写在前面:笔者发现目前关于Skywalking的内容很是零散,没有成型的内容,笔者在项目中使用到Skywalking进行埋点分析,下面分三篇来介绍下Skywalking,分别是Skywalking基本知识,Skywalking基于docke安装,SpringBoot工程集成Skywalking
服务监控需要满足的三要素分别如下:
服务监控只要能满足这三个要素,基本就能实现我们想要的监控效果,我们来看看为什么服务监控需要满足这三要素。
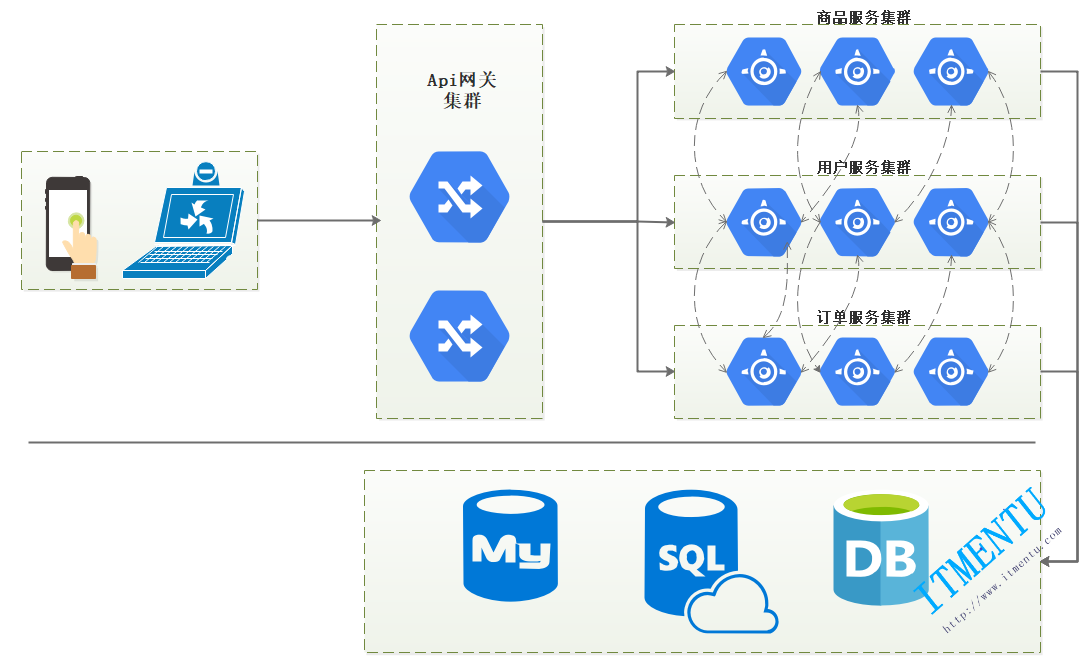
我们在学习Skywalking之前,先来分析一个电商项目中的案例,如上图:
1:用户请求调用微服务网关,请求到达后端服务。
2:此时用户有可能调用订单服务,订单服务有可能调用用户服务,用户服务有可能调用商品服务,商品服务有可能调用用户服务,用户服务有可能调用订单服务等。
3:在调用过程中存在很多请求跟踪问题,例如如果报错了,哪个环节出错了?这个问题如果不解决,很难快速定位bug。
通过我们刚才分析,在微服务场景下,服务之间调用如果不解决调用跟踪问题,就很难排查错误,很难分析服务健康状态。
如果我们要解决调用跟踪、了解服务健康状态,又该如何实现?
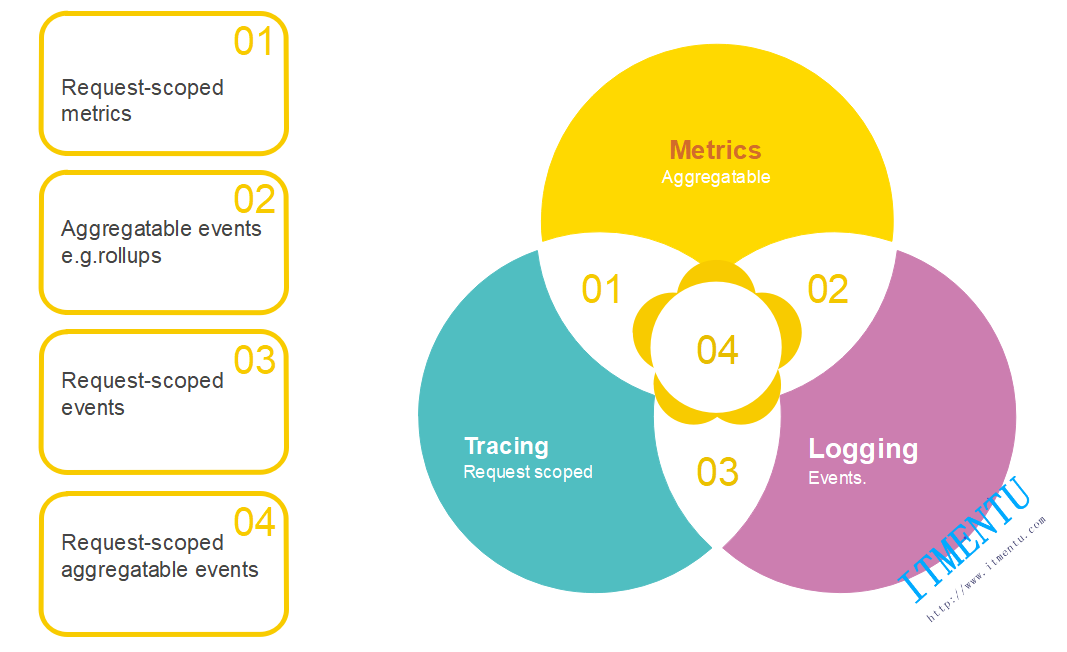
我们可以通过日志(Logging)记录调用链路信息,通过日志统计时间窗口下的指标数据(Metrics),如果服务之间的调用可以通过日志分析出来,那也就解决了调用流程跟踪,也就是链路追踪(Tracing)了。
我们分别来看看Logging、Metrics、Tracing概念:
ElasticSearch 或是其他存储中,然后通过 Kibana 或是其他工具来分析这些日志了解服务的行为和状态。大多数情况下,日志记录的数据很分散,并且相互独立,比如错误日志、请求处理过程中关键步骤的日志等等。Promethus、Open-Falcon 等,这些监控系统最终给运维人员展示的是一张张二维的折线图。Metrics 是可以聚合的,例如,为电商系统中每个 HTTP 接口添加一个计数器,计算每个接口的 QPS,之后我们就可以通过简单的加和计算得到系统的总负载情况。
谷歌在 2010 年 4 月发表了一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》介绍了分布式追踪的概念,之后很多互联网公司都开始根据这篇论文打造自己的分布式链路追踪系统。前面提到的 APM 系统的核心技术就是分布式链路追踪。
OpenTracing提供了一个标准的、与供应商无关的框架,这意味着如果开发者想要尝试一种不同的分布式追踪系统,开发者只需要简单地修改Tracer配置即可,而不需要替换整个分布式追踪系统。
OpenTracing API目前支持的语言众多:
下面通过官方的一个示例简单介绍说明什么是 Tracing,把Tracing学完后,更有助于大家运用Skywalking UI进行数据分析。
在一个分布式系统中,追踪一个事务或者调用流程,可以用下图方式描绘出来。这类流程图可以看清各组件的组合关系,但它并不能看出一次调用触发了哪个组件调用、什么时间调用、是串行调用还是并行调用。
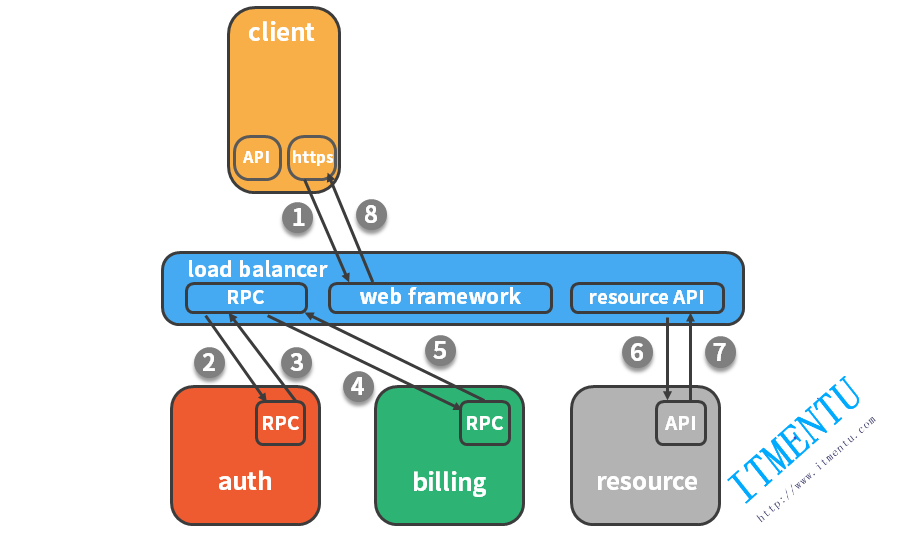
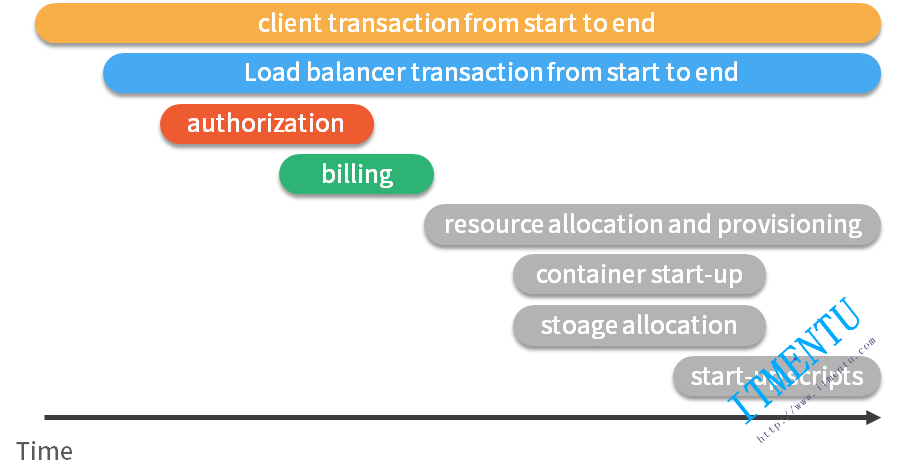
一种更有效的展现方式就是下图这样,这是一个典型的 trace 视图,这种展现方式增加显示了执行时间的上下文,相关服务间的层次关系,进程或者任务的串行或并行调用关系。这样的视图有助于发现系统调用的关键路径。通过关注关键路径的执行过程,开发团队就可以专注于优化路径中的关键服务,最大幅度的提升系统性能。例如下图中,我们可以看到请求串行的调用了授权服务、订单服务以及资源服务,在资源服务中又并行的执行了三个子任务。我们还可以看到,在这整个请求的生命周期中,资源服务耗时是最长的。
学好OpenTracing,更有助于我们运用Skywalking UI进行数据分析。
Trace
一个 Trace 代表一个事务、请求或是流程在分布式系统中的执行过程。OpenTracing 中的一条 Trace 被认为是一个由多个 Span 组成的有向无环图( DAG 图),一个 Span 代表系统中具有开始时间和执行时长的逻辑单元,Span 一般会有一个名称,一条 Trace 中 Span 是首尾连接的。
Span
Span 代表系统中具有开始时间和执行时长的逻辑单元,Span 之间通过嵌套或者顺序排列建立逻辑因果关系。
每个 Span 中可以包含以下的信息:
2021-1-25 22:00:002021-1-30 22:00:00在一个 Trace 中,一个 Span 可以和一个或者多个 Span 间存在因果关系。目前,OpenTracing 定义了 ChildOf 和 FollowsFrom 两种 Span 之间的引用关系。这两种引用类型代表了子节点和父节点间的直接因果关系。
ChildOf 关系:一个 Span 可能是一个父级 Span 的孩子,即为 ChildOf 关系。下面这些情况会构成 ChildOf 关系:
很明显,上述 ChildOf 关系中的父级 Span 都要等待子 Span 的返回,子 Span 的执行时间影响了其所在父级 Span 的执行时间,父级 Span 依赖子 Span 的执行结果。除了串行的任务之外,我们的逻辑中还有很多并行的任务,它们对应的 Span 也是并行的,这种情况下一个父级 Span 可以合并所有子 Span 的执行结果并等待所有并行子 Span 结束。
FollowsFrom 关系:在分布式系统中,一些上游系统(父节点)不以任何方式依赖下游系统(子节点)的执行结果,例如,上游系统通过消息队列向下游系统发送消息。这种情况下,下游系统对应的子 Span 和上游系统对应的父级 Span 之间是 FollowsFrom 关系。
Logs
每个 Span 可以进行多次 Logs 操作,每一次 Logs 操作,都需要带一个时间戳,以及一个可选的附加信息。
Tags
每个 Span 可以有多个键值对形式的 Tags,Tags 是没有时间戳的,只是为 Span 添加一些简单解释和补充信息。
SpanContext 和 Baggage
SpanContext 表示进程边界,在跨进调用时需要将一些全局信息,例如,TraceId、当前 SpanId 等信息封装到 Baggage 中传递到另一个进程(下游系统)中。
Baggage 是存储在 SpanContext 中的一个键值对集合。它会在一条 Trace 中全局传输,该 Trace 中的所有 Span 都可以获取到其中的信息。
需要注意的是,由于 Baggage 需要跨进程全局传输,就会涉及相关数据的序列化和反序列化操作,如果在 Baggage 中存放过多的数据,就会导致序列化和反序列化操作耗时变长,使整个系统的 RPC 的延迟增加、吞吐量下降。
虽然 Baggage 与 Span Tags 一样,都是键值对集合,但两者最大区别在于 Span Tags 中的信息不会跨进程传输,而 Baggage 需要全局传输。因此,OpenTracing 要求实现提供 Inject 和 Extract 两种操作,SpanContext 可以通过 Inject 操作向 Baggage 中添加键值对数据,通过 Extract 从 Baggage 中获取键值对数据。
核心接口语义
OpenTracing 希望各个实现平台能够根据上述的核心概念来建模实现,不仅如此,OpenTracing 还提供了核心接口的描述,帮助开发人员更好的实现 OpenTracing 规范。
Span接口必须实现以下的功能:
SpanContext 接口
SpanContext 接口必须实现以下功能,用户可以通过 Span 实例或者 Tracer 的 Extract 能力获取 SpanContext 接口实例。
Tracer 接口
Tracer 接口必须实现以下功能:
**创建 Span:**创建新的 Span。
注入 SpanContext:主要是将跨进程调用携带的 Baggage 数据记录到当前 SpanContext 中。
提取 SpanContext ,主要是将当前 SpanContext 中的全局信息提取出来,封装成 Baggage 用于后续的跨进程调用。
当前主流的分布式链路追踪系统也并非只有Skywalking,还有很多开源的分布式链路追踪系统,但维度Skywalking异常火爆。
我们前面提到了APM系统,APM 系统(Application Performance Management,即应用性能管理)是对企业的应用系统进行实时监控,实现对应用性能管理和故障定位的系统化解决方案,在运维中常用。
我们将学习Skywalking,Skywalking有很多优秀特性。SkyWalking 对业务代码无侵入,性能表现优秀,SkyWalking 增长势头强劲,社区活跃,中文文档齐全,支持多语言探针, SkyWalking 支持Dubbo、gRPC、SOFARPC 等很多框架。

Skywalking是一个可观测性分析平台和应用性能管理系统,它也是基于OpenTracing规范、开源的AMP系统。Skywalking提供分布式跟踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。支持Java, .Net Core, PHP, NodeJS, Golang, LUA, c++代理。支持Istio +特使服务网格
我们在学习Skywalking之前,可以先访问官方提供的控制台演示
演示地址:http://demo.skywalking.apache.org/ 账号:skywalking 密码:skywalking
SkyWalking 核心功能:
SkyWalking 特点:
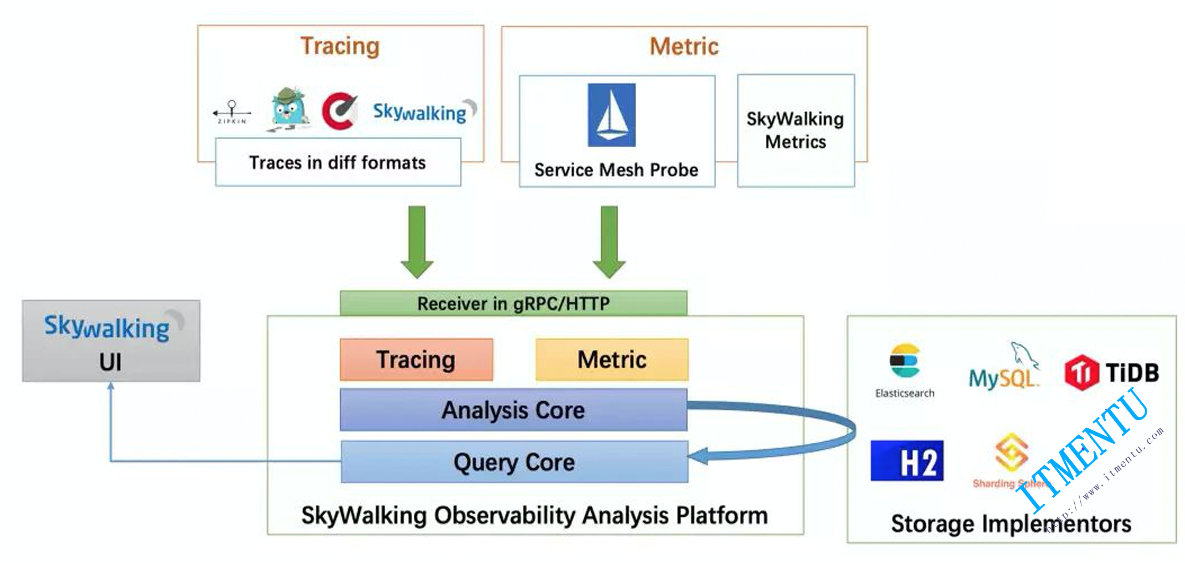
SkyWalking 分为三个核心部分:
Agent(探针):Agent 运行在各个服务实例中,负责采集服务实例的 Trace 、Metrics 等数据,然后通过 gRPC 方式上报给 SkyWalking 后端。
OAP:SkyWalking 的后端服务,其主要责任有两个。
Agent 上报上来的 Trace、Metrics 等数据,交给 Analysis Core (涉及 SkyWalking OAP 中的多个模块)进行流式分析,最终将分析得到的结果写入持久化存储中。SkyWalking 可以使用 ElasticSearch、H2、MySQL 等作为其持久化存储,一般线上使用 ElasticSearch 集群作为其后端存储。UI 界面:SkyWalking 前后端进行分离,该 UI 界面负责将用户的查询操作封装为 GraphQL 请求提交给 OAP 后端触发后续的查询操作,待拿到查询结果之后会在前端负责展示。
一、相关网址1、官网(可以下载,查看文章)https://skywalking.apache.org/downloads/2、github地址:(可提问题寻求帮助)https://github.com/apache/skywalking二、 实验环境操作系统 centos7.9先安装好 elasticsearch7.16.2操作系统安装好jdk8-17,实验机器jdk11java下载地址:https://www.oracle.com/java/technologies/downloads/#java8IP地址为192.168.24.160三、安装skywalking 1、下载skywalkin
我是Rails的新手。当我启动我的应用程序时,我不断看到这些弃用警告:DEPRECATIONWARNING:refisdeprecatedandwillberemovedfromRails3.2.(calledfromatD:/dev/AquaticKodiak/config/application.rb:12)DEPRECATIONWARNING:newisdeprecatedandwillberemovedfromRails3.2.(calledfromatD:/dev/AquaticKodiak/config/application.rb:12)好的,第12行是什么?这个:Bun
文/高扬(微信公众号:量子论)据上次3月18号发布的V1.8版,已经过去十天,这期间AI领域发生了很多重大变化。因此,我们对《ChatGPT实用指南》进行了重大改版,增加了大量实用的操作和详细的讲解,保证小白可以轻松上手,快速驾驭ChatGPT。V2.0版本亮点:1、结构更合理。分为基础篇、进阶篇、高级篇,从易到难,由浅入深,符合学习规律。2、内容更充实。扩充了27页的内容,尽量看图说话,将操作步骤一步步地展示出来。3、排版更美观。按图书出版的规范制作,便于知识点查阅。后记:2022年11月底,我们在HackerNews上看到了关于ChatGPT的新闻报道后,开始意识到,人工智能的春天来了,这
我有一个在Heroku上运行的RubyonRails应用程序。我不断在日志中收到这些消息:2015-05-05T16:11:14Zapp[postgres.27102]:[AQUA]connectionreceived:host=xx.xxx.xx.26port=602782015-05-05T16:11:14Zapp[postgres.27102]:[AQUA]connectionauthorized:user=postgresdatabase=somedb2015-05-05T16:11:14Zapp[postgres.27103]:[AQUA]connectionreceived
目录简介ROS诞生背景ROS的设计目标ROS与ROS2安装ROS1.配置ubuntu的软件和更新2.设置安装源3.设置key4.安装5.配置环境变量安装可能出现的问题安装构建依赖卸载ROS架构1.设计者2.维护者3.立足系统架构:ROS可以划分为三层ROS通信机制话题通信理论模型流程通信样例自定义消息的通信服务通信理论模型服务通信自定义srv参数服务器理论模型参数操作常用命令简介rosnoderostopicrosmsgrosservicerossrvrosparam常用API初始化话题与服务相关对象C++回旋函数C++对比时间1.时刻2.持续时间3.持续时间与时刻运算4.设置运行频率(非常常
Error:[$sanitize:badparse]Thesanitizerwasunabletoparsethefollowingblockofhtml::778:50)atScope.$digest(http://localhost:3000/assets/angular.js?body=1:12396:29)atScope.$delegate.__proto__.$digest(:844:31)atScope.$apply(http://localhost:3000/assets/angular.js?body=1:12661:24)我知道这是因为以下问题:http://erro
///国家发改委:中国是全球能耗强度降低最快的国家之一2012年以来,我国以年均3%的能源消费增速支撑了年均6.6%的经济增长,单位GDP能耗下降26.4%,是全球能耗强度降低最快的国家之一///苹果自研5G芯片或将推迟至2025年后苹果原计划在2023年推出自研芯片,但因为功耗及效能表现不如预期,推出时间将延后到2025年之后,制程将推进采用台积电4nm,届时将搭载于iPhone17系列///飞常准:时隔近3年,国际单日客运航班量首次恢复至300班次以上时隔2年半多,国际及地区航线单日客运航班量首次恢复至300班次以上///国家发改委:我国风电、光伏发电装机均处于世界第一落实可再生能源发电全
paddleocr最后几个库一个比一个难装,特别是lanms库,巨难装,拒绝任何花里胡哨,十分钟,三步内解决问题。pip下载报错Keyringisskippedduetoanexception:'keyring.backends'CollectinglanmsUsingcachedlanms-1.0.2.tar.gz(973kB)ERROR:Commanderroredoutwithexitstatus1:command:'C:\Users\TensorFlow\anaconda3\python.exe'-c'importsys,setuptools,tokenize;sys.argv[0]=
文章目录前言一元线性回归多元线性回归局部加权线性回归多项式回归Lasso回归&Ridge回归Lasso回归Ridge回归岭回归和lasso回归的区别L1正则&L2正则弹性网络回归贝叶斯岭回归Huber回归KNNSVMSVM最大间隔支持向量&支持向量平面寻找最大间隔SVRCART树随机森林GBDTboosting思想AdaBoost思想提升树&梯度提升GBDT面试题整理XGBOOST面试题整理LightGBMXGBoost的缺点LightGBM的优化基于Histogram的决策树算法带深度限制的Leaf-wise算法单边梯度采样算法互斥特征捆绑算法直接支持类别特征支持高效并行Cache命中率优化
Nginx实现10万+并发在优化内核时,可以做的事情很多,不过,我们通常会根据业务特点来进行调整,当Nginx作为静态web内容服务器、反向代理或者提供压缩服务器的服务器时,期内核参数的调整都是不同的,概述:由于默认的linux内核参数考虑的是最通用场景,这明显不符合用于支持高并发访问的Web服务器的定义,所以需要修改Linux内核参数,让Nginx可以拥有更高的性能;注:本文以PDF持续更新,最新尼恩架构笔记、面试题的PDF文件,请从下面的链接获取:码云参考关键的Linux内核优化参数/etc/sysctl.conf修改/etc/sysctl.conf来更改内核参数修改好配置文件,执行sys