源码基于:Android R
其实,很久以前在 android 查看内存使用情况 一文中已经分析过dumpsys meminfo,但最近在统计内存数据的时候发现怎么也对不上,所以重新分析了下源码,之前在 android 查看内存使用情况 一文只是讲了个大概框架或含义。本篇博文会结合代码详细分析下AMS 下meminfo service 以及dump 的过程。
AMS 下的meminfo 统计是通过dumpsys 命令进行dump 的,这个是存放在 /system/bin/下的bin 文件。源码目录位于 frameworks/native/cmds/dumpsys/下,详细的请查看 android 中的dumpsys 一文。
可以dump的这些service都是在ServiceManager里面添加上的,例如meminfo是在:frameworks/base/services/java/com/android/server/am/ActivityManagerService.java的函数setSystemProcess添加的:
frameworks/base/services/core/java/com/android/server/am/AMS.java
public void setSystemProcess() {
try {
...
ServiceManager.addService("meminfo", new MemBinder(this), /* allowIsolated= */ false,
DUMP_FLAG_PRIORITY_HIGH);
...
}注意:
通过 android 中的dumpsys 一文的step7,我们得知,如果某service(例如,meminfo) 需要通过dumpsys 命令进行dump 操作,必要将指定dump flag。这里meminfo 在addService 的时候指定了dump flag 为 DUMP_FLAG_PRIORITY_HIGH。
下面来看下:
frameworks/base/services/core/java/com/android/server/am/AMS.java
static class MemBinder extends Binder {
ActivityManagerService mActivityManagerService;
private final PriorityDump.PriorityDumper mPriorityDumper =
new PriorityDump.PriorityDumper() {
@Override
public void dumpHigh(FileDescriptor fd, PrintWriter pw, String[] args,
boolean asProto) {
dump(fd, pw, new String[] {"-a"}, asProto);
}
@Override
public void dump(FileDescriptor fd, PrintWriter pw, String[] args, boolean asProto) {
mActivityManagerService.dumpApplicationMemoryUsage(
fd, pw, " ", args, false, null, asProto);
}
};
MemBinder(ActivityManagerService activityManagerService) {
mActivityManagerService = activityManagerService;
}
@Override
protected void dump(FileDescriptor fd, PrintWriter pw, String[] args) {
try {
mActivityManagerService.mOomAdjuster.mCachedAppOptimizer.enableFreezer(false);
if (!DumpUtils.checkDumpAndUsageStatsPermission(mActivityManagerService.mContext,
"meminfo", pw)) return;
PriorityDump.dump(mPriorityDumper, fd, pw, args);
} finally {
mActivityManagerService.mOomAdjuster.mCachedAppOptimizer.enableFreezer(true);
}
}
}里面定义了两个成员变量:
真正实现的地方是在AMS 的dumpApplicationMemoryUsage() 中。
进入dumpApplicationMemoryUsage() 之后,会看到一个while 循环用来分析dumpsys meminfo 附带的参数,这里首先来看下 -h,通过此参数进一步了解 dumpsys meminfo 的其他参数选项。
代码这里就不贴了,直接来看下终端的输出:
meminfo dump options: [-a] [-d] [-c] [-s] [--oom] [process]
-a: include all available information for each process.
-d: include dalvik details.
-c: dump in a compact machine-parseable representation.
-s: dump only summary of application memory usage.
-S: dump also SwapPss.
--oom: only show processes organized by oom adj.
--local: only collect details locally, don't call process.
--package: interpret process arg as package, dumping all
processes that have loaded that package.
--checkin: dump data for a checkin
--proto: dump data to proto
If [process] is specified it can be the name or
pid of a specific process to dump.
当dumpsys meminfo 的命令行参数解析完之后,会调用collectProcesses() 来确认符合命令的packages 或pid:
frameworks/base/services/core/java/com/android/server/am/ProcessList.java
ArrayList<ProcessRecord> collectProcessesLocked(int start, boolean allPkgs, String[] args) {
ArrayList<ProcessRecord> procs;
if (args != null && args.length > start
&& args[start].charAt(0) != '-') {
procs = new ArrayList<ProcessRecord>();
int pid = -1;
try {
pid = Integer.parseInt(args[start]);
} catch (NumberFormatException e) {
}
for (int i = mLruProcesses.size() - 1; i >= 0; i--) {
ProcessRecord proc = mLruProcesses.get(i);
if (proc.pid > 0 && proc.pid == pid) {
procs.add(proc);
} else if (allPkgs && proc.pkgList != null
&& proc.pkgList.containsKey(args[start])) {
procs.add(proc);
} else if (proc.processName.equals(args[start])) {
procs.add(proc);
}
}
if (procs.size() <= 0) {
return null;
}
} else {
procs = new ArrayList<ProcessRecord>(mLruProcesses);
}
return procs;
}代码还是比较清晰的:
注意,前两点有可能收集的 proc 为空,因为设定的参数有可能是假的或者无法匹配。
这个时候终端上还提示No process:
shift:/ # dumpsys meminfo 12345
No process found for: 12345
这个函数的代码量太大,这里抽重点的地方剖析下。
frameworks/base/services/core/java/com/android/server/am/AMS.java
private final void dumpApplicationMemoryUsage() {
...
for (int i = numProcs - 1; i >= 0; i--) {
final ProcessRecord r = procs.get(i);
final IApplicationThread thread;
final int pid;
final int oomAdj;
final boolean hasActivities;
synchronized (this) {
thread = r.thread;
pid = r.pid;
oomAdj = r.getSetAdjWithServices();
hasActivities = r.hasActivities();
}
if (thread != null) {
if (mi == null) {
mi = new Debug.MemoryInfo();
}在最开始的时候需要注意几个重点的初始化:
源码目录:frameworks/base/core/java/android/os/Debug.java
这里提供了很多的native 接口:
public static native long getNativeHeapSize();
public static native long getNativeHeapAllocatedSize();
public static native long getNativeHeapFreeSize();
public static native void getMemoryInfo(MemoryInfo memoryInfo);
public static native boolean getMemoryInfo(int pid, MemoryInfo memoryInfo);
public static native long getPss();
public static native long getPss(int pid, long[] outUssSwapPssRss, long[] outMemtrack);
接着第 5.1 节的代码继续往下看:
if (opts.dumpDetails || (!brief && !opts.oomOnly)) {
reportType = ProcessStats.ADD_PSS_EXTERNAL_SLOW;
startTime = SystemClock.currentThreadTimeMillis();
if (!Debug.getMemoryInfo(pid, mi)) {
continue;
}
endTime = SystemClock.currentThreadTimeMillis();
hasSwapPss = mi.hasSwappedOutPss;
} else {
reportType = ProcessStats.ADD_PSS_EXTERNAL;
startTime = SystemClock.currentThreadTimeMillis();
long pss = Debug.getPss(pid, tmpLong, null);
if (pss == 0) {
continue;
}
mi.dalvikPss = (int) pss;
endTime = SystemClock.currentThreadTimeMillis();
mi.dalvikPrivateDirty = (int) tmpLong[0];
mi.dalvikRss = (int) tmpLong[2];
}在没有指定 --oom 时,代码都是会走 if 的case,会通过Debug.getMemoryInfo() 获取进程的详细内存信息:
frameworks/base/core/jni/android_os_Debug.cpp
static jboolean android_os_Debug_getDirtyPagesPid(JNIEnv *env, jobject clazz,
jint pid, jobject object)
{
bool foundSwapPss;
stats_t stats[_NUM_HEAP];
memset(&stats, 0, sizeof(stats));
if (!load_maps(pid, stats, &foundSwapPss)) {
return JNI_FALSE;
}
struct graphics_memory_pss graphics_mem;
if (read_memtrack_memory(pid, &graphics_mem) == 0) {
stats[HEAP_GRAPHICS].pss = graphics_mem.graphics;
...
}
for (int i=_NUM_CORE_HEAP; i<_NUM_EXCLUSIVE_HEAP; i++) {
stats[HEAP_UNKNOWN].pss += stats[i].pss;
...
}
for (int i=0; i<_NUM_CORE_HEAP; i++) {
env->SetIntField(object, stat_fields[i].pss_field, stats[i].pss);
...
}
env->SetBooleanField(object, hasSwappedOutPss_field, foundSwapPss);
...
for (int i=_NUM_CORE_HEAP; i<_NUM_HEAP; i++) {
...
}
env->ReleasePrimitiveArrayCritical(otherIntArray, otherArray, 0);
return JNI_TRUE;
}
static bool load_maps(int pid, stats_t* stats, bool* foundSwapPss)
{
*foundSwapPss = false;
uint64_t prev_end = 0;
int prev_heap = HEAP_UNKNOWN;
std::string smaps_path = base::StringPrintf("/proc/%d/smaps", pid);
auto vma_scan = [&](const meminfo::Vma& vma) {
...
};
return meminfo::ForEachVmaFromFile(smaps_path, vma_scan);
}meminfo::ForEachVmaFromFile() 是 libmeminfo.so 接口,代码位于 /system/memory/libmeminfo/下。
这里总结一个调用框架图:

主要是读取进程 smaps 节点,根据属性的不同,进程的虚拟地址空间会被划分成若干个 VMA,每个VMA 通过vm_next 和vm_prev 组成双向链表,链表位于进程的 task_struct->mm_struct->mmap 中。当通过proc接口读取进程的smaps文件时,内核会首先找到该进程的vma链表头,遍历链表中的每一个vma, 通过walk_page_vma统计这块vma的使用情况,最后显示出来。
下面是其中一块 VMA 的统计信息:
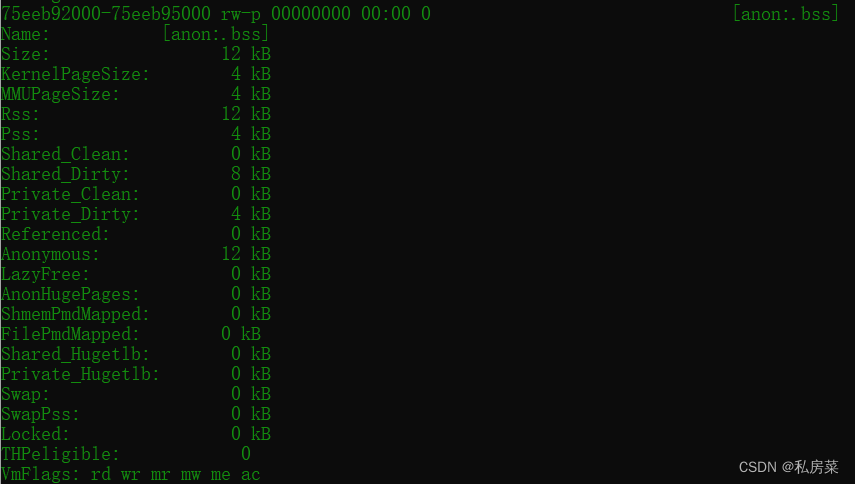
一般情况下,在Android 中就是ZRAM,通过压缩内存页面并将其放入动态分配的内存交换区来增加系统中的可用内存量,压缩的都是匿名页。
但下面这段vma 是文件映射的,但还有swap字段的,这是因为这个文件是通过mmap到进程地址空间的。当标记中有MAP_PRIVATE时,这表示是一个copy-on-write的映射,虽然是file-backed,但当向这个数据写入数据的时候,会把数据拷贝到匿名页里,所以看到上面的 Anonymous: 也不为0。
| [heap] [anon:libc_malloc] [anon:scudo: [anon:GWP-ASan | HEAP_NATIVE |
| [anon:dalvik-* | HEAP_DALVIK_OTHER |
| *.so | HEAP_SO |
| *.jar | HEAP_JAR |
| *.apk | HEAP_APK |
| *.ttf | HEAP_TTF |
| *.odex (*.dex) | HEAP_DEX ----HEAP_DEX_APP_DEX |
| *.vdex (@boot /boot /apex)
| HEAP_DEX ----HEAP_DEX_BOOT_VDEX ----HEAP_DEX_APP_VDEX |
| *.oat | HEAP_OAT |
| *.art *.art] (@boot /boot /apex) | HEAP_ART ----HEAP_ART_BOOT ----HEAP_ART_APP |
| /dev/ | HEAP_UNKNOWN_DEV |
| /dev/kgsl-3d0 | HEAP_GL_DEV |
| /dev/ashmem/CursorWindow | HEAP_CURSOR |
| /dev/ashmem/jit-zygote-cache /memfd:jit-cache /memfd:jit-zygote-cache | HEAP_DALVIK_OTHER |
| /dev/ashmem | HEAP_ASHMEM |
详细的which_heap 和sub_heap 看load_maps() 函数。
通过本函数,获取进程在GPU 上的分配内存。
下面是调用框架图:
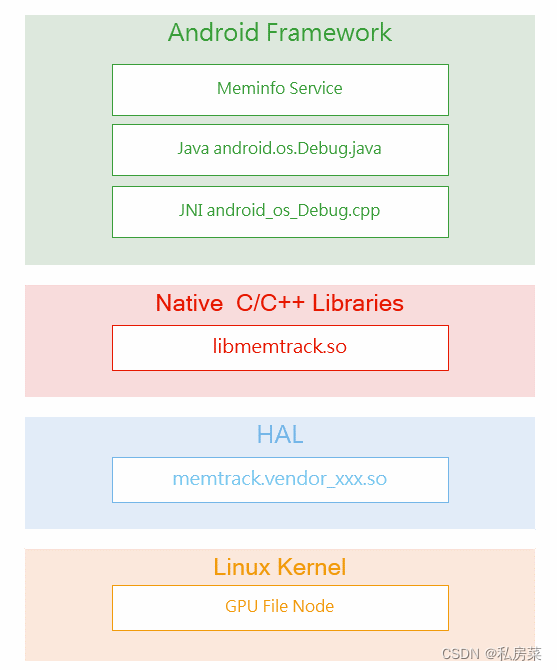
上图读取进程在GPU上分配的内存,每个厂商统计的策略可能不一样,这也是出现HAL层的原因。
在第 5.1 节中列举了几个重要的变量,其中一个就是 IApplicationThread,每个进程独有。
当然这个case 是当 opts.dumpDetails 为true,也就是针对单个应用的meminfo;
try {
TransferPipe tp = new TransferPipe();
try {
thread.dumpMemInfo(tp.getWriteFd(),
mi, opts.isCheckinRequest, opts.dumpFullDetails,
opts.dumpDalvik, opts.dumpSummaryOnly, opts.dumpUnreachable, innerArgs);
tp.go(fd, opts.dumpUnreachable ? 30000 : 5000);
} finally {
tp.kill();
}创建TransferPipe 对象,里面会创建一个thread 和 一个pipe。然后将writeFd 给app 进程的ActivithThread,在ActivityThread 将解析app 进程的内存使用。当调用go() 函数时会启动TransferPipe 创建的thread,并等待pipe 通信,如果AMS 通过 readFd 获取到数据后,会通知 dumpsys 进程表示dump 完成。
下面来看下dumpMemInfo():
---->
frameworks/base/core/java/android/app/ActivityThread.java
public void dumpMemInfo(ParcelFileDescriptor pfd, Debug.MemoryInfo mem, boolean checkin,
boolean dumpFullInfo, boolean dumpDalvik, boolean dumpSummaryOnly,
boolean dumpUnreachable, String[] args) {
FileOutputStream fout = new FileOutputStream(pfd.getFileDescriptor());
PrintWriter pw = new FastPrintWriter(fout);
try {
dumpMemInfo(pw, mem, checkin, dumpFullInfo, dumpDalvik, dumpSummaryOnly, dumpUnreachable);
} finally {
pw.flush();
IoUtils.closeQuietly(pfd);
}
}详细的代码这里不继续分析了,总结一个调用框架图:
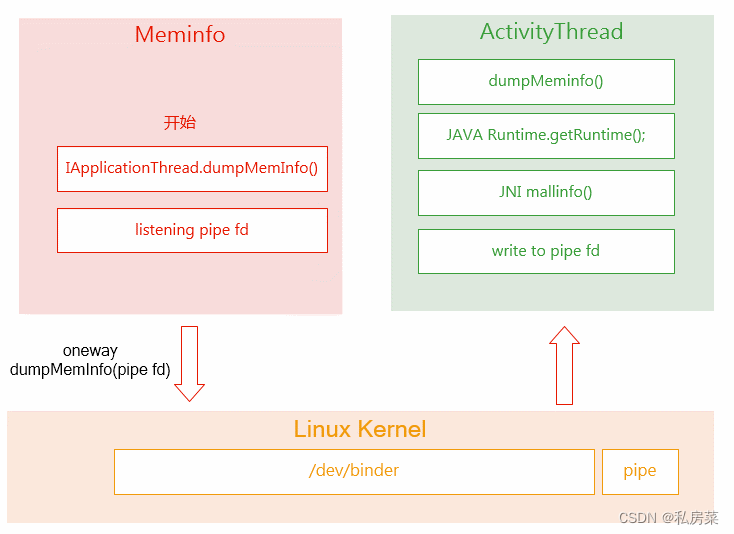
dumpMeminfo() 中会通过getRuntime() 获取app 进程dalvik 的totalMemory 和freeMemory,并计算出 dalvikAllocated,得到app 进程虚拟机内存使用情况。
并且通过Debug.getNativeHeapSize() 等三个native 接口统计app 进程的native 使用。这里同上面第 5.3 节,依然会进入androi_os_Debug.cpp 中:
frameworks/base/core/jni/android_os_Debug.cpp
static jlong android_os_Debug_getNativeHeapSize(JNIEnv *env, jobject clazz)
{
struct mallinfo info = mallinfo();
return (jlong) info.usmblks;
}
static jlong android_os_Debug_getNativeHeapAllocatedSize(JNIEnv *env, jobject clazz)
{
struct mallinfo info = mallinfo();
return (jlong) info.uordblks;
}
static jlong android_os_Debug_getNativeHeapFreeSize(JNIEnv *env, jobject clazz)
{
struct mallinfo info = mallinfo();
return (jlong) info.fordblks;
}mallinfo() 返回内存分配的统计信息,函数声明在 android/bionic/libc/include/malloc.h,函数定义在 android/bionic/libc/bionic/malloc_common.cpp:
extern "C" struct mallinfo mallinfo() {
auto dispatch_table = GetDispatchTable();
if (__predict_false(dispatch_table != nullptr)) {
return dispatch_table->mallinfo();
}
return Malloc(mallinfo)();
}mallinfo() 主要是返回一个结构体,结构体中包含了通过malloc() 和其相关的函数调用所申请的内存信息,下面是结构体mallinfo 的具体信息(其他信息见man):
struct mallinfo {
int arena; /* Non-mmapped space allocated (bytes) */
int ordblks; /* Number of free chunks */
int smblks; /* Number of free fastbin blocks */
int hblks; /* Number of mmapped regions */
int hblkhd; /* Space allocated in mmapped regions (bytes) */
int usmblks; /* Maximum total allocated space (bytes) */
int fsmblks; /* Space in freed fastbin blocks (bytes) */
int uordblks; /* Total allocated space (bytes) */
int fordblks; /* Total free space (bytes) */
int keepcost; /* Top-most, releasable space (bytes) */
};我们这里返回的三个信息:
这两个输在如下图所示: 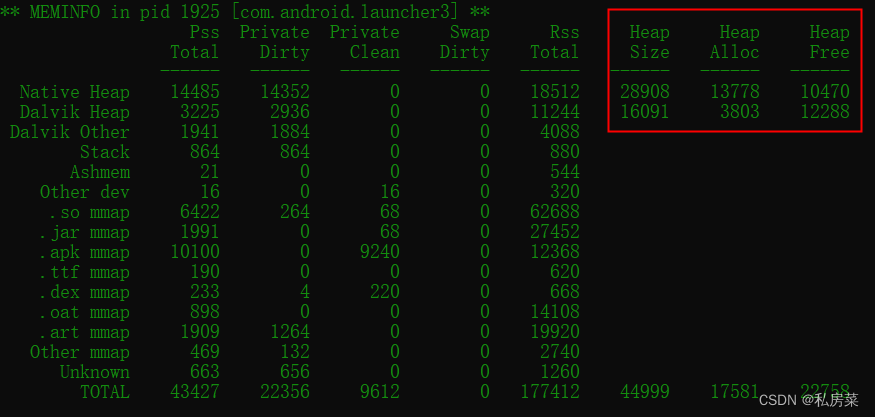
在将MemInfoReader 之前,需要回到代码最开始,了解下变量 collectNative:
final boolean collectNative = !opts.isCheckinRequest && numProcs > 1 && !opts.packages;当dump 多个应用或者所有应用的meminfo 时,变量 collectNative 被置true;如果只是打印单个应用的meminfo 时该值为 false,所以最终不会打印。
MemInfoReader memInfo = new MemInfoReader();
memInfo.readMemInfo();详细的代码不再剖析,这里总结一个调用框架:

输出如下图:

shift:/ # dumpsys meminfo com.android.launcher3
Applications Memory Usage (in Kilobytes):
Uptime: 4443605 Realtime: 4443605
** MEMINFO in pid 1834 [com.android.launcher3] **
Pss Private Private Swap Rss Heap Heap Heap
Total Dirty Clean Dirty Total Size Alloc Free
------ ------ ------ ------ ------ ------ ------ ------
Native Heap 13647 13548 0 0 16152 21672 16064 1962
Dalvik Heap 5338 5144 0 0 9496 6657 3329 3328
Dalvik Other 1317 1192 0 0 2376
Stack 636 636 0 0 644
Ashmem 2 0 0 0 20
Other dev 140 0 140 0 392
.so mmap 7350 232 12 0 57116
.jar mmap 2359 0 76 0 24984
.apk mmap 22108 0 15208 0 51748
.ttf mmap 110 0 0 0 376
.dex mmap 348 8 336 0 432
.oat mmap 1384 0 0 0 14560
.art mmap 2434 1608 4 0 20496
Other mmap 495 60 24 0 2896
Unknown 599 588 0 0 1128
TOTAL 58267 23016 15800 0 58267 28329 19393 5290
App Summary
Pss(KB) Rss(KB)
------ ------
Java Heap: 6756 29992
Native Heap: 13548 16152
Code: 15872 149484
Stack: 636 644
Graphics: 0 0
Private Other: 2004
System: 19451
Unknown: 6544
TOTAL PSS: 58267 TOTAL RSS: 202816 TOTAL SWAP (KB): 0
Objects
Views: 89 ViewRootImpl: 1
AppContexts: 10 Activities: 1
Assets: 14 AssetManagers: 0
Local Binders: 34 Proxy Binders: 43
Parcel memory: 13 Parcel count: 69
Death Recipients: 1 OpenSSL Sockets: 0
WebViews: 0
SQL
MEMORY_USED: 682
PAGECACHE_OVERFLOW: 292 MALLOC_SIZE: 117
DATABASES
pgsz dbsz Lookaside(b) cache Dbname
4 16 20 1/14/1 /data/user/0/com.android.launcher3/databases/widgetpreviews.db
4 252 71 99/18/5 /data/user/0/com.android.launcher3/databases/app_icons.db
4 16 57 6/17/4 /data/user/0/com.android.launcher3/databases/launcher.db来看下其中几个主要概念:
Java Heap: 24312 dalvik heap + .art mmap
Native Heap: 62256
Code: 66452 .so mmap + .jar mmap + .apk mmap + .ttf mmap + .dex mmap + .oat mmap
Stack: 84
Graphics: 5338 Gfx dev + EGL mtrack + GL mtrack
Private Other: 9604 TotalPrivateClean + TotalPrivateDirty - java - native - code - stack - graphics
System: 12900 TotalPss - TotalPrivateClean - TotalPrivateDirtyhttps://developer.android.com/studio/profile/investigate-ram?hl=zh-cn
Dalvik Heap
应用中 Dalvik 分配占用的 RAM。Pss Total 包括所有 Zygote 分配(如上述 PSS 定义所述,通过进程之间的共享内存量来衡量)。Private Dirty 数值是仅分配到您应用的堆的实际 RAM,由您自己的分配和任何 Zygote 分配页组成,这些分配页自从 Zygote 派生应用进程以来已被修改。
Heap Alloc
是 Dalvik 和原生堆分配器为您的应用跟踪的内存量。此值大于 Pss Total 和 Private Dirty,因为您的进程从 Zygote 派生,且包含您的进程与所有其他进程共享的分配。
.so mmap 和 .dex mmap
映射的 .so(原生)和 .dex(Dalvik 或 ART)代码占用的 RAM。Pss Total 数值包括应用之间共享的平台代码;Private Clean 是您的应用自己的代码。通常情况下,实际映射的内存更大 - 此处的 RAM 仅为应用执行的代码当前所需的 RAM。不过,.so mmap 具有较大的私有脏 RAM,因为在加载到其最终地址时对原生代码进行了修改。
.oat mmap
这是代码映像占用的 RAM 量,根据多个应用通常使用的预加载类计算。此映像在所有应用之间共享,不受特定应用影响。
.art mmap
这是堆映像占用的 RAM 量,根据多个应用通常使用的预加载类计算。此映像在所有应用之间共享,不受特定应用影响。尽管 ART 映像包含 Object 实例,它仍然不会计入您的堆大小。
But as to what the difference is between "Pss", "PrivateDirty", and "SharedDirty"... well now the fun begins.
A lot of memory in Android (and Linux systems in general) is actually shared across multiple processes.
So how much memory a processes uses is really not clear. Add on top of that paging out to disk (let alone swap which we don't use on
Android) and it is even less clear.
Thus if you were to take all of the physical RAM actually mapped in to each process, and add up all of the processes,
you would probably end up with a number much greater than the actual total RAM.
The Pss number is a metric the kernel computes that takes into account memory sharing -- basically each page of RAM in a process is
scaled by a ratio of the number of other processes also using that page. This way you can (in theory) add up the pss across all
processes to see the total RAM they are using, and compare pss between processes to get a rough idea of their relative weight.
The other interesting metric here is PrivateDirty, which is basically the amount of RAM inside the process that can not be paged
to disk (it is not backed by the same data on disk), and is not shared with any other processes. Another way to look at this is the
RAM that will become available to the system when that process goes away (and probably quickly subsumed into caches and other uses
of it).从这篇文章中得知:
一般的android和linux系统中很多进程会共享一些mem,所以一个进程用到的mem其实不是十分清楚,因此如果将每个进程实际占用的mem加到一起,可能会发现这个结果会远远的超过实际的总的mem。
Pss 是kernel根据共享mem计算得到的值,Pss的值是一块共享mem中一定比例的值。这样,将所有进程Pss加起来就是总的RAM值了,也可以通过进程间Pss值得到这些进程使用比重情况。
PrivateDirty,它基本上是进程内不能被分页到磁盘的内存,也不和其他进程共享。查看进程的内存用量的另一个途径,就是当进程结束时刻,系统可用内存的变化情况(也可能会很快并入高速缓冲或其他使用该内存区的进程)。
其他类型 smap 路径名称 描述
Ashmem /dev/ashmem 匿名共享内存用来提供共享内存通过分配一个多个进程
可以共享的带名称的内存块
Other dev /dev/ 内部driver占用的在 “Other dev”
.so mmap .so C 库代码占用的内存
.jar mmap .jar Java 文件代码占用的内存
.apk mmap .apk apk代码占用的内存
.ttf mmap .ttf ttf 文件代码占用的内存
.dex mmap .dex Dex 文件代码占用的内存
Other mmap 其他文件占用的内存 Total RAM: 3,768,168K (status normal)
Free RAM: 2,186,985K ( 64,861K cached pss + 735,736K cached kernel + 1,386,388K free)
ION: 58,408K ( 53,316K mapped + -128K unmapped + 5,220K pools)
Used RAM: 1,440,349K (1,116,469K used pss + 323,880K kernel)
Lost RAM: 140,822K
ZRAM: 12K physical used for 0K in swap (2,097,148K total swap)
Tuning: 256 (large 512), oom 640,000K, restore limit 213,333K (high-end-gfx)
pw.print(stringifyKBSize(memInfo.getTotalSizeKb()));Total RAM 就是/proc/meminfo 中的 MemTotal
pw.print(stringifyKBSize(cachedPss + memInfo.getCachedSizeKb()
+ memInfo.getFreeSizeKb()));括号中的:
pw.print(stringifyKBSize(totalPss - cachedPss + kernelUsed)); 括号中的
注意上面的 KernelStack,只要在kernel 没有配置 CONFIG_VMAP_STACK 时,才会加上。
frameworks/base/core/java/com/android/internal/util/MemInfoReader.java
public long getKernelUsedSizeKb() {
long size = mInfos[Debug.MEMINFO_SHMEM] + mInfos[Debug.MEMINFO_SLAB_UNRECLAIMABLE]
+ mInfos[Debug.MEMINFO_VM_ALLOC_USED] + mInfos[Debug.MEMINFO_PAGE_TABLES];
if (!Debug.isVmapStack()) {
size += mInfos[Debug.MEMINFO_KERNEL_STACK];
}
return size;
} final long lostRAM = memInfo.getTotalSizeKb() - (totalPss - totalSwapPss)
- memInfo.getFreeSizeKb() - memInfo.getCachedSizeKb()
- kernelUsed - memInfo.getZramTotalSizeKb();Lost RAM = proc/meminfo.Memtotal - (totalPss - totalSwapPss) - /proc/meminfo.Memfree - /proc/meminfo.Cached - kernel used - zram used
注意:
从这里大致可以推算出
FREE RAM + USed RAM - totalSwapPss + Lost RAM + ZRAM = Total RAM
pw.print(" Tuning: ");
pw.print(ActivityManager.staticGetMemoryClass());
pw.print(" (large ");
pw.print(ActivityManager.staticGetLargeMemoryClass());
pw.print("), oom ");
pw.print(stringifySize(
mProcessList.getMemLevel(ProcessList.CACHED_APP_MAX_ADJ), 1024));
pw.print(", restore limit ");
pw.print(stringifyKBSize(mProcessList.getCachedRestoreThresholdKb()));
if (ActivityManager.isLowRamDeviceStatic()) {
pw.print(" (low-ram)");
}
if (ActivityManager.isHighEndGfx()) {
pw.print(" (high-end-gfx)");
}
pw.println();large:dalvik.vm.heapsize属性取值,单位为MB
oom:ProcessList中mOomMinFree数组最后一个元素取值
restore limit:ProcessList中mCachedRestoreLevel变量取值,将一个进程从cached 到background的最大值,一般是mOomMinFree 最后一个值的 1/3.
low-ram:是否为low ram 设备,一般通过prop ro.config.low_ram,或者当ro.debuggable 使能时prop debug.force_low_ram。
high-end-gfx:ro.config.low_ram 为false,且ro.config.avoid_gfx_accel 为false,且config config_avoidGfxAccel 的值为false。
参考:https://blog.csdn.net/feelabclihu/article/details/105534175
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
如何用IDEA2022创建并初始化一个SpringBoot项目?目录如何用IDEA2022创建并初始化一个SpringBoot项目?0. 环境说明1. 创建SpringBoot项目 2.编写初始化代码0. 环境说明IDEA2022.3.1JDK1.8SpringBoot1. 创建SpringBoot项目 打开IDEA,选择NewProject创建项目。 填写项目名称、项目构建方式、jdk版本,按需要修改项目文件路径等信息。 选择springboot版本以及需要的包,此处只选择了springweb。 此处需特别注意,若你使用的是jdk1
前言上一篇我们简要讲述了粒子系统是什么,如何添加,以及基本模块的介绍,以及对于曲线和颜色编辑器的讲解。从本篇开始,我们将按照模块结构讲解下去,本篇主要讲粒子系统的主模块,该模块主要是控制粒子的初始状态和全局属性的,以下是关于该模块的介绍,请大家指正。目录前言本系列提要一、粒子系统主模块1.阅读前注意事项2.参考图3.参数讲解DurationLoopingPrewarmStartDelayStartLifetimeStartSpeed3DStartSizeStartSize3DStartRotationStartRotationFlipRotationStartColorGravityModif
VMware虚拟机与本地主机进行磁盘共享前提虚拟机版本为Windows10(专业版,不是可能有问题)本地主机为家庭版或学生版(此版本会有问题,但有替代方式)最好是专业版VMware操作1.关闭防火墙,全部关闭。2.打开电脑属性3.点击共享-》高级共享-》权限4.如果没有everyone,就添加权限选择完全控制,然后应用确定。5.打开cmd输入lusrmgr.msc(只有专业版可以打开)如果不是专业版,可以跳过这一步。点击用户-》administrator密码要复杂密码,否则不行。推荐admaiN@1234类型的密码。设置完密码,点击属性,将禁用解开。6.如果虚拟机的windows不是专业版,可
IK分词器本文分为简介、安装、使用三个角度进行讲解。简介倒排索引众所周知,ES是一个及其强大的搜索引擎,那么它为什么搜索效率极高呢,当然和他的存储方式脱离不了关系,ES采取的是倒排索引,就是反向索引;常见索引结构几乎都是通过key找value,例如Map;倒排索引的优势就是有效利用Value,将多个含有相同Value的值存储至同一位置。分词器为了配合倒排索引,分词器也就诞生了,只有合理的利用Value,才会让倒排索引更加高效,如果一整个Value不进行任何操作直接进行存储,那么Value和key毫无区别。分词器Analyzer通常会对Value进行操作:一、字符过滤,过滤掉html标签;二、分
题外话:抑郁场,开局一小时只出A,死活想不来B,最后因为D题出锅ura才保住可怜的分。但咱本来就写不到DB-LongLegs(数论)本题题解法一学自同样抑郁的知乎作者幽血魅影的题解,有讲解原理。法二来着知乎巨佬cup-pyy(大佬说《不难发现》呜呜)题意三种操作:向上走mmm步向右走mmm步给自己一次走的步数加111,即使得m=m+1m=m+1m=m+1问从(0,0)(0,0)(0,0)走到(a,b)(a,b)(a,b)的最小操作次数,值得注意的是操作三不可逆。解析假设我们最终一步的大小增长到mmm,那么在这个过程中我能以[1,m][1,m][1,m](当步数增长到该数时)之间的任何数字向上或