分布式系统是由多个独立的计算机节点协同工作,以共同完成一个任务的系统。这些节点通过网络进行通信和协调,共享计算和存储资源,从而实现对更大规模问题的处理和更高系统可用性的要求。
分布式应用场景:
id就是一个身份的标识,在日常生活以及软件系统中都是必不可少的存在的。id可以用来唯一标识一个对象或事件,例如我们都有一个身份证号码来标识每一位公民,在软件系统中,为了标识每一个用户,会有对应的user id,在网购时有订单id,发表评论时有评论id等等。
在计算机科学中,ID(Identifier)通常是一个数字或字符串,用于唯一标识某个实体。在软件开发中,ID常常用于识别、定位、查找和管理对象,例如用户、订单、商品等。
在分布式系统中,生成唯一的ID是非常重要的,因为分布式系统可能包含多个节点和多个数据中心,每个节点都需要在处理数据和请求时分配唯一的ID。这样可以帮助在分布式系统中进行诊断、故障排除和性能分析,同时还可以保证数据的一致性和正确性。
分布式ID(Distributed ID)是指在分布式系统中生成全局唯一的ID的方法或算法。分布式ID的生成需要满足以下几个条件:
常见的分布式ID生成算法包括UUID、Snowflake、Leaf等。这些算法都可以生成唯一的ID,并且在分布式系统中具有可排序性和可读性。
UUID(通用唯一识别码)是一种用于唯一标识信息的标准格式,通常由32位的16进制数字和4个“-”符号构成,形式为8-4-4-4-12的36个字符,如:123e4567-e89b-12d3-a456-426655440000,在Java中可以通过java.util.UUID#randomUUID来调用。 有意思的是uuid是存在极小概率重复可能的,不过由于过低,大部分情况都可以忽略。
特点:
UUID的优点:
全局唯一性:UUID可以保证全球范围内的唯一性,即使在分布式系统中也可以使用。
高性能:生成UUID的算法比较简单,执行效率很高,在分布式系统中广泛使用。
不可预测性:由于UUID是随机生成的,因此无法被猜测或推断出来,可以提高系统的安全性。
UUID的缺点:
在分布式系统中,由于系统规模的增大和负载的增加,单点自增ID已经不能满足需求。UUID是一种很好的解决方案,可以保证全球范围内的唯一性,并且可以在分布式系统中广泛使用。在一些需要防止ID被猜测或推断的场景下,如密码重置、授权等场景,使用UUID可以提高系统的安全性。但是,UUID的缺点也需要考虑,如可读性差、冲突概率等。为了克服这些缺点,一些方案使用了更加复杂的算法来生成ID,如Twitter的Snowflake算法、美团点评的Leaf算法等。
基于数据库的分布式ID生成方法是一种生成全局唯一ID的方法。它的主要原理是利用数据库的特性,如自增主键、事务和锁,保证ID的唯一性和有序性。下面将详细介绍这种方法的实现原理和应用。
基于数据库的分布式ID生成方法的实现原理如下:
通过上述步骤,我们可以保证在分布式系统中生成的ID是唯一且有序的。
基于数据库的分布式ID生成方法通常适用于以下场景:
优点:
然而,它也存在以下缺点:
Redis的优点是单线程、免去了线程间切换的开销,存取速度快。Redis本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
但Redis无法保证在主节点宕机时自动完成数据一致性的同步操作。那么在极端情况下,主节点挂掉后可能产生重复的id。
Snowflake 算法是 Twitter 开源的分布式 ID 生成算法,其核心思想是:一个 long 型的 ID 由 64 位组成,其中,第1 个为符号位,41 个为时间戳,5 个为数据中心标识,5 个为机器标识,12 个为序列号。由此,Snowflake 算法可以生成全局唯一的 ID,同时,其按时间有序递增,也便于对数据进行排序。
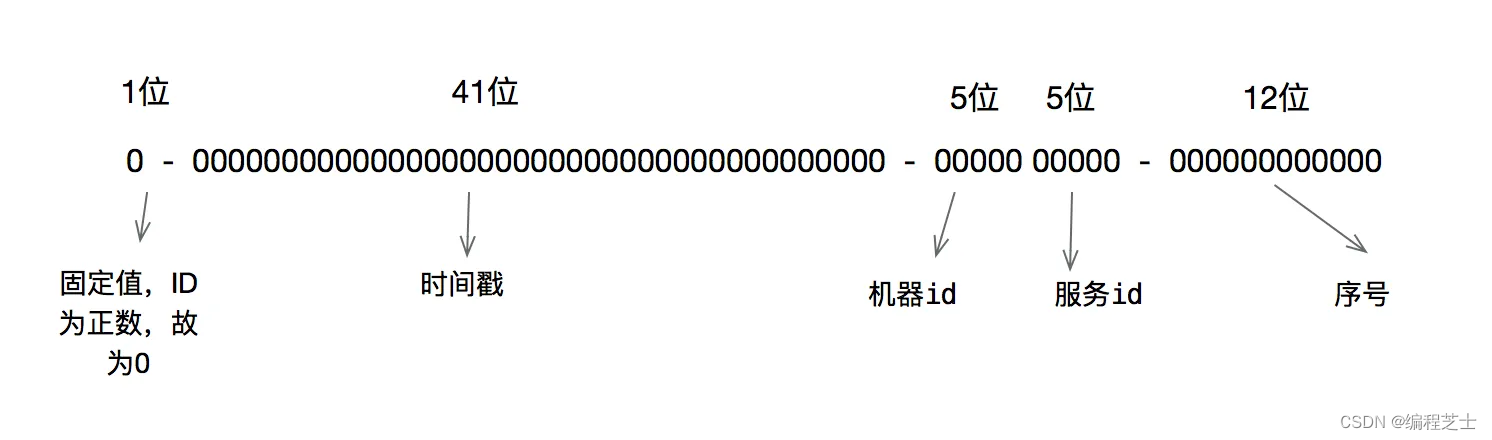
Snowflake 算法的特点如下:
Snowflake 算法的优点如下:
Snowflake 算法的缺点如下:
该方案的主要思想是将ID的生成工作交由独立的ID生成服务,由其负责ID的生成和管理。在Leaf算法中,ID生成服务使用数据库和缓存协同工作,生成的ID具有可读性、可排序性和趋势递增性等特点。
Leaf算法将ID分成三个部分:时间戳、数据中心ID、业务ID。其中,时间戳占用的位数最多,可以根据需要分配更多的位数;数据中心ID和业务ID分别用于区分不同的数据中心和业务,分别占用固定的位数。Leaf算法的位分配策略如下表所示:

在Leaf算法中,时间戳的精度可以通过配置来控制,可以选择使用秒、毫秒或微秒级别的时间戳。同时,Leaf算法也支持使用基于ZooKeeper的全局唯一ID生成器,可以避免时间戳回拨等问题。
优点:
缺点:
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
我正在使用Maruku,将Markdown(超集)转换为HTML,你知道我该怎么做才能从HTML转换为Markdown吗? 最佳答案 Google发现了一个名为reverse_markdown的ruby脚本.它似乎可以满足您的需求。 关于ruby-on-rails-我需要从HTML转到markdown,有什么建议吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/175162
capybara找不到在我的cucumber测试中用它的id标记。当我save_and_open_page时,我能够看到该元素.但我无法通过has_css?找到它或find:pry(#)>page.html.scan(/notice_sent/).count=>1pry(#)>page.html.scan(/id=\"notice_sent\"/).count=>1pry(#)>page.find('#notice_sent')Capybara::ElementNotFound:Unabletofindcss"#notice_sent"from/Users/me/.gem/ruby/2
目前我正在使用这个正则表达式从YoutubeURL中提取视频ID:url.match(/v=([^&]*)/)[1]我怎样才能改变它,以便它也可以从这个没有v参数的YoutubeURL获取视频ID:http://www.youtube.com/user/SHAYTARDS#p/u/9/Xc81AajGUMU感谢阅读。编辑:我正在使用ruby1.8.7 最佳答案 对于Ruby1.8.7,这就可以了。url_1='http://www.youtube.com/watch?v=8WVTOUh53QY&feature=feedf'url
在开发模式下:nil.id=>"Calledidfornil,whichwouldmistakenlybe4--ifyoureallywantedtheidofnil,useobject_id"在生产模式中:nil.id=>4为什么? 最佳答案 在您的环境配置中查找包含以下内容的行:#Logerrormessageswhenyouaccidentallycallmethodsonnil.config.whiny_nils=true#orfalseinproduction.rb这是为了防止您在开发模式下调用nil上的方法。我猜他们在生
如何在rakedb:migrate:status中删除带有“**NOFILE**”的迁移ID列表?例如:StatusMigrationIDMigrationName--------------------------------------------------up20131017204224Createusersup20131218005823**********NOFILE**********up20131218011334**********NOFILE**********我不明白为什么当我自己手动删除它时它仍然保留旧的迁移文件,因为我正在研究迁移的工作原理。这是为了记录吗?但
我有一组名为Tasks和Posts的资源,它们之间存在has_and_belongs_to_many(HABTM)关系。还有一个连接它们的值的连接表。create_table'posts_tasks',:id=>falsedo|t|t.column:post_id,:integert.column:task_id,:integerend所以我的问题是如何检查特定任务的ID是否存在于从@post.tasks创建的数组中?irb(main):011:0>@post=Post.find(1)=>#@post.tasks=>[#,#]所以我的问题是,@post.tasks中是否存在"@task