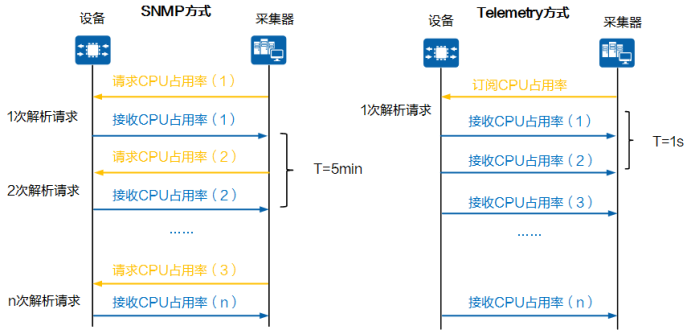
 由图所示,两者采集数据的交互过程主要有以下两个区别:1、从采集模型上,Telemetry占用网络设备性能很小。SNMP采集器与设备之间采用一问一答的交互方式,采集器每次采集数据时下发SNMP get请求,设备需对每个get请求进行响应,而Telemetry只需1次订阅及解析请求即可完成订阅,后续设备按照订阅指定的采集周期,持续推送数据给采集器,对网络设备的性能损耗很少;2、从采集周期上,Telemetry拥有更高采集精度及频率。SNMP get请求采集周期取决于网络轮询网内所有监控对象一次的整体时间,通常最短建议间隔5分钟,而Telemetry采集间隔可为1秒,最高精度可达亚秒级,精度细粒化可达300-30000倍。因此,在覆盖采集相同监控对象的情况下,SNMP协议采用“拉模式”,设备CPU需要响应更多的get请求,而Telemetry采用“推模式”,只需要进行1次订阅请求,因此Telemetry对设备CPU的性能消耗更小。同时,Telemetry采集频率更高,精度从5分钟到亚秒级,能获取更高精度的监控数据,对设备性能的消耗可控,实现精准监控网络状态。Telemetry和常见网络监控技术在工作模式、采集精度等方面的区别如下表所示:
由图所示,两者采集数据的交互过程主要有以下两个区别:1、从采集模型上,Telemetry占用网络设备性能很小。SNMP采集器与设备之间采用一问一答的交互方式,采集器每次采集数据时下发SNMP get请求,设备需对每个get请求进行响应,而Telemetry只需1次订阅及解析请求即可完成订阅,后续设备按照订阅指定的采集周期,持续推送数据给采集器,对网络设备的性能损耗很少;2、从采集周期上,Telemetry拥有更高采集精度及频率。SNMP get请求采集周期取决于网络轮询网内所有监控对象一次的整体时间,通常最短建议间隔5分钟,而Telemetry采集间隔可为1秒,最高精度可达亚秒级,精度细粒化可达300-30000倍。因此,在覆盖采集相同监控对象的情况下,SNMP协议采用“拉模式”,设备CPU需要响应更多的get请求,而Telemetry采用“推模式”,只需要进行1次订阅请求,因此Telemetry对设备CPU的性能消耗更小。同时,Telemetry采集频率更高,精度从5分钟到亚秒级,能获取更高精度的监控数据,对设备性能的消耗可控,实现精准监控网络状态。Telemetry和常见网络监控技术在工作模式、采集精度等方面的区别如下表所示: 由表可见,Telemetry的工作模式是推模式,设备侧主动推送数据,并提供亚秒级精度,此外还有比较关键的一点是,Telemetry数据采用标准结构和编码,方便对接第三方设备,有助于提升网络监控效率和监控质量。SNMP Trap和SYSLOG虽然也是推模式,但是其推送的数据范围有限,对于类似接口流量等监控数据不能实时采集。
由表可见,Telemetry的工作模式是推模式,设备侧主动推送数据,并提供亚秒级精度,此外还有比较关键的一点是,Telemetry数据采用标准结构和编码,方便对接第三方设备,有助于提升网络监控效率和监控质量。SNMP Trap和SYSLOG虽然也是推模式,但是其推送的数据范围有限,对于类似接口流量等监控数据不能实时采集。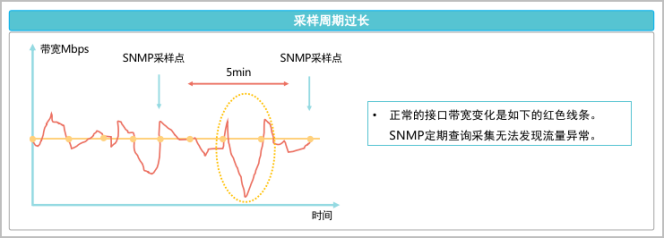 当SNMP等传统运维方式采用更快的数据采集周期解决这个问题时,由于使用的是“拉模式”,更为密集的采集拉取可能会造成网络设备CPU持续升高,甚至有瘫痪风险。因此SNMP为代表的运维技术无法满足当前IT运维实时和全程监控的需求,也无法检测网络中大量微突发(Mirco Burst)造成的网络问题。微突发是指在很短时间(毫秒级别)内收到很多的突发数据,以至于瞬时突发速率达到平均速率的数十、百倍,甚至占满端口带宽的现象。网管设备或网络性能监测软件通常是基于较长时间(数分钟),通过计算这段时间内的平均值来作为网络实时带宽。在这种情况下,看到流量速率通常会被“削峰填谷”,呈现出来是一条较为平稳的曲线,但是实际设备可能已由于微突发导致丢包,并影响应用系统。如下图所示为采用分钟级SNMP和亚秒级Telemetry采集数据的对比曲线。
当SNMP等传统运维方式采用更快的数据采集周期解决这个问题时,由于使用的是“拉模式”,更为密集的采集拉取可能会造成网络设备CPU持续升高,甚至有瘫痪风险。因此SNMP为代表的运维技术无法满足当前IT运维实时和全程监控的需求,也无法检测网络中大量微突发(Mirco Burst)造成的网络问题。微突发是指在很短时间(毫秒级别)内收到很多的突发数据,以至于瞬时突发速率达到平均速率的数十、百倍,甚至占满端口带宽的现象。网管设备或网络性能监测软件通常是基于较长时间(数分钟),通过计算这段时间内的平均值来作为网络实时带宽。在这种情况下,看到流量速率通常会被“削峰填谷”,呈现出来是一条较为平稳的曲线,但是实际设备可能已由于微突发导致丢包,并影响应用系统。如下图所示为采用分钟级SNMP和亚秒级Telemetry采集数据的对比曲线。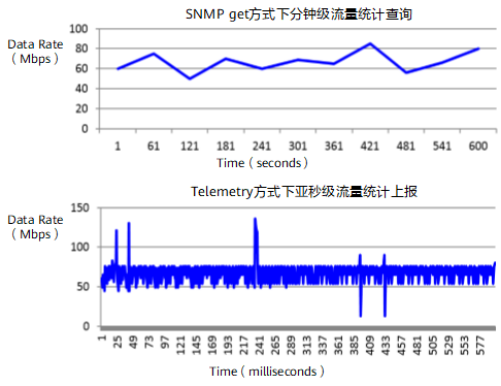 从图中可看出,以SNMP get方式查询的端口流量统计是比较平滑的,而Telemetry方式流量统计明显看到有微突发现象发生。通过Telemetry的高精度采样,能检测到这些微突发流量以及由于微突发导致的端口丢包问题。
从图中可看出,以SNMP get方式查询的端口流量统计是比较平滑的,而Telemetry方式流量统计明显看到有微突发现象发生。通过Telemetry的高精度采样,能检测到这些微突发流量以及由于微突发导致的端口丢包问题。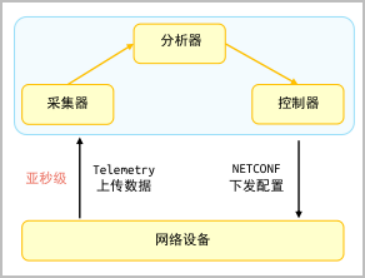 1、采集器用于接收和存储网络设备上报的原始监控数据,网络设备依据采集器的配置要求,将采集完成的秒级或亚秒级监控数据,上报给采集器存储。2、分析器 用于分析采集器接收到的监控数据,并对数据进行处理,以图形化界面的形式将分析结果直观展现给用户。3、控制器通过 NETCONF等方式向设备下发配置,实现对网络设备的控制。控制器根据分析器提供的分析数据向网络设备下发配置,对网络设备的转发行为进行调整,也可控制网络设备对哪些数据进行采样和上报。
1、采集器用于接收和存储网络设备上报的原始监控数据,网络设备依据采集器的配置要求,将采集完成的秒级或亚秒级监控数据,上报给采集器存储。2、分析器 用于分析采集器接收到的监控数据,并对数据进行处理,以图形化界面的形式将分析结果直观展现给用户。3、控制器通过 NETCONF等方式向设备下发配置,实现对网络设备的控制。控制器根据分析器提供的分析数据向网络设备下发配置,对网络设备的转发行为进行调整,也可控制网络设备对哪些数据进行采样和上报。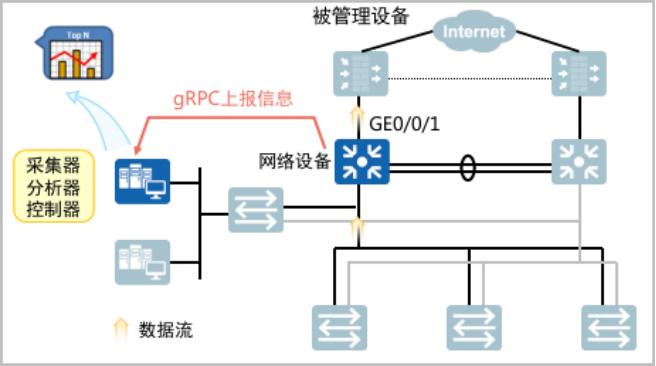 在网络设备侧,Telemetry按照YANG模型组织数据,利用GPB(Google Protocol Buffer)格式编码,并通过gRPC(Google Remote Procedure Call Protocol)协议传输数据。在网管系统侧,Telemetry完成数据的收集、分析、存储功能,利用分析结果为网络配置调整提供依据,如下图所示:
在网络设备侧,Telemetry按照YANG模型组织数据,利用GPB(Google Protocol Buffer)格式编码,并通过gRPC(Google Remote Procedure Call Protocol)协议传输数据。在网管系统侧,Telemetry完成数据的收集、分析、存储功能,利用分析结果为网络配置调整提供依据,如下图所示: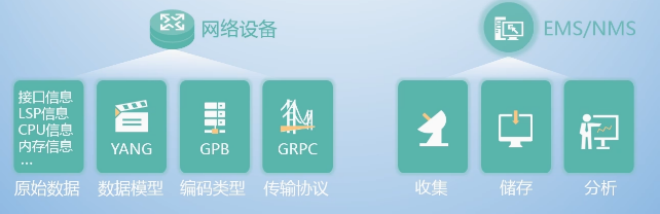 下面是网络设备侧涉及的一些概念和名词的说明解释: 原始数据:Telemetry采样的原始数据可来自网络设备的转发面、控制面和管理面,目前支持采集设备的接口流量统计、CPU或内存数据等信息。数据模型:Telemetry基于YANG模型组织采集数据。YANG是一种数据建模语言,用于设计可以作为各种传输协议操作的配置数据模型、状态数据模型、远程调用模型和通知机制等。编码格式:支持GPB(Google Protocol Buffer)和 JSON(JavaScript Object Notation)编码格式。Telemetry利用GPB编码格式(GPB编码格式的文件名后缀为.proto),提供一种灵活、高效、自动序列化结构数据的机制,GPB属于二进制编码,性能好、效率高。传输协议:支持gRPC协议(google Remote Procedure Call Protocol)和UDP协议(User Datagram Protocol)。gRPC协议是谷歌发布的一个基于HTTP2协议承载的高性能、通用的RPC开源软件框架。通信双方都基于该框架进行二次开发,从而使得通信双方聚焦在业务,无需关注由gRPC软件框架实现的底层通信。需要说明的一点是,gRPC协议可以用于Telemetry静态订阅或动态订阅,而UDP仅可以用于Telemetry静态订阅。
下面是网络设备侧涉及的一些概念和名词的说明解释: 原始数据:Telemetry采样的原始数据可来自网络设备的转发面、控制面和管理面,目前支持采集设备的接口流量统计、CPU或内存数据等信息。数据模型:Telemetry基于YANG模型组织采集数据。YANG是一种数据建模语言,用于设计可以作为各种传输协议操作的配置数据模型、状态数据模型、远程调用模型和通知机制等。编码格式:支持GPB(Google Protocol Buffer)和 JSON(JavaScript Object Notation)编码格式。Telemetry利用GPB编码格式(GPB编码格式的文件名后缀为.proto),提供一种灵活、高效、自动序列化结构数据的机制,GPB属于二进制编码,性能好、效率高。传输协议:支持gRPC协议(google Remote Procedure Call Protocol)和UDP协议(User Datagram Protocol)。gRPC协议是谷歌发布的一个基于HTTP2协议承载的高性能、通用的RPC开源软件框架。通信双方都基于该框架进行二次开发,从而使得通信双方聚焦在业务,无需关注由gRPC软件框架实现的底层通信。需要说明的一点是,gRPC协议可以用于Telemetry静态订阅或动态订阅,而UDP仅可以用于Telemetry静态订阅。
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
我在思考流量控制的最佳实践。我应该走哪条路?1)不要检查任何东西并让程序失败(更清晰的代码,自然的错误消息):defself.fetch(feed_id)feed=Feed.find(feed_id)feed.fetchend2)通过返回nil静默失败(但是,“CleanCode”说,你永远不应该返回null):defself.fetch(feed_id)returnunlessfeed_idfeed=Feed.find(feed_id)returnunlessfeedfeed.fetchend3)抛出异常(因为不按id查找feed是异常的):defself.fetch(feed_id
我希望访问我机器上的所有HTTP流量(我的Windows机器-不是服务器)。据我了解,拥有一个本地代理是所有流量路线的必经之路。我一直在谷歌搜索但未能找到任何资源(关于Ruby)来帮助我。非常感谢任何提示或链接。 最佳答案 WEBrick中有一个HTTP代理(Rubystdlib的一部分)和here's一个实现示例。如果你喜欢生活在边缘,还有em-proxy伊利亚·格里戈里克。这postIlya暗示它似乎确实需要一些调整来解决您的问题。 关于ruby-如何捕获所有HTTP流量(本地代理)
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
我刚刚看到whitehouse.gov正在使用drupal作为CMS和门户技术。drupal的优点之一似乎是很容易添加插件,而且编程最少,即重新发明轮子最少。这实际上正是Ruby-on-Rails的DRY理念。所以:drupal的缺点是什么?Rails或其他基于Ruby的技术有哪些不符合whitehouse.org(或其他CMS门户)门户技术的资格? 最佳答案 Whatarethedrawbacksofdrupal?对于Ruby和Rails,这确实是一个相当主观的问题。Drupal是一个可靠的内容管理选项,非常适合面向社区的站点。它
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG