什么是阻塞,非阻塞,异步同步,select,poll,epoll?今天我们用一遍文章解开这多年的迷惑。
首先我们想要通过网络接收消息,是这样的一个步骤。
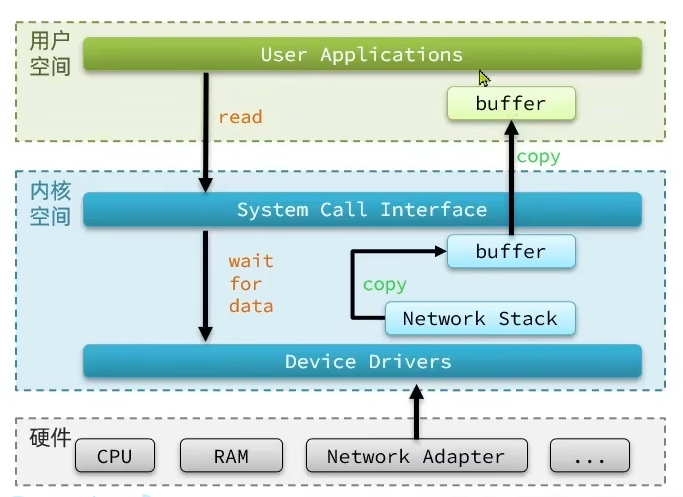
根据我们请求数据的情况不同,以及内核缓冲区到用户缓冲区的不同,分为了阻塞,非阻塞,异步同步的区别。
在《UNIX网络编程》一书中,总结归纳了5种I0模型:
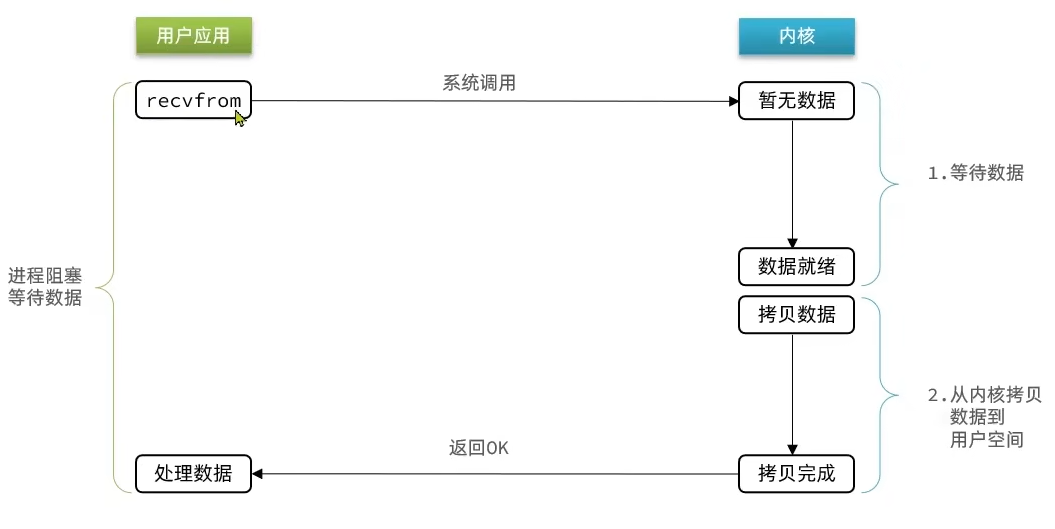
以上可以看出来,根据等待数据的方式不同,分为阻塞和非阻塞。
阻塞IO在请求内核数据的时候,没有数据就会一直阻塞直到获取数据。
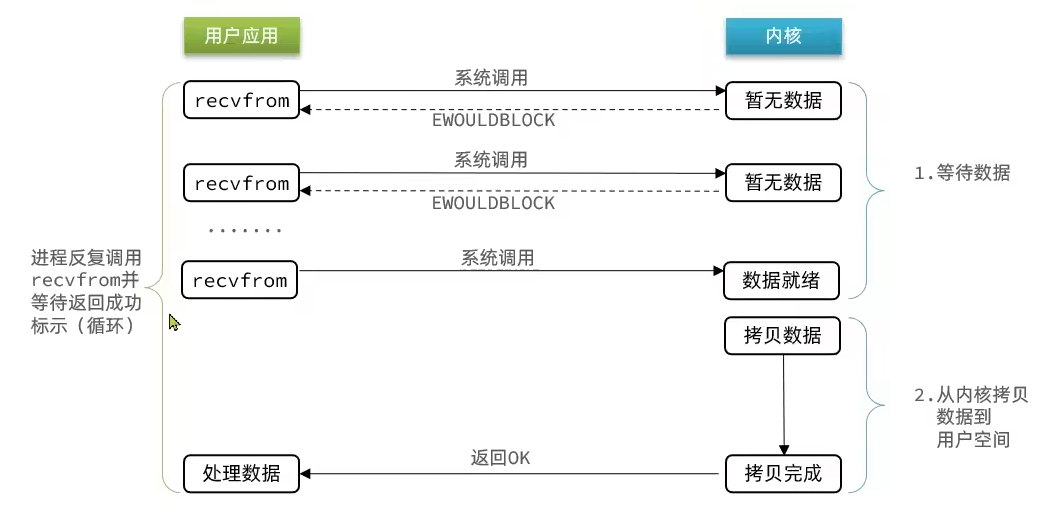
非阻塞IO在等待内核数据的时候,没有数据就会得到没数据的结果,应用可以进行其他动作。
同步IO的主要看内核数据到用户空间的过程是同步进行的就是同步IO
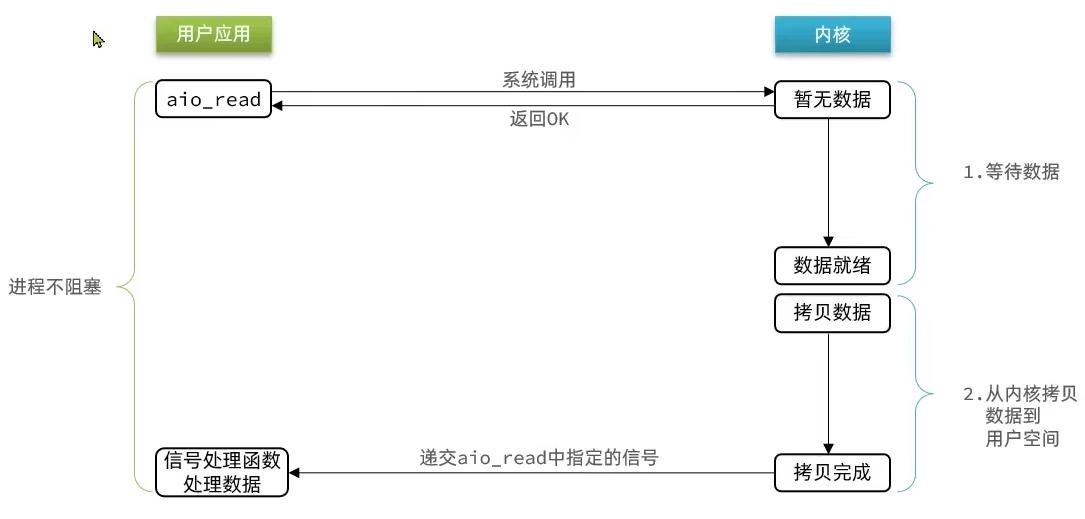
异步IO首先是非阻塞IO,区别在于成功标志的时机。异步IO连内核到用户态的数据拷贝都是异步的,直到数据拷贝完成,才会回调一个信号,通知一切已经准备完成。用户应用此时就可以直接处理结果了。
阻塞非阻塞指的是在获取结果上是否会阻塞等待结果完成
同步异步指的是是否会参与IO读写,或者是等待读写成功的回调
如果是阻塞IO也就是BIO,那么在一个fd(文件描述符)没有数据的时候,就是阻塞一直等待,如果同时有多个fd,对于单线程来说,只能一直等第一个有数据,然后再接着处理第二个,效率很慢。

就像顾客点餐,要一直等到第一个人点完餐,后面的人才有机会。BIO也有个解决办法,一般是增加多线程,每个线程都维护一个fd,就相当于为每个顾客都添加一个点餐台。在fd足够多的情况下,会有大量的线程被创建,线程可是有上限的,开销也大(更多线程需要更多的内存空间)。
如果是非阻塞IO也就是NIO,会有顾客没点完餐,然后造成CPU一直在询问一直空转的情况。
因此引入了IO多路复用模型:利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源
文件描述符( File Descriptor) :简称FD,是一个从0开始递增的无符号整数,用来关联Linux中的一一个文件。在Linux
中,一切皆文件,例如常规文件、视频、硬件设备等,当然也包括网络套接字(Socket),
这时候每来一个顾客(FD),我们就会给他一个开关(注册进监听事件),一个服务员(一个线程)等待开关亮起(阻塞等待事件)。有顾客完成,就会按下开关,一定的频率下开关会亮起(事件通知),服务员会选取按下开关的一批人,给他们点餐(批量处理事件)。
IO多路复用的实现有select,poll,epoll,我们来看看他们的优缺点。
select是Linux中最早的I/O多路复用实现方案,并且windows操作系统上只支持select。这就是为啥window发挥不出redis的最大性能的一个原因。

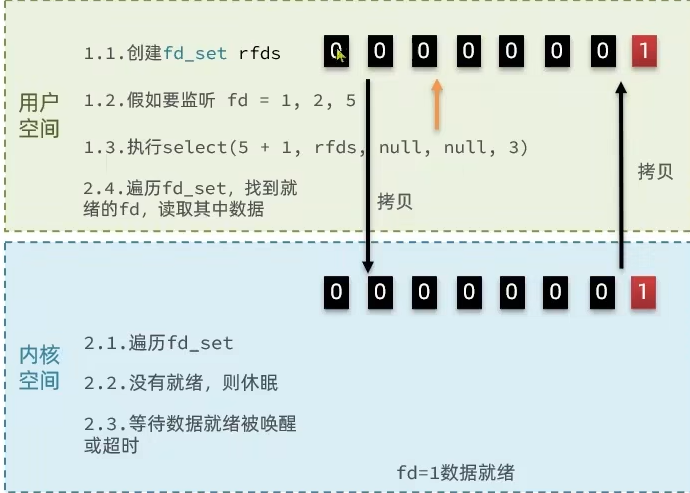
select函数执行流程
用户空间创建fd_set,把需要监听的位置置1,比如 1,2,5用户空间拷贝fd_set(注册的事件集合)到内核空间内核遍历所有fd文件,并将当前进程挂到每个fd的等待队列中,当某个fd文件设备收到消息后,会唤醒设备等待队列上睡眠的进程,那么当前进程就会被唤醒内核如果遍历完所有的fd没有I/O事件,则当前进程进入睡眠,当有某个fd文件有I/O事件或当前进程睡眠超时后,当前进程重新唤醒再次遍历所有fd文件内核有事件产生,会把fd_set中有事件的位置保留为1,没有事件的位置擦除为0.内核拷贝fd_set给用户空间用户空间线程被唤醒,遍历fd_set为1的位置,确认是哪些fd有就绪事件,然后开始处理用户空间处理完事件,再一次将要监听的fd_set设置为1,重复之前的监听动作根据上面可以很清楚的看出整个执行流程在用户空间和内核空间的切换。
select函数的缺点
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的

poll运行流程
①创建pollfd数组, 向其中添加关注的fd信息,数组大小自定义
②调用poll函数,将pollfd数组拷贝到内核空间,转链表存储,无上限
③内核遍历fd,判断是否就绪
④数据就绪或超时后,拷贝pollfd数组到用户空间,返回就绪fd数量n
⑤用户进程判断n是否大于0
⑥大于0则遍历pollfd数组,找到就绪的fd
与select对比
poll还是没有解决需要遍历判断fd事件的方式,只是增加了监听数量,在fd很多的情况下,性能下降的更加严重
epoll可以理解为event pool,不同与select、poll的轮询机制,epoll采用的是事件驱动机制,每个fd上有注册有回调函数,当网卡接收到数据时会回调该函数,同时将该fd的引用放入rdlist就绪列表中。
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。

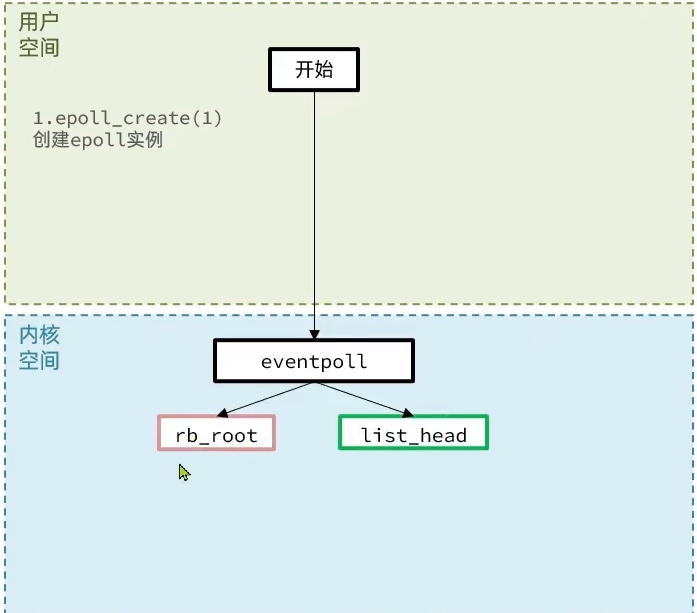
他主要有三个函数,epoll的执行流程
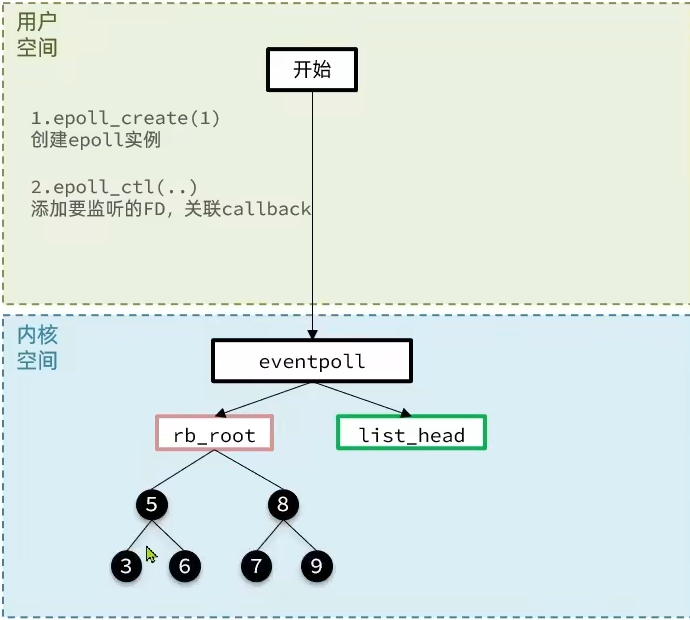
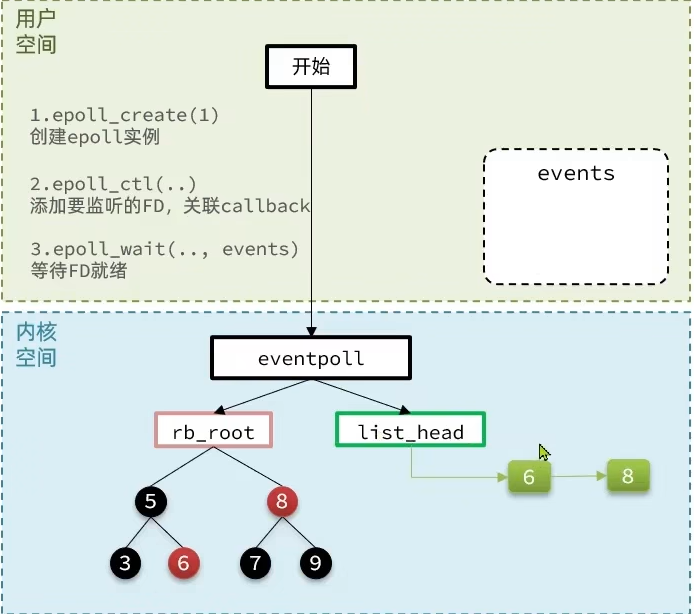
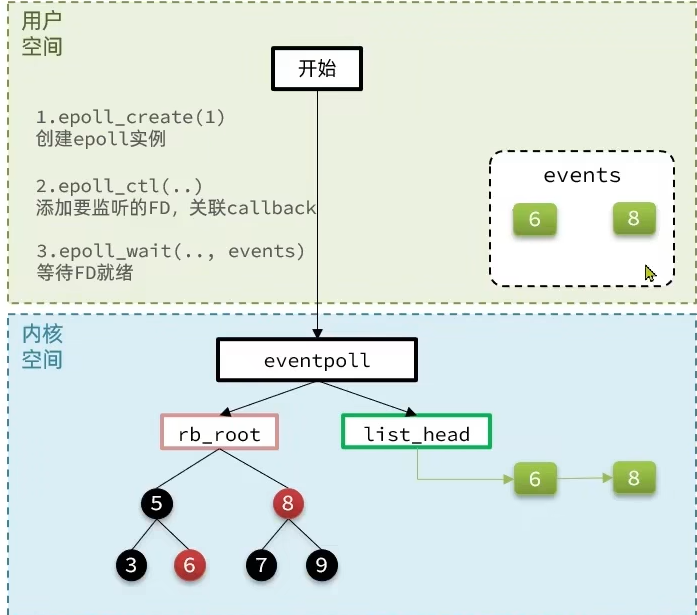
对应的redis的server执行流程
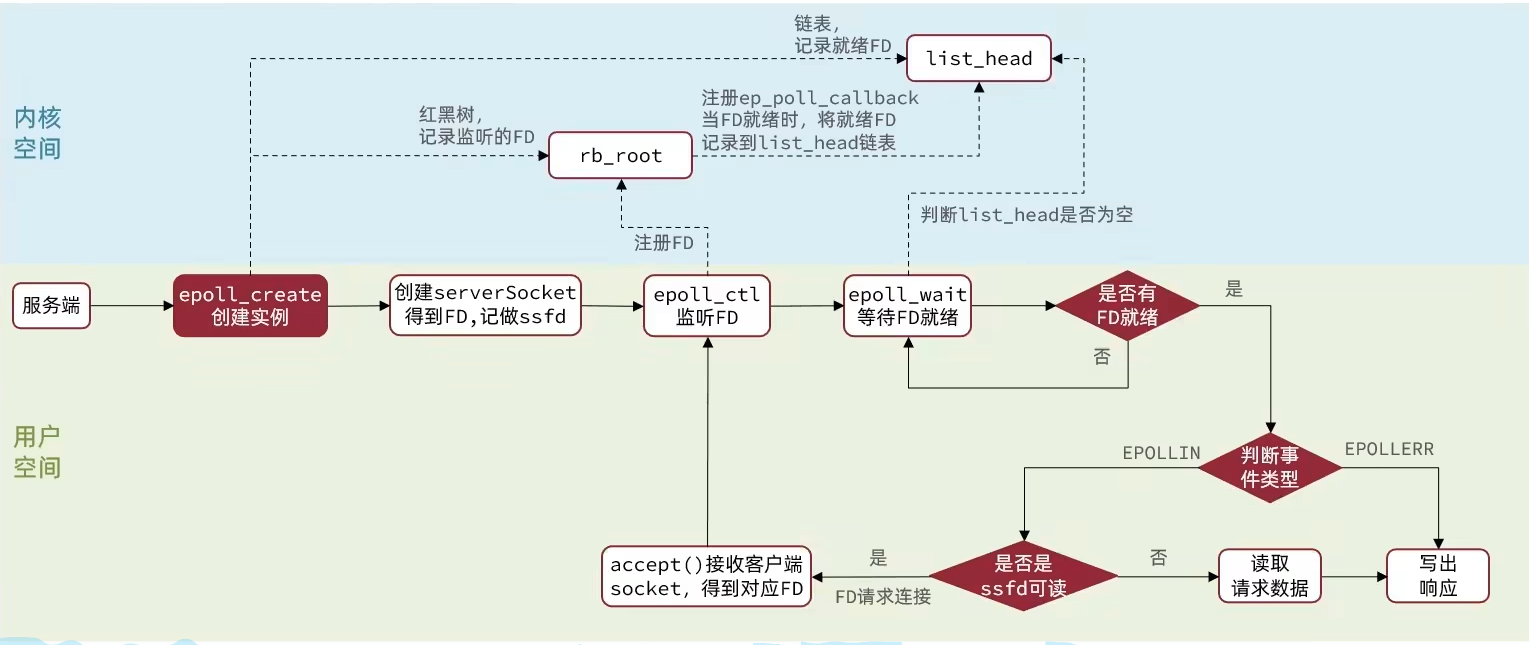
epoll优点
读事件很好理解,有一个读事件就立马处理请求,怎么理解写事件?
当socket 写缓冲区已满,假如设置了非阻塞I/O,应用程序调用send会返回EAGAIN,告诉应用程序写缓冲区已满,下次再来尝试调用,这时候就有一个尝试的时机问题,应用程序怎么知道socket 缓冲区可写呢?如果频繁调用send,会浪费CPU。这时候,epoll就排上用场了,对socket 设置写事件,并添加到 epoll中,应用程序调用epoll_wait,当该socket 的写缓冲有空余时,就返回对应的写事件,应用程序这时候就可以调用send,发送数据。
所以写事件是用来告诉程序,写缓冲是空余的。一般情况下fd都是有写事件的。但是在写缓冲区满了的时候,就会频繁触发写事件。所以我们可以一开始不监听写事件,直到发现数据量可能大于缓冲区,再监听写事件
参考:高效处理写事件
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我正在尝试解析一个文本文件,该文件每行包含可变数量的单词和数字,如下所示:foo4.500bar3.001.33foobar如何读取由空格而不是换行符分隔的文件?有什么方法可以设置File("file.txt").foreach方法以使用空格而不是换行符作为分隔符? 最佳答案 接受的答案将slurp文件,这可能是大文本文件的问题。更好的解决方案是IO.foreach.它是惯用的,将按字符流式传输文件:File.foreach(filename,""){|string|putsstring}包含“thisisanexample”结果的
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
print"Enteryourpassword:"pass=STDIN.noecho(&:gets)puts"Yourpasswordis#{pass}!"输出:Enteryourpassword:input.rb:2:in`':undefinedmethod`noecho'for#>(NoMethodError) 最佳答案 一开始require'io/console'后来的Ruby1.9.3 关于ruby-为什么不能使用类IO的实例方法noecho?,我们在StackOverflow上
当我将IO::popen与不存在的命令一起使用时,我在屏幕上打印了一条错误消息:irb>IO.popen"fakefake"#=>#irb>(irb):1:commandnotfound:fakefake有什么方法可以捕获此错误,以便我可以在脚本中进行检查? 最佳答案 是:升级到ruby1.9。如果您在1.9中运行它,则会引发Errno::ENOENT,您将能够拯救它。(编辑)这是在1.8中的一种hackish方式:error=IO.pipe$stderr.reopenerror[1]pipe=IO.popen'qwe'#
当我尝试使用“套接字”库中的方法“read_nonblock”时出现以下错误IO::EAGAINWaitReadable:Resourcetemporarilyunavailable-readwouldblock但是当我通过终端上的IRB尝试时它工作正常如何让它读取缓冲区? 最佳答案 IgetthefollowingerrorwhenItrytousethemethod"read_nonblock"fromthe"socket"library当缓冲区中的数据未准备好时,这是预期的行为。由于异常IO::EAGAINWaitReadab
我需要将目录中的一堆文件上传到S3。由于上传所需的90%以上的时间都花在了等待http请求完成上,所以我想以某种方式同时执行其中的几个。Fibers能帮我解决这个问题吗?它们被描述为解决此类问题的一种方法,但我想不出在http调用阻塞时我可以做任何工作的任何方法。有什么方法可以在没有线程的情况下解决这个问题? 最佳答案 我没有使用1.9中的纤程,但是1.8.6中的常规线程可以解决这个问题。尝试使用队列http://ruby-doc.org/stdlib/libdoc/thread/rdoc/classes/Queue.html查看文
在ruby中...我有一个由外部进程创建的IO对象,我需要从中获取文件名。然而我似乎只能得到文件描述符(3),这对我来说不是很有用。有没有办法从此对象获取文件名甚至获取文件对象?我正在从通知程序中获取IO对象。所以这也可能是获取文件路径的一种方式? 最佳答案 关于howtogetathefilenameinC也有类似的问题,我将在这里以ruby的方式给出这个问题的答案。在Linux中获取文件名假设io是您的IO对象。以下代码为您提供了文件名。File.readlink("/proc/self/fd/#{io.fileno}")例
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
一、网络环境及TOP1.1R1相当于内网的一台PC, IP:192.168.1.10 网关为 192.168.1.254[R1]iproute-static0.0.0.00192.168.1.254#R1配置默认路由(网关)1.2R2为出口路由器,分别连接内网R1及外网R31)R2 内网接口IP:192.168.1.2542)R2外网接口IP:100.1.1.102)R2NAT地址为:100.1.1.11-100.1.1.14二、静态NAT配置1.1静态NAT(一对一双向)R2配置静态NAT,将公网IP100.1.1.11映射到内网R1 192.168.1.10[R2]intg0/0/1[R2