 △光是目录就有这么长……至于谁是性价比之王,不卖关子,这里先放上Tim哥的结论:
△光是目录就有这么长……至于谁是性价比之王,不卖关子,这里先放上Tim哥的结论:对于16位训练过程,RTX 3080的性价比最高;对于8位和16位推理,RTX 4070Ti的性价比最高。有意思的是,不只这俩,他在本文推荐的显卡全是英伟达家的——Tim哥觉得,对于深度学习,“AMD GPU+ROCm”目前还打不过“NVIDIA GPU+CUDA”。
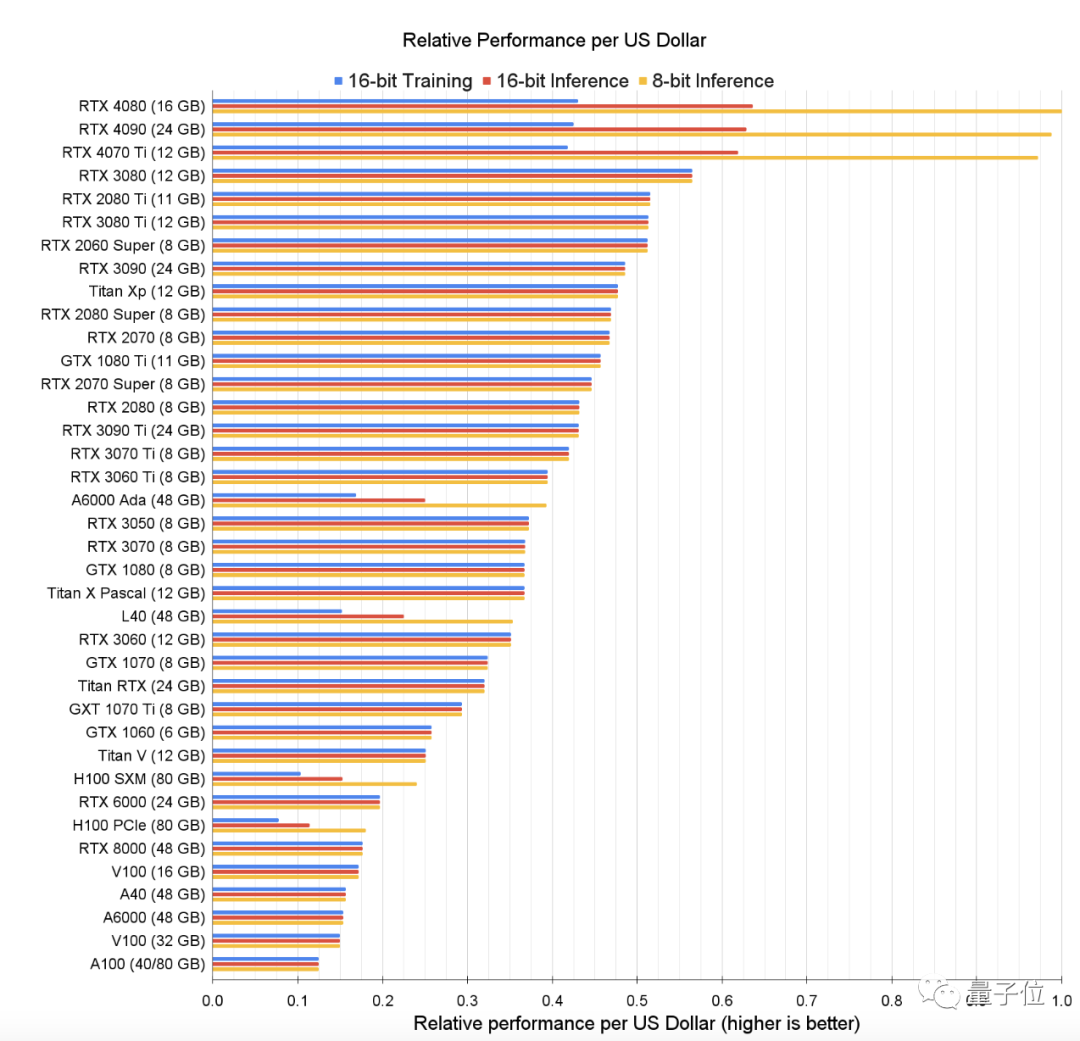 △蓝色-16位训练;红色-16位推理;黄色-8位推理看到这个,你可能一脸问号:从表格来看,不是RTX 4080在8位和16位推理上的性价比更高吗?其实,咱们开头说的是“综合性价比”——除了看一美元能买多少算力,还要结合显卡的运行成本,比如电费。所以总的来说,还是RTX 4070Ti的性价比更高。虽然RTX3080和RTX 4070 Ti性价比高,但这俩的内存是个明显短板:Tim哥指出,12GB在很多情况下都不够用,要运行Transformer模型的话,至少需要24GB。于是,Tim哥又贴心地做了一个小程序,帮你根据不同的任务选择最合适的GPU。
△蓝色-16位训练;红色-16位推理;黄色-8位推理看到这个,你可能一脸问号:从表格来看,不是RTX 4080在8位和16位推理上的性价比更高吗?其实,咱们开头说的是“综合性价比”——除了看一美元能买多少算力,还要结合显卡的运行成本,比如电费。所以总的来说,还是RTX 4070Ti的性价比更高。虽然RTX3080和RTX 4070 Ti性价比高,但这俩的内存是个明显短板:Tim哥指出,12GB在很多情况下都不够用,要运行Transformer模型的话,至少需要24GB。于是,Tim哥又贴心地做了一个小程序,帮你根据不同的任务选择最合适的GPU。 其背后的核心思想是:不管干啥,一定要保证GPU的内存满足你的需求。首先,要弄清楚这个GPU是个人用还是公用,还有就是要处理什么任务——比如,是要训练语言大模型(LLM)吗、参数量有没有超过130亿?还是就做点小项目?然后再根据自己的钱包情况,参考上面的表格,选择最合适的GPU。举个例子:如果要训练LLM且参数量超过130亿,不差钱的可以选择支持Azure公有云的A100或者H100;追求性价比的话,可以选支持AWS的A100或者H100。但如果预算实在有限,建议放弃……(在亚马逊上,40GB的英伟达Tesla A100售价为11769美元起,约合人民币79529元。当然这都是针对国外的情况,在国内炼丹仅供参考)另外,Tim哥还支了一招:最好用云GPU(比如Lambda云)来估测一下所需的GPU内存(至少12GB用于图像生成,至少24GB用于处理Transformer)。其实假如GPU仅偶尔使用(每隔几天用几小时),甚至都不用去买个实体的,用云GPU就可以了。对了~如果你真的不在乎这点(?)钱,就要追求极致性能,那可以看看这张表,即GPU的原始性能排行。
其背后的核心思想是:不管干啥,一定要保证GPU的内存满足你的需求。首先,要弄清楚这个GPU是个人用还是公用,还有就是要处理什么任务——比如,是要训练语言大模型(LLM)吗、参数量有没有超过130亿?还是就做点小项目?然后再根据自己的钱包情况,参考上面的表格,选择最合适的GPU。举个例子:如果要训练LLM且参数量超过130亿,不差钱的可以选择支持Azure公有云的A100或者H100;追求性价比的话,可以选支持AWS的A100或者H100。但如果预算实在有限,建议放弃……(在亚马逊上,40GB的英伟达Tesla A100售价为11769美元起,约合人民币79529元。当然这都是针对国外的情况,在国内炼丹仅供参考)另外,Tim哥还支了一招:最好用云GPU(比如Lambda云)来估测一下所需的GPU内存(至少12GB用于图像生成,至少24GB用于处理Transformer)。其实假如GPU仅偶尔使用(每隔几天用几小时),甚至都不用去买个实体的,用云GPU就可以了。对了~如果你真的不在乎这点(?)钱,就要追求极致性能,那可以看看这张表,即GPU的原始性能排行。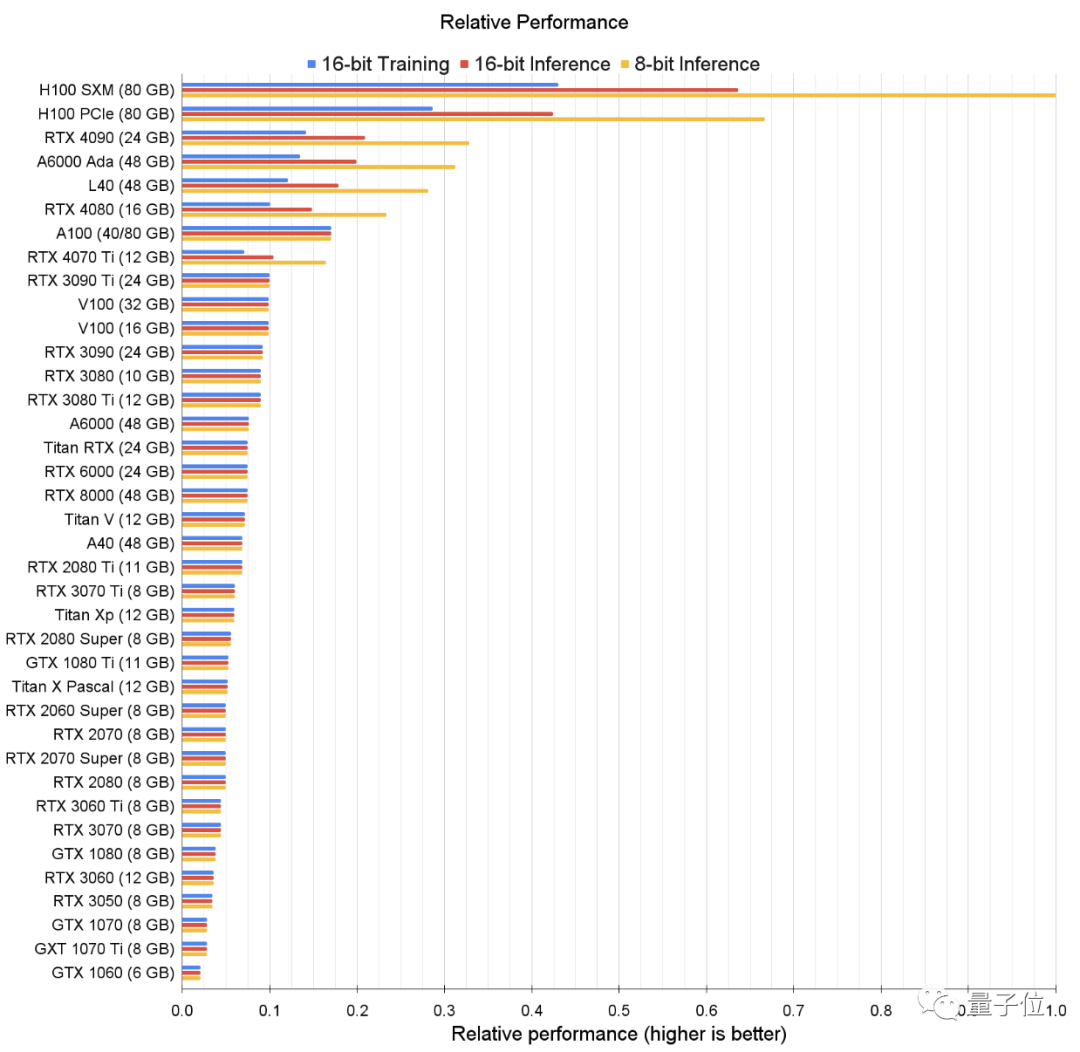 那如果实在钱不够,即使是Tim哥推荐的最便宜的GPU也买不起,还有办法吗?那可以考虑二手呀!先去买个便宜的GPU用于原型设计和测试,然后在云端进行全面的实验和测试。
那如果实在钱不够,即使是Tim哥推荐的最便宜的GPU也买不起,还有办法吗?那可以考虑二手呀!先去买个便宜的GPU用于原型设计和测试,然后在云端进行全面的实验和测试。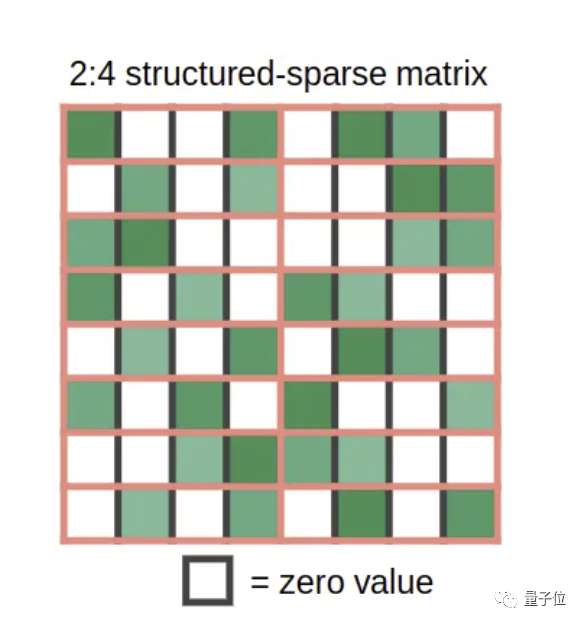 然后把这些稀疏权重矩阵与一些密集输入相乘,Tensor Core功能启动,将稀疏矩阵压缩为密集表示,其大小为下图所示的一半。
然后把这些稀疏权重矩阵与一些密集输入相乘,Tensor Core功能启动,将稀疏矩阵压缩为密集表示,其大小为下图所示的一半。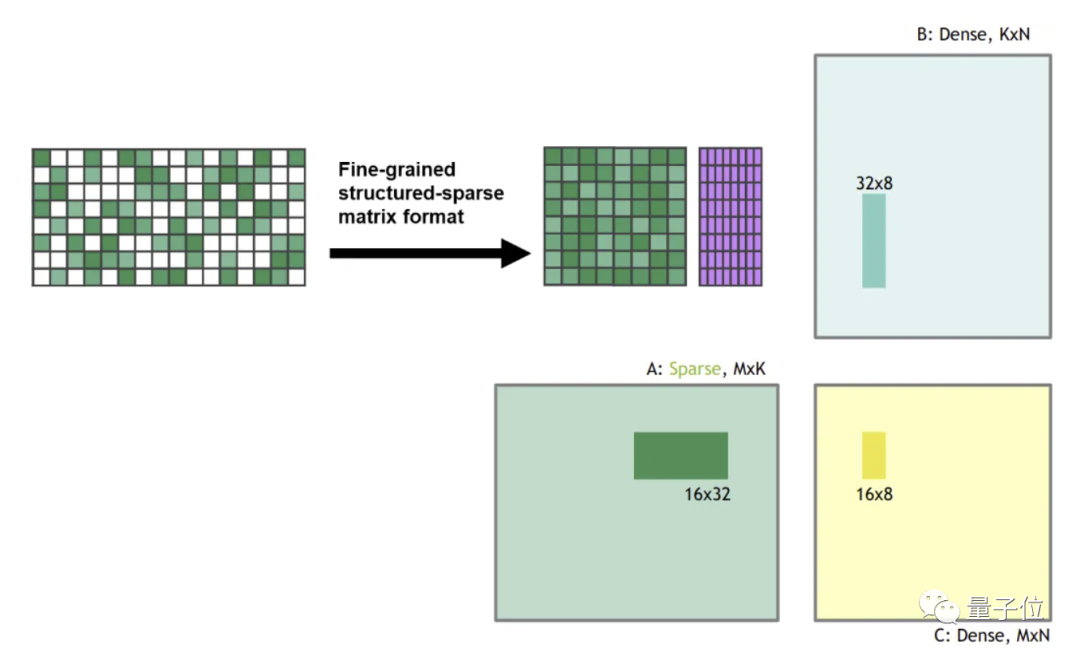 在压缩之后,密集压缩的“碎片”被送入Tensor Core,计算的矩阵乘法是一般大小的两倍。这样,运算速度就成了通常的2倍。Tim哥表示,上述性能点,他在统计英伟达GPU性能时都考虑在内了。如果你把这些东西吃透了话,以后就能完全靠自己配置出最合适的“炼丹炉”了。原文传送门:
在压缩之后,密集压缩的“碎片”被送入Tensor Core,计算的矩阵乘法是一般大小的两倍。这样,运算速度就成了通常的2倍。Tim哥表示,上述性能点,他在统计英伟达GPU性能时都考虑在内了。如果你把这些东西吃透了话,以后就能完全靠自己配置出最合适的“炼丹炉”了。原文传送门:
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我安装了ruby、yeoman,当我运行我的项目时,出现了这个错误:Warning:Running"compass:dist"(compass)taskWarning:YouneedtohaveRubyandCompassinstalledthistasktowork.Moreinfo:https://github.com/gruUse--forcetocontinue.Use--forcetocontinue.我有进入可变session目标的路径,但它不起作用。谁能帮帮我? 最佳答案 我必须运行这个:geminstallcom
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
我不是Ruby专家,但想弄清楚发生了什么,因为我试图让指南针在节点应用程序中工作,但我的Ruby似乎坏了。打字:ruby--version让我:ruby2.1.1p76(2014-02-24revision45161)[x86_64-darwin13.0]我安装了Homebrew,之前遇到过Ruby版本的问题,但它似乎已安装并且可以正常工作。但是,当我使用gem输入请求时,出现此错误:$gem-hErrorloadingRubyGemsplugin"/Users/user_dir/.rvm/gems/ruby-2.1.1@global/gems/executable-hooks-1.3
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
我正在尝试安装bootstrap-sass并收到以下错误。我试过旧版本的sass,但bundler一直在安装3.3.0。WARN:UnresolvedspecsduringGem::Specification.reset:sass(~>3.2)WARN:Clearingoutunresolvedspecs.Pleasereportabugifthiscausesproblems./Library/Ruby/Gems/2.0.0/gems/compass-0.12.2/lib/compass/sass_extensions/monkey_patches/browser_support.r
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动
自从2019年OpenApplicationModel诞生以来,KubeVela已经经历了几十个版本的变化,并向现代应用程序交付先进功能的方向不断发展。最近,KubeVela完成了向CNCF孵化项目的晋升,标志着社区的发展来到一个新的里程碑。今天,KubeVela社区内活跃着大量来自全球的开发者,共同推动KubeVela项目的落地和发展。在即将开幕的KubeCon+CloudNatvieConEurope2023上,我们惊喜地发现,连续3天,KubeVela项目的贡献者、企业用户和来自阿里云的核心维护者,将从不同角度展对KubeVela项目的分享。让我们先睹为快!🎙️BuildingaPlat
目录配置模拟模拟类型与实例期望录制-回放-验证指定调用计数验证指定自定义结果验证调用参数联级模拟部分模拟模拟未实现的类其他伪装伪装方法及类伪装未实现类本文主要内容如何在SpringBoot中配置使用JMockit如何mock/faking依赖的对象如何对行为mock如何VerificationJMockit之所以强大,是因其使用了javaagent对类的字节码做了修改,在JVM的所有mock工具中,它是功能最强大的。同时注解又是最少的。配置在SpringBoot项目中使用JMockit隔离代码做单元测试,需要做以下配置引入JMockit依赖。dependencies>dependency>gr