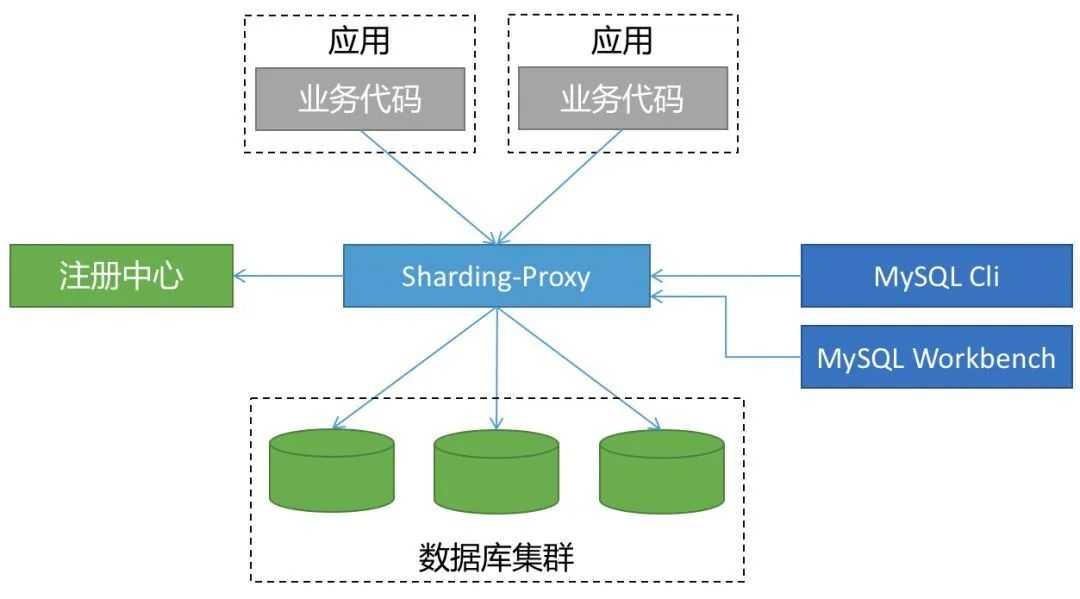
 代理层介于应用程序与数据库间,每次请求都需要做一次转发,请求会存在额外的时延。这种方式对于应用非常友好,应用基本零改动,和语言无关,可以通过连接共享减少连接数消耗。二、ShardingSphere-JDBCShardingSphere-JDBC 是 ShardingSphere 的第一个产品,也是 ShardingSphere 的前身, 我们经常简称之为:sharding-jdbc 。它定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
代理层介于应用程序与数据库间,每次请求都需要做一次转发,请求会存在额外的时延。这种方式对于应用非常友好,应用基本零改动,和语言无关,可以通过连接共享减少连接数消耗。二、ShardingSphere-JDBCShardingSphere-JDBC 是 ShardingSphere 的第一个产品,也是 ShardingSphere 的前身, 我们经常简称之为:sharding-jdbc 。它定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。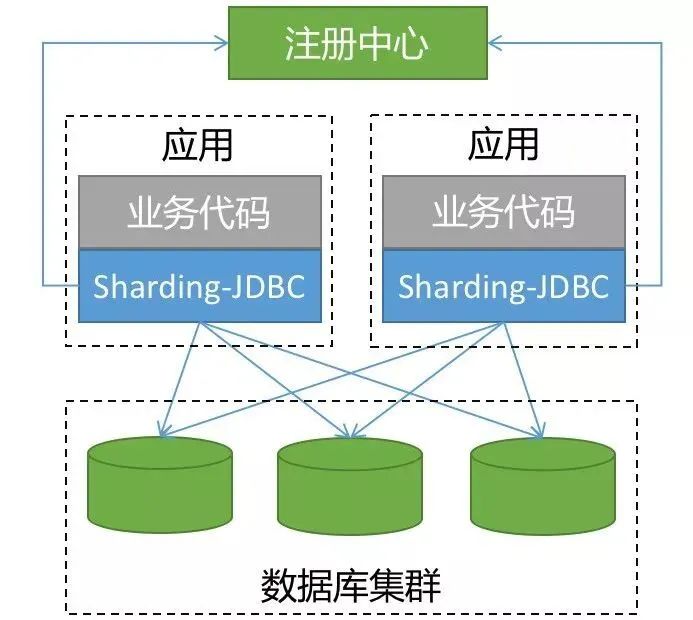
| JDBC | Proxy | |
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
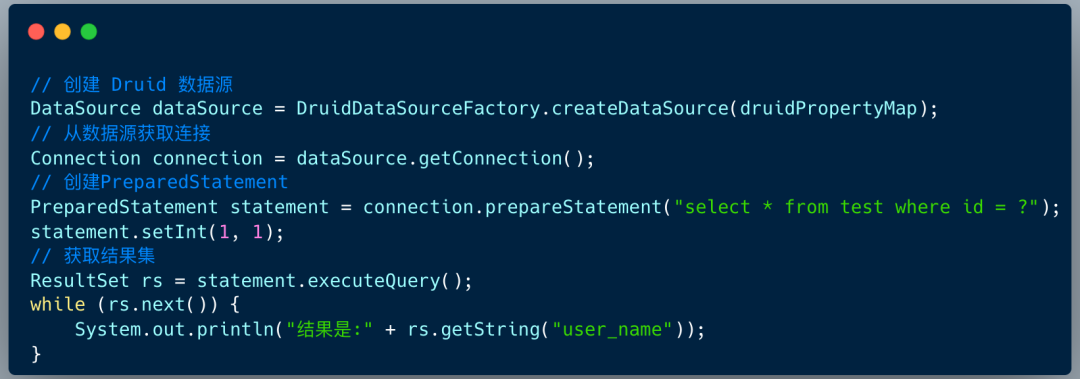 sharding-jdbc 的本质上就是实现 JDBC 的核心接口。
sharding-jdbc 的本质上就是实现 JDBC 的核心接口。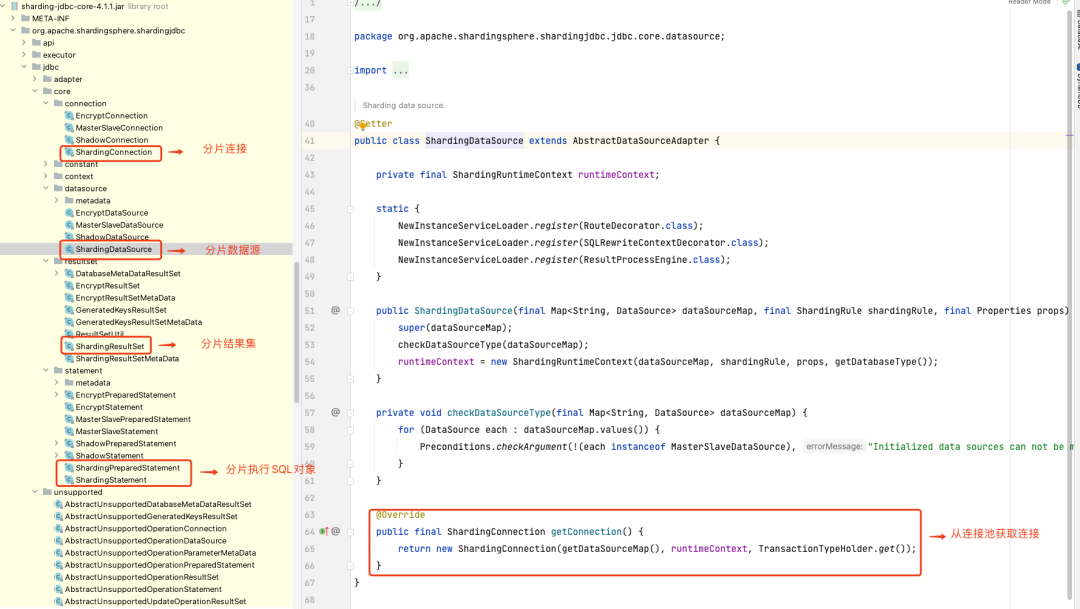
| 接口 | 实现类 |
| DataSource | ShardingDataSource |
| Connection | ShardingConnection |
| Statement | ShardingStatement |
| PreparedStatement | ShardingPreparedStatement |
| ResultSet | ShardingResultSet |
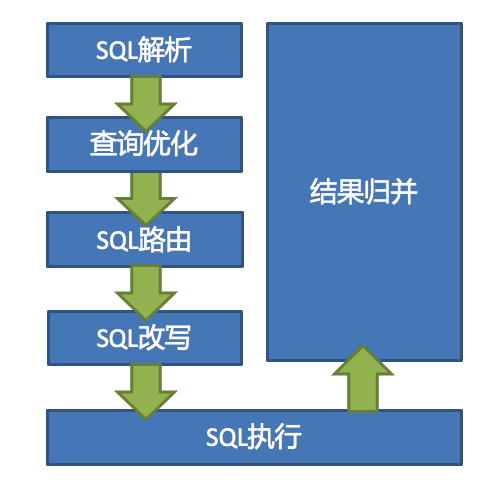 1.SQL 解析分为词法解析和语法解析。先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。2.执行器优化合并和优化分片条件,如 OR 等。3.SQL 路由根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。4.SQL 改写将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写。5.SQL 执行通过多线程执行器异步执行。6.结果归并将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
1.SQL 解析分为词法解析和语法解析。先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。2.执行器优化合并和优化分片条件,如 OR 等。3.SQL 路由根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。4.SQL 改写将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写。5.SQL 执行通过多线程执行器异步执行。6.结果归并将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。本文的重点在于实战层面, sharding-jdbc 的实现原理细节我们会在后续的文章一一给大家呈现 。
 然后 springboot 项目中配置依赖 :
然后 springboot 项目中配置依赖 :<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>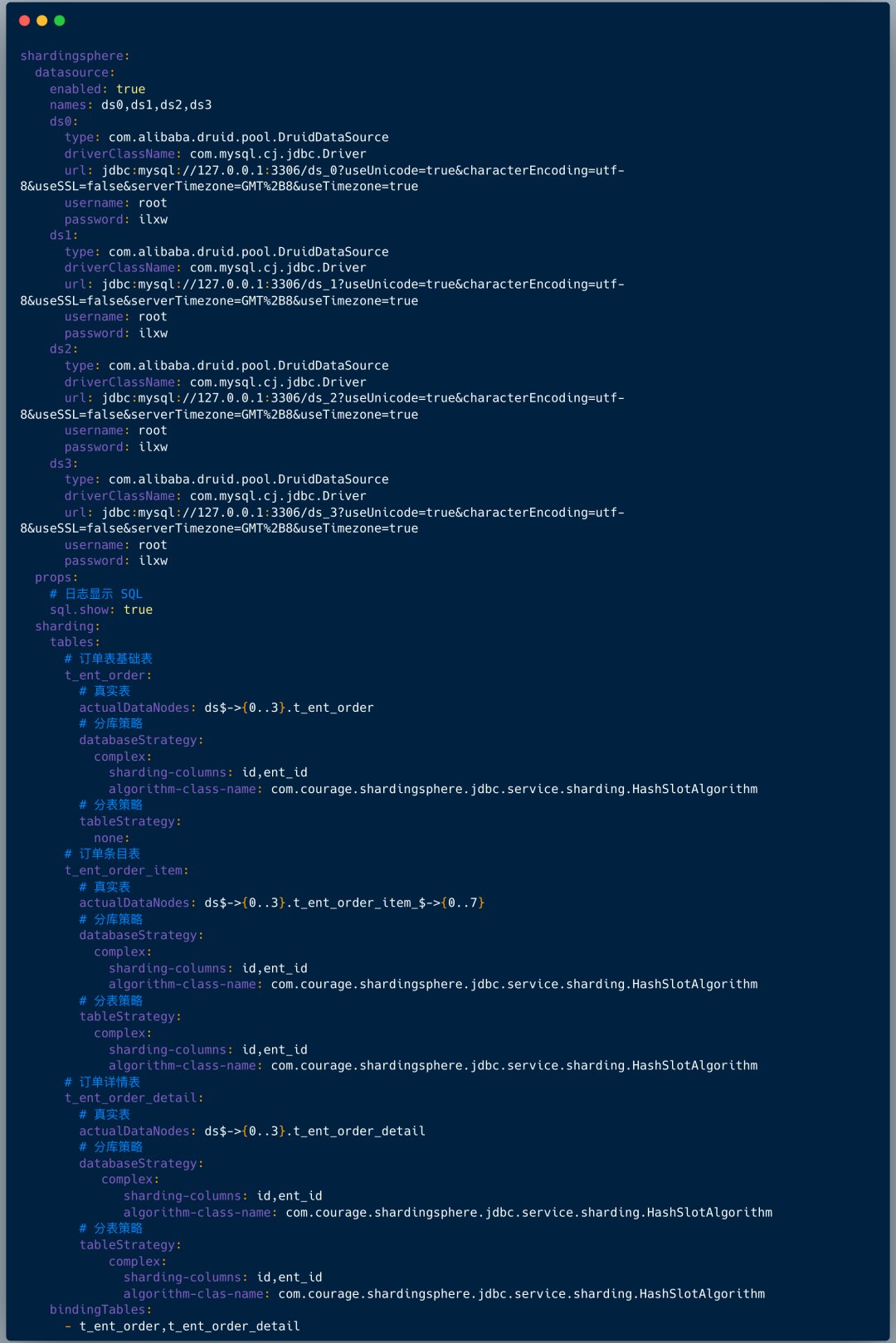
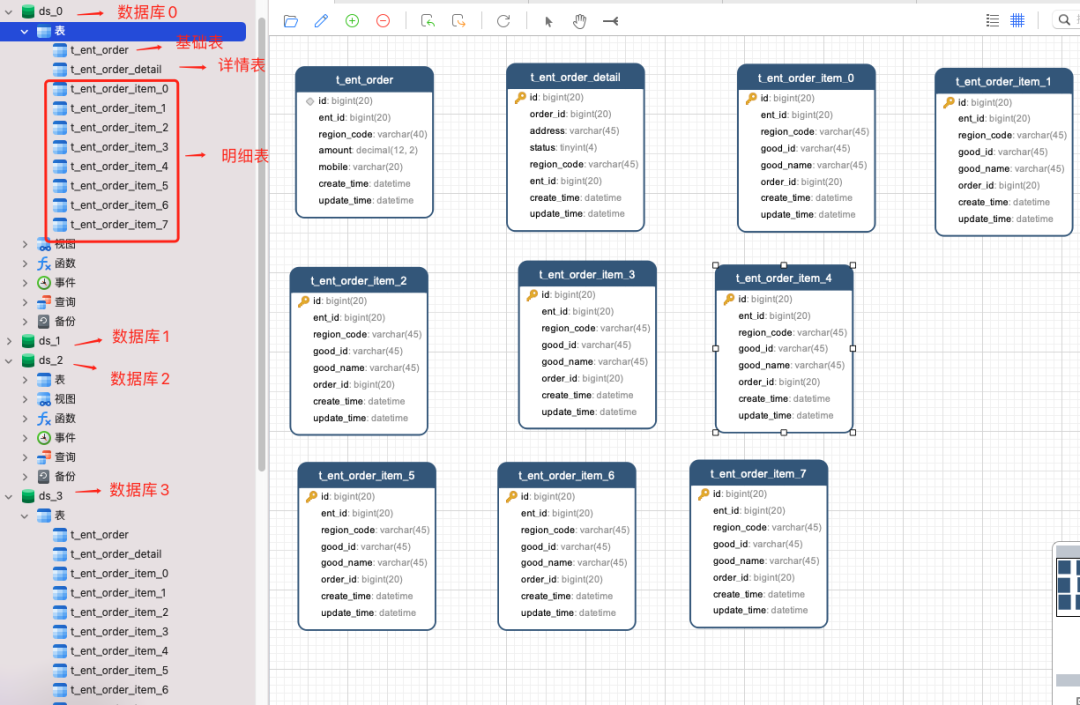
 上图中我们看到配置分片规则包含如下两点:1.真实节点对于我们的应用来讲,我们查询的逻辑表是:t_ent_order_item 。它们在数据库中的真实形态是:t_ent_order_item_0 到 t_ent_order_item_7。真实数据节点是指数据分片的最小单元,由数据源名称和数据表组成。订单明细表的真实节点是:ds$->{0..3}.t_ent_order_item_$->{0..7} 。2.分库分表算法配置分库策略和分表策略 , 每种策略都需要配置分片字段( sharding-columns )和分片算法。
上图中我们看到配置分片规则包含如下两点:1.真实节点对于我们的应用来讲,我们查询的逻辑表是:t_ent_order_item 。它们在数据库中的真实形态是:t_ent_order_item_0 到 t_ent_order_item_7。真实数据节点是指数据分片的最小单元,由数据源名称和数据表组成。订单明细表的真实节点是:ds$->{0..3}.t_ent_order_item_$->{0..7} 。2.分库分表算法配置分库策略和分表策略 , 每种策略都需要配置分片字段( sharding-columns )和分片算法。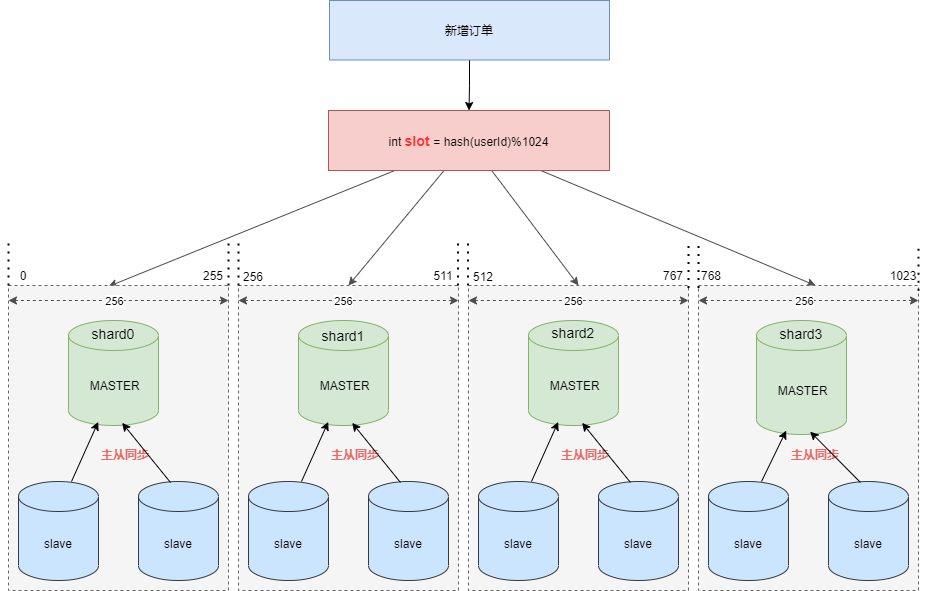 看起来分片算法很简单,但我们需要按照订单 ID 查询订单信息时依然需要路由四个分片,效率不高,那么如何优化呢 ?答案是:基因法 & 自定义复合分片算法。基因法是指在订单 ID 中携带企业用户编号信息,我们可以在创建订单 order_id 时使用雪花算法,然后将 slot 的值保存在 10位工作机器 ID 里。
看起来分片算法很简单,但我们需要按照订单 ID 查询订单信息时依然需要路由四个分片,效率不高,那么如何优化呢 ?答案是:基因法 & 自定义复合分片算法。基因法是指在订单 ID 中携带企业用户编号信息,我们可以在创建订单 order_id 时使用雪花算法,然后将 slot 的值保存在 10位工作机器 ID 里。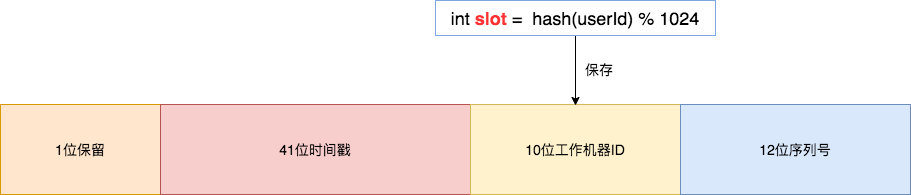 通过订单 order_id 可以反查出 slot , 就可以定位该用户的订单数据存储在哪个分片里。
通过订单 order_id 可以反查出 slot , 就可以定位该用户的订单数据存储在哪个分片里。Integer getWorkerId(Long orderId) {
Long workerId = (orderId >> 12) & 0x03ff;
return workerId.intValue();
} 解决了分布式 ID 问题,接下来的一个问题:sharding-jdbc 可否支持按照订单 ID ,企业用户 ID 两个字段来决定分片路由吗?答案是:自定义复合分片算法。我们只需要实现 ComplexKeysShardingAlgorithm 类即可。
解决了分布式 ID 问题,接下来的一个问题:sharding-jdbc 可否支持按照订单 ID ,企业用户 ID 两个字段来决定分片路由吗?答案是:自定义复合分片算法。我们只需要实现 ComplexKeysShardingAlgorithm 类即可。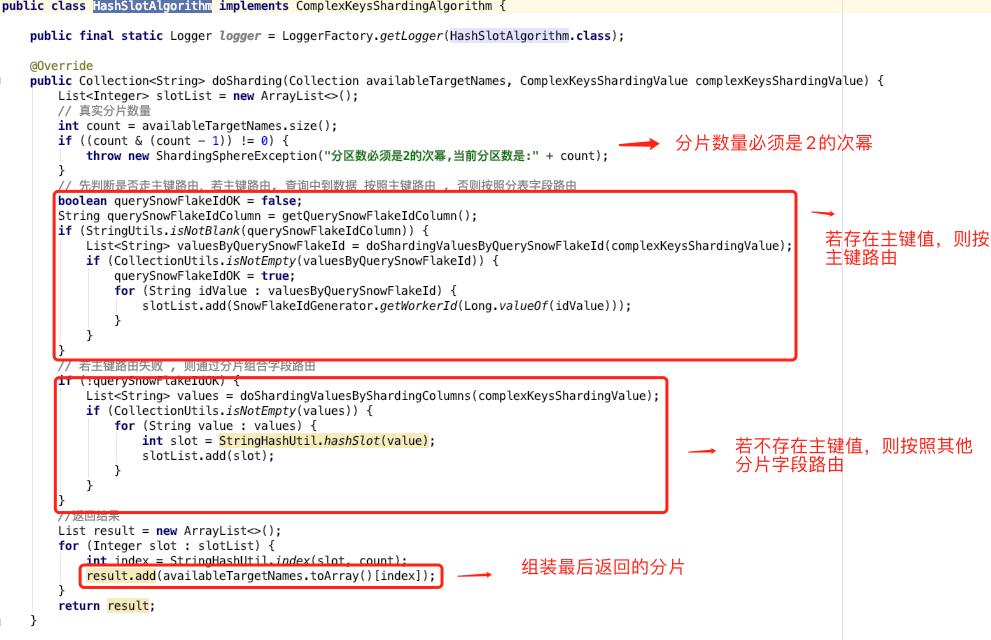 复合分片的算法流程非常简单:1.分片键中有主键值,则直接通过主键解析出路由分片;2.分片键中不存在主键值 ,则按照其他分片字段值解析出路由分片。
复合分片的算法流程非常简单:1.分片键中有主键值,则直接通过主键解析出路由分片;2.分片键中不存在主键值 ,则按照其他分片字段值解析出路由分片。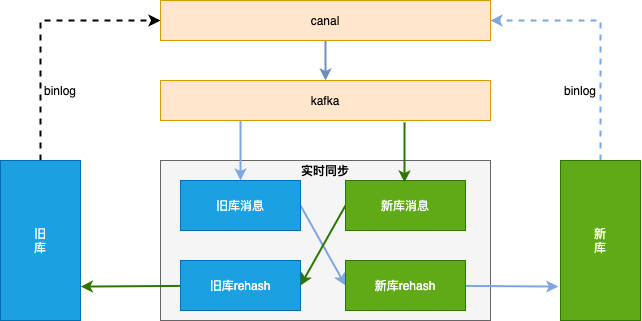 首先需要做历史数据全量同步:也就是将旧库迁移到新库。单独一个服务,使用游标的方式从旧库分片 select 语句,经过 rehash 后批量插入 (batch insert)到新库,需要配置jdbc 连接串参数 rewriteBatchedStatements=true 才能使批处理操作生效。因为历史数据也会存在不断的更新,如果先开启历史数据全量同步,则刚同步完成的数据有可能不是最新的。所以我们会先开启增量数据单向同步(从旧库到新库),此时只是开启积压 kafka 消息并不会真正消费;然后在开始历史数据全量同步,当历史全量数据同步完成后,在开启消费 kafka 消息进行增量数据同步(提高全量同步效率减少积压也是关键的一环),这样来保证迁移数据过程中的数据一致。增量数据同步考虑到灰度切流稳定性、容灾 和可回滚能力 ,采用实时双向同步方案,切流过程中一旦新库出现稳定性问题或者新库出现数据一致问题,可快速回滚切回旧库,保证数据库的稳定和数据可靠。增量数据实时同步的大体思路 :1.过滤循环消息需要过滤掉循环同步的 binlog 消息 ;2.数据合并同一条记录的多条操作只保留最后一条。为了提高性能,数据同步组件接到 kafka 消息后不会立刻进行数据流转,而是先存到本地阻塞队列,然后由本地定时任务每X秒将本地队列中的N条数据进行数据流转操作。此时N条数据有可能是对同一张表同一条记录的操作,所以此处只需要保留最后一条(类似于 redis aof 重写);3.update 转 insert数据合并时,如果数据中有 insert + update 只保留最后一条 update ,会执行失败,所以此处需要将 update 转为 insert 语句 ;4.按新表合并将最终要提交的 N 条数据,按照新表进行拆分合并,这样可以直接按照新表纬度进行数据库批量操作,提高插入效率。扩容方案文字来自 《256变4096:分库分表扩容如何实现平滑数据迁移》,笔者做了些许调整。
首先需要做历史数据全量同步:也就是将旧库迁移到新库。单独一个服务,使用游标的方式从旧库分片 select 语句,经过 rehash 后批量插入 (batch insert)到新库,需要配置jdbc 连接串参数 rewriteBatchedStatements=true 才能使批处理操作生效。因为历史数据也会存在不断的更新,如果先开启历史数据全量同步,则刚同步完成的数据有可能不是最新的。所以我们会先开启增量数据单向同步(从旧库到新库),此时只是开启积压 kafka 消息并不会真正消费;然后在开始历史数据全量同步,当历史全量数据同步完成后,在开启消费 kafka 消息进行增量数据同步(提高全量同步效率减少积压也是关键的一环),这样来保证迁移数据过程中的数据一致。增量数据同步考虑到灰度切流稳定性、容灾 和可回滚能力 ,采用实时双向同步方案,切流过程中一旦新库出现稳定性问题或者新库出现数据一致问题,可快速回滚切回旧库,保证数据库的稳定和数据可靠。增量数据实时同步的大体思路 :1.过滤循环消息需要过滤掉循环同步的 binlog 消息 ;2.数据合并同一条记录的多条操作只保留最后一条。为了提高性能,数据同步组件接到 kafka 消息后不会立刻进行数据流转,而是先存到本地阻塞队列,然后由本地定时任务每X秒将本地队列中的N条数据进行数据流转操作。此时N条数据有可能是对同一张表同一条记录的操作,所以此处只需要保留最后一条(类似于 redis aof 重写);3.update 转 insert数据合并时,如果数据中有 insert + update 只保留最后一条 update ,会执行失败,所以此处需要将 update 转为 insert 语句 ;4.按新表合并将最终要提交的 N 条数据,按照新表进行拆分合并,这样可以直接按照新表纬度进行数据库批量操作,提高插入效率。扩容方案文字来自 《256变4096:分库分表扩容如何实现平滑数据迁移》,笔者做了些许调整。@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
最近在工作中,看到一些新手测试同学,对接口测试存在很多疑问,甚至包括一些从事软件测试3,5年的同学,在聊到接口时,也是一知半解;今天借着这个机会,对接口测试做个实战教学,顺便总结一下经验,分享给大家。计划拆分成4个模块跟大家做一个分享,(接口测试、接口基础知识、接口自动化、接口进阶)感兴趣的小伙伴记得关注,希望对你的日常工作和求职面试,带来一些帮助。注:文章较长有5000多字,希望小伙伴们认真看完,当然有些内容对小白同学不是太友好,如果你需要详细了解其中的一些概念或者名词,请在文章之后留言,后续我将针对大家的疑问,整理输出一些大家感兴趣的文章。随着开发模式的迭代更新,前后端分离已不是新的概念,
1.什么是JDBC?Java数据库连接,(JavaDatabaseConnectivity,简称JDBC)是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法。JDBC也是SunMicrosystems的商标。我们通常说的JDBC是面向关系型数据库的。简而言之,JDBC就是JDK提供的关于数据库操作的一套接口规范,不同数据库厂商来负责实现这个接口,完成指定的操作。用程序和数据建立连接,分为三步骤:1.连接数据库2.执行SQL语句3.把查询到的结果集转换成JAVA对象2.对于MySQL的JDBC编程的前期准备工作知识拓展:JAR文件(Java归
目录FIFO一.自定义同步FIFO1.1代码设计1.2Testbech1.3行为仿真***学习位宽计算函数$clog2()***$clog2()系统函数使用,可以不关注***分布式资源或者BLOCKBRAM二.异步FIFO2.1在FIFO判满的时候有两种方式:2.2异步FIFO为什么要使用格雷码2.2.1介绍格雷码2.2.2格雷码在异步FIFO中的应用2.2.2格雷码判满2.4二进制与格雷码之间的转换2.4.1二进制码转换为格雷码的方法2.4.2格雷码转换为二进制码的方法2.3实现框图2.5实现及仿真代码2.6仿真图验证2.7结论FIFO 这篇更多的是记录FIFO学习,参考了众多优秀的文章,
运行有问题或需要源码请点赞关注收藏后评论区留言一、利用ContentResolver读写联系人在实际开发中,普通App很少会开放数据接口给其他应用访问。内容组件能够派上用场的情况往往是App想要访问系统应用的通讯数据,比如查看联系人,短信,通话记录等等,以及对这些通讯数据及逆行增删改查。首先要给AndroidMaifest.xml中添加响应的权限配置 下面是往手机通讯录添加联系人信息的例子效果如下分成三个步骤先查出联系人的基本信息,然后查询联系人号码,再查询联系人邮箱代码 ContactAddActivity类packagecom.example.chapter07;importandroid
📝学技术、更要掌握学习的方法,一起学习,让进步发生👩🏻作者:一只IT攻城狮。💐学习建议:1、养成习惯,学习java的任何一个技术,都可以先去官网先看看,更准确、更专业。💐学习建议:2、然后记住每个技术最关键的特性(通常一句话或者几个字),从主线入手,由浅入深学习。❤️《SpringCloud入门实战系列》解锁SpringCloud主流组件入门应用及关键特性。带你了解SpringCloud主流组件,是如何一战解决微服务诸多难题的。项目demo:源码地址👉🏻SpringCloud入门实战系列不迷路👈🏻:SpringCloud入门实战(一)什么是SpringCloud?SpringCloud入门实战
目录1.数据库编程:JDBC2.JDBC工作原理3.JDBC使用3.1驱动包的下载与导入3.2JDBC使用步骤(插入)4.JDBC修改删除查询1.将数据库驱动包,添加到项目依赖中创建目录,拷贝jar包,然后addaslibrary2.创建数据源DataSourse:数据源,描述了数据库服务器在哪里3.和数据库建立连接使用JDBC里的Connection将代码和数据库服务器进行连接一个程序中,通常有一个数据源对象,可以有多个Connection对象4.构造sql语句PreparedStatement:表示一个预处理过的SQL语句对象5.执行sql语句(1)executeUpdate对应插入到删除
快捷目录前言一、涉及到的相关技术简介二、具体实现过程及踩坑杂谈1.安卓手机改造成linux系统实现方案2.改造后的手机Linux中软件的安装3.手机Linux中安装MySQL5.7踩坑实录4.手机Linux中安装软件的正确方法三、Linux服务器部署前后端分离项目流程1.前提准备(安装必要软件,搭建环境):2.前后端分离项目的详细部署过程:总结前言总体概述:本篇文章隶属于“手机改造服务器部署前后端分离项目”系列专栏,该专栏将分多个板块,每个板块独立成篇来详细记录:手机(安卓)改造成个人服务器(Linux)、Linux中安装软件、配置开发环境、部署JAVA+VUE+MySQL5.7前后端分离项目
【保姆级】Python最新版开发环境搭建,看这一篇就够了(适用于Python3.11.2安装)文章目录【保姆级】Python最新版开发环境搭建,看这一篇就够了(适用于Python3.11.2安装)一、Python解释器安装Windows安装步骤环境变量配置(非必要)MacOS安装步骤Linux安装步骤二、PyCharm安装三、创建Python工程工欲善其事必先利其器,在使用Python开发程序之前,在计算机上搭建Python开发环境是必不可少的环节,目前Python最新稳定版本是3.11.1,且支持到2027年,如下图所示本文手把手带你从0到1搭建Python最新版3.11.1开发环境,堪称保
1、接口的概念系统与系统之间,组件与组件之间,数据传递交互的通道2、接口的类型按协议划分:http、tcp、IP按语言划分:C++、java、PHP……按范围划分:系统之间多个内部系统之间内部系统与外部系统之间程序之间方法与方法之间、函数与函数之间、模块与模块之间3、接口测试的概念对系统或组件之间的接口进行测试,校验传递的数据正确性和逻辑依赖关系的正确行。4、接口测试的原理主要针对服务器,模拟客户端向服务器发送请求,通过工具或者代码来测试服务器针对客户端请求回发的响应数据是否与预期结果一致。5、接口测试的特点符合质量控制前移的理念可以发现一些页面操作发现不了的问题接口测试低成本高效益接口测试是