注意目标:通信效率、数据异构性、隐私保护性
服务器和客户机之间的通信必要的,但是会带来大量的传递数据,更新轮数、数据压缩。
数据异构性:非i.i.d.数据,客户的训练样本来自不同的分布。
本地计算 ,客户机会有计算能力的限制;这种计算的不公平有可能导致结果模型的不公平
分层系统很复杂,客户机会掉线、离开、突然加入。
通信信道必须纳入考虑,带宽的限制,通信噪声和不稳定性,
B.1介绍了三种FL算法:FedAVG,FedAVGM,FedADAM 35页也有对比,并在4中具体描述的算法的测试情况
4.2介绍的建议很有帮助
本文还需要多看几遍,包含了很多FL的知识。
重点体会其分层的思想
云服务器-设备模式和边缘服务器-设备模式各有优缺点,CEC正是将其结合起来,但是同时带来一些问题:收敛性证明、聚合频率的选取、本地更新的延迟和功耗之间的平衡。
本文给出的:收敛证明+两级聚合频率选取的定性准则
云-设备和边缘-设备都被看做两层FL模型,FAVG算法;CEC看作三层模型,用HierFAVG算法
问题为监督学习。训练数据 D = { x j , y j } j = 1 ∣ D ∣ \mathcal{D}=\{\textbf{x}_j,y_j\}^{|\mathcal{D}|}_{j=1} D={xj,yj}j=1∣D∣, ∣ D ∣ |\mathcal{D}| ∣D∣是数据样本的总数, x j \textbf{x}_j xj是第j个输入样本,yi是对应的标签, ω \omega ω是ML模型的全部参数的实向量。 f j ( ω ) f_j(\omega) fj(ω)是第j个数据样本的损失函数,优化目标:

损失函数F(w)取决于ML模型,可以是凸的,如logistic回归,或非凸的,如神经网络。这个F(w)因为数据分散的原因,没法直接得到全局的损失的,只能加权每个设备的来估计。
∪ i = 1 N D i = D \cup^N_{i=1}\mathcal{D}_i=\mathcal{D} ∪i=1NDi=D中的U是取并集的意思
L个边缘服务器标记为 l l l,互不连接的客户端 { C l } l = 1 L {\{\mathcal{C}^l}\}^L_{l=1} {Cl}l=1L,N个用户,有分布式的数据集 { D l } l = 1 L {\{\mathcal{D}^l}\}^L_{l=1} {Dl}l=1L,边缘 l l l负责从其客户端聚合数据集 D l D^l Dl。 k k k为第k次的梯度更新,用户每过k1次,更新下边缘;边缘每更新k2次,更新云端。 ω i l ( k ) \omega^l_i(k) ωil(k)是本地更新了k次之后的本地模型参数。
其实整个CEC的模型没有做太多事情,只是把原本的二层模型转换为三层模型
在上文CEC的 基础上改进
数据的异构性,设备的移动性,导致原来的算法效率低下。
全局平均的模型不能很好的适配每一个用户。
本文假设了移动用户在基站之间的移动为马尔可夫的转移矩阵来描述移动性。(最简单的对移动性的考虑了)
面对移动性,到另一个簇就上传,会破坏异构性,因此需要更谨慎的加权,减少查差异性影响和SGD方差
学习其数学模型!
分层聚合:垂直来看
分簇:相同层之间D2D聚合,但仍是一个集群内

大规模降低能耗(只需要顶部节点上传),减少网络负载(每一层进行了降维)。
适应移动性:快速接入集群(复制模型参数)、退出时传输学习结果到本地对等方、利用上一层进行广播减少局部偏差
D2D延时代价高,需要权衡哪些设备集群适合D2D
抑制误差噪声的累计放大,加快收敛
基于块的学习:位于网络不同层的设备可以形成不同的学习块,在垂直更新之间,他们可以进行多轮块内学习本地更新。研究不同学习块的聚合频率、块内节点的计算能力、模型精度和训练收敛速度之间的权衡是一个开放的方向
DRL在这样的问题下很有前景

这一段给出了计算耗时的模型:max{本地计算,边缘计算+传输延时}
在我们的模型中,每个用户的能量消耗由三部分组成:a)设备操作,b)数据传输和c)数据计算。
接下来,我们提出了我们的优化问题,其目标是最小化每个用户的能量和时间消耗的加权和。该最小化问题涉及根据以下公式确定用户关联、服务序列和必须传输到HAB的数据的大小
任务是用户产生的,由于每个n只能收集和该任务有关的用户的信息而不是全体,传统的迭代器难以达到全局优化,需要机器学习来预测连接,从而n可以选择和任务量相同的用户连接
a) agents, b) input, c) output, d) SVM model
算法输入: X m n X_{mn} Xmn,m的历史时刻上的连接和任务大小
算法输出:HAB n为预测用户m在时刻k的未来关联而执行的所提出的算法的输出是 a m n , k + 1 a_{mn,k+1} amn,k+1,它表示HAB n和用户m在时刻k1的用户关联。
SVM模型:每个基站m,我们定义一个SVM模型由向量 ω m n \omega_{mn} ωmn和矩阵 Ω m ∈ R N × N \Omega_m\in\mathbb{R}^{N\times N} Ωm∈RN×N表示, ω m n \omega_{mn} ωmn是用来近似输入 x m , k x_{m,k} xm,k和输出 a m n , k + 1 a_{mn,k+1} amn,k+1之间的预测函数,从而建立未来用户关联和用户m当前需要处理的任务的数据大小之间的关系。 Ω m \Omega_m Ωm是用来度量由基站n生成的SVM模型和由其它基站生成的SVM模型之间的差异。事实上,优化 Ω m \Omega_m Ωm能够提升n的本地SVM模型预测效果。
先利用和自己相关的连接的过往任务分配训练 W m W_m Wm,然后只把SVM模型 ω m \omega_m ωm发给别的,别的基站就能根据模型生成 W m W_m Wm,然后用这些 W m W_m Wm训练 Ω m \Omega_m Ωm
用户连接确定后,优化服务序列和任务分配。每个基站是独立决定这样优化分配的。上述两个问题是独立的可以分成两个子问题。
每个边缘设备定制模型。。。应对异构数据分布。。。
N个设备,一个中心,每一个设备都有一个特定的任务。第k个用户有nk个训练数据表示为 S k = { ( x k 1 , y k 1 ) , ( x k 2 , y k 2 ) , … , ( x k n k , y k n k ) } S_k=\{(\textbf{x}_{k1},y_{k1}),(\textbf{x}_{k2},y_{k2}),\dots,(\textbf{x}_{kn_k},y_{kn_k})\} Sk={(xk1,yk1),(xk2,yk2),…,(xknk,yknk)},
此外,假设跨设备的数据是独立的,但不一定是同分布。而且不能传递原始数据,因此考虑的学习规则是 h ω k : X → Y , k = 1 , 2 , 3 h_{\omega k}:\mathcal{X}\rightarrow \mathcal{Y}, k=1,2,3 hωk:X→Y,k=1,2,3 , L k ( ω ) \mathcal{L}_k(\omega) Lk(ω)是损失函数!
在经典的联邦设置中,目标是解决以下优化问题,即在所有设备上找到一个神经网络 ω ∈ R d \omega\in\mathbb{R}^{d} ω∈Rd

这个 Φ \Phi Φ就是所有设备上面的网络模型的损失函数的和!!!要优化的全局的损失
n为样本总数 ∑ k = 1 N n k \sum^N_{k=1}n_k ∑k=1Nnk,需要注意的是,在实践中,上述问题的解可以通过SGD算法中Lk(w)的梯度估计得到。FL的挑战在于,总体梯度是单个平均损失梯度的总和。解决方案,比如FedAvg[9],1bit基于梯度的多数投票[17],和更多的人提出了文献[16]在于 系数nk / n将决定相应用户的损失函数的重要性k。然而,如果将来从用户k采样的数量减少,然后,通过解决上述问题返回的模型可能会导致多个设备的性能较差。解决上述问题的一个方法是看看最坏的情况,如下[3]所述:

因为相关数据的分布问题,很可能训练第k设备的损失函数的时候不只依赖自己的数据,因此需要将全局学习到的损失进行加权综合,但又不是简单的平均

一言以蔽之,我们在对不同的设备生成的损失进行适当加权,要求最后和(2)中的优化目标尽可能接近
该通信模型由单个BS单输入单输出(SISO)系统和多个用户或边缘设备组成。特别地,假设时间是时隙的,并且假设任何设备k和BS之间的信道是一个无线瑞利平坦衰落信道。对于输入xk(t)∈C,设备k在BS处**接收到的复基带信号y(t)**∈C为

其中 (i.i.d.为独立同分布)为设备k与BS之间的衰落信道系数。噪声
(i.i.d.为独立同分布)为设备k与BS之间的衰落信道系数。噪声
为圆对称复高斯随机变量。通常,这些设备是移动电话,因此功率有限。因此,设备k处的功率约束为
E
∣
x
k
(
t
)
∣
2
≤
P
k
\mathbb{E}|x_k(t)|^2\le P_k
E∣xk(t)∣2≤Pk。==(E代表均值吗)==另一方面,BS被假定有足够的能力进行通信而不会出现任何错误。这个假设是为了简单和易于解释。在任何给定的时隙,都假定调度程序将带宽B的信道分配给希望通信的任何边缘设备。例如,在OFDMA系统中,一个资源块被分配给希望传输的用户。为简单起见,本文忽略了调度方案对算法收敛性的影响。
值得注意的是,为了解决(7),需要了解差异。然而,设备可以访问数据,因此需要以分布式的方式估计差异。这个估计值将被用作(7)中设计联邦算法的代理。在接下来的小节中,提出了一种估计误差的算法。
从差异的定义来看,DDE算法相当于求解 sup ω ∈ R d ∣ L k ( ω ) − L j ( ω ) ∣ \sup_{\omega\in\mathbb{R}^d}|\mathcal{L}_k(\omega)-\mathcal{L}_j(\omega)| supω∈Rd∣Lk(ω)−Lj(ω)∣,(对所有的k,j)。由于差异定义式的真实均值未知,因此这两项可以被估计为 L ^ k ( ω , S k ) 和 L ^ k ( ω , S j ) \hat{\mathcal{L}}_k(\omega,S_k)和\hat{\mathcal{L}}_k(\omega,S_j) L^k(ω,Sk)和L^k(ω,Sj),解决这一问题的一种自然方法是采用分布式的梯度上升算法。利用差异估计,开发了一种分布式联邦学习算法。
本文的重点是表明,在保持通信复杂度为标称值的情况下,使用差异估计可以提高联邦算法的性能。
在解决(7)中的问题时,DDE算法得到的差异估计可以作为真实差异的代理。可以使用经典的联邦算法来解决这个问题。然而,这需要交换梯度,这在许多问题中可能是非常高的维度,导致通信瓶颈。因此,在本节中,我们提出了一种不同于[17]的带符号梯度法。虽然在这种情况下可以使用量化梯度的一般方法,但为了简单起见,将使用一个简单的带符号梯度,并将量化梯度的分析降级到未来的工作。
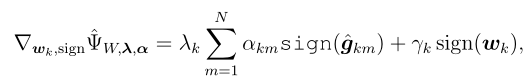
==!!!!==具体来说,每个设备m发送带符号的梯度sign(gkm) 和损失
L
^
(
ω
k
,
S
m
)
\hat{\mathcal{L}}(\omega_k,S_m)
L^(ωk,Sm)给BS,BS根据(9)和(10)汇总这些,得到估计的梯度
。这些估计用于获得最优权值wk和重要性系数αkj的改进估计给每个设备k。为了满足约束
∑
j
=
1
N
α
k
j
=
1
\sum^N_{j=1}\alpha_{kj}=1
∑j=1Nαkj=1。注意,(7)相对于α的梯度依赖于估计的差异。计算这个梯度很简单,因此在算法中没有明确提到。
联邦学习架构,目前看到的,有分层(CEC),部分讲了分簇(MACFL),有的考虑了通信信道(气球那个)和移动性(MACFL),但是,对于D2D网络似乎还没有提到,D2D通信对于本地模型的聚合应该有很大帮助。
非i.i.d.数据、异构数据;用户移动性;通信不稳定和噪声;都是FL的一些约束问题,上文基本上注重其中某几点。
异构环境:全局的模型不能很好的适配每一个用户(MINIST分数字学习很有意思)
对本地client的数据,能否有选择性的进行采集?抛弃一部分?动态权重?
怎么和D2D结合发挥最大性优势。
由移动性启发,一个簇不一定是一成不变的,层是不是也可以呢?更灵活的结果。
FL不只是纯机器学习计算中的问题,还应该和网络架构、通信策略等结合起来,综合为FL服务。
效率、能耗、时延、收敛性,成为不可忽略的问题。
。。。
1.怎么
运行bundleinstall后出现此错误:Gem::Package::FormatError:nometadatafoundin/Users/jeanosorio/.rvm/gems/ruby-1.9.3-p286/cache/libv8-3.11.8.13-x86_64-darwin-12.gemAnerroroccurredwhileinstallinglibv8(3.11.8.13),andBundlercannotcontinue.Makesurethat`geminstalllibv8-v'3.11.8.13'`succeedsbeforebundling.我试试gemin
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我正在运行Ubuntu11.10并像这样安装Ruby1.9:$sudoapt-getinstallruby1.9rubygems一切都运行良好,但ri似乎有空文档。ri告诉我文档是空的,我必须安装它们。我执行此操作是因为我读到它会有所帮助:$rdoc--all--ri现在,当我尝试打开任何文档时:$riArrayNothingknownaboutArray我搜索的其他所有内容都是一样的。 最佳答案 这个呢?apt-getinstallri1.8编辑或者试试这个:(非rvm)geminstallrdocrdoc-datardoc-da
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
我正在使用PostgreSQL9.1.3(x86_64-pc-linux-gnu上的PostgreSQL9.1.3,由gcc-4.6.real(Ubuntu/Linaro4.6.1-9ubuntu3)4.6.1,64位编译)和在ubuntu11.10上运行3.2.2或3.2.1。现在,我可以使用以下命令连接PostgreSQLsupostgres输入密码我可以看到postgres=#我将以下详细信息放在我的config/database.yml中并执行“railsdb”,它工作正常。开发:adapter:postgresqlencoding:utf8reconnect:falsedat
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG