目录
http://t.csdn.cn/mz8dg
http://t.csdn.cn/mz8dghttp://t.csdn.cn/1TqDp
- 😄关于快排的基本思想和实现及其优化
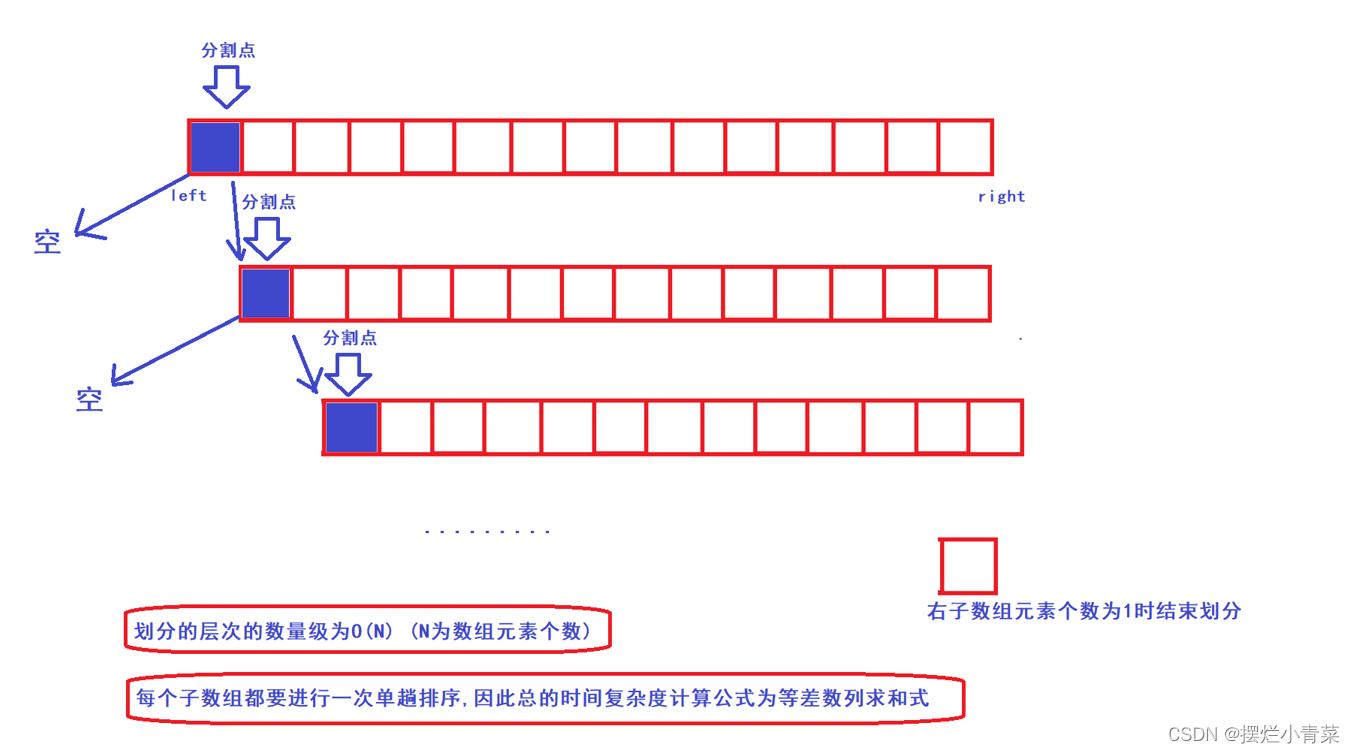
- 😄利用双指针单趟排序实现的快速排序有一个无法避免的缺陷:当待排序序列中有大量(或全部)元素相同时,快排的时间复杂度会升阶为O(N^2),此时快排的递归树呈线型结构,递归的深度为O(N),时间消耗和空间消耗都非常巨大:
- 😄为了避免这种情况出现,就需要重新设计一下快排的单趟排序,目的在于:当待排序序列中存在大量相同元素时,减小快排递归树的深度
😍算法思想:
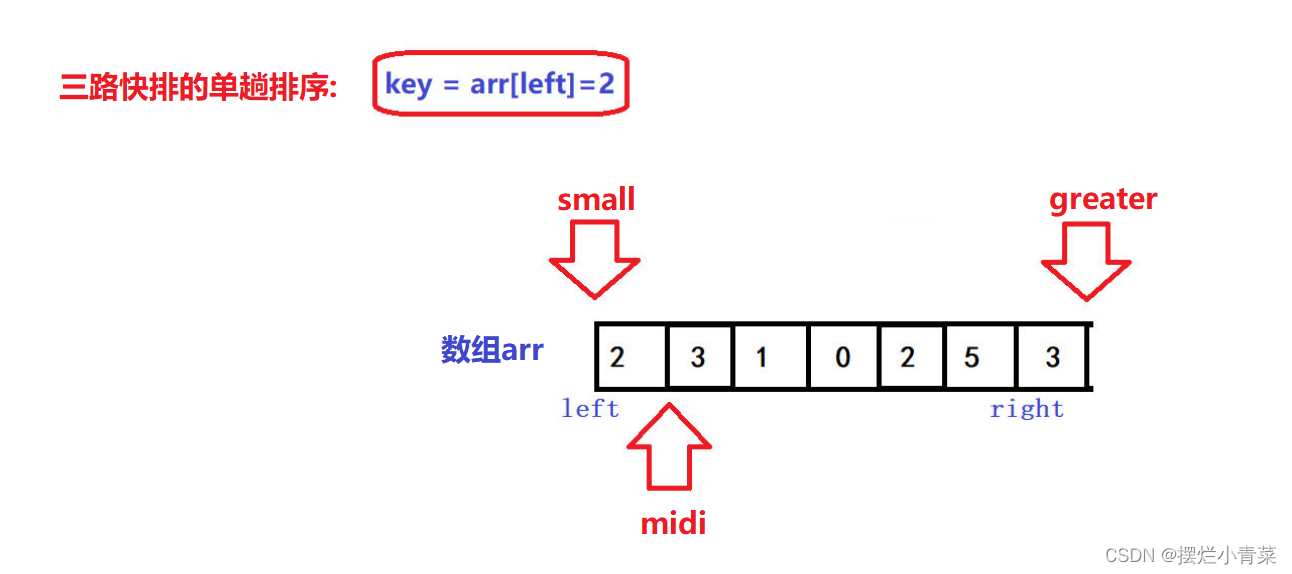
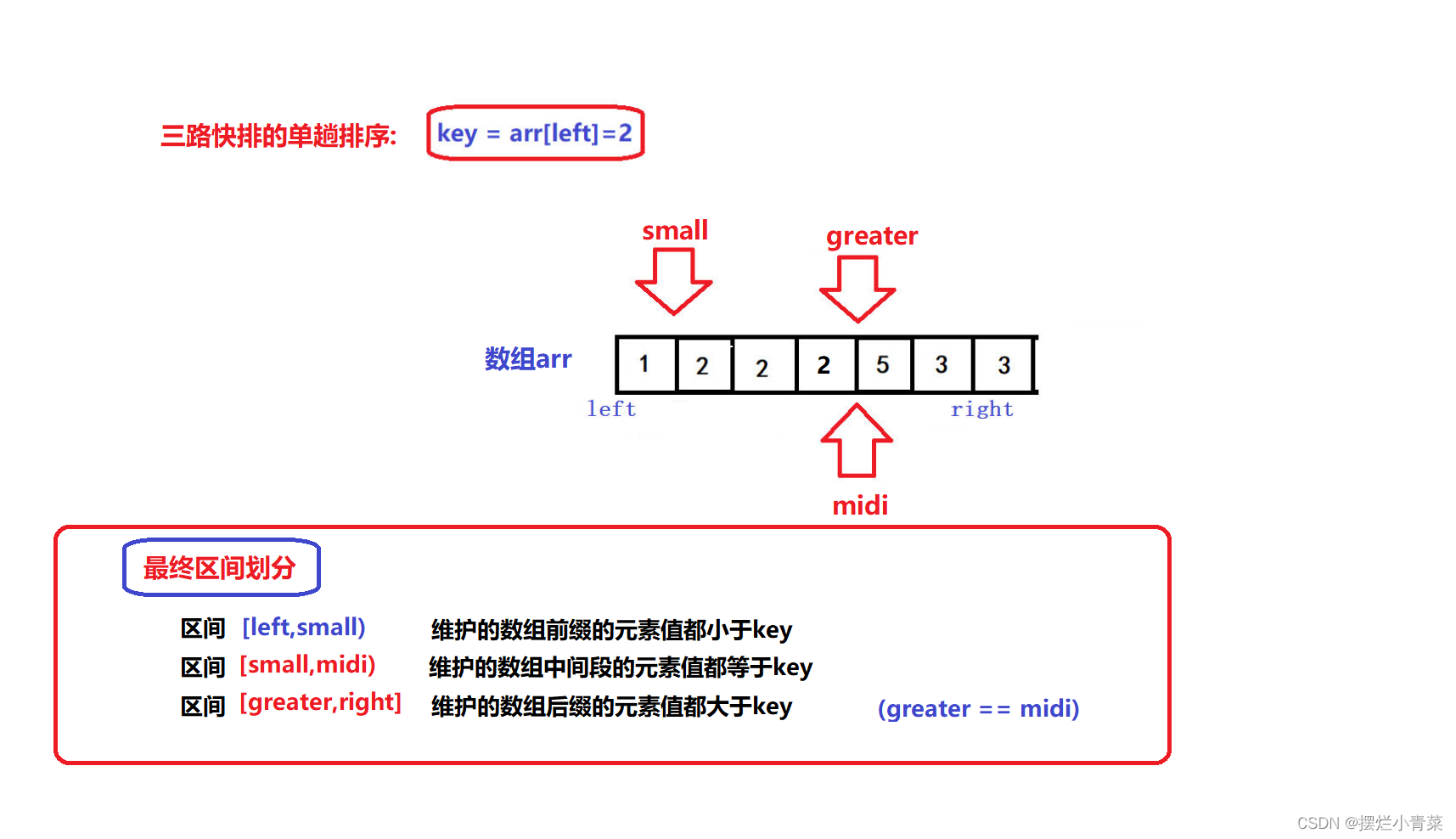
- 🤪三路快排的单趟排序是利用三指针算法来实现的
- 🤪其基本思想是利用三个指针将数组从左到右划分为三个部分,第一部分中所有元素都比key小,第二部分中所有元素都等于key,第三部分中所有元素都大于key
- 🤪后续就可以对数组第一部分和第三部分进行分治,数组的第二部分所有元素已经处于它们在有序序列中的最终位置,无须再进行处理
- 🤪三路快排的边界条件有点折磨人
😍算法实现步骤:
- 🤪三个指针的初始位置如图所示
- 🤪left是待排序区间的左边界,right是待排序区间的右边界,待排序区间为闭区间
- 🤪算法实现思路:
- 🤪利用midi指针来遍历待排序序列,遍历限制条件为:midi<greater.
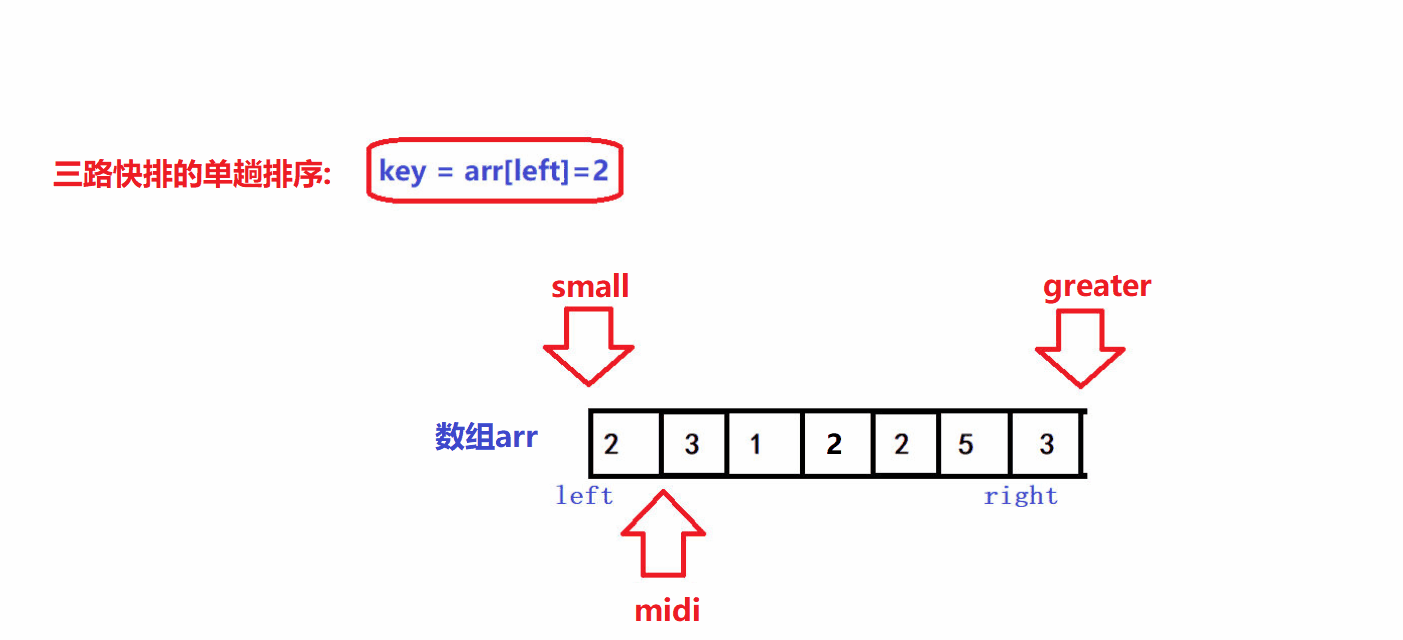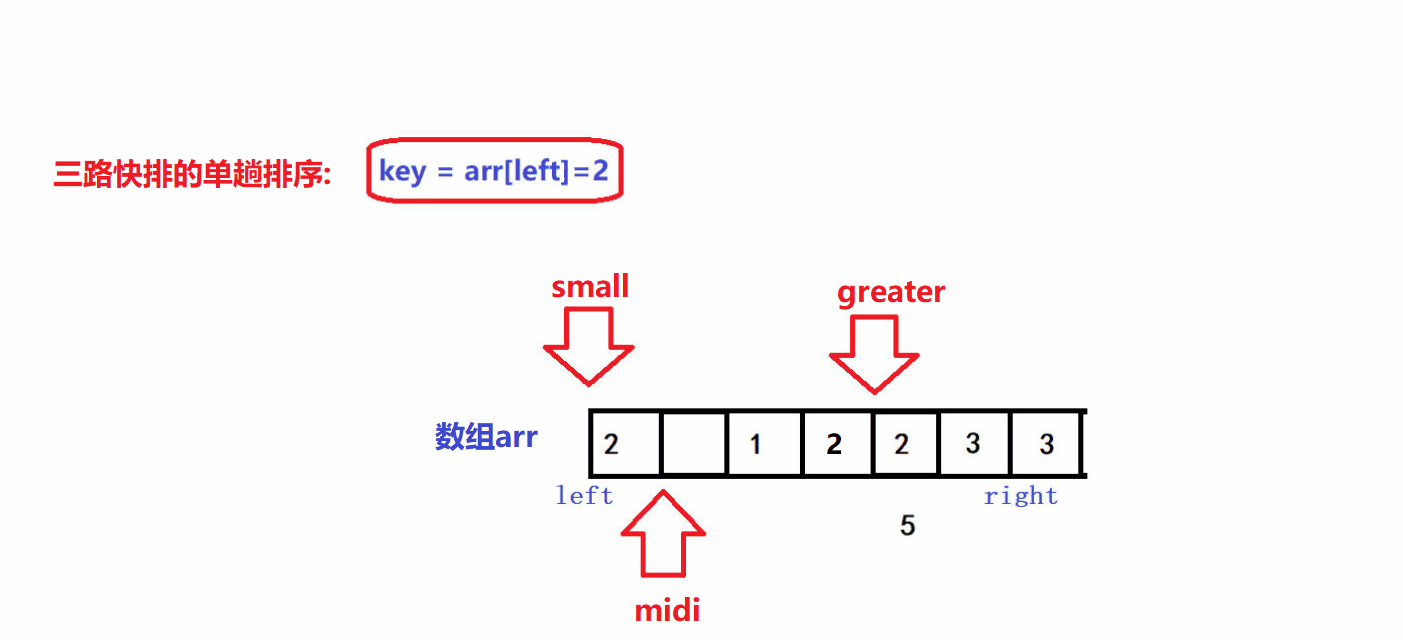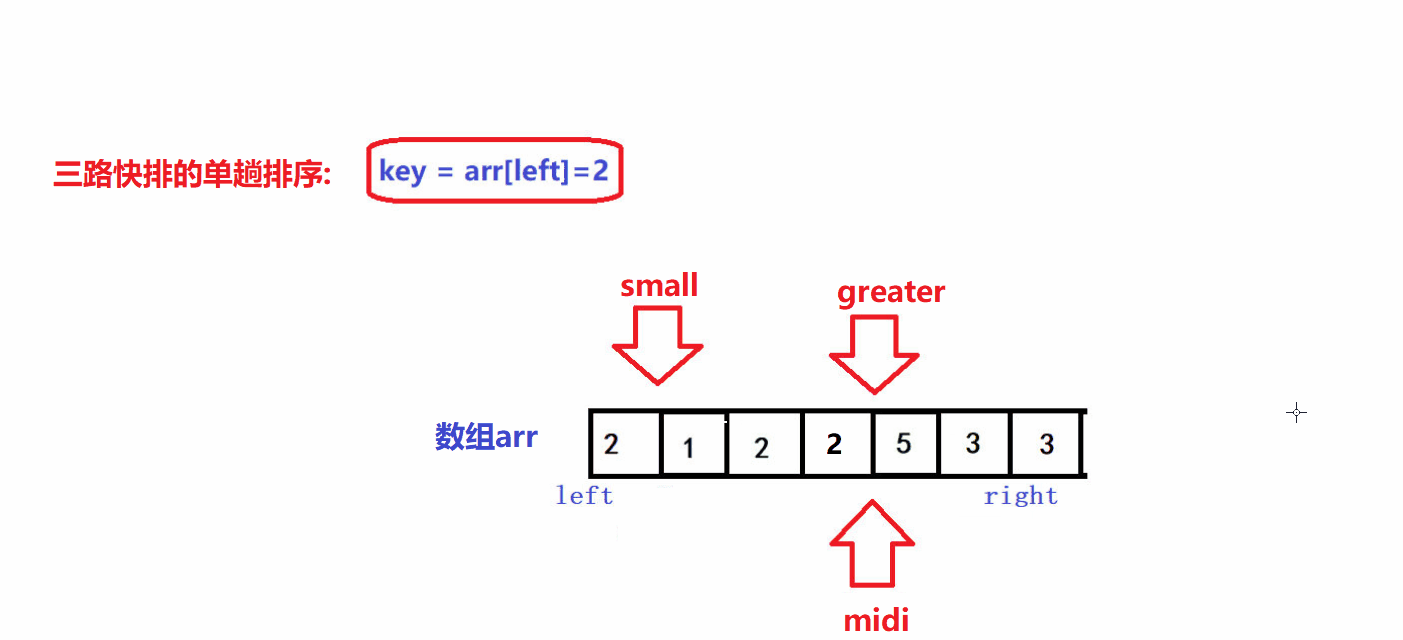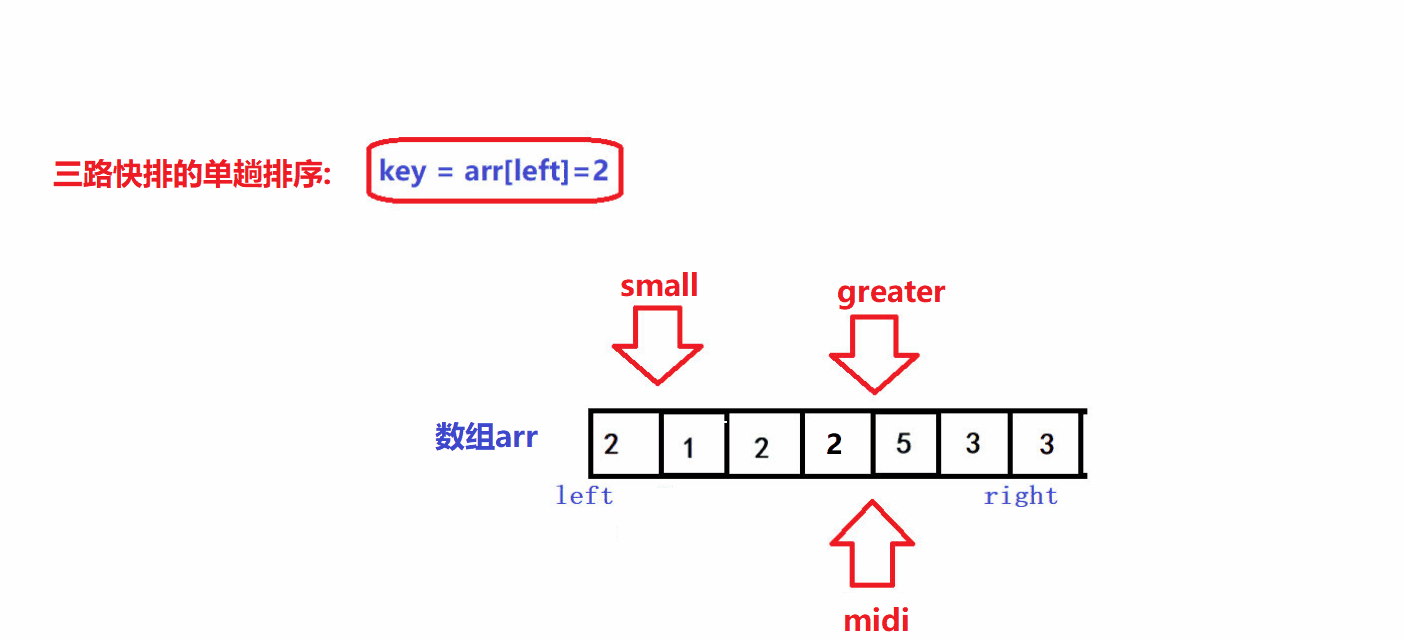
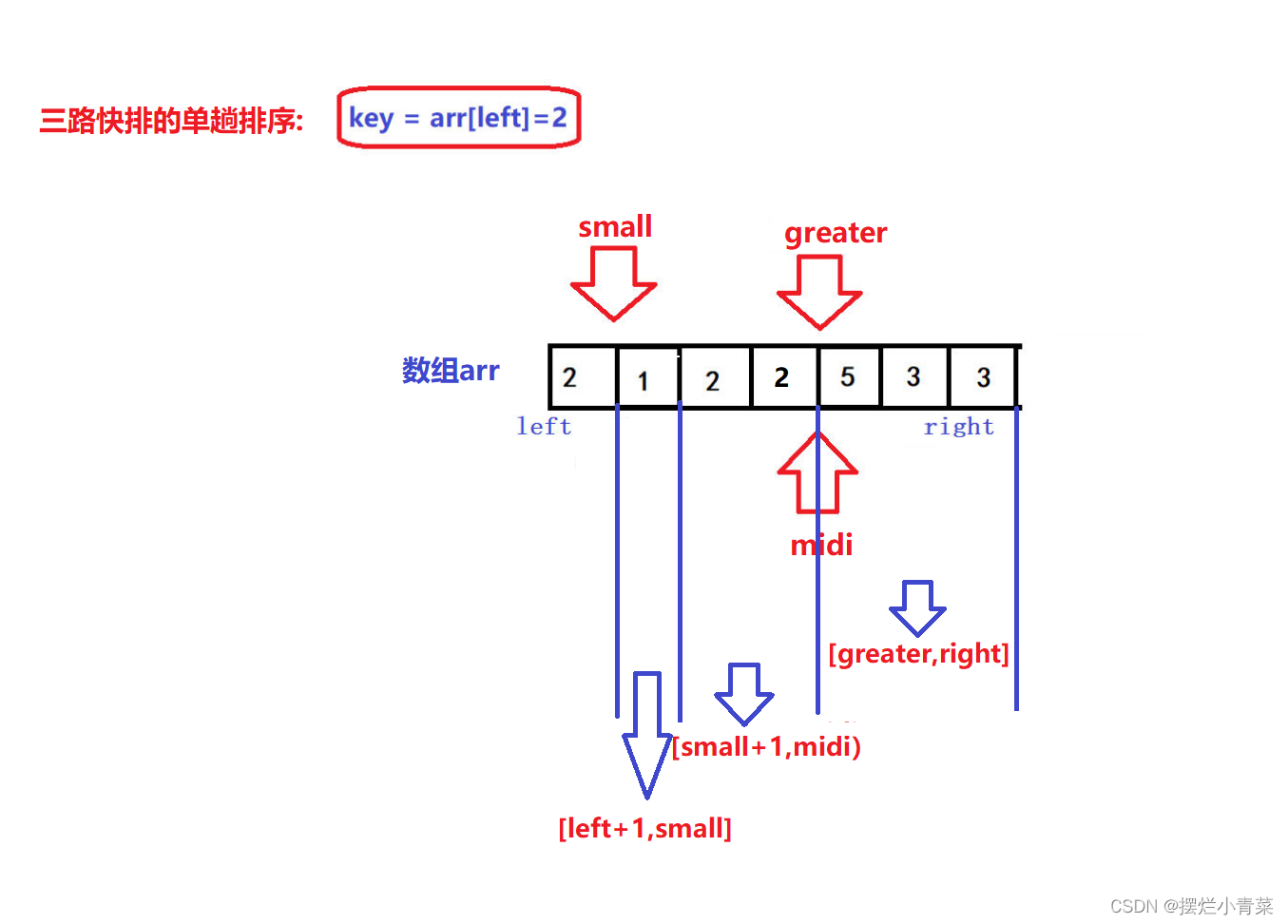
- 😝若arr[midi]比key大,令grater指针减一,并将arr[midi]交换到[greater,right]区间中,midi指针不动
- 😝若arr[midi]比key小,令small指针加一, 并将arr[midi]交换到[left+1,small]区间中,midi指针向前走一步
- 😝若arr[midi]与key相同,midi指针向前走一步,其余指针不动,目的是将等于key元素的arr[midi]"括入"[small+1,midi)区间中
- 😝重复上述过程直到midi指针和geater指针相遇,算法gif:
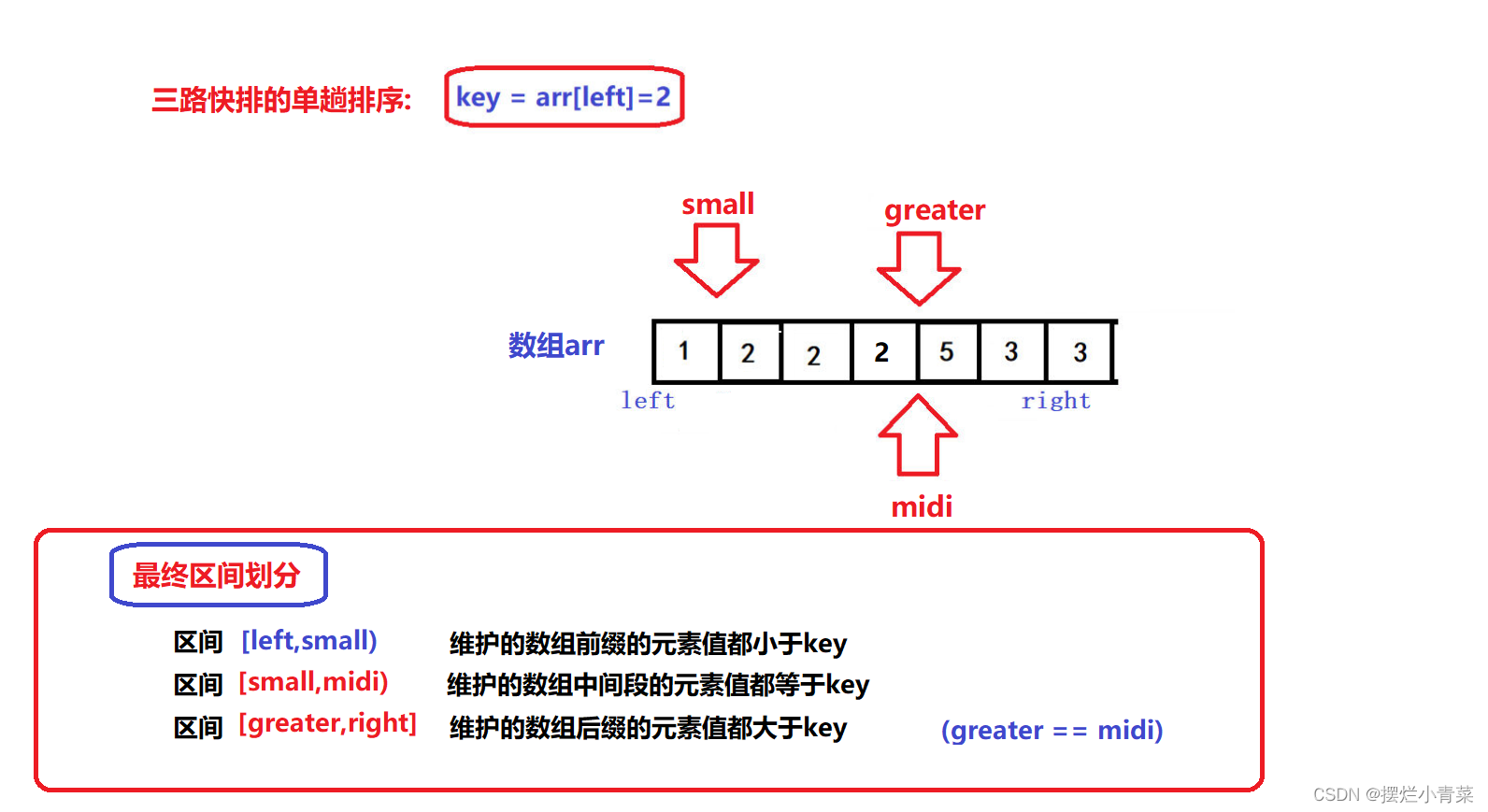
- 😝经过上述过程,最终[left+1,small]区间中的所有元素一定比key小,[greater,right]区间中的所有元素一定比key大,[small+1,midi)区间中的所有元素一定等于key:
- 😝同时注意,迭代过程结束后,small最终指向的元素一定小于key,所以最后一步就是将arr[small]和arr[left]进行交换,于是数组就被划分成了三个部分:
- 😝接下来就可以对区间[left,small-1]和区间[greater,right]进行分治并形成递归完成快速排序
😍三指针单趟排序的实现:
void QuickSort(int* arr, int left, int right) { assert(arr); int key = left; int midi = left + 1; int small = left; int greater = right + 1; while (midi < greater) { if (arr[midi] < arr[key]) //将arr[midi]交换到[left + 1, small]区间中,同时注意small位置的元素一定比key元素小 { ++small; if (small != midi) { swap(&arr[small], &arr[midi]); } ++midi; } else if (arr[midi] > arr[key]) //将arr[midi]交换到[greater,right]区间 { --greater; swap(&arr[midi], &arr[greater]); } else { ++midi; //将等于key元素的arr[midi]"括入"[small+1,midi)区间中 } } swap(&arr[small], &arr[key]); //small最终指向的元素一定小于key }接下来再进行分治递归并给出递归出口完成快速排序:
😍非递归快排完全体:
- 😝同时辅以三数取中优化
void swap(int* e1, int* e2) { assert(e1 && e2); int tem = *e1; *e1 = *e2; *e2 = tem; } //三数取中优化 int GetMid(int* arr,int left,int right) { int mid = left + ((right - left) >> 2); //在arr[left],arr[mid],arr[right]三者中取中间值作为key,返回key的下标 if (arr[left] < arr[right]) { if (arr[left] < arr[mid] && arr[mid] < arr[right]) { return mid; } else if (arr[mid] > arr[right]) { return right; } else { return left; } } else { if (arr[left] > arr[mid] && arr[mid] > arr[right]) { return mid; } else if (arr[mid] > arr[left]) { return left; } else { return right; } } } void QuickSort(int* arr, int left, int right) { if (left >= right) //递归出口 { return; } assert(arr); int key = left; swap(&arr[left], &arr[GetMid(arr, left, right)]); int midi = left + 1; int small = left; int greater = right + 1; while (midi < greater) { if (arr[midi] < arr[key]) //将arr[midi]交换到[left + 1, small]区间中,同时注意small位置的元素一定比key元素小 { ++small; if (small != midi) { swap(&arr[small], &arr[midi]); } ++midi; } else if (arr[midi] > arr[key]) //将arr[midi]交换到[greater,right]区间 { --greater; swap(&arr[midi], &arr[greater]); } else { ++midi; //将等于key元素的arr[midi]"括入"[small+1,midi)区间中 } } //small指向的元素一定小于key swap(&arr[small], &arr[key]); //将key交换到其应该出现的最终位置 QuickSort(arr, left, small - 1); //分治左子数组 QuickSort(arr, midi,right); //分治右子数组 }🤔经过三数取中和三指针优化后的快排就可以对任意序列进行高效排序,不会再出现时间复杂度升阶为O(N^2)的情况
🤔力扣排序测试:(该测试非常针对未经优化和非三指针的快排)
912. 排序数组 - 力扣(Leetcode)
🤔与C标准库里的快排进行对比测试:
int main() { srand((unsigned int)time(0)); const int N = 10000000; int* arr1 = (int*)malloc(sizeof(int) * N); int* arr2 = (int*)malloc(sizeof(int) * N); int* arr3 = (int*)malloc(sizeof(int) * N); for (int i = 0; i < N; ++i) { arr1[i] = rand(); arr2[i] = arr1[i]; arr3[i] = arr1[i]; } int begin2 = clock(); qsort(arr2, N, sizeof(int), cmp); int end2 = clock(); printf("qsort:%d\n", end2 - begin2); int begin3 = clock(); QuickSort(arr3, 0,N-1); int end3 = clock(); printf("QuickSort:%d\n", end3 - begin3); free(arr1); free(arr2); free(arr3); }
- 🤔有点奇怪的是在我的机器环境中,我自己写的快排比标准库里的快排还要快一倍左右(可执行程序为release版本)
- 😍设N为待排序序列的元素个数
- 😍以下分析中的log都表示以2为底的对数
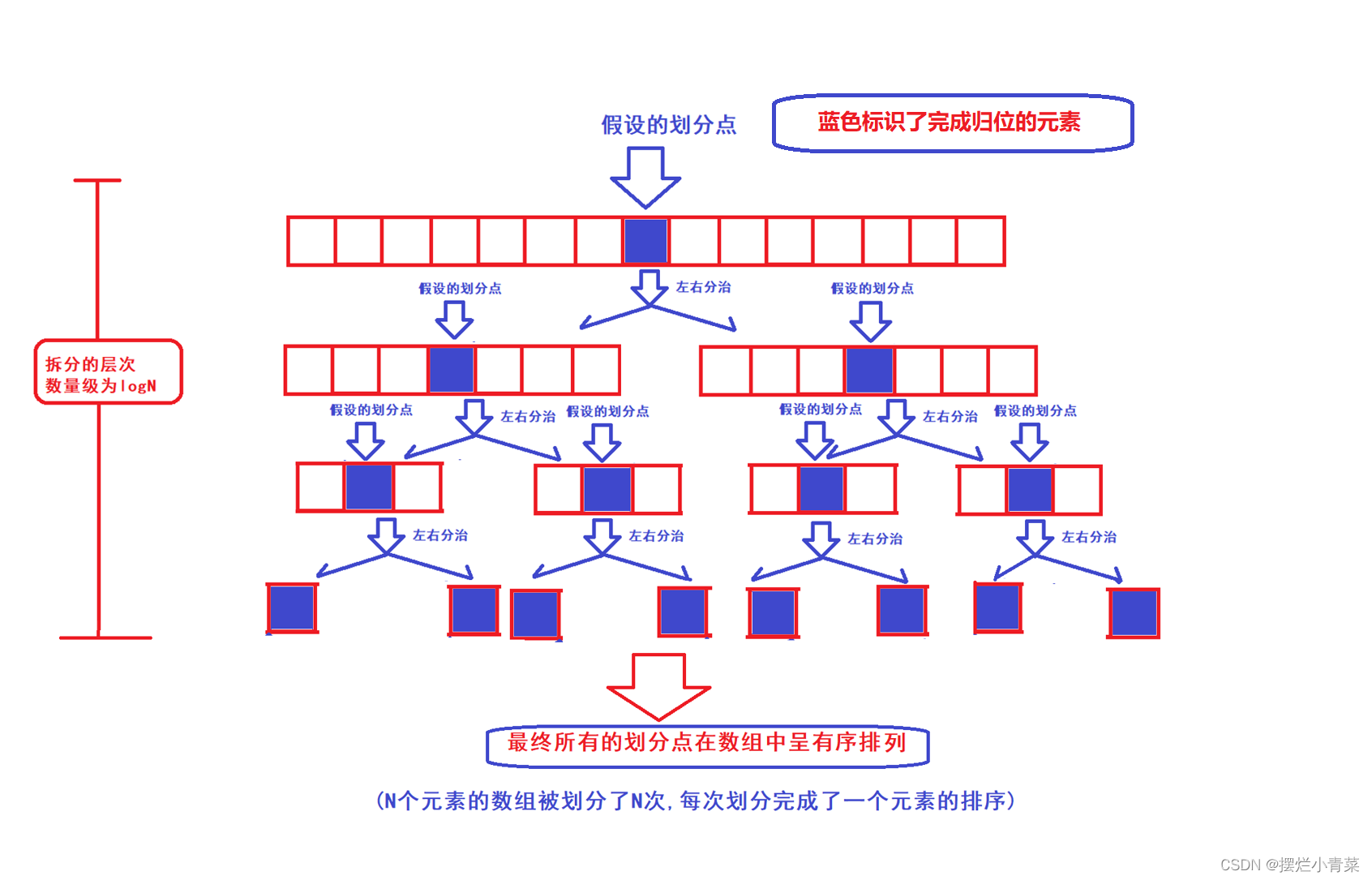
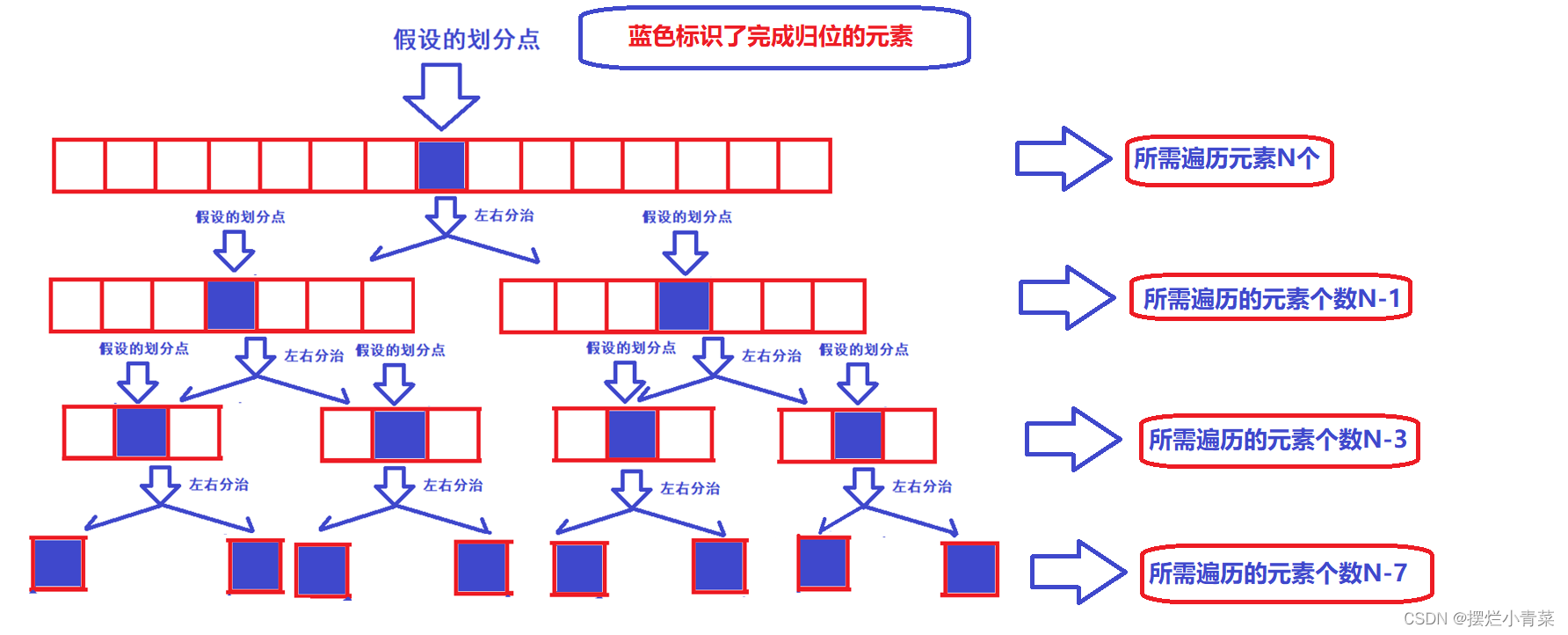
- 😍经过三数取中和三指针优化后的快排分治递归的递归树可以认为在处理任何序列时都接近一颗满二叉树:(注意数组的分割点不参与后续的单趟排序)
- 😍从递归树的第一层开始,递归树每一层中所有单趟排序所需遍历元素的总个数依次为:N+(N-1)+(N-3)+(N-7)......即快排的时间复杂度计算公式为:
- 😍将上述复杂度公式进行求和运算,取b = logN可得:
- 😍再化简可得:
- 😍可见快速排序的时间复杂度在O(NlogN)的基础上存在进一步的微收敛,这使得快速排序在四个时间复杂度数量级为O(NlogN)的排序算法中独占鳌头进而成为工业级排序中用的最多的排序算法。(四个时间复杂度为O(NlogN)数量级的排序算法分别为:希尔排序,堆排序,归并排序和快速排序)

导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我需要用任何语言编写一个算法,根据3个因素对数组进行排序。我以度假村为例(如Hipmunk)。假设我想去度假。我想要最便宜的地方、最好的评论和最多的景点。但是,显然我找不到在所有3个中都排名第一的方法。Example(assumingthereare20importantattractions):ResortA:$150/night...98/100infavorablereviews...18of20attractionsResortB:$99/night...85/100infavorablereviews...12of20attractionsResortC:$120/night
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
>>a=5=>5>>b=a=>5>>b=4=>4>>a=>5如何将“b”设置为实际的“a”,以便在示例中,变量a也将变为4。谢谢。 最佳答案 classRefdefinitializeval@val=valendattr_accessor:valdefto_s@val.to_sendenda=Ref.new(4)b=aputsa#=>4putsb#=>4a.val=5putsa#=>5putsb#=>5当您执行b=a时,b指向与a相同的对象(它们具有相同的object_id).当你执行a=some_other_thing时,a将指向
有没有办法快速将表格格式的ruby哈希打印到文件中?如:keyAkeyBkeyC...1232343451253474456...其中散列的值是不同大小的数组。还是使用双循环是唯一的方法?谢谢 最佳答案 试试我写的这个gem(在表中打印散列、ruby对象、ActiveRecord对象):http://github.com/arches/table_print 关于ruby-如何以表格格式快速打印Ruby哈希值?,我们在StackOverflow上找到一个类似的问题: