CSDN话题挑战赛第2期
参赛话题:学习笔记
为分清带结点与不带头结点的单链表操作,本文以图文和表格形式描述了两者之间的区别。考研中,数据结构的单链表操作是重要考点,其中,比较常考带头结点的链表操作。
所以,本文只描述了带头结点的插入、删除、查找、用前插法和后插法创建单链表等基本操作。
可结合以下链接一起学习:
【考研】数据结构考点——直接插入排序_住在阳光的心里的博客-CSDN博客
【考研】单链表相关算法(从基础到真题)_住在阳光的心里的博客-CSDN博客
// 单链表的存储结构
typedef struct LNode{
ElemType data; //结点的数据域
struct LNode *next; //结点的指针域
}LNode, *LinkList;
// LinkList 为指向结构体 LNode 的指针类型 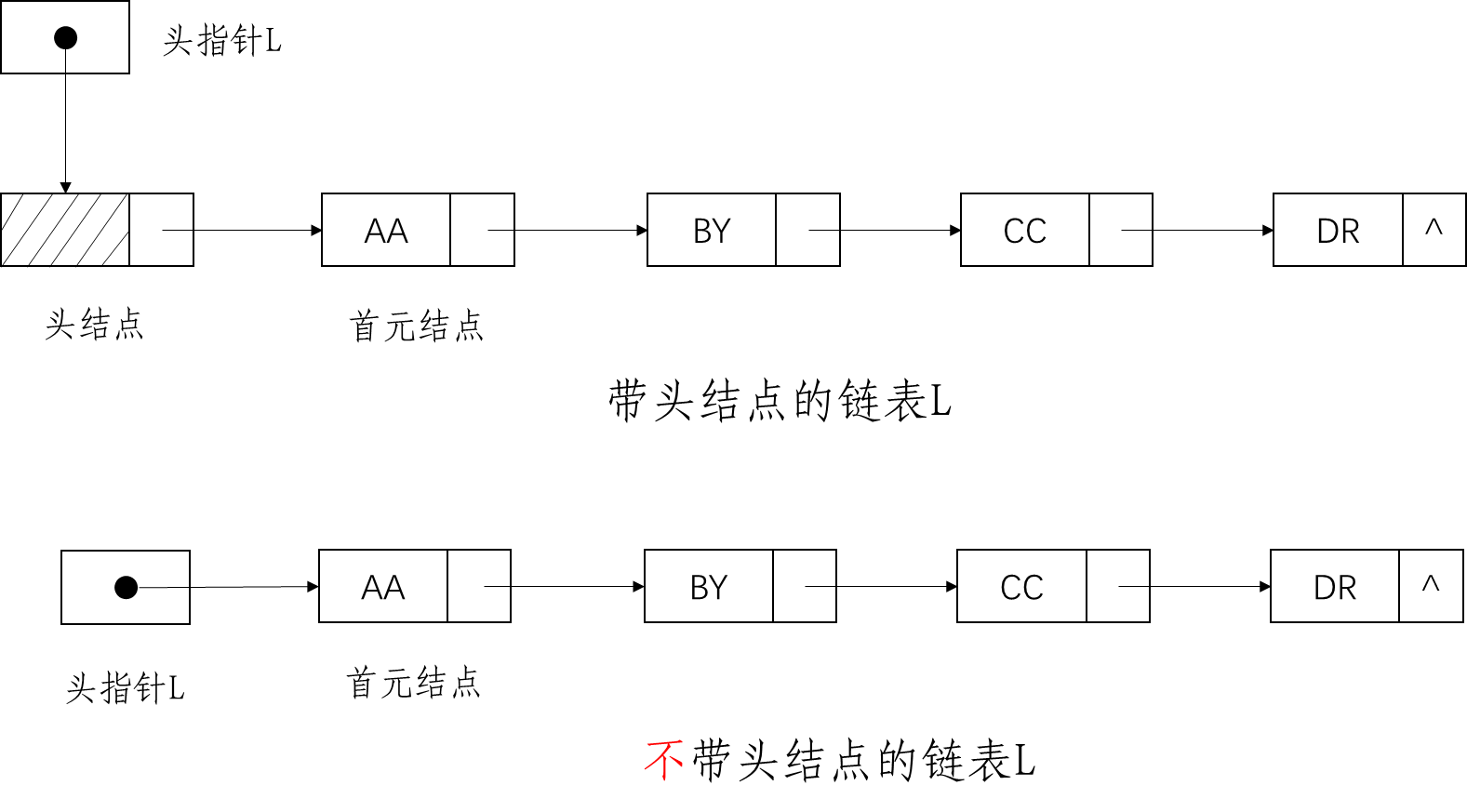
针对上图,在分清带头结点与不带头结点的单链表之前,需弄清头指针与首元结点。
LNode * 与 LinkList ,两者本质上是等价的。
通常习惯上用 LinkList 定义单链表,强调定义的是某个单链表的头指针;用 LNode * 定义指向单链表中任意结点的指针变量。例如:
(1)若定义 LinkList L,则 L 为单链表的头指针。(简称该链表为表L)
(2)若定义 LNode *p,则 p 为指向单链表中某个结点的指针,表示该结点的地址;用 *p 表示该结点。
LinkList p 的定义形式完全等价于 LNode *p。
所以,头指针是指向链表中第一个结点的指针。
(3)若链表设有头结点,则头指针所指结点为该线性表的头结点;
(4)若链表不带头结点,则头指针所指结点为该线性表的首元结点。
(1)一般,在单链表的第一个结点之前附设一个结点,称为头结点。而链表中存储第一个数据元素的结点,则称为首元结点。
(2)头结点与首元结点的关系:头结点的指针域指向首元结点。
可以不存储任何信息,也可存储与数据元素类型相同的其他附加信息,例如:当数据元素为整数型时,头结点的数据域可存放该线性表的长度。
增加了头结点后,首元结点的地址保存在头结点(即其 “ 前驱 ” 结点)的指针域中,则对链表的第一个数据元素的操作与其他数据元素相同,无需进行特殊处理。
当链表不设头结点时,假设 L 为单链表的头指针,它应该指向首元结点,则当单链表为长度 n 为 0的空表时,L 指针为空(判定空表的条件可记为: L == NULL)。
增加头结点后,无论链表是否为空,头指针都是指向头结点的非空指针。如图2.10(a) 所示的非空单链表,头指针指向头结点。若为空表,则头结点的指针域为空(判定空表的条件可记为:
L->next == NULL),如图2.10 (b)所示。
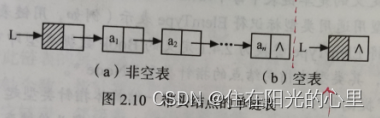
| 单链表 | 不带头结点 | 带头结点 |
| 判定空表的条件 | L == NULL | L->next == NULL |
| LinkList L;( L 为单链表的头指针) | L指向首元结点 | L指向头结点,头结点指向首元结点 |
// (为更好理解清楚,博主会在每个操作前面放上单链表的结构定义)
// 单链表的存储结构
typedef struct LNode{
ElemType data; //结点的数据域
struct LNode *next; //结点的指针域
}LNode, *LinkList; // LinkList 为指向结构体 LNode 的指针类型
// 构造一个空的带头结点的单链表L
Status InitList(LinkList &L){
L = new LNode; //生成新结点作为头结点,用头指针L指向头结点 (C++)
L->next == NULL; //头结点的指针域置空
return OK;
}
// 也可以用以下方式
// 构造一个空的带头结点的单链表L
Status InitList(LinkList &L){
L = (LNode *)malloc(sizeof(LNode)); //生成新结点作为头结点,用头指针L指向头结点 (C语言)
L->next == NULL; //头结点的指针域置空
return OK;
}
【算法步骤】
将值为 e 的新结点插入到表的第 i 个结点的位置上,即插入到结点 与 之间,具体插入过程如上图所示,图中对应的 5 个步骤说明如下。
① 查找结点 并由指针 p 指向该结点。
② 生成一个新结点 *s。
③ 将新结点 *s 的数据域置为 e。
④ 将新结点 *s 的指针域指向结点 。
⑤ 将结点 *p 的指针域指向新结点 *s。
// 单链表的存储结构
typedef struct LNode{
ElemType data; //结点的数据域
struct LNode *next; //结点的指针域
}LNode, *LinkList; // LinkList 为指向结构体 LNode 的指针类型
// 在带头结点的单链表 L 中第 i 个位置插入值为 e 的新结点
Status ListInsert (LinkList &L, int i, ElemType e)
{
p = L;
j = 0;
while(p && (j < i - 1)){ //查找第 i-1 个结点,P指向该结点
p = p->next;
++j;
}
if(!p || j > i - 1) // i > n+1 或者 i < 1
return ERROR;
s = new LNode; //生成新结点 *s
s->data = e; //将结点 *s 的数据域置为 e
s->next = p->next; //将结点 *s 的指针域指向结点ai
p->next = s; //将结点 *p 的指针域指向结点 *s
return OK;
}
// 单链表的存储结构
typedef struct LNode{
ElemType data; //结点的数据域
struct LNode *next; //结点的指针域
}LNode, *LinkList; // LinkList 为指向结构体 LNode 的指针类型
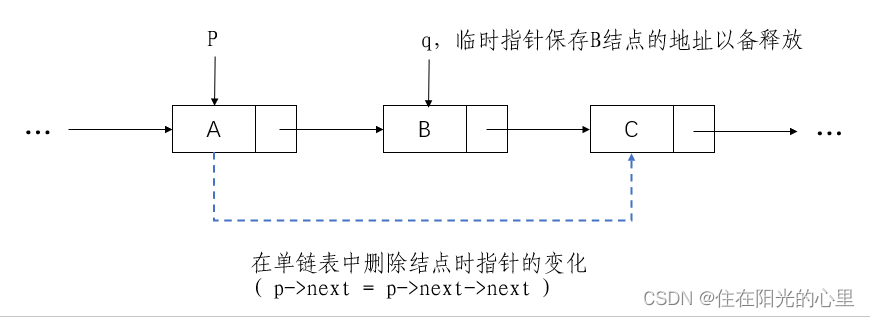
//在带头结点的单链表 L 中,删除第 i 个元素
Status ListDelete(LinkList &L, int i){
p = L;
j = 0;
while((p->next) && (j < i-1)){ //查找第 i-1 个个结点,p指向该结点
p = p->next;
++j;
}
//注意与插入操作的区别,因为合法的插入位置有 n+1 个,而合法的删除位置只有 n 个
if(!(p->next) || (j > i-1)) //当 i > n 或 i < 1 时,删除位置不合理
return ERROR;
q = p->next; //临时保存被删结点的地址以备释放
p->next = q->next; //改变删除结点前驱结点的指针域
delete q; //释放删除结点的空间
return OK;
}注意:单链表是非随机存取的存储结构,即不能直接找到表中某个特定的结点。所以在查找某个特定的结点,需要从表头开始遍历,依次查找。
// 单链表的存储结构
typedef struct LNode{
ElemType data; //结点的数据域
struct LNode *next; //结点的指针域
}LNode, *LinkList; // LinkList 为指向结构体 LNode 的指针类型
// 在带头结点的单链表 L 中查找值为 e 的元素
LNode *LocateElem(LinkList L, ElemType e){
p = L->next; //初始化,p指向首元结点
while(p && p->data != e){ //顺链域向后扫描,直到 p 为空或 P 所指结点的数据域等于 e
p = p->next; //p指向下一个结点
}
return p; //查找成功返回值为e的结点地址p,查找失败p为NULL
}
// 在带头结点的单链表 L 中查找序号为 i 的结点
LNode *LocateElem(LinkList L, int i){
int j = 1; //计数,初始为1
LNode *p = L->next; //头结点指针赋给p
if(i == 0) return L; //若 i 等于 0,则返回头结点
if(i < 1) return NULL; //若 i 无效,则返回 NULL
while(p && j < i){ //从第一个结点开始找,查找第 i 个结点
p = p->next;
j++;
}
return p; //返回第 i 个结点的指针,若 i 大于表长,则返回 NULL
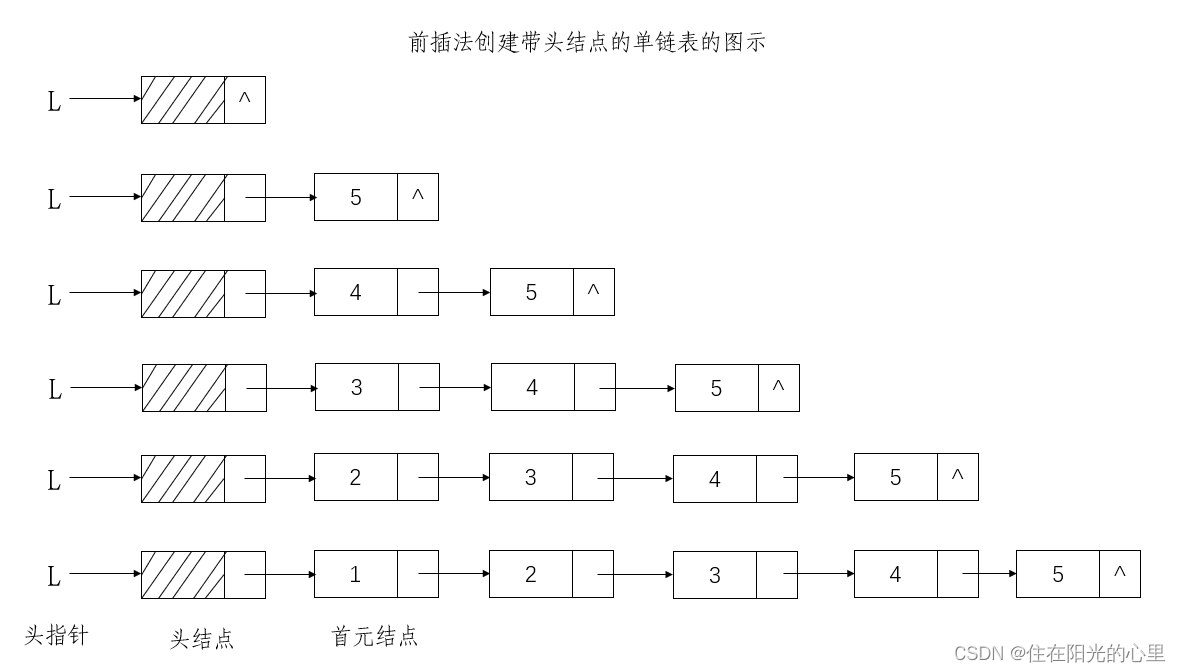
}前插法:通过将新结点逐个插入链表的头部(头结点之后)来创建链表,每次申请一个新结点,读入相应的数据元素值,然后将新结点插入到头结点之后。
注意:输入顺序与线性表中的逻辑顺序是相反。
例如:输入顺序:5,4,3,2,1 线性表:1,2,3,4,5
// 单链表的存储结构
typedef struct LNode{
ElemType data; //结点的数据域
struct LNode *next; //结点的指针域
}LNode, *LinkList; // LinkList 为指向结构体 LNode 的指针类型
//逆位序输入 n 个元素的值,用前插法创建带头结点的单链表L
void CreatList_H(LinkList &L, int n){
L = new LNode;
L->next = NULL; // 建立一个带头结点的空链表
for(int i = 0; i < n; ++i){
p = new LNode; //生成新结点 *p
cin>>p->data; //输入元素值赋给新结点 *p 的数据域
//将新结点 *p 插入到头结点之后
p->next = L->next;
L->next = p;
}
}
后插法:通过将新结点逐个插入到链表的尾部来创建链表。同前插法一样,每次申请一个新结点,读入相应的数据元素值。不同的是,为了使新结点能插入到表尾,需增加一个尾指针 r 指向链表的尾结点。
注意:输入顺序与线性表中的逻辑顺序是相同的。
例如:输入顺序:1,2,3,4,5 线性表:1,2,3,4,5
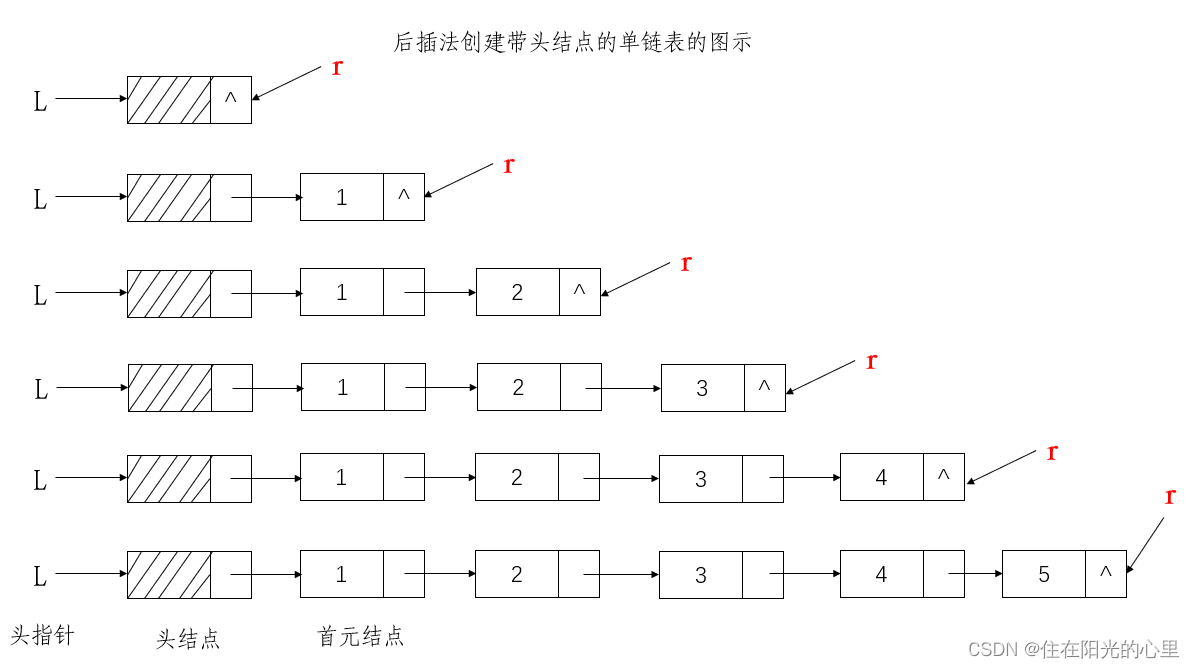
// 单链表的存储结构
typedef struct LNode{
ElemType data; //结点的数据域
struct LNode *next; //结点的指针域
}LNode, *LinkList; // LinkList 为指向结构体 LNode 的指针类型
//顺序输入 n 个元素的值,用后插法创建带头结点的单链表L
void CreatList_R(LinkList &L, int n){
L = new LNode;
L->next = NULL; //建立一个带头结点的空链表
r = L; //尾指针 r 指向头结点
for(int i = 0; i < n; ++i){
p = new LNode; //生成新结点 *p
cin>>p->data; //输入元素值赋给新结点 *p 的数据域
//将新结点 *p 插入尾结点 *r 之后
p->next = NULL;
r->next = p;
r = p; // r 指向新的尾结点 *p
}
我想要这样的参数:programdothis--additional--options和:programdothat--with_this_option=value我不知道该怎么做。我唯一能做的就是在开头使用带有--的参数。有什么想法吗? 最佳答案 要使用OptionParser处理位置参数,首先使用OptionParser解析开关,然后从ARGV中获取剩余的位置参数:#optparse-positional-arguments.rbrequire'optparse'options={}OptionParser.newdo|opts
前文,我们实现了认识了链表这一结构,并实现了无头单向非循环链表,接下来我们实现另一种常用的链表结构,带头双向循环链表。如有仍不了解单向链表的,请看这一篇文章(7条消息)【数据结构和算法】认识线性表中的链表,并实现单向链表_小王学代码的博客-CSDN博客目录前言一、带头双向循环链表是什么?二、实现带头双向循环链表1.结构体和要实现函数2.初始化和打印链表3.头插和尾插4.头删和尾删5.查找和返回结点个数6.在pos位置之前插入结点7.删除指定pos结点8.摧毁链表三、完整代码1.DSLinkList.h2.DSLinkList.c3.test.c总结前言带头双向循环链表,是链表中最为复杂的一种结
以前的答案answer类似question是错误的。Ruby中均未提及方法调用documentation也不在communitywiki.不带括号的方法调用高于或or似乎比没有括号的方法调用具有更低的优先级:putsfalseortrue相当于(putsfalse)ortrue并显示false。注意:我知道不应该使用or。尽管如此,这仍然是一个很好的例子,表明某些运算符的优先级确实低于方法调用。低于||putsfalse||true相当于puts(false||true)并显示true。带括号的方法调用用于方法调用的括号don'tseem进行分组:puts(falseortrue)#S
我正在使用ASP.NET捆绑机制:BundleTable.Bundles.Add(newScriptBundle("~/Scripts/Master-js").Include("~/Scripts/respond.min.js","~/Scripts/jquery.form.js","~/Scripts/jquery.MetaData.js","~/Scripts/jquery.validate.js","~/Scripts/bootstrap.js","~/Scripts/jquery.viewport.js","~/Scripts/jquery.cookie.js"));我希望在构
我遇到了这个区别,在ExploringJS中没有很好地解释Qualifiedandunqualifiedimportsworkthesameway(theyarebothindirections)有什么区别,因此这个陈述是什么意思? 最佳答案 严格来说,JavaScrpit中没有合格/不合格的导入。这些术语在AxelRauschmayer博士的“探索ES6”一书中在循环依赖的上下文中使用,大致意思是:不合格导入(直接导入模块的一部分):通用JS:varfoo=require('a').foo//doesn'tworkwithcycl
1.单链表单链表是多个节点通过指针串联起来的线性结构,每个节点分为两部分,一个是数据域,一个为指针域,头节点的数据域为空,最后一个节点的指针域胃为空,链表的前一个节点的指针域,存放的是下一个节点的地址。数据域:存放数据;指针域:指向下一个节点的指针。头节点的作用:为了方便操作整个链表,它并不保存具有实际意义的数据。创建链表的步骤(1)构建节点计算机中没有现成的节点,我们需要自己创建它。任意的节点都包含了两部分:左边部分data存储数据,右边部分next存储指针,就是下一个节点的地址。data中可以存放任意数据,包括int,float,double等,可以存放单个数据,也尅存放多个数据。例子构建
声明**本文档不做任何商业用途,是作者个人与团队的学习数据结构的心得笔记以及在考研备考中的学习回顾,加以整理,仅用于学习交流,任何人不得进行有偿销售、本文档的著作权归作者或团队所有,文中部分引用的图片说明来源,特此感谢。任何人使用本文档所述内容所衍生的风险与责任均由其自行承担,本文档的作者或团队不承担任何因此产生的直接或间接损失或责任。同时,本文档的内容仅代表作者或团队的观点和理解,并不代表其他任何组织或个人的观点和立场。读者在阅读和使用本文档时,请自行判断其内容的正确性、准确性和实用性,十分欢迎读者批评指正、提出建议意见,不足之处,多多包涵。**团队微信公众号:CodeLab代码实验室作者C
笔记首发于:lengyueling.cnPDF版本附在 lengyueling.cn 对应文章结尾,欢迎下载访问交流绪论数据结构在学什么如何用程序代码把现实世界的问题信息化如何用计算机高效地处理这些信息从而创造价值数据结构的基本概念什么是数据:数据是信息的载体,是描述客观事物属性的数、字符及所有能输入到计算机中并被计算机程序识别和处理的符号的集合。数据是计算机程序加工的原料。现代计算机处理的数据:现代计算机——经常处理非数值型问题对于非数值型的问题:我们关心每个个体的具体信息我们还关心个体之间的关系数据元素:数据元素是数据的基本单位,通常作为一个整体进行考虑和处理。数据项:一个数据元素可由若干
我正在玩围棋的一些基本计时,有一个问题。我想在Golang计算数组的每个元素的平方根时计算时间,但无论是否保留输出,我都会得到两个不同的答案。这是我的第一个版本:packagemainimport("fmt""time""math""math/rand")//ArandomarrayofintegersfuncrandomArray(maxint,lenint)[]int{a:=make([]int,len)fori:=0;i平均耗时约36毫秒:timetaken:36.542019ms9现在,当我用空白标识符替换输出“sqrt”时,我得到的速度要慢得多。具体来说,我将main()替换
这个问题在这里已经有了答案:Valuereceivervs.pointerreceiver(3个答案)关闭3年前。我刚接触golang。只是想了解为Calc类型声明的两种方法之间的区别。第一个函数sum被声明为(c*Calc)Sum,另一个没有*的函数被声明为(cCalc)Minus。两者之间的区别和推荐的写法是什么?我看到不同之处在于我们如何调用main下的函数。point*类型的方法需要new(Calc),另外一个可以直接调用Calc{}.Sum。一些行为解释会有所帮助。funcmain(){Calc{}.Minus(2,2)c:=new(Calc)c.Sum(3,2)}typeC