加高效的实现需求;早先在数据公司时;见识过低代码的应用,也参与过部分研发,比如元数据平台,BI分析等;不过,当时还是以数据管理的工具来定义项目,并非是低代码;从「2020年底」开始;实际上,那个时间节点,低代码平台的应用已经形成趋势了;现在的公司,将低代码平台的使用规划到业务体系中;后来
目录文章信息写在前面Background&MotivationMethodDCNV2DCNV3模型架构Experiment分类检测文章信息Title:InternImage:ExploringLarge-ScaleVisionFoundationModelswithDeformableConvolutionsPaperLink:https://arxiv.org/abs/2211.05778CodeLink:https://github.com/OpenGVLab/InternImage写在前面拿到文章之后先看了一眼在ImageNet1k上的结果,确实很高,超越了同等大小下的VAN、RepLK
我正在寻找一种有效的方法,在Ruby1.9.x/Rails3.2.x中,以一个小时的步长在两个DateTime对象之间进行迭代。('2013-01-01'.to_datetime..'2013-02-01'.to_datetime).step(1.hour)do|date|...end我知道这个问题是1.hour只是秒数,但我尝试将其转换为DateTime对象并将其用作步骤也不起作用.我查看了“BewareofRubySugar”。它在底部附近提到DateTime有一个直接的step方法。我通过在DateTime对象上运行methods来确认这一点,但是我在DateTime中找不到任何
我有一个具有以下属性的slider:水平方向一个handle最少2最多65我的目标是强制用户仅在7个点(例如:“2、3、4、26、39、52、65”)之间进行选择,仅此而已。如何创建动态步长或如何只允许这些点作为slider步长? 最佳答案 为什么不使用只有7个点的slider,并用表格转换您的值:查看我的jsfiddle示例http://jsfiddle.net/bouillard/Uy5sD/ 关于javascript-JquerySliderUI动态步长,我们在StackOverf
【摘 要】近年来,基于自注意力机制的神经网络在计算机视觉任务中得到广泛的应用。随着智能交通系统的广泛应用,面对复杂多变的交通场景,车牌识别任务的难度不断提高,准确识别的需求更加迫切。因此提出一个基于自注意力的免矫正的车牌识别方法T-LPR。首先对图像进行切片和序列化,并使用3D卷积对切片序列进行特征提取,从而得到图像的嵌入向量序列。然后将嵌入向量序列输入基于TransformerEncoder的编码器中,学习各个嵌入向量之间的关系并输出最终的编码结果。最后使用分类器进行分类。在多个公共数据集上的实验结果表明,所提方法对各类困难场景下的车牌识别都非常有效。【关键词】车牌识别 ; 图像嵌入向量 ;
我不得不解析科学记数法,这是对我的图表实现对数刻度的结果,但它打印出了图表中每一行的每个值。似乎没有任何步骤方法有效。RESULTINGCHARTIMGvarpacketsElement=$("#packetsGraph");pckBarChart=newChart(packetsElement,{type:'bar',data:{labels:["Received","Errors","Lost"],datasets:[{label:'#ofPackets',data:packetsArr,backgroundColor:['rgba(55,102,245,0.3)','rgba(5
如何使用FPGA加速机器学习算法如何使用FPGA加速机器学习算法 当前,AI因为其CNN(卷积神经网络)算法出色的表现在图像识别领域占有举足轻重的地位。基本的CNN算法需要大量的计算和数据重用,非常适合使用FPGA来实现。上个月,RalphWittig(XilinxCTOOffice的卓越工程师)在2016年OpenPower峰会上发表了约20分钟时长的演讲并讨论了包括清华大学在内的中国各大学研究CNN的一些成果。在这项研究中出现了一些和CNN算法实现能耗相关的几个有趣的结论:①限定使用片上Memory;②使用更小的乘法器;③进行定点匹配:相对于32位定点或浮点计算,将定点计算结果精度降为16
GPU池化和虚拟化属于计算机体系结构的技术领域,它的本质是进行异构算力的解耦和共享。痛点分析:1.之前的做法,如果有一张卡,哪怕只用了1%的计算能力,剩下的99%也无法被利用了,所以算力有耦合不可分。2.虽然任何一张独立的卡无法满足需求,但是多张卡的算例总和是可以达到算力要求的。随着人工智能的发展,其对算例的需求呈现指数级增长,自从2012年以来,全球算力需求增长超过30万倍,以GPU为代表的人工智能芯片是支撑算力的核心部件。GPU服务器占据了50%以上的AI算力市场份额,且GPU芯片的价格占到整台服务器成本的80%以上,然而,大部分用户的GPU利用率都比较低,只有10%~30%.其核心原因在
理解3d卷积我的个人理解我的个人理解作分类时,对于不同类别的数据,无论是使用什么方法和分类器(仅限于线性回归和深度学习)去拟合数据,都首先要构建适合数据的多种特征(比如根据性别、年龄、身高来区分一个人是否喜欢打篮球).之后的处理过程是,权重参数都要和不同的特征分别相乘,然后再将不同的乘积加起来求和,处理过程就是不同特征和对应的权重相乘再相加,而不会是将不同的特征相乘.对于图像数据,不同的通道表示不同种类的特征,比如RGB通道分别表示红、绿、蓝光谱特征.而卷积就是分别对不同通道操作,再将这些不同通道的卷积结果相加,而不会将不同通道之间相互卷积.通道始终是独立的,每一个卷积核中的滤波器个数由输入图
我想在图像上执行卷积乘积。原图为:所以我用gimp测试卷积。使用此矩阵:111111111和分隔线9我得到当我执行我的算法时,我得到:我的算法是:funcConvolution(img*image.Image,matrice[][]int)*image.NRGBA{imageRGBA:=image.NewNRGBA((*img).Bounds())w:=(*img).Bounds().Dx()h:=(*img).Bounds().Dy()sumR:=0sumB:=0sumG:=0varruint32varguint32varbuint32fory:=0;y错误在哪里?谢谢您的帮助。