提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
分享一个交通大数据可视化的案例,本案例来自于transbigdata包的出租车数据分析案例的复现,数据集采用的是成都市的出租车(网约车和传统的出租车数据),文件内容比较大,这里我会附带数据集的下载链接,由于电脑运行内存有限,本案例分享选择其中一个数据集中的一部分车辆轨迹进行分析.废话少说,直接上案例。数据链接如下
链接:https://pan.baidu.com/s/1OeNs36fZHEon2yNA2bhs9A
提取码:hqen
–来自百度网盘超级会员V6的分享
大家提取完数据集后,建议先压缩一个压缩包中的一个txt文件,如果电脑空间大,当我没说。
不要试图去打开这个 txt文档,太大了根本打不开。这里直接将txt文档的后缀改成csv后缀,如下图

然后还有一个地理信息文件(JESON)要准备

这些都准备好之后我们就可以开始操作了。
这里建议在jupyter notebook上进行操作,并且假设你已经装好下面几个库。这里需要注意transbigdata、geopandas两个库如果之前没有用过的同学可能会比较陌生,但这两个库是本案例的核心库,具体的安装与引入请参考https://transbigdata.readthedocs.io/zh_CN/latest/index.html。CoordinatesConverter库用于转换坐标系。matplotlib、pandas库应该很常见,直接pip install就完事儿。
代码如下(示例):
import transbigdata as tbd
import CoordinatesConverter #GPS数据转换库
import geopandas as gpd
import matplotlib.pyplot as plt
import pandas as pd
这里注意要将数据文件和jeson文件都放入.ipynb或者程序所在的文件夹下。
代码如下(示例):
data = pd.read_csv('20140803_train.csv',header=None)
data
输出结果如下
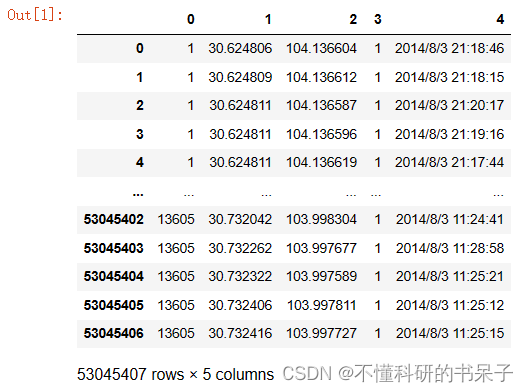
上述数据又500多万条,如果电脑吃不消的话,可以筛选其中十几万条进行分析。五个字段,分别为车辆编号,纬度,经度,载客状态,时间。可以用下面代码给数据添加有意义的表头
代码如下(示例):
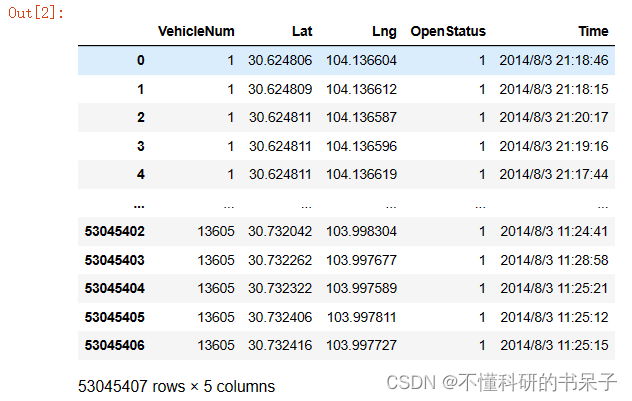
data.columns = ['VehicleNum','Lat','Lng','OpenStatus','Time']
data
data
查看数据统计
tbd.data_summary(data, col=['VehicleNum', 'Time'], show_sample_duration=False, roundnum=4)
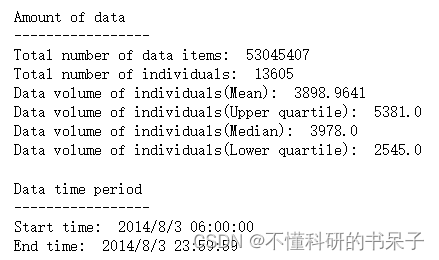
这里的时间数据已经被识别,从6-23:59:59,也可以用下面代码识别数据集中的时间字段数据是否能够在后续的操作中被运用。
pd.to_datetime(data['Time'])
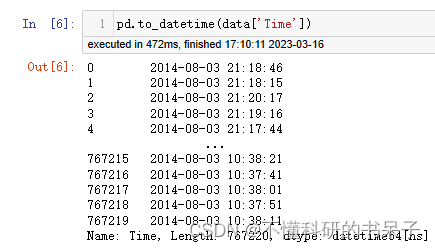
这里我电脑运行内存只有8GB,所以运行不了那么大的数据量,需要筛选,经过我多次的筛选,最终确定了70万条数据为我电脑比较合适的数据处理量,如果各位读者电脑很牛掰(比我电脑牛)的话,这段话及下面的提取前70多万条数据的代码块可以跳过。
#提取前199俩车的轨迹数据
data = data[data['VehicleNum']<200] #筛选前199辆车的轨迹数据
tbd.data_summary(data, col=['VehicleNum', 'Time'], show_sample_duration=False, roundnum=4) #统计这199俩车的数据情况
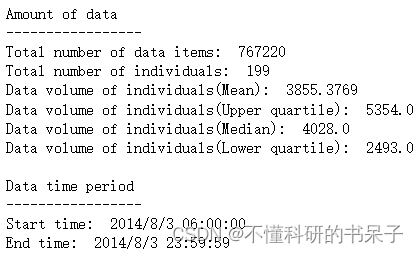
考虑到不同数据记录方式所用的坐标系可能不同,这里可以用transbigdata库的一个函数判断是否大体与底图配对。
tbd.visualization_data(data,col = ['Lng','Lat'],accuracy=20) #accuracy表示识别精度,建议50以下
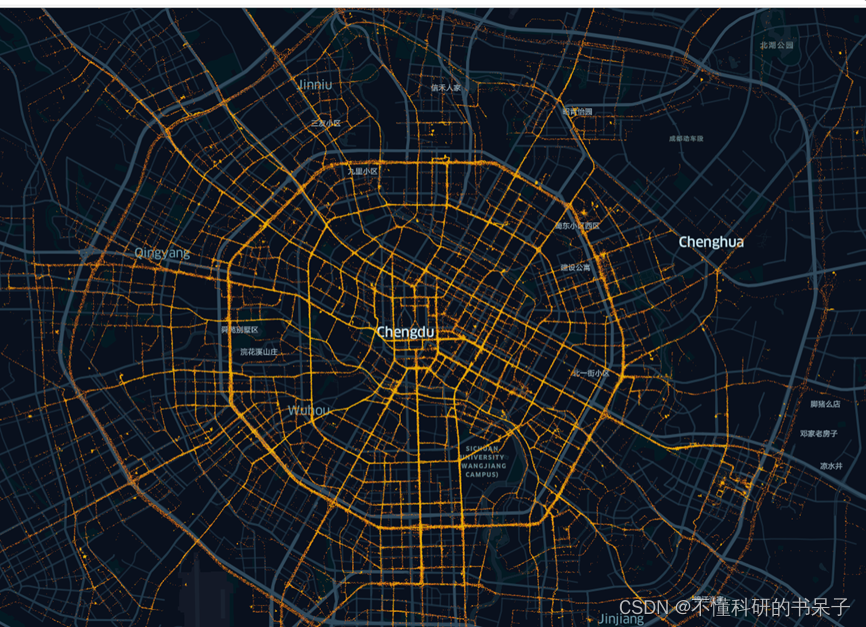
很明显车辆轨迹点与路网匹配的偏差比较大,所以需要对坐标系进行转换。
data['Lng'],data['Lat'] = CoordinatesConverter.gcj02towgs84(data['Lng'],data['Lat']) #将数据点转换为84坐标系下的GPS点
tbd.visualization_data(data,col = ['Lng','Lat'],accuracy=20) #可视化
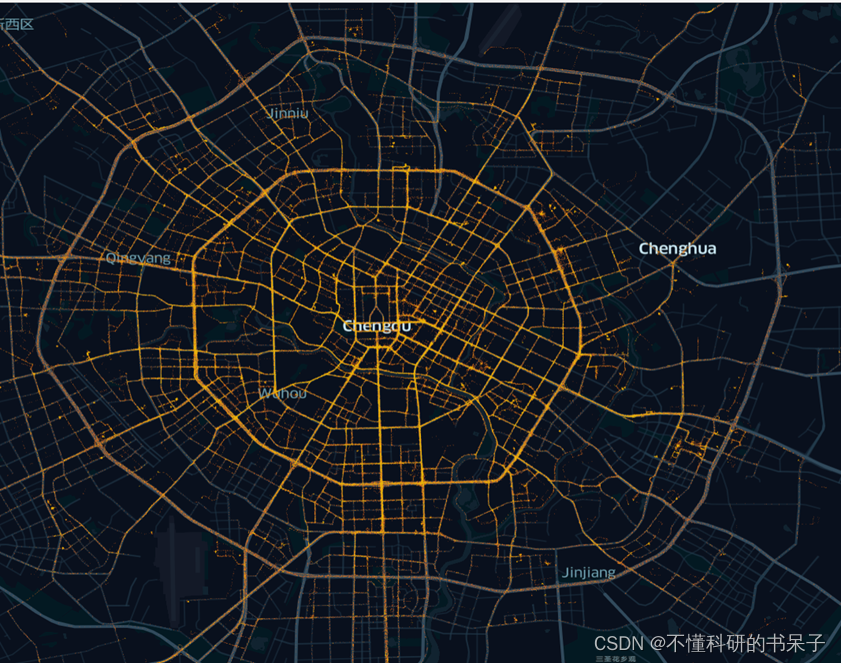
可以看出经过坐标转换之后数据点与路网基本配对上。
transbigdata包栅格化处理数据框架

读取研究范围内的地图信息,生成GeoDataFrame变量
#读取区域信息
cd = gpd.read_file(r'citys_510100.json')
cd.crs = None
cd.head()#展示表格前五行的数据
也可以用plot方法把cd变量画出来
cd.plot()
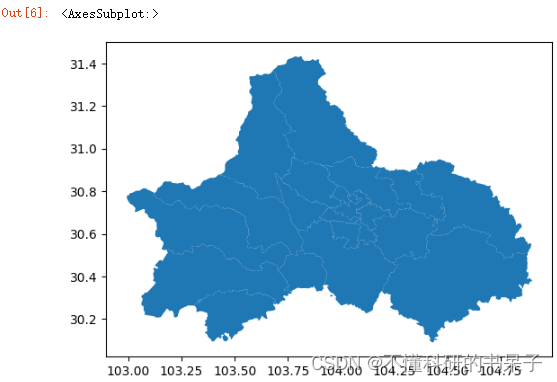
这里大概可以获取到图形的边界bounds = [103, 30.2, 104.75, 31.4] (后面有用上)。需要根据研究范围对数据集进行异常数据的处理,主要处理掉不在研究范围内的数据与载客状态变化异常的数据
data = tbd.clean_outofshape(data, cd, col=['Lng', 'Lat'], accuracy=1) #剔除研究范围外的数据,accuracy可以调整,越小越精确。
data = tbd.clean_taxi_status(data, col=['VehicleNum', 'Time', 'OpenStatus']) #剔除出租车数据中载客状态瞬间变化的记录
将研究范围进行栅格化,这里分两步进行,第一步先加载底图和绘制研究范围内的图像,第二步生成研究范围栅格化的图像。
第一步代码:
bounds = [102.95, 30.08, 104.9, 31.45] #设定研究范围的边界
#绘制区域以及地图底图
fig = plt.figure(1, (6, 6), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
#plot_map函数加载底图
tbd.plot_map(plt, bounds, zoom=12, style='OSM')
#绘制地理区域
cd.plot(ax=ax, alpha=0.5)
plt.axis('off');
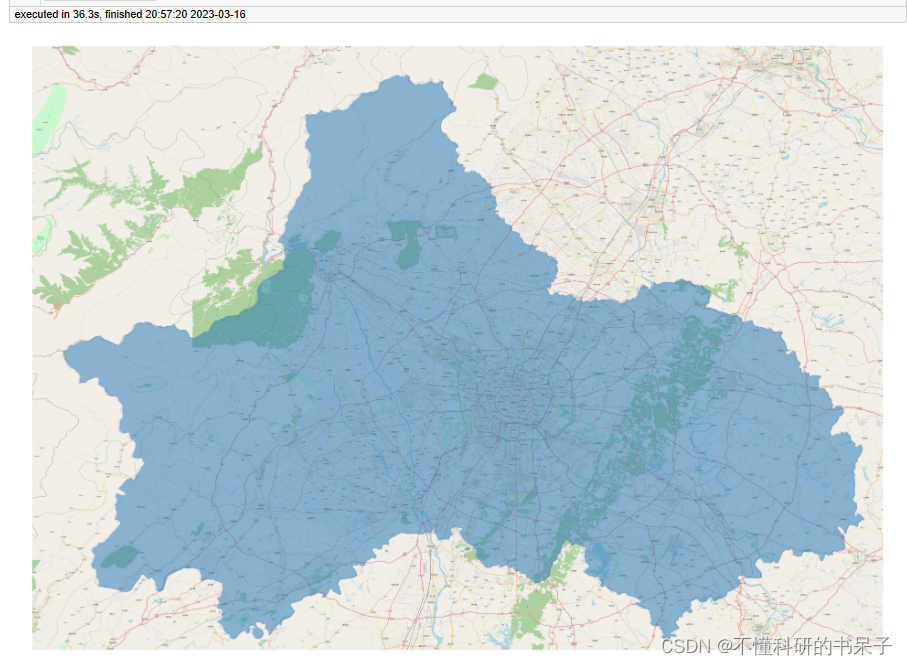
第二步代码:
import pprint
grid, params = tbd.area_to_grid(cd)
#栅格参数,方形栅格下method参数是rect,代表方形栅格
pprint.pprint(params)
#栅格几何图形
grid.head()
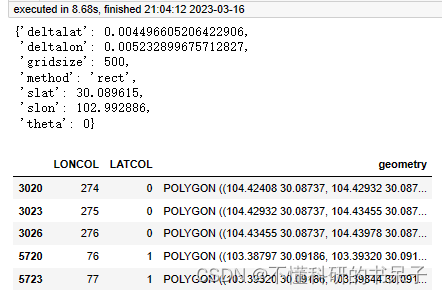
栅格地图的表格形式已经生成好,同时栅格的切割参数如上图字典中的内容,下面代码进行切割后的栅格图像的可视化。
#可视化刚才创建的方形栅格
#创建图框
fig = plt.figure(1, (12, 8), dpi=800)
ax1 = plt.subplot(121)
plt.sca(ax1)
tbd.plot_map(plt, bounds, zoom=13, style='OSM')
#绘制方形栅格
grid.plot(ax=ax1, lw=0.2, edgecolor='blue', facecolor="None")
plt.axis('off');
这里我采用的样式也就是tbd.plot_map方法里面style='OSM’为免费的样式(OpenStreetMap),如果想用其它的样式可以参考https://transbigdata.readthedocs.io/zh_CN/latest/plot_map.html一共有12种样式,这里的12种样式都需要mapbox里面的Access token,可以通过申请mapbox并成为开发者免费获得Access token,这里我给大家展示一下style='streets’的样式:
将获得的GPS数据栅格化,生成车辆轨迹所在栅格地图上的位置。
#GPS栅格化
data['LONCOL'], data['LATCOL'] = tbd.GPS_to_grid(data['Lng']
data['Lat'], params)
data

执行后的结果可以看到右边两列表示该轨迹点在栅格地图种的位置,0号轨迹在栅格中的位置为(215,126)。
#集计栅格数据量
datatest = data.groupby(['LONCOL', 'LATCOL'])
['VehicleNum'].count().reset_index()
#生成栅格地理图形
datatest['geometry'] = tbd.grid_to_polygon([datatest['LONCOL'], datatest['LATCOL']], params)
#转为GeoDataFrame
# import geopandas as gpd
datatest = gpd.GeoDataFrame(datatest)
datatest.head()
对车辆轨迹数据进行栅格统计,并生成栅格地理图形。可以调用变量datatest查看集计后的表格和地理图形。
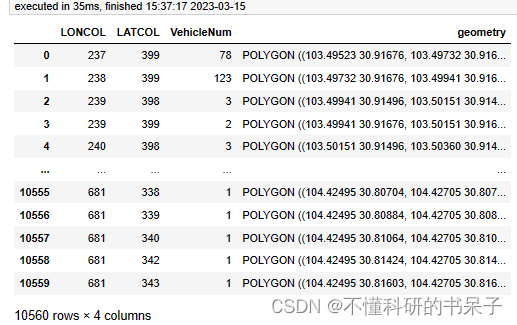
第一行的意思表示(237,399)栅格上有78条车辆轨迹数据。同时可以对该数据可视化。
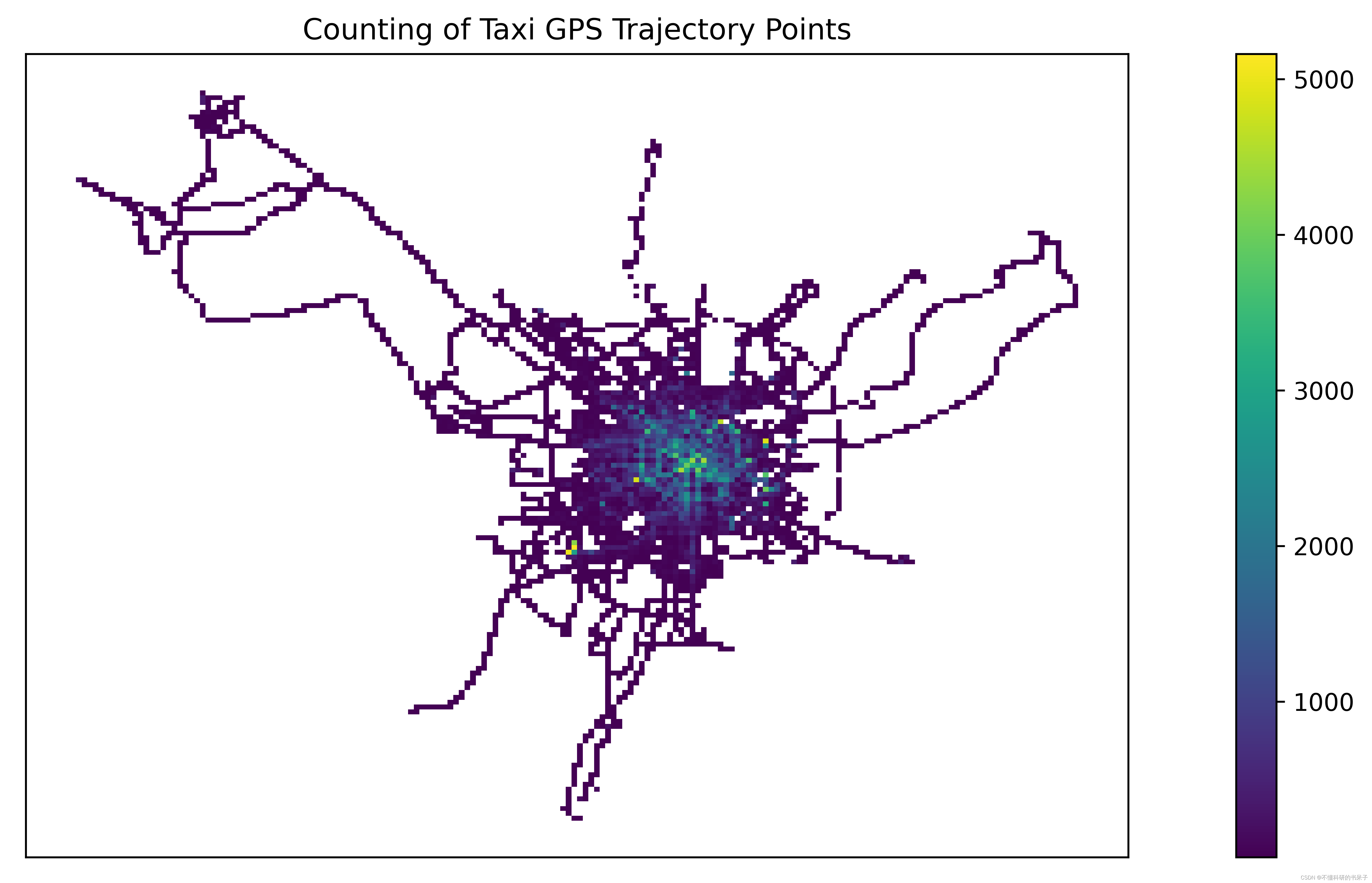
不绘制底图的可视化
# 绘制栅格
fig = plt.figure(1, (16, 6), dpi=600)
ax1 = plt.subplot(111)
# tbd.plot_map(plt, bounds, zoom=10, style=4)
datatest.plot(ax=ax1, column='VehicleNum', legend=True)
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
plt.title('Counting of Taxi GPS Trajectory Points', fontsize=12);
绘制底图的可视化
bounds = [102.95, 30.08, 104.9, 31.45]
#创建图框
fig = plt.figure(1, (10, 10), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
#添加地图底图
tbd.plot_map(plt, bounds, zoom=14, style='streets')
cd.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
datatest.plot(ax=ax, column='VehicleNum', scheme='quantiles')
plt.title('Counting of Taxi GPS Trajectory Points', fontsize=12);
注意这里我用的是mapbox的底图,如果各位没用Access token的话就将style改成OSM。接下来提取车辆OD,这里有两种方法都可以提取OD。
#从GPS数据提取OD
#方法一:
oddata = tbd.taxigps_to_od(data,col = ['VehicleNum', 'Time', 'Lng', 'Lat', 'OpenStatus'])
#方法二:
'''data = data.sort_values(by = ['VehicleNum','Time'])
data['OpenStatus_pre'] = data['OpenStatus'].shift()
data['OpenStatus_next'] = data['OpenStatus'].shift(-1)
data = data[-((data['OpenStatus']!=data['OpenStatus_next'])&(data['OpenStatus']!=data['OpenStatus_pre'])&
(data['VehicleNum']==data['VehicleNum'].shift())&(data['VehicleNum']==data['VehicleNum'].shift(-1)))]
data['VehicleNum_next']=data['VehicleNum'].shift(-1)
oddata = data[(data['VehicleNum'] == data['VehicleNum_next']) & (data['OpenStatus'] != data['OpenStatus_next'])].copy()
oddata = oddata[['VehicleNum','Time','Lng','Lat','OpenStatus']].copy()
oddata['VehicleNum_next'] = oddata['VehicleNum'].shift(-1)
oddata['OpenStatus_next'] = oddata['OpenStatus'].shift(-1)
oddata['Lng_'] = oddata['Lng'].shift(-1)
oddata['Lat_'] = oddata['Lat'].shift(-1)
oddata['Time_next'] = oddata['Time'].shift(-1)
oddata = oddata[(oddata['OpenStatus'] == 0)&(oddata['VehicleNum'] ==oddata['VehicleNum_next'])
].drop(['OpenStatus','VehicleNum_next','OpenStatus_next'],axis = 1).copy()
oddata
oddata.columns=['VehicleNum','stime','slog','slat','elog','elat','etime']'''
oddata
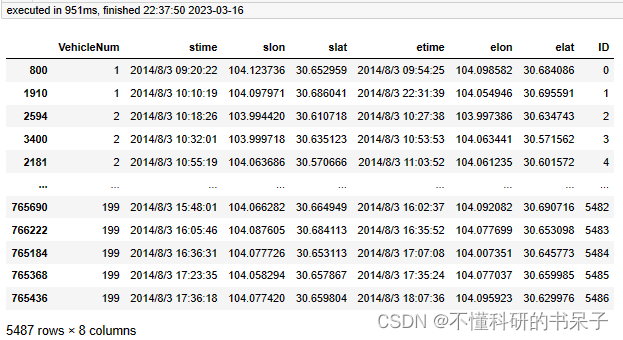
OD数据提取后,也要将OD数据栅格化。
OD数据栅格化
od_gdf = tbd.odagg_grid(oddata, params)
od_gdf.head()

在执行完这段代码后可能会出现warning,不过对我们的结果不会有任何影响,我们继续。下面绘制栅格OD
# 绘制栅格OD
fig = plt.figure(1, (16, 6), dpi=800) # 确定图形高为6,宽为8;图形清晰度
ax1 = plt.subplot(111)
# data_grid_count.plot(ax=ax1, column='VehicleNum', legend=True, cmap='OrRd', scheme='quantiles')
plt.sca(ax1)
od_gdf.plot(ax=ax1, column='count', legend=True, scheme='quantiles')
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
plt.title('OD Trips', fontsize=12);
bounds = [102.95, 30.08, 104.9, 31.45]
cd.plot(ax=ax1, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
tbd.plot_map(plt, bounds, zoom=12, style='streets')
这段代码执行也会有warning,无伤大雅,可以继续下面的步骤。将OD集计到小区,并进行可视化
od_gdf = tbd.odagg_shape(oddata, cd, round_accuracy=6) #OD集计到小区
bounds = [102.95, 30.08, 104.9, 31.45]
#创建图框
fig = plt.figure(1, (10, 10), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
#添加地图底图
tbd.plot_map(plt, bounds, zoom=12, style='streets')
#绘制colorbar
cax = plt.axes([0.05, 0.33, 0.02, 0.3])
plt.title('OD\nMatrix')
plt.sca(ax)
#绘制OD
od_gdf.plot(ax=ax, vmax=100, column='count', cax=cax, legend=True)
#绘制小区底图
cd.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
#添加比例尺和指北针
tbd.plotscale(ax, bounds=bounds, textsize=10, compasssize=1, accuracy=2000, rect=[0.06, 0.03], zorder=10)
plt.axis('off')
plt.xlim(bounds[0], bounds[2])
plt.ylim(bounds[1], bounds[3])
plt.show()
这样基本上将出租车数据栅格化分析整完了,下面开始进行可视化分析,进行下面的分析时需要用到上面的代码,所以请在上述程序下继续进行。
这里需要提取载客时的轨迹(data_deliver)和空载时的轨迹(data_idle),执行如下代码
data_deliver, data_idle = tbd.taxigps_traj_point(data,oddata,col=['VehicleNum',
'Time',
'Lng',
'Lat',
'OpenStatus'])
数据提取完毕之后可以将载客与空载的轨迹用图形表示
载客
bounds = [102.95, 30.08, 104.9, 31.45]
#创建图框
fig = plt.figure(1, (10, 10), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
#添加地图底图
tbd.plot_map(plt, bounds, zoom=12, style='streets')
#绘制colorbar
cax = plt.axes([0.05, 0.33, 0.02, 0.3])
plt.title('OD\nMatrix')
plt.sca(ax)
#绘制OD
traj_deliver = tbd.points_to_traj(data_deliver)
traj_deliver.plot(ax=ax);
#绘制小区底图
cd.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
#添加比例尺和指北针
tbd.plotscale(ax, bounds=bounds, textsize=10, compasssize=1, accuracy=2000, rect=[0.06, 0.03], zorder=10)
plt.axis('off')
plt.xlim(bounds[0], bounds[2])
plt.ylim(bounds[1], bounds[3])
plt.title('zaike', fontsize=12);
plt.show()
空载
bounds = [102.95, 30.08, 104.9, 31.45]
#创建图框
fig = plt.figure(1, (10, 10), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
#添加地图底图
tbd.plot_map(plt, bounds, zoom=12, style='streets')
#绘制colorbar
cax = plt.axes([0.05, 0.33, 0.02, 0.3])
plt.title('OD\nMatrix')
plt.sca(ax)
#绘制OD
traj_deliver = tbd.points_to_traj(data_idle)
traj_deliver.plot(ax=ax);
#绘制小区底图
cd.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
#添加比例尺和指北针
tbd.plotscale(ax, bounds=bounds, textsize=10, compasssize=1, accuracy=2000, rect=[0.06, 0.03], zorder=10)
plt.axis('off')
plt.xlim(bounds[0], bounds[2])
plt.ylim(bounds[1], bounds[3])
plt.title('', fontsize=12);
plt.show()
根据处理后的数据可以生成相应的轨迹移动视频
from keplergl import KeplerGl
a=tbd.visualization_trip(data_deliver)
a.save_to_html(file_name='data_visua_vedio.html')
del a
这样就在当前文件夹目录下生成了一共html文件
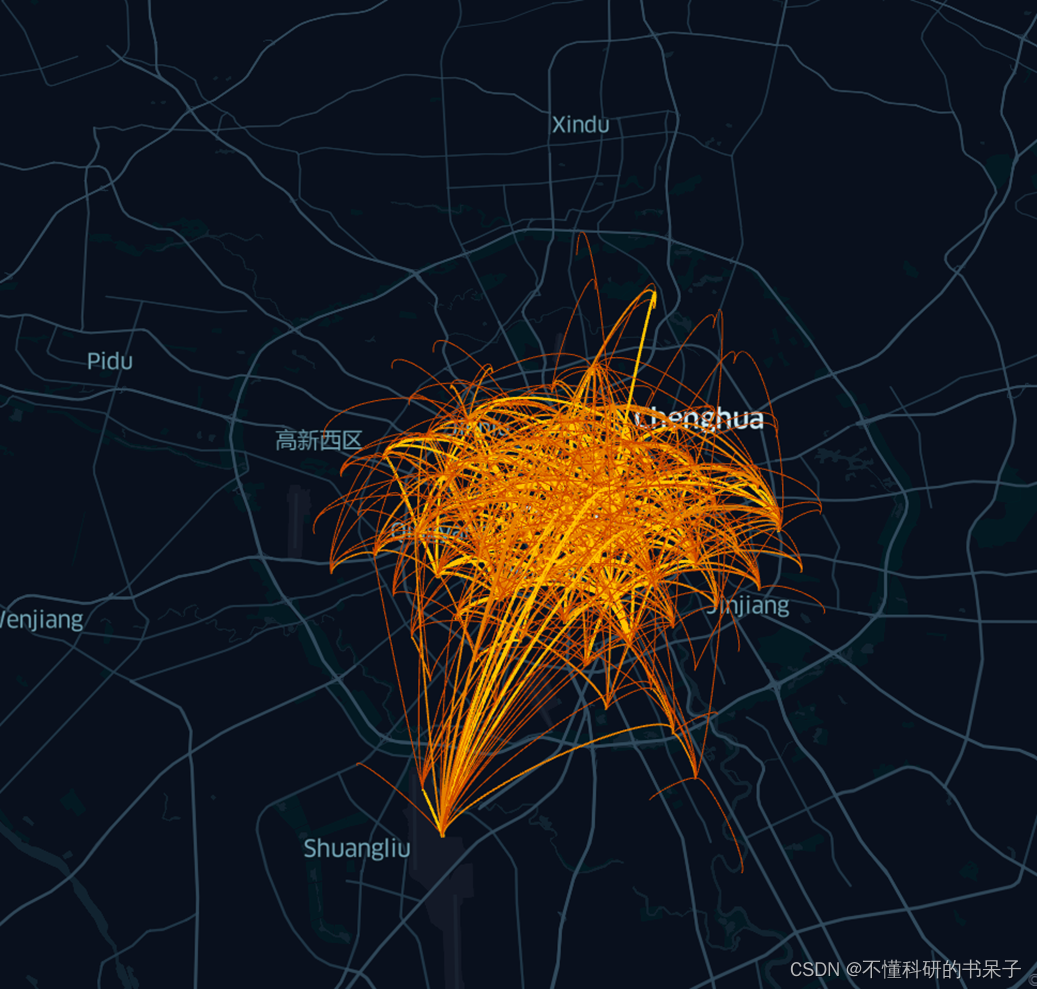
在文件目录下打开html文件就可以显示其轨迹的结果了。如果要将空载的轨迹可视化则把data_deliver替换成data_idle即可。也可以根据od数据生成OD图
a=tbd.visualization_od(oddata,accuracy=2000)
a.save_to_html(file_name='od_visua.html')
del a
本文主要运用transbigdata库对出租车数据进行栅格化处理后再对其OD和轨迹数据进行可视化。transbigdata库上的案例是深圳市的,这里的案例是成都市的轨迹数据分析,通过数据预处理、数据栅格化、可视化三个步骤复现,同时像文中的一些参数的调整将会生成不同的图形样式,如accuracy参数对应精确度,style参数对应底图的样式。对应不同的样式相关研究人员可以在此基础上进一步统计不同时间段不同区的订单数,行车速度等,也可以提取空间特征和时间特征并运用机器学习的方法对速度或者出租车流量进行预测。
交通小白刚入门,文中难免存在不妥之处,也诚恳地希望大家能够多多指出存在的问题,若有更好的处理意见也可以在评论区发言交流。愿本案例能够对大家处理交通大数据有所帮助,制作不易,多多支持
我即将开始一个将录制和编辑音频文件的项目,我正在寻找一个好的库(最好是Ruby,但会考虑Java或.NET以外的任何库)以进行实时可视化波形。有人知道我应该从哪里开始搜索吗? 最佳答案 要流入浏览器的数据量很大。Flash或Flex图表可能是唯一能提高内存效率的解决方案。Javascript图表往往会因大型数据集而崩溃。 关于ruby-Ruby中的波形可视化,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
下载微PE工具箱进入官网下载微PE工具箱-下载 安装好后,打开微PE工具箱客户端,选择安装PE到U盘 PE壁纸可选择自己喜欢的壁纸,勾选上包含DOS工具箱,个性化盘符图标 下载原版系统进入网站下载镜像NEXT,ITELLYOU如果没有账号,注册一下就好进入选择开始使用选择win10 这里我们选择消费者版,用迅雷把BT种子下载下来 下面的两个盘符,是PE工具箱安装进U盘后,分成的盘符,注意EFI的盘符,这里面不能删东西,也不能添东西,另一个盘符可以当做正常的U盘空间使用,我们现在需要把下载下来的景象文件复制到正常的U盘空间中去 这个时候我们的系统U盘就只做好了 安装系统我们将U盘插入电脑,开机,
如果使用Marshal.dump写入文件,我有一个Ruby散列达到大约10兆字节。gzip压缩后约为500KB。在ruby中迭代和改变这个散列是非常快的(几分之一毫秒)。即使复制它也非常快。问题是我需要在RubyonRails进程之间共享此散列中的数据。为了使用Rails缓存(file_store或memcached)执行此操作,我需要先Marshal.dump文件,但这会在序列化文件时产生1000毫秒的延迟,在序列化文件时产生400毫秒的延迟。理想情况下,我希望能够在100毫秒内从每个进程保存和加载此哈希。一个想法是生成一个新的Ruby进程来保存这个散列,该散列为其他进程提供AP
Unity数据可视化图表插件XCharts3.0发布历时8个多月,业余时间,断断续续,XCharts3.0总算发布了。如果要打个满意度,我给3.0版本来个80分。对于代码框架结构设计的调整改动,基本符合预期,甚是满意。相比之前的1.0和2.0版本,我认为3.0才是一个拿得出手给广大开发者使用的版本。1.0发布的时候,很兴奋,从0.1到1.0,也磨了一年,真的等不及想给大家试用了,还特地写过一篇文章以示庆祝。那个时候,1.0虽然还还不够完善,功能也不够丰富,但它是XCharts的开始,没有1.0,也就没有后面的2.0和3.0。后面的2.0发布,做了很多改进和优化,随着版本迭代,慢慢的发现有不少硬
文章目录概述背景为何要存算分离优势**应用场景**存算分离产品技术流派华为JuiceFSHashDataXSKY概述背景Hadoop一出生就是奔存算一体设计,当时设计思想就是存储不动而计算(code也即是代码程序)动,负责调度Yarn会把计算任务尽量发到要处理数据所在的实例上,这也是与传统集中式存储最大的不同。为何当时Hadoop设计存算一体的耦合?要知道2006年服务器带宽只有100Mb/s~1Gb/s,但是HDD也即是磁盘吞吐量有50MB/s,这样带宽远远不够传输数据,网络瓶颈尤为明显,无奈之举只好把计算任务发到数据所在的位置。众观历史常言道天下分久必合合久必分,随着云计算技术的发展,数据
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
本人是音乐爱好者,从小就特别喜欢那个随着音乐跳动的方框效果,就是这个:arduino上一大把对,我忍你很久了,我就想用mpy做,全网没有,行我自己研究。果然兴趣是最好的老师,我之前有篇博客专门讲音频,有兴趣的可以回顾一下。提到可视化频谱,必然绕不开fft,大学学过这玩意,当时一心玩,老师讲的一个字都么听进去,网上教程简略扫了一下,大该就是把时域转频域的工具,我大mpy居然没有fft函数,奶奶的,先放着。音频信息如何收集?第一种傻瓜式的ADC,模拟转数字,原始粗暴,第二种,I2S库,我之前博客有讲过,数据是PCM编码。然后又去学PCM编码,一学豁然开朗,舒服,以代码为例:audio_in=I2S
我以前在Laravel4上工作过,它有一个很棒的日志查看器工具laravellogviewer查看demo我正在寻找与Rubyonrails4.2非常相似的东西,如果你们知道Rails4.2的任何好的可视化日志记录GEM,请告诉我..从代码我需要记录不同的日志级别,这个工具应该直观地组织我的日志,谢谢.. 最佳答案 这应该可以帮助您入门https://github.com/shadabahmed/logstasher如其所说Thisgemisheavilyinspiredfromlograge,butit'sfocusedonone
我有以下场景:我需要在一个非常大的集合中找出唯一的ID列表。例如,我有6000个id数组(关注者列表),每个数组的大小范围在1到25000(他们的关注者列表)之间。我想获得所有这些ID数组中的唯一ID列表(关注者的唯一关注者)。完成后,我需要减去另一个ID列表(另一个人的关注者列表)并获得最终计数。最后一组唯一ID增长到大约60,000,000条记录。在ruby中,将数组添加到大数组时,它开始变得非常慢,大约几百万。添加到集合中一开始需要0.1秒,然后增长到200万时需要超过4秒(离我需要去的地方不远)。我用java编写了一个测试程序,它在不到一分钟的时间内完成了整个过程。也许我在
人类生活在充满多样性的世界里。长久以来的研究发现,人类的脑与行为受到基因、环境和文化及其相互作用的塑造,然而这种影响发生的机制始终缺乏系统性探索与研究。近年来,前沿神经影像技术方法飞速进步,推动着多模态脑成像大数据集的产生和融合性探索,并让学界得以深入探究人脑宏观结构与功能连接组架构,为包括上述主题在内的许多有趣而重要的科学问题带来了新的启发和思路。2022年12月20日,北京大学物理学院、IDG麦戈文脑科学研究所高家红团队在《NatureNeuroscience》在线发表了题为“IncreasingdiversityinconnectomicswiththeChineseHumanConne